Plans for Evaluating Structured Generative Search Summaries
Pith reviewed 2026-06-29 16:23 UTC · model grok-4.3
The pith
A framework is proposed to evaluate structured generative summaries placed above web search results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
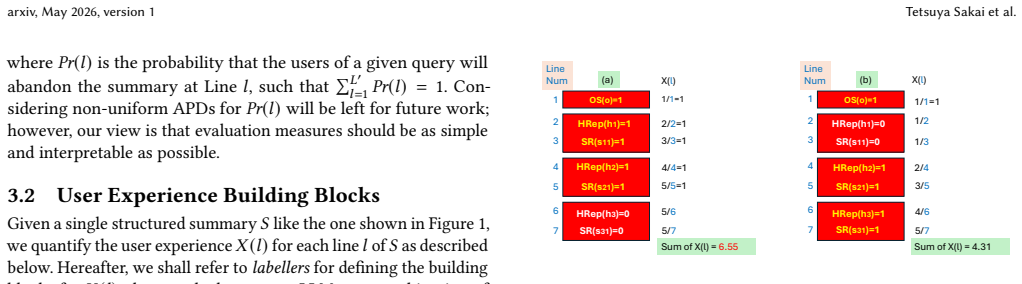
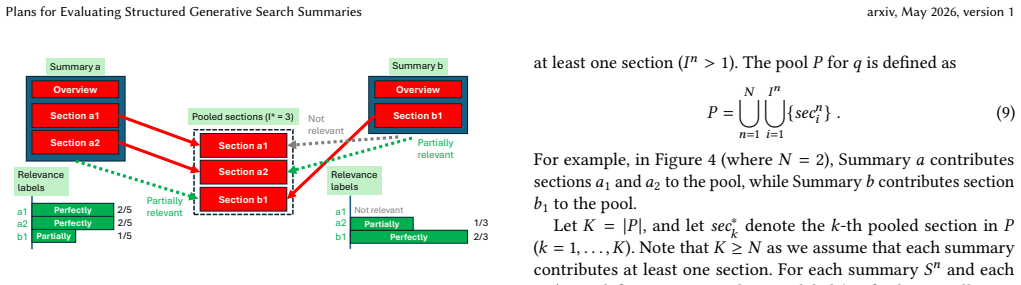
We propose a framework for evaluating structured generative search summaries that are placed atop organic web search results. A structured summary, generated by a large language model, typically consists of an overview, several sections with section titles, and a list of source documents that are cited within the summary. We then describe our plans for implementing and evaluating the framework.
What carries the argument
The evaluation framework for structured generative search summaries, which measures the quality of the overview, titled sections, and cited sources.
If this is right
- Search engines can apply consistent checks to the structure and sourcing of LLM summaries before display.
- Developers receive concrete signals on where generated summaries need improvement in accuracy or coverage.
- Evaluation can extend to user-facing tasks such as verifying citation correctness and section relevance.
- The framework provides a repeatable process for comparing different generation models on the same summary task.
Where Pith is reading between the lines
- If the framework succeeds, it could be adapted to measure how well summaries reduce user clicks on the original results.
- The approach leaves open the question of whether human raters or automated checks will dominate the scoring once data arrives.
- Connection to existing IR metrics such as nDCG may require new definitions that treat the summary as a single composite object rather than ranked items.
Load-bearing premise
That LLM summaries will consistently appear in the form of an overview plus titled sections with citations, so that an evaluation framework can be designed without first collecting data on how they usually fail.
What would settle it
A large sample of current LLM outputs for search queries shows that most summaries lack the expected overview-sections-citations structure or cannot be scored by the planned metrics.
Figures


read the original abstract
We propose a framework for evaluating structured generative search summaries that are placed atop organic web search results. A structured summary, generated by a large language model, typically consists of an overview, several sections with section titles, and a list of source documents that are cited within the summary. We then describe our plans for implementing and evaluating the framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework for evaluating structured generative search summaries placed atop organic web search results. These summaries are described as typically consisting of an overview, several titled sections, and a list of cited source documents generated by LLMs. The paper outlines plans for implementing and evaluating the framework but contains no completed evaluations, data, or empirical results.
