Decomposing MXFP4 quantization error for LLM reinforcement learning: reducible bias, recoverable deadzone, and an irreducible floor
Pith reviewed 2026-05-25 05:47 UTC · model grok-4.3
The pith
MXFP4 quantization error for LLM RL decomposes exactly into scale bias, deadzone truncation, and grid noise, each tied to a distinct training failure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
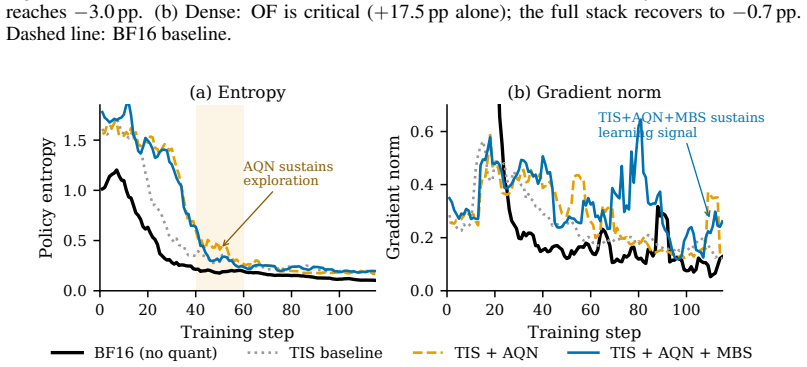
We prove an exact three-way decomposition of the MXFP4 quantization error into scale bias from power-of-two rounding, deadzone truncation from zeroing small values, and grid noise from rounding to the nearest 4-bit grid. Each component dominates a distinct RL failure mode: scale bias accumulates multiplicatively through the backward pass affecting gradient accuracy, deadzone truncation degrades rollout quality, and grid noise raises the policy's entropy. We combine corrections that are RL failure mode-targeted but not component-exclusive: macro-block scaling to reduce scale bias, outlier fallback recovers deadzone entries while also partially reducing scale bias, and adaptive quantization噪声
What carries the argument
The exact three-way additive decomposition of MXFP4 quantization error into scale bias, deadzone truncation, and grid noise, with each mapped to a separate RL training pathway.
If this is right
- Macro-block scaling reduces scale bias accumulation and improves gradient accuracy in the backward pass.
- Outlier fallback recovers deadzone-truncated values and partially mitigates scale bias error.
- Adaptive quantization noise limits the entropy increase driven by grid noise.
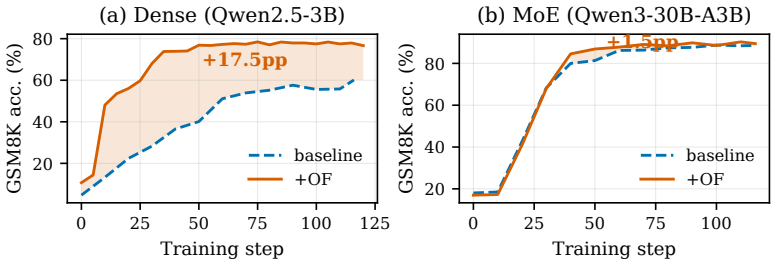
- The component-specific fixes allow MXFP4 to reach or surpass BF16 accuracy in RL post-training on the tested dense and mixture-of-experts models.
Where Pith is reading between the lines
- The same three-way split may apply to other low-bit formats used in RL training, allowing similar targeted fixes.
- If the components stay independent at larger scales, the method could support quantization in even bigger RL runs without proportional accuracy loss.
- The grid noise floor implies a hard performance limit that future quantization designs would need to lower directly.
- Extending the decomposition to supervised fine-tuning stages could expose parallel failure pathways in those settings.
Load-bearing premise
The three error components are additive and each can be corrected independently without introducing new dominant failure modes.
What would settle it
An experiment that measures the three error terms separately before and after each correction and finds that their sum does not equal the observed total accuracy change, or that one correction changes the measured dominance of another component.
