Causal Inference with Multiple Misclassified Exposures: A Control Variate-Adjusted Calibration Weighting Approach
Pith reviewed 2026-06-26 07:12 UTC · model grok-4.3
The pith
Calibration weighting that treats misclassification as missing data, combined with control variates, produces doubly robust causal estimates for multiple binary exposures without modeling the error process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
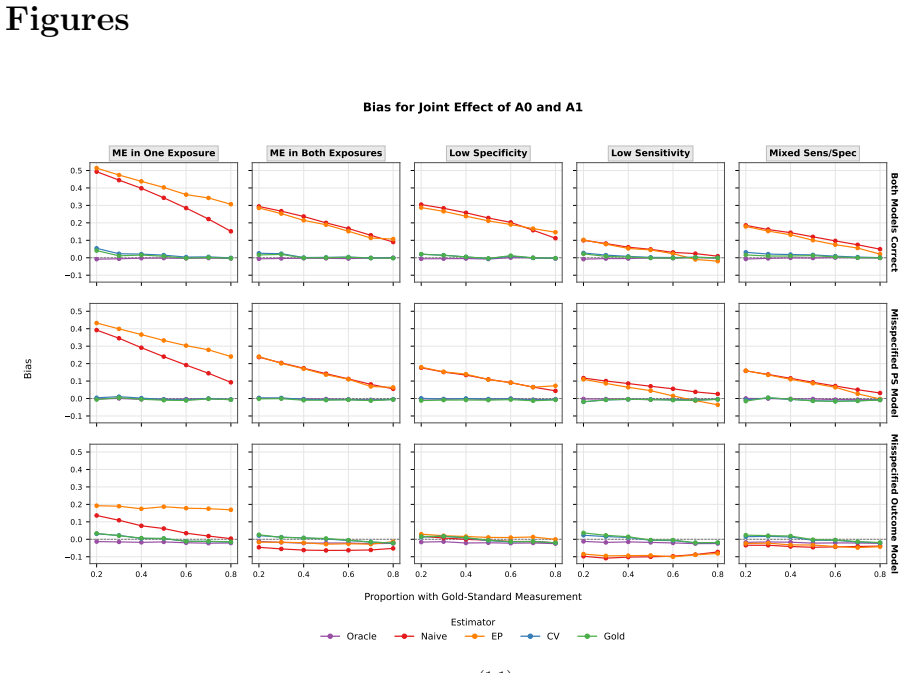
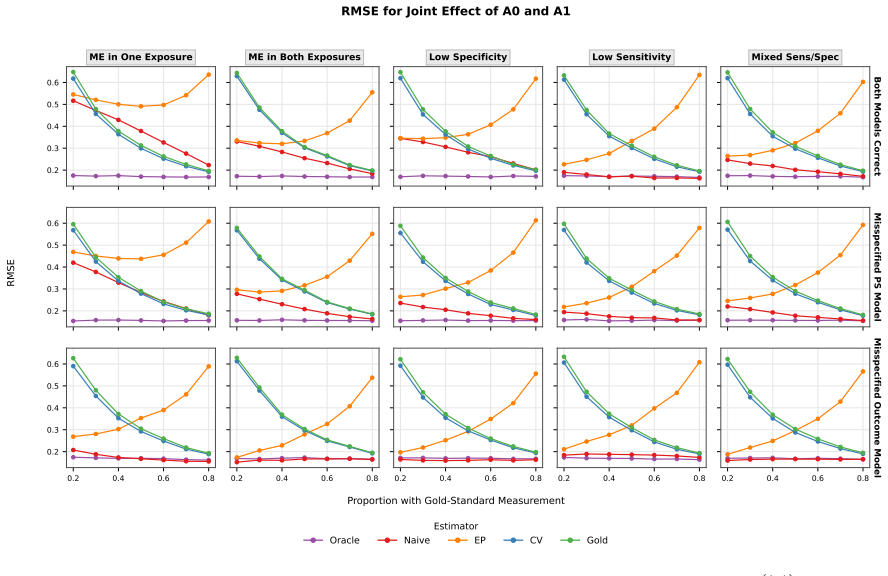
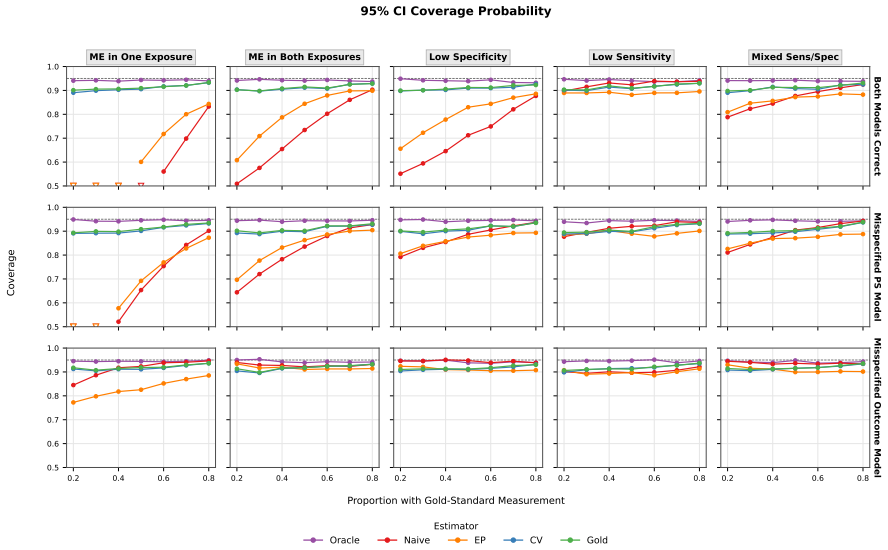
We develop calibration weighting and control variate estimators for causal inference with multiple misclassified binary exposures and clustered observations. The calibration approach treats misclassification as a missing data problem, achieving consistency without modelling the misclassification mechanism. The control variate adjustment integrates information from error-prone