Significance. If a concrete framework were developed from these plans, it could address a timely need in information retrieval for assessing the quality of LLM-generated structured outputs in search, particularly regarding citation accuracy and structural coherence. The proposal correctly notes the distinction between free-form and structured generative summaries. However, the absence of any implemented components or validation means the work offers no demonstrated advance or falsifiable predictions at present.
major comments (2)
- [Abstract and plans description] The central proposal assumes LLM outputs will reliably conform to the overview-plus-titled-sections-plus-citations structure, yet the plans provide no mechanism or preliminary analysis for detecting or handling non-conforming outputs (see abstract description of structured summaries and the implementation plans).
- [Plans for implementing and evaluating the framework] No concrete evaluation metrics, datasets, or protocols are specified in the framework plans, leaving the claim that such a framework can be designed and implemented without first collecting data on failure modes unsupported (see the description of plans for implementing the framework).
minor comments (1)
- The manuscript would benefit from explicit section headings and a clearer distinction between the proposed framework components and the evaluation plans.
Simulated Author's Rebuttal
We thank the referee for their review. The manuscript is explicitly a description of plans for a framework rather than a report of completed implementation or empirical results. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and plans description] The central proposal assumes LLM outputs will reliably conform to the overview-plus-titled-sections-plus-citations structure, yet the plans provide no mechanism or preliminary analysis for detecting or handling non-conforming outputs (see abstract description of structured summaries and the implementation plans).
Authors: We agree the plans should address non-conforming outputs. The abstract uses 'typically' to describe the target structure, but the implementation section will be revised to include explicit mechanisms such as structure-validation steps (e.g., parsing for required sections and citations) and fallback procedures. This addition will be made in the next version. revision: yes
-
Referee: [Plans for implementing and evaluating the framework] No concrete evaluation metrics, datasets, or protocols are specified in the framework plans, leaving the claim that such a framework can be designed and implemented without first collecting data on failure modes unsupported (see the description of plans for implementing the framework).
Authors: The manuscript presents high-level plans consistent with its title. We accept that greater specificity on metrics (e.g., citation faithfulness, section coherence), example datasets, and protocols would strengthen the description. We will partially revise by adding proposed concrete metrics and an initial data-collection step on failure modes while retaining the overall plan-oriented scope. revision: partial
Circularity Check
No significant circularity in forward proposal
full rationale
This document is explicitly a proposal paper that describes plans for a future evaluation framework rather than presenting any completed derivation, empirical results, equations, fitted parameters, or self-referential claims. The central claim is the existence and description of those plans; it contains no load-bearing steps that reduce by construction to inputs, no self-citation chains, and no predictions or uniqueness theorems. The derivation chain is therefore self-contained as a non-empirical planning document.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zahra Abbasiantaeb, Simon Lupart, Leif Azzopardi, Jeffrey Dalton, and Moham- mad Aliannejadi. 2025. Conversational Gold: Evaluating Personalized Conversa- tional Search System Using Gold Nuggets. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (Padua, Italy)(SIGIR ’25). Association for Comp...