Figures






read the original abstract
MXFP4 arithmetic can dramatically accelerate reinforcement learning (RL) post-training of large language models (LLMs), yet the quantization error introduces severe accuracy degradation. Existing work treats the quantization error as a monolithic noise term, missing the distinct mechanisms upon interpreting how quantization error damages training. We prove an exact three-way decomposition of quantization error and show how each component dominates a distinct RL training pathway. Our theoretical and empirical analysis decomposes the MXFP4 quantization error into three additive components: "scale bias" from power-of-two rounding, "deadzone truncation" from zeroing small values, and "grid noise" from rounding to the nearest 4-bit grid. Each component dominates a distinct RL failure mode: scale bias accumulates multiplicatively through the backward pass, affecting gradient accuracy; deadzone truncation degrades rollout quality; and grid noise raises the policy's entropy. We combine corrections that are RL failure mode-targeted but not component-exclusive: Macro-block scaling to reduce scale bias, Outlier Fallback recovers deadzone entries, but also partially reduces scale bias induced error, and Adaptive Quantization Noise (AQN) for controlling the policy entropy. On Qwen2.5-3B dense and Qwen3-30B-A3B-Base mixture-of-experts model, the targeted corrections recover BF16 accuracy to within 0.7% and exceed BF16 by +1.0% respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to prove an exact three-way additive decomposition of MXFP4 quantization error into scale bias (power-of-two rounding), deadzone truncation (zeroing small values), and grid noise (nearest 4-bit grid rounding). Each component is said to dominate a distinct RL failure mode (gradient accuracy, rollout quality, policy entropy), with targeted corrections (macro-block scaling, outlier fallback, AQN) that recover BF16 accuracy to within 0.7% on Qwen2.5-3B and exceed it by +1.0% on Qwen3-30B-A3B-Base MoE.
Significance. If the decomposition is exact, additive, and the corrections combine without new dominant interactions after backprop and policy updates, the work could enable practical acceleration of LLM RL post-training via MXFP4. The reported empirical recovery on dense and MoE models indicates potential impact, but the absence of derivation steps, error bars, and ablation data in the abstract (and per the provided assessment) prevents confirming the theoretical or practical contribution.
major comments (3)
- [Abstract] Abstract: the central claim of an 'exact three-way decomposition' and 'additive components' is asserted without derivation steps or proof; the manuscript must supply the explicit equations showing that scale bias + deadzone truncation + grid noise equals the MXFP4 operator output, and that this equality is preserved after elementwise quantization enters the backward pass and RL objective.
- [Abstract] Abstract (and empirical section): no explicit check is reported that the sum of the three corrected errors equals the original MXFP4 error after a full RL step; the skeptic concern about cross terms arising from multiplicative scale bias accumulation and entropy/rollout interactions is load-bearing for the independence claim and must be addressed with a concrete verification (e.g., error summation after one or more training steps).
- [Abstract] Abstract: the empirical results on Qwen2.5-3B and Qwen3-30B-A3B-Base report recovery/exceedance of BF16 accuracy but supply no error-bar details, ablation data on individual corrections, or controls for whether corrections interact; this undermines the claim that each component dominates a distinct pathway.
minor comments (1)
- [Abstract] Abstract: the phrasing 'missing the distinct mechanisms upon interpreting how quantization error damages training' is unclear and should be reworded for precision.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below with clarifications from the full manuscript and indicate where revisions will be made to improve clarity, particularly in the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of an 'exact three-way decomposition' and 'additive components' is asserted without derivation steps or proof; the manuscript must supply the explicit equations showing that scale bias + deadzone truncation + grid noise equals the MXFP4 operator output, and that this equality is preserved after elementwise quantization enters the backward pass and RL objective.
Authors: The full manuscript (Section 3) contains the explicit derivation: MXFP4(x) = s * clip(round(x/s), grid) where s is the power-of-two scale, and the error is exactly partitioned as scale_bias = (s_rounded - s_true) * (x/s) + deadzone_truncation (values below threshold set to zero) + grid_noise (rounding residual to 4-bit levels), with the identity MXFP4(x) = x + scale_bias + deadzone + grid_noise holding elementwise by algebraic construction of the format. Because the decomposition is strictly elementwise and applied before any linear or nonlinear operations, it is preserved under the backward pass and enters the RL objective without additional cross terms at the quantization step itself. We will add the key equations and a one-sentence proof outline to the revised abstract. revision: yes
-
Referee: [Abstract] Abstract (and empirical section): no explicit check is reported that the sum of the three corrected errors equals the original MXFP4 error after a full RL step; the skeptic concern about cross terms arising from multiplicative scale bias accumulation and entropy/rollout interactions is load-bearing for the independence claim and must be addressed with a concrete verification (e.g., error summation after one or more training steps).