observations to reduce variance while preserving the consistency of the gold-standard estimator. We show that the resulting estimator inherits double robustness from its component estimators. We also characterize a structural ceiling on efficiency gains in the bivariate setting, where joint correct classification of bot
What carries the argument
Calibration weighting estimator that recasts misclassification as missing data, adjusted by control variates drawn from the error-prone measurements.
If this is right
- The estimator remains consistent for the causal effect even if the outcome or exposure model is misspecified, provided the calibration weights are correctly formed.
- Double robustness holds for the combined control-variate version.
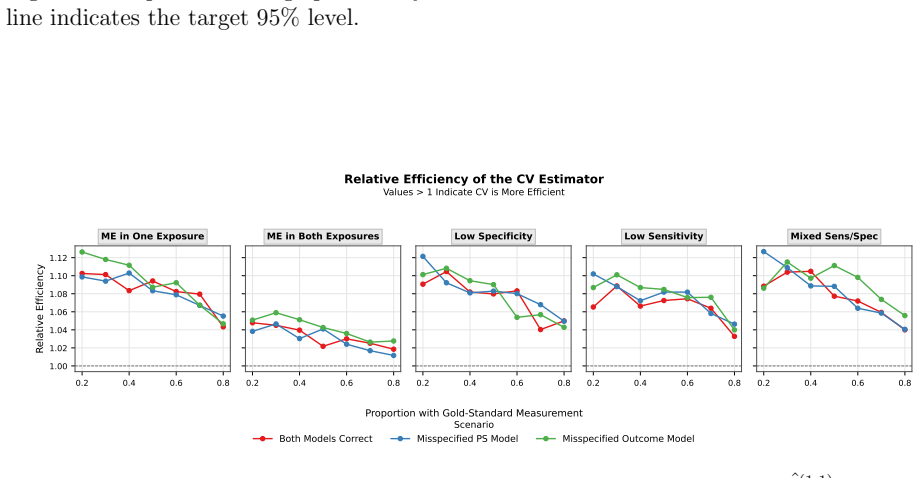
- In the two-exposure case, the maximum variance reduction is bounded by the joint probability that both exposures are correctly classified.