-
[2]
Marwah Alaofi, Negar Arabzadeh, Charles L. A. Clarke, and Mark Sanderson. 2024.Generative Information Retrieval Evaluation. Springer Nature Switzerland, 135–159. doi:10.1007/978-3-031-73147-1_6
-
[3]
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Jackson Kernion, Kamal Ndousse, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, and Jared Kaplanz. 2021. A General Language Assistant as a...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Chris Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Greg Hullender. 2005. Learning to rank using gradient descent. InProceedings of the 22nd International Conference on Machine Learning(Bonn, Germany)(ICML ’05). Association for Computing Machinery, New York, NY, USA, 89–96. doi:10. 1145/1102351.1102363
-
[5]
Shuyang Cao and Lu Wang. 2024. Verifiable Generation with Subsentence- Level Fine-Grained Citations. InFindings of the Association for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 15584–15596. doi:10.18653/v1/2024.findings-acl.920
-
[6]
Clarke and Laura Dietz
Charles L.A. Clarke and Laura Dietz. 2025. LLM-based relevance assessment still can’t replace human relevance assessment. InProceedings of EVIA 2025. to appear
2025
-
[7]
Charles L. A. Clarke, Nick Craswell, and Ellen M. Voorhees. 2013. Overview of the TREC 2012 Web Track. InProceedings of TREC 2012. NIST
2013
-
[8]
Clarke and Peter Willet
Sarah J. Clarke and Peter Willet. 1997. Estimating the Recall Performance of Web Search Engines.Aslib Proceedings49, 7 (1997), 184–189
1997
-
[9]
William S. Cooper. 1973. On selecting a measure of retrieval effective- ness.Journal of the American Society for Information Science24, 2 (1973), 87–
1973
-
[10]
arXiv:https://asistdl.onlinelibrary.wiley.com/doi/pdf/10.1002/asi.4630240204 doi:10.1002/asi.4630240204
-
[11]
Rahmani, Daniel Campos, Jimmy Lin, Ellen M
Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Hossein A. Rahmani, Daniel Campos, Jimmy Lin, Ellen M. Voorhees, and Ian Soboroff. 2024. Overview of the TREC 2023 Deep Learning Track. InProceedings of TREC 2023. https: //trec.nist.gov/pubs/trec32/papers/Overview_deep.pdf
2024
-
[12]
Hoa Trang Dang, Jimmy Lin, and Diane Kelly. 2007. Overview of the TREC 2006 Question Answering Track. InProceedings of TREC 2006. https://trec.nist.gov/ pubs/trec15/papers/QA06.OVERVIEW.pdf
2007
-
[13]
Michael D Ekstrand, Graham McDonald, and Amifa Raj. 2022. Overview of the TREC 2021 Fair Ranking Track. InThe Thirtieth Text REtrieval Conference (TREC
2022
-
[14]
Proceedings. NIST. https://trec.nist.gov/pubs/trec30/papers/Overview-F.pdf
-
[15]
Shahul Es, Jithin James, Luis Espinosa Anke, and Steven Schockaert. 2024. RAGAs: Automated Evaluation of Retrieval Augmented Generation. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, Nikolaos Aletras and Orphee De Clercq (Eds.). Association for Computational Linguistic...
2024
-
[16]
Guglielmo Faggioli, Laura Dietz, Charles L. A. Clarke, Gianluca Demartini, Matthias Hagen, Claudia Hauff, Noriko Kando, Evangelos Kanoulas, Martin Potthast, Benno Stein, and Henning Wachsmuth. 2023. Perspectives on Large Language Models for Relevance Judgment. InProceedings of the 2023 ACM SI- GIR International Conference on Theory of Information Retrieva...
-
[17]
Susanne Förster and Yarden Skop. 2026. Between fact and fairy: tracing the hallucination metaphor in AI discourse.AI & SOCIETY41, 3 (2026), 1695–1698. doi:10.1007/s00146-025-02392-w
-
[18]
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023. Enabling Large Language Models to Generate Text with Citations. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 6465–6488. doi:10.18653/v1/2023.emnlp-main.398
-
[19]
Lukas Gienapp, Harrisen Scells, Niklas Deckers, Janek Bevendorff, Shuai Wang, Johannes Kiesel, Shahbaz Syed, Maik Fröbe, Guido Zuccon, Benno Stein, Matthias Hagen, and Martin Potthast. 2024. Evaluating Generative Ad Hoc Information Retrieval. InProceedings of the 47th International ACM SIGIR Conference on Re- search and Development in Information Retrieva...
-
[20]
Amelia Glaese, Nat McAleese, Maja Trebacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, Lucy Campbell-Gillingham, Jonathan Uesato, Po-Sen Huang, Ramona Comanescu, Fan Yang, Abigail See, Sumanth Dathathri, Rory Greig, Charlie Chen, Doug Fritz, Jaume Sanchez Elias, Richard Green, Soňa Mokrá, Nich...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Hideaki Joko and Faegheh Hasibi. 2026. FACE: A Fine-Grained Reference-Free Evaluator for Conversational Information Access. arXiv:2506.00314 [cs.IR] https: //arxiv.org/abs/2506.00314
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Why Language Models Hallucinate
Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, and Edwin Zhang. 2025. Why Language Models Hallucinate. arXiv:2509.04664 [cs.CL] https://arxiv.org/ abs/2509.04664
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Weronika Łajewska and Krisztian Balog. 2025. GINGER: Grounded Information Nugget-Based Generation of Responses. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (Padua, Italy)(SIGIR ’25). Association for Computing Machinery, New York, NY, USA, 2723–2727. doi:10.1145/3726302.3730166
-
[24]
Salima Lamsiyah, Aria Nourbakhsh, and Christoph Schommer. 2025. Trust but Verify: A Comprehensive Survey of Faithfulness Evaluation Methods in Abstrac- tive Text Summarization. InProceedings of the 15th International Conference on Recent Advances in Natural Language Processing - Natural Language Processing in the Generative AI Era, Galia Angelova, Maria K...