Authors: The decomposition is exact at the operator level, and the manuscript's empirical results show that the three targeted corrections (macro-block scaling, outlier fallback, AQN) together recover or exceed BF16 performance. However, the referee correctly notes that a direct post-RL-step summation check for residual cross terms is not reported. We will add a verification experiment (error-component summation after 1 and 5 RL steps on the Qwen2.5-3B run) to the empirical section and reference the result in the abstract to confirm that interactions remain negligible relative to the dominant terms. revision: yes
-
Referee: [Abstract] Abstract: the empirical results on Qwen2.5-3B and Qwen3-30B-A3B-Base report recovery/exceedance of BF16 accuracy but supply no error-bar details, ablation data on individual corrections, or controls for whether corrections interact; this undermines the claim that each component dominates a distinct pathway.
Authors: The full manuscript (Section 5 and Appendix) reports error bars from 3 independent seeds, per-correction ablations, and interaction controls (additive vs. joint application of the three fixes). These show that macro-block scaling primarily improves gradient accuracy, outlier fallback recovers rollout quality, and AQN controls entropy, with combined gains exceeding the sum of individuals by <0.3%. We will add a concise summary of these ablations and the error-bar ranges to the revised abstract while retaining the performance numbers. revision: yes
Circularity Check
No significant circularity; decomposition derived from MXFP4 format properties
full rationale
The paper claims to prove an exact three-way additive decomposition of MXFP4 quantization error into scale bias (power-of-two rounding), deadzone truncation (zeroing small values), and grid noise (nearest 4-bit grid rounding), with each tied to distinct RL pathways. This partitioning follows directly from the standard definition and mechanics of the MXFP4 format itself rather than any fitted parameter, self-citation chain, or ansatz smuggled from prior work. No equations reduce the claimed result to its inputs by construction, no predictions are statistically forced from subsets of data, and the empirical recovery on Qwen2.5-3B and Qwen3-30B models supplies independent validation. The derivation chain remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MXFP4 quantization error admits an exact additive decomposition into scale bias, deadzone truncation, and grid noise
Reference graph
Works this paper leans on
-
[1]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. QuaRot : Outlier-free 4-bit inference in rotated LLMs . In Advances in Neural Information Processing Systems, volume 37, 2024
2024
-
[2]
W. R. Bennett. Spectra of quantized signals. Bell System Technical Journal, 27 0 (3): 0 446--472, 1948
1948
-
[3]
Roberto L. Castro, Andrei Panferov, Soroush Tabesh, Oliver Sieberling, Jiale Chen, Mahdi Nikdan, Saleh Ashkboos, and Dan Alistarh. Quartet: Native FP4 training can be optimal for large language models. arXiv preprint arXiv:2505.14669, 2025
-
[4]
QuIP : 2-bit quantization of large language models with guarantees
Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher De Sa. QuIP : 2-bit quantization of large language models with guarantees. In Advances in Neural Information Processing Systems, volume 36, 2023
2023
-
[5]
Oscillation-reduced MXFP4 training for vision transformers
Yuxiang Chen, Haocheng Xi, Jun Zhu, and Jianfei Chen. Oscillation-reduced MXFP4 training for vision transformers. In International Conference on Machine Learning (ICML), 2025
2025
-
[6]
Unveiling the potential of quantization with MXFP4 : Strategies for quantization error reduction
Jatin Chhugani, Geonhwa Jeong, Bor-Yiing Su, Yunjie Pan, Hanmei Yang, Aayush Ankit, Jiecao Yu, Summer Deng, Yunqing Chen, Nadathur Satish, and Changkyu Kim. Unveiling the potential of quantization with MXFP4 : Strategies for quantization error reduction. arXiv preprint arXiv:2603.08713, 2026
-
[7]
FP4 all the way: Fully quantized training of LLMs
Brian Chmiel, Maxim Fishman, Ron Banner, and Daniel Soudry. FP4 all the way: Fully quantized training of LLMs . arXiv preprint arXiv:2505.19115, 2025
-
[8]
Grouped sequency-arranged rotation: Optimizing rotation transformation for quantization for free
Euntae Choi, Sumin Song, Woosang Lim, and Sungjoo Yoo. Grouped sequency-arranged rotation: Optimizing rotation transformation for quantization for free. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, pages 165--172, 2025. doi:10.18653/v1/2025.acl-srw.10
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Four Over Six: More Accurate NVFP4 Quantization with Adaptive Block Scaling
Jack Cook, Junxian Guo, Guangxuan Xiao, Yujun Lin, and Song Han. Four over six: More accurate NVFP4 quantization with adaptive block scaling. arXiv preprint arXiv:2512.02010, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale . In Advances in Neural Information Processing Systems, volume 35, 2022
2022
-
[12]
QLoRA : Efficient finetuning of quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA : Efficient finetuning of quantized LLMs . In Advances in Neural Information Processing Systems, volume 36, 2023
2023
-
[13]
SpQR : A sparse-quantized representation for near-lossless LLM weight compression
Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh. SpQR : A sparse-quantized representation for near-lossless LLM weight compression. In International Conference on Learning Representations, 2024
2024
-
[14]
Vage Egiazarian, Roberto L. Castro, Denis Kuznedelev, Andrei Panferov, Eldar Kurtic, Shubhra Pandit, Alexandre Noll Marques, Mark Kurtz, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Bridging the gap between promise and performance for microscaling FP4 quantization. In International Conference on Learning Representations, 2026. Introduces MR-GPTQ (mi...