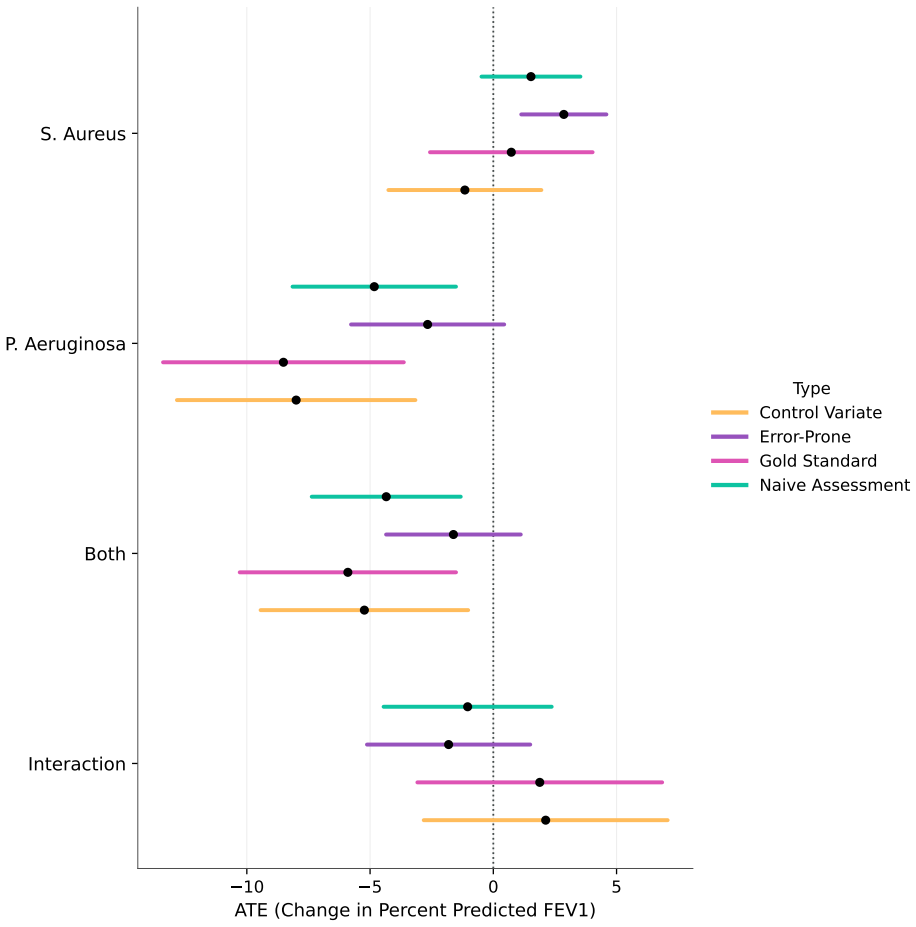
- Application to the cystic fibrosis cohort shows swab-based estimates of the Pseudomonas effect on FEV1 are attenuated by about 69 percent relative to sputum-based estimates.
Where Pith is reading between the lines
- The missing-data framing may extend naturally to settings with three or more misclassified binary exposures if the calibration step can be generalized.
- The efficiency ceiling implies that pairing a high-quality but expensive measure with a cheap noisy one will yield smaller gains when the two exposures are strongly associated.
- The approach could be tested in other clustered observational studies where multiple risk factors are recorded with different levels of accuracy, such as electronic health records.
Load-bearing premise
Misclassification can be handled as a missing-data problem that yields consistent estimates without any model for how the errors arise.
What would settle it
A data-generating process in which the gold-standard observations are a random subsample but the probability of correct classification depends on factors unobserved in the calibration step, producing persistent bias in the weighted estimator.