2025
-
[25]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. InProceedings of the 34th International Conference on Neural Information Processing Systems(Van...
2020
-
[26]
Yuepei Li, Kang Zhou, Qiao Qiao, Bach Nguyen, Qing Wang, and Qi Li. 2025. Investigating Context Faithfulness in Large Language Models: The Roles of Mem- ory Strength and Evidence Style. InFindings of the Association for Computational Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for ...
-
[27]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://aclanthology.org/W04-1013/
2004
-
[28]
Nelson Liu, Tianyi Zhang, and Percy Liang. 2023. Evaluating Verifiability in Generative Search Engines. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 7001–7025. doi:10.18653/ v1/2023.findings-emnlp.467
2023
-
[29]
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingam, Ge- offrey Irving, and Nat McAleese. 2022. Teaching language models to support answers with verified quotes. (2022). https://arxiv.org/abs/2203.11147
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Teruko Mitamura, Hideki Shima, Tetsuya Sakai, Noriko Kando, Tatsunori Mori, Koichi Takeda, Chin-Yew Lin, Ruihua Song, Chuan-Jie Lin, and Cheng-Wei Lee. 2010. Overview of the NTCIR-8 ACLIA Tasks: Ad- vanced Cross-Lingual Information Access. InProceedings of NTCIR-8. 15–
2010
-
[31]
http://research.nii.ac.jp/ntcir/workshop/OnlineProceedings8/NTCIR/01- NTCIR8-OV-CCLQA-MitamuraT.pdf
- [32]
-
[33]
LLM Evaluators Recognize and Favor Their Own Generations
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. 2024. LLM Evaluators Recognize and Favor Their Own Generations. arXiv:2404.13076 [cs.CL] https: //arxiv.org/abs/2404.13076
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Fabio Petroni, Federico Siciliano, Fabrizio Silvestri, and Giovanni Trappolini. 2024. IR-RAG @ SIGIR24: Information Retrieval’s Role in RAG Systems. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in In- formation Retrieval(Washington DC, USA)(SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 3036...
-
[35]
Ronak Pradeep, Nandan Thakur, Shivani Upadhyay, Daniel Campos, Nick Craswell, Ian Soboroff, Hoa Trang Dang, and Jimmy Lin. 2025. The Great Nugget Recall: Automating Fact Extraction and RAG Evaluation with Large Language Models. InProceedings of the 48th International ACM SIGIR Confer- ence on Research and Development in Information Retrieval(Padua, Italy)...