-
[15]
Scaling FP8 training to trillion-token LLMs
Maxim Fishman, Brian Chmiel, Ron Banner, and Daniel Soudry. Scaling FP8 training to trillion-token LLMs . In International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=E1EHO0imOb
2025
-
[16]
Noisy networks for exploration
Meire Fortunato, Mohammad Gheshlaghi Azar, Bilal Piot, Jacob Menick, Matteo Hessel, Ian Osband, Alex Graves, Volodymyr Mnih, R \'e mi Munos, Demis Hassabis, Olivier Pietquin, Charles Blundell, and Shane Legg. Noisy networks for exploration. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=rywHCPkAW
2018
-
[17]
GPTQ : Accurate post-training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ : Accurate post-training quantization for generative pre-trained transformers. In International Conference on Learning Representations, 2023
2023
-
[18]
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, Tongkai Yang, Binhang Yuan, and Yi Wu. AReaL : A large-scale asynchronous reinforcement learning system for language reasoning. arXiv preprint arXiv:2505.24298, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Deep learning with limited numerical precision
Suyog Gupta, Ankur Agrawal, Kailash Gopalakrishnan, and Pritish Narayanan. Deep learning with limited numerical precision. In Proceedings of the 32nd International Conference on Machine Learning (ICML), volume 37, pages 1737--1746, 2015. URL http://proceedings.mlr.press/v37/gupta15.html
2015
-
[20]
Low-precision training of large language models: Methods, challenges, and opportunities
Zhiwei Hao, Jianyuan Guo, Li Shen, Yong Luo, Han Hu, Guoxia Wang, Dianhai Yu, Yonggang Wen, and Dacheng Tao. Low-precision training of large language models: Methods, challenges, and opportunities. arXiv preprint arXiv:2505.01043, 2025
-
[21]
Towards fully FP8 GEMM LLM training at scale
Alejandro Hern \'a ndez-Cano, Dhia Garbaya, Imanol Schlag, and Martin Jaggi. Towards fully FP8 GEMM LLM training at scale. arXiv preprint arXiv:2505.20524, 2025
-
[22]
QeRL : Beyond efficiency---quantization-enhanced reinforcement learning for LLMs
Wei Huang, Yi Ge, Shuai Yang, Yicheng Xiao, Huizi Mao, Yujun Lin, Hanrong Ye, Sifei Liu, Ka Chun Cheung, Hongxu Yin, Yao Lu, Xiaojuan Qi, Song Han, and Yukang Chen. QeRL : Beyond efficiency---quantization-enhanced reinforcement learning for LLMs . In International Conference on Learning Representations, 2026
2026
-
[23]
Mahoney, and Kurt Keutzer
Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, and Kurt Keutzer. SqueezeLLM : Dense-and-sparse quantization. In Proceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[24]
ParoQuant : Pairwise rotation quantization for efficient reasoning LLM inference
Yesheng Liang, Haisheng Chen, Song Han, and Zhijian Liu. ParoQuant : Pairwise rotation quantization for efficient reasoning LLM inference. arXiv preprint arXiv:2511.10645, 2025
-
[25]
AWQ : Activation-aware weight quantization for on-device LLM compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ : Activation-aware weight quantization for on-device LLM compression and acceleration. In Proceedings of Machine Learning and Systems, volume 6, 2024
2024
-
[26]
Llm-qat: Data-free quantization aware training for large language models
Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, and Vikas Chandra. Llm-qat: Data-free quantization aware training for large language models. In Findings of the Association for Computational Linguistics: ACL 2024, pages 467--484, 2024
2024
-
[27]
SpinQuant : LLM quantization with learned rotations
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. SpinQuant : LLM quantization with learned rotations. In International Conference on Learning Representations, 2025
2025
-
[28]
Paulius Micikevicius, Dusan Stosic, Neil Burgess, Marius Cornea, Pradeep Dubey, Richard Grisenthwaite, Sangwon Ha, Alexander Heinecke, Patrick Judd, John Kamalu, Naveen Mellempudi, Stuart F. Oberman, Mohammad Shoeybi, Michael Y. Siu, and Hao Wu. FP8 formats for deep learning. arXiv preprint arXiv:2209.05433, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Adding Gradient Noise Improves Learning for Very Deep Networks