Figures
read the original abstract
Exposure misclassification is a common concern in studies of respiratory infections in cystic fibrosis. Throat swabs are frequently used in place of expectorated or induced sputum cultures, although they have imperfect sensitivity and specificity to detect Pseudomonas aeruginosa and Staphylococcus aureus. We develop calibration weighting and control variate estimators for causal inference with multiple misclassified binary exposures and clustered observations. The calibration approach treats misclassification as a missing data problem, achieving consistency without modelling the misclassification mechanism. The control variate adjustment integrates information from error-prone observations to reduce variance while preserving the consistency of the gold-standard estimator. We show that the resulting estimator inherits double robustness from its component estimators. We also characterize a structural ceiling on efficiency gains in the bivariate setting, where joint correct classification of both exposures limits the variance reduction achievable relative to univariate applications. Simulation studies confirm the consistency and double robustness of the proposed estimators under model misspecification. We then apply these methods to a cohort of $651$ cystic fibrosis patients ages $6$-$21$. Swab-based estimates attenuate the effect of P. aeruginosa on percent predicted FEV$_1$ by approximately $69\%$ relative to sputum-based estimates ($-2.67$ vs. $-8.52$ percentage points; $95\%$ CI for sputum: $-13.40$, $-3.63$). These findings suggest that relying on throat swabs may lead to under-treatment of P. aeruginosa infections. More broadly, the methods provide a framework for causal inference with multiple misclassified exposures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops calibration weighting and control variate estimators for causal inference with multiple misclassified binary exposures under clustered sampling. It treats misclassification as a missing-data problem to obtain consistency without modeling the error mechanism, shows that the combined estimator inherits double robustness, derives a structural bound on efficiency gains in the bivariate case, validates the properties via simulations under misspecification, and applies the methods to cystic fibrosis data to demonstrate attenuation of the P. aeruginosa effect on FEV1 when using throat swabs versus sputum.
Significance. If the consistency and double-robustness claims hold under clustering, the work supplies a practical, assumption-light framework for a common problem in respiratory epidemiology and similar clustered studies with error-prone binary exposures. The inheritance of double robustness and the explicit characterization of the bivariate efficiency ceiling are theoretically attractive features; the real-data illustration quantifies the practical consequences of misclassification.
major comments (2)
- [methods (calibration weighting derivation)] The consistency claim rests on treating misclassification as missing data so that calibration weighting delivers consistency without an explicit error model. With clustered observations and two binary exposures, the missingness indicators are plausibly dependent within clusters. The calibration equations (methods section deriving the weights) appear to be written under an independence assumption for the missingness indicators; no cluster-level calibration or cluster-robust adjustment to the estimating equations is described. This directly threatens the consistency and double-robustness inheritance when within-cluster dependence is present.
- [theoretical results on double robustness] The double-robustness result is stated to be inherited from the component estimators. The paper should explicitly verify that the inheritance continues to hold once the calibration step is applied to the joint distribution of two misclassified exposures under clustering, rather than relying solely on the univariate or independent-missingness case.
minor comments (2)
- [application results] The abstract and application section report point estimates and a 95% CI for the sputum-based analysis but do not state the variance estimator or whether clustering is accounted for in the reported intervals.
- [notation] Notation for the multiple-exposure calibration weights and the control-variate adjustment should be introduced with a single consolidated table or display equation to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below, indicating the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [methods (calibration weighting derivation)] The consistency claim rests on treating misclassification as missing data so that calibration weighting delivers consistency without an explicit error model. With clustered observations and two binary exposures, the missingness indicators are plausibly dependent within clusters. The calibration equations (methods section deriving the weights) appear to be written under an independence assumption for the missingness indicators; no cluster-level calibration or cluster-robust adjustment to the estimating equations is described. This directly threatens the consistency and double-robustness inheritance when within-cluster dependence is present.
Authors: We appreciate the referee's identification of this potential gap. The calibration equations in the current manuscript are derived marginally at the individual level to target the required moments without an explicit misclassification model. While this delivers consistency under the stated assumptions, we acknowledge that within-cluster dependence in the missingness indicators is not explicitly addressed in the estimating equations. In the revision we will augment the calibration step with cluster-robust adjustments to the estimating equations and will add a brief theoretical note clarifying that consistency is retained under cluster dependence provided the calibration variables remain correctly specified. We will also include a targeted simulation experiment with dependent missingness within clusters to confirm finite-sample behavior. revision: yes
-
Referee: [theoretical results on double robustness] The double-robustness result is stated to be inherited from the component estimators. The paper should explicitly verify that the inheritance continues to hold once the calibration step is applied to the joint distribution of two misclassified exposures under clustering, rather than relying solely on the univariate or independent-missingness case.