-
[36]
Filip Radlinski and Nick Craswell. 2017. A Theoretical Framework for Conversa- tional Search. InProceedings of the 2017 Conference on Conference Human Infor- mation Interaction and Retrieval(Oslo, Norway)(CHIIR ’17). Association for Com- puting Machinery, New York, NY, USA, 117–126. doi:10.1145/3020165.3020183 arxiv, May 2026, version 1 Tetsuya Sakai et al
-
[37]
Shahzad Rajput, Virgil Pavlu, Peter B. Golbus, and Javed A. Aslam. 2011. A nugget- based test collection construction paradigm. InProceedings of the 20th ACM International Conference on Information and Knowledge Management(Glasgow, Scotland, UK)(CIKM ’11). Association for Computing Machinery, New York, NY, USA, 1945–1948. doi:10.1145/2063576.2063861
-
[38]
Hannah Rashkin, Vitaly Nikolaev, Matthew Lamm, Lora Aroyo, Michael Collins, Dipanjan Das, Slav Petrov, Gaurav Singh Tomar, Iulia Turc, and David Reitter
-
[39]
Measuring Attribution in Natural Language Generation Models.Computa- tional Linguistics49, 4 (Dec. 2023), 777–840. doi:10.1162/coli_a_00486
-
[40]
Soolienah Rhiu, Moses Kim, Jae hyung Kim, Hye Jin Lee, and Tae-Hyung Lim
-
[41]
Korean Version Self-testing Application for Reading Speed.Korean Journal of Ophthalmology31, 3 (2017), 202–208. doi:10.3341/kjo.2016.0042
-
[42]
Stephen Robertson. 2008. A new interpretation of average precision. InPro- ceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval(Singapore, Singapore)(SIGIR ’08). Asso- ciation for Computing Machinery, New York, NY, USA, 689–690. doi:10.1145/ 1390334.1390453
-
[43]
2014.Metrics, Statistics, Tests
Tetsuya Sakai. 2014.Metrics, Statistics, Tests. Springer Berlin Heidelberg, Berlin, Heidelberg, 116–163. doi:10.1007/978-3-642-54798-0_6
-
[44]
2019.How to Run an Evaluation Task
Tetsuya Sakai. 2019.How to Run an Evaluation Task. Springer International Publishing, Cham, 71–102. doi:10.1007/978-3-030-22948-1_3
- [45]
-
[46]
Tetsuya Sakai. 2024. Evaluating System Responses Based On Overconfidence and Underconfidence. InJoint Proceedings of the SIGIR-AP 2024 Workshops EMTCIR 2024 and UM-CIR 2024. https://ceur-ws.org/Vol-3854/emtcir-1.pdf
2024
-
[47]
Tetsuya Sakai and Zhicheng Dou. 2013. Summaries, ranked retrieval and sessions: a unified framework for information access evaluation. InProceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval(Dublin, Ireland)(SIGIR ’13). Association for Computing Machinery, New York, NY, USA, 473–482. doi:10.1145/24...
-
[48]
Tetsuya Sakai, Makoto P. Kato, and Young-In Song. 2011. Click the search button and be happy: evaluating direct and immediate information access. InProceedings of the 20th ACM International Conference on Information and Knowledge Manage- ment(Glasgow, Scotland, UK)(CIKM ’11). Association for Computing Machinery, New York, NY, USA, 621–630. doi:10.1145/206...
-
[49]
Tetsuya Sakai, Jin Young Kim, and Inho Kang. 2023. A Versatile Framework for Evaluating Ranked Lists in Terms of Group Fairness and Relevance.ACM TOIS 42, 1, Article 11 (Aug. 2023), 36 pages. doi:10.1145/3589763
-
[50]
Tetsuya Sakai, Khant Myoe Rain, Rikiya Takehi, Sijie Tao, and Young-In Song
-
[51]
Highly Reliable Manual Relevance Assessment: A Case Study
Open-Source LLM-based Relevance Assessment vs. Highly Reliable Manual Relevance Assessment: A Case Study. InProceedings of the 34th ACM Interna- tional Conference on Information and Knowledge Management(Seoul, Republic of Korea)(CIKM ’25). Association for Computing Machinery, New York, NY, USA, 5186–5190. doi:10.1145/3746252.3760934
-
[52]
Tetsuya Sakai and Stephen Robertson. 2008. Modelling A User Population for Designing Information Retrieval Metrics. InProceedings of EVIA 2008. 30–
2008
-
[53]
https://research.nii.ac.jp/ntcir/workshop/OnlineProceedings7/pdf/EVIA2008/ 07-EVIA2008-SakaiT.pdf
-
[54]
Tetsuya Sakai, Sijie Tao, Atsuya Ishikawa, Hanpei Fang, Ziliang Zhao, Yujia Zhou, Nuo Chen, and Young-In Song. 2025. Evaluating the Modesty of RAG Systems at the NTCIR-19 R2C2 Task: Potential Challenges. InProceedings of BREV- RAG@SIGIR-AP 2025. 5–21. https://brev-rag-workshop.github.io/paper-02.pdf
2025
-
[55]
Tetsuya Sakai, Sijie Tao, and Young-In Song. 2025. Evaluating Group Fair- ness and Relevance in Conversational Search: An Alternative Formulation. In Proceedings of EVIA 2025. 15–22. https://research.nii.ac.jp/ntcir/workshop/ OnlineProceedings18/pdf/evia/03-EVIA2025-EVIA-SakaiT.pdf
2025
-
[56]
Tetsuya Sakai and Zhaohao Zeng. 2021. Retrieval Evaluation Measures that Agree with Users’ SERP Preferences: Traditional, Preference-based, and Diversity Measures.ACM TOIS39, 2, Article 14 (2021), 35 pages. doi:10.1145/3431813
-
[57]
Chris Samarinas, Alexander Krubner, Alireza Salemi, Youngwoo Kim, and Hamed Zamani. 2025. Beyond Factual Accuracy: Evaluating Coverage of Diverse Factual Information in Long-form Text Generation. InFindings of the Association for Computational Linguistics: ACL 2025, Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Associ...