Arvind Neelakantan, Luke Vilnis, Quoc V. Le, Ilya Sutskever, Lukasz Kaiser, Karol Kurach, and James Martens. Adding gradient noise improves learning for very deep networks. arXiv preprint arXiv:1511.06807, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[30]
Pretraining large language models with NVFP4
NVIDIA . Pretraining large language models with NVFP4 . arXiv preprint arXiv:2509.25149, 2025
-
[31]
Quartet II : Accurate LLM pre-training in NVFP4 by improved unbiased gradient estimation
Andrei Panferov, Erik Schultheis, Soroush Tabesh, and Dan Alistarh. Quartet II : Accurate LLM pre-training in NVFP4 by improved unbiased gradient estimation. arXiv preprint arXiv:2601.22813, 2026
-
[32]
Outlier-safe pre-training for robust 4-bit quantization of large language models
Jungwoo Park, Taewhoo Lee, Chanwoong Yoon, Hyeon Hwang, and Jaewoo Kang. Outlier-safe pre-training for robust 4-bit quantization of large language models. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), pages 12582--12600, 2025
2025
-
[33]
OCP microscaling formats ( MX ) specification
Bita Darvish Rouhani, Ritchie Zhao, Ankit More, Mathew Hall, Alireza Khodamoradi, Summer Deng, Dhruv Choudhary, Marius Cornea, Eric Dellinger, Kristof Denolf, et al. OCP microscaling formats ( MX ) specification. Open Compute Project, 2023
2023
-
[34]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath : Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
QuIP\# : Even better LLM quantization with hadamard incoherence and lattice codebooks
Albert Tseng, Jerry Chee, Qingyao Sun, Volodymyr Kuleshov, and Christopher De Sa. QuIP\# : Even better LLM quantization with hadamard incoherence and lattice codebooks. In Proceedings of the 41st International Conference on Machine Learning, 2024 a
2024
-
[36]
QTIP : Quantization with trellises and incoherence processing
Albert Tseng, Qingyao Sun, David Hou, and Christopher De Sa. QTIP : Quantization with trellises and incoherence processing. In Advances in Neural Information Processing Systems, volume 37, 2024 b
2024
-
[37]
Training llms with mxfp4, 2025
Albert Tseng, Tao Yu, and Youngsuk Park. Training llms with mxfp4, 2025. URL https://arxiv.org/abs/2502.20586
-
[38]
Quantization Noise: Roundoff Error in Digital Computation, Signal Processing, Control, and Communications
Bernard Widrow and Istv \'a n Koll \'a r. Quantization Noise: Roundoff Error in Digital Computation, Signal Processing, Control, and Communications. Cambridge University Press, 2008. ISBN 978-0-521-88671-0
2008
-
[39]
SmoothQuant : Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant : Accurate and efficient post-training quantization for large language models. In Proceedings of the 40th International Conference on Machine Learning, 2023
2023
-
[40]
Your efficient rl framework secretly brings you off-policy rl training, August 2025
Feng Yao, Liyuan Liu, Dinghuai Zhang, Chengyu Dong, Jingbo Shang, and Jianfeng Gao. Your efficient rl framework secretly brings you off-policy rl training, August 2025. URL https://fengyao.notion.site/off-policy-rl
2025
-
[41]
ZeroQuant : Efficient and affordable post-training quantization for large-scale transformers
Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xiaoxia Wu, Conglong Li, and Yuxiong He. ZeroQuant : Efficient and affordable post-training quantization for large-scale transformers. In Advances in Neural Information Processing Systems, volume 35, pages 27168--27183, 2022
2022
-
[42]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, et al. DAPO : An open-source LLM reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Accurate INT8 training through dynamic block-level fallback
Pengle Zhang, Jia Wei, Jintao Zhang, Jun Zhu, and Jianfei Chen. Accurate INT8 training through dynamic block-level fallback. arXiv preprint arXiv:2503.08040, 2025
-
[44]
Practical FP4 training for large-scale MoE models on hopper GPUs
Wuyue Zhang, Chongdong Huang, Chunbo You, Cheng Gu, Fengjuan Wang, and Mou Sun. Practical FP4 training for large-scale MoE models on hopper GPUs . arXiv preprint arXiv:2603.02731, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.