Authors: We agree that an explicit verification under joint misclassification and clustering strengthens the theoretical contribution. The current manuscript relies on the inheritance property from the univariate control-variate and calibration estimators, but does not re-derive the cancellation of bias terms for the bivariate clustered case. In the revised version we will add a short appendix subsection that explicitly shows the double-robustness property continues to hold when the calibration weights are obtained from the joint observed-data distribution and the estimating equations are cluster-robust. The argument follows the same bias-cancellation logic as the univariate case once the joint calibration moments are correctly targeted. revision: yes
Circularity Check
No circularity; derivation extends established calibration and control-variate methods without self-referential reduction
full rationale
The paper treats misclassification as a missing-data problem to obtain consistency via calibration weighting, then augments with control variates while inheriting double robustness from the component estimators. These steps rest on standard missing-data and weighting theory applied to the clustered bivariate setting; the structural efficiency ceiling is derived from the joint classification probabilities rather than from any quantity fitted inside the present manuscript. No equation or claim reduces by construction to a parameter defined by the paper's own data or to a self-citation whose validity is presupposed. The central consistency and robustness results therefore remain independent of the target dataset's fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Misclassification can be treated as a missing data problem to achieve consistency without modeling the misclassification mechanism
Reference graph
Works this paper leans on
-
[1]
Cystic fibrosis
Abdulghani Sankari and Sandeep Sharma. Cystic fibrosis. InStatPearls. StatPearls Publishing, Treasure Island, FL, 2024
2024
-
[2]
Clinical sig- nificance of microbial infection and adaptation in cystic fibrosis.Clinical Microbiology Reviews, 24(1):29–70, 2011
Alan R Hauser, Manu Jain, Maskit Bar-Meir, and Susanna A McColley. Clinical sig- nificance of microbial infection and adaptation in cystic fibrosis.Clinical Microbiology Reviews, 24(1):29–70, 2011
2011
-
[3]
Nathan Ward, Kathy Stiller, and Anne E Holland. Exercise and airway clearance tech- niques in cystic fibrosis.Seminars in Respiratory and Critical Care Medicine, 44(2): 209–216, 2023. doi: 10.1055/s-0042-1758729
-
[4]
David P Nichols, Sarah J Morgan, Michelle Skalland, Anh T Vo, Jill M Van Dalfsen, Sachinkumar B P Singh, Wendy Ni, Lucas R Hoffman, Kailee McGeer, Sonya L Heltshe, John P Clancy, Steven M Rowe, Peter Jorth, and Pradeep K Singh. Pharmacologic improvement of CFTR function rapidly decreases sputum pathogen density, but lung infections generally persist.Journ...