-
[58]
Ian Soboroff. 2025. Don’t Use LLMs to Make Relevance Judgments.Information Retrieval Research1, 1 (Mar. 2025), 29–46. doi:10.54195/irrj.19625
-
[59]
Rijsbergen
Karen Sparck Jones and C.J. Rijsbergen. 1975.Report on the Need for and Provision of an ‘Ideal’ Information Retrieval Test Collection. Technical Report. Computer Laboratory, University of Cambridge, British Library Research and Development Report No.5266
1975
-
[60]
Sijie Tao and Tetsuya Sakai. 2022. Overview of the NTCIR-16 Di- alogue Evaluation (DialEval-2) Task. InProceedings of NTCIR-16. 51–
2022
-
[61]
https://research.nii.ac.jp/ntcir/workshop/OnlineProceedings16/pdf/ntcir/01- NTCIR16-OV-DIALEVAL-TaoS.pdf
- [62]
-
[63]
Ian van Dort and Maria Heuss. 2026. How Do LLMs Cite? A Mechanistic Interpre- tation of Attribution in RAG. InAdvances in Information Retrieval: 48th European Conference on Information Retrieval, ECIR 2026, Delft, The Netherlands, March 29 – April 2, 2026, Proceedings, Part III(Delft, The Netherlands). Springer-Verlag, Berlin, Heidelberg, 458–473. doi:10....
-
[64]
Voorhees
Ellen M. Voorhees. 2004. Overview of the TREC 2003 Question Answering Track. InProceedings of TREC 2003. https://trec.nist.gov/pubs/trec12/papers/QA. OVERVIEW.pdf
2004
-
[65]
Voorhees and Donna K
Ellen M. Voorhees and Donna K. Harman. 2005.TREC: Experiment and Evaluation in Information Retrieval. The MIT Press, Cambridge, Masachusetts, Chapter 2, 21–52
2005
-
[66]
Jonas Wallat, Maria Heuss, Maarten de Rijke, and Avishek Anand. 2025. Cor- rectness is not Faithfulness in Retrieval Augmented Generation Attributions. InProceedings of the 2025 International ACM SIGIR Conference on Innova- tive Concepts and Theories in Information Retrieval (ICTIR)(Padua, Italy)(IC- TIR ’25). Association for Computing Machinery, New York...
-
[67]
Zhaohao Zeng, Sosuke Kato, Tetsuya Sakai, and Inho Kang. 2020. Overview of the NTCIR-15 Dialogue Evaluation (DialEval-1) Task. InProceedings of NTCIR-15. 13–
2020
-
[68]
https://research.nii.ac.jp/ntcir/workshop/OnlineProceedings15/pdf/ntcir/01- NTCIR15-OV-DIALEVAL-ZengZ.pdf
-
[69]
Wenxuan Zhou, Sheng Zhang, Hoifung Poon, and Muhao Chen. 2023. Context- faithful Prompting for Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 14544–14556. doi:10.18653/v1/2023.findings-emnlp.968
-
[70]
Justin Zobel, Alistair Moffat, and Laurence A.F. Park. 2009. Against recall: is it persistence, cardinality, density, coverage, or totality?SIGIR Forum43, 1 (June 2009), 3–8. doi:10.1145/1670598.1670600
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.