-
[5]
New drugs, new challenges in cystic fibrosis care.European Respiratory Review, 33(173):240045, 2024
Isabelle Fajac, Pierre-R´ egis Burgel, and Cl´ emence Martin. New drugs, new challenges in cystic fibrosis care.European Respiratory Review, 33(173):240045, 2024. doi: 10. 1183/16000617.0045-2024
arXiv 2024
-
[6]
Jordana E Hoppe, Elinor Towler, Brandie D Wagner, Frank J Accurso, Scott D Sagel, and Edith T Zemanick. Sputum induction improves detection of pathogens in children with cystic fibrosis.Pediatric Pulmonology, 50(7):638–646, 2015. doi: 10.1002/ppul. 23150. 25
doi:10.1002/ppul 2015
-
[7]
Respiratory bacterial culture sampling in expectorating and non- expectorating patients with cystic fibrosis.Frontiers in Pediatrics, 6:403, 2018
Hanneke Eyns, Denis Pi´ erard, Elke De Wachter, Leo Eeckhout, Peter Vaes, and Anne Malfroot. Respiratory bacterial culture sampling in expectorating and non- expectorating patients with cystic fibrosis.Frontiers in Pediatrics, 6:403, 2018
2018
-
[8]
Helen Gavillet, Lauren Hatfield, Damian Rivett, Andrew Jones, Anirban Maitra, Alexander Horsley, and Christopher van der Gast. Bacterial culture underestimates lung pathogen detection and infection status in cystic fibrosis.Microbiology Spectrum, 10(5):e00419–22, 2022. doi: 10.1128/spectrum.00419-22
-
[9]
Measurement error in nonlinear models: A modern perspective
Raymond J Carroll, David Ruppert, Leonard A Stefanski, and Ciprian M Crainiceanu. Measurement error in nonlinear models: A modern perspective. Chapman and Hal- l/CRC, 2006
2006
-
[10]
Kevin P Josey, Priyanka DeSouza, Xiao Wu, Danielle Braun, and Rachel Nethery. Estimating a causal exposure response function with a continuous error-prone exposure: A study of fine particulate matter and all-cause mortality.Journal of Agricultural, Biological and Environmental Statistics, 28(1):20–41, 2023
2023
-
[11]
Propensity scores with misclassified treatment assignment: a likelihood-based adjustment.Biostatistics, 18(4):695–710, 2017
Danielle Braun, Malka Gorfine, Giovanni Parmigiani, Nils D Arvold, Francesca Do- minici, and Corwin Zigler. Propensity scores with misclassified treatment assignment: a likelihood-based adjustment.Biostatistics, 18(4):695–710, 2017
2017
-
[12]
Causal inference in the context of an error prone exposure: Air pollution and mortality.The Annals of Applied Statistics, 13(1):520–547, 2019
Xiao Wu, Danielle Braun, Marianthi-Anna Kioumourtzoglou, Christine Choirat, Qian Di, and Francesca Dominici. Causal inference in the context of an error prone exposure: Air pollution and mortality.The Annals of Applied Statistics, 13(1):520–547, 2019
2019
-
[13]
Justin R Williams and Catherine M Crespi. Causal inference for multiple contin- uous exposures via the multivariate generalized propensity score.arXiv preprint arXiv:2008.13767, 2020
arXiv 2008
-
[14]
An imputation-based solution to using mismeasured covariates in propensity score analysis.Statistical Methods in Medical Research, 26(4):1824–1837, 2017
Yenny Webb-Vargas, Kara E Rudolph, David Lenis, Peter Murakami, and Elizabeth A 26 Stuart. An imputation-based solution to using mismeasured covariates in propensity score analysis.Statistical Methods in Medical Research, 26(4):1824–1837, 2017
2017
-
[15]
Edward H Kennedy. Towards optimal doubly robust estimation of heterogeneous causal effects.Electronic Journal of Statistics, 17(2):3008–3049, 2023. Earlier arXiv preprint: 2004.14497, 2020
arXiv 2023
-
[16]
Connections between survey calibration estimators and semiparametric models for incomplete data.International Statistical Review, 79(2):200–220, 2011
Thomas Lumley, Pamela A Shaw, and James Y Dai. Connections between survey calibration estimators and semiparametric models for incomplete data.International Statistical Review, 79(2):200–220, 2011
2011
-
[17]
All your data are always miss- ing: incorporating bias due to measurement error into the potential outcomes frame- work.International Journal of Epidemiology, 44(4):1452–1459, 2015
Jessie K Edwards, Stephen R Cole, and Daniel Westreich. All your data are always miss- ing: incorporating bias due to measurement error into the potential outcomes frame- work.International Journal of Epidemiology, 44(4):1452–1459, 2015
2015
-
[18]
Im- proving trial generalizability using observational studies.Biometrics, 79(2):1213–1225,
Dasom Lee, Shu Yang, Lin Dong, Xiaofei Wang, Donglin Zeng, and Jianwen Cai. Im- proving trial generalizability using observational studies.Biometrics, 79(2):1213–1225,
-
[19]
doi: 10.1111/biom.13609
-
[20]
Combining multiple observational data sources to estimate causal effects.Journal of the American Statistical Association, 115(531):1540–1554, 2020
Shu Yang and Peng Ding. Combining multiple observational data sources to estimate causal effects.Journal of the American Statistical Association, 115(531):1540–1554, 2020
2020
-
[21]
Flexible and efficient estimation of causal effects with error-prone ex- posures: a control variates approach for measurement error.Biometrics, 81(4):ujaf151, 2025
Keith Barnatchez, Rachel Nethery, Bryan E Shepherd, Giovanni Parmigiani, and Kevin P Josey. Flexible and efficient estimation of causal effects with error-prone ex- posures: a control variates approach for measurement error.Biometrics, 81(4):ujaf151, 2025
2025
-
[22]
Estimating causal effects of treatments in randomized and nonran- domized studies.Journal of Educational Psychology, 66(5):688–701, 1974
Donald B Rubin. Estimating causal effects of treatments in randomized and nonran- domized studies.Journal of Educational Psychology, 66(5):688–701, 1974. 27
1974
-
[23]
Causal interaction in factorial experiments: Application to conjoint analysis.Journal of the American Statistical Association, 114(526):529–540,
Naoki Egami and Kosuke Imai. Causal interaction in factorial experiments: Application to conjoint analysis.Journal of the American Statistical Association, 114(526):529–540,
-
[24]
doi: 10.1080/01621459.2018.1476246
-
[25]
Calibration estimators in survey sampling
Jean-Claude Deville and Carl-Erik S¨ arndal. Calibration estimators in survey sampling. Journal of the American Statistical Association, 87(418):376–382, 1992
1992
-
[26]
Semiparametric efficiency in multivariate re- gression models with missing data.Journal of the American Statistical Association, 90 (429):122–129, 1995
James M Robins and Andrea Rotnitzky. Semiparametric efficiency in multivariate re- gression models with missing data.Journal of the American Statistical Association, 90 (429):122–129, 1995
1995
-
[27]
Doubly robust estimation in missing data and causal inference models.Biometrics, 61(4):962–973, 2005
Heejung Bang and James M Robins. Doubly robust estimation in missing data and causal inference models.Biometrics, 61(4):962–973, 2005
2005
-
[28]
Doubly robust estimation of causal effects.American Journal of Epidemiology, 173(7):761–767, 2011
Michele Jonsson Funk, Daniel Westreich, Chris Wiesen, Til St¨ urmer, M Alan Brookhart, and Marie Davidian. Doubly robust estimation of causal effects.American Journal of Epidemiology, 173(7):761–767, 2011
2011
-
[29]
Kyunghee Han, Pamela A Shaw, and Thomas Lumley. Combining multiple imputation with raking of weights: An efficient and robust approach in the setting of nearly true models.Statistics in Medicine, 40(30):6777–6791, 2021. doi: 10.1002/sim.9210
doi:10.1002/sim.9210 2021
-
[30]
Kevin P Josey, Elizabeth Juarez-Colunga, Fan Yang, and Debashis Ghosh. A framework for covariate balance using Bregman distances.Scandinavian Journal of Statistics, 48 (3):790–816, 2021. doi: 10.1111/sjos.12457
-
[31]
Generalized raking pro- cedures in survey sampling.Journal of the American Statistical Association, 88(423): 1013–1020, 1993
Jean-Claude Deville, Carl-Erik S¨ arndal, and Olivier Sautory. Generalized raking pro- cedures in survey sampling.Journal of the American Statistical Association, 88(423): 1013–1020, 1993
1993
-
[32]
Kevin P Josey, Seth A Berkowitz, Debashis Ghosh, and Sridharan Raghavan. Trans- 28 porting experimental results with entropy balancing.Statistics in Medicine, 40(19): 4310–4326, 2021. doi: 10.1002/sim.9031
doi:10.1002/sim.9031 2021
-
[33]
Kevin P Josey, Fan Yang, Debashis Ghosh, and Sridharan Raghavan. A calibration approach to transportability and data-fusion with observational data.Statistics in Medicine, 41(23):4511–4531, 2022. doi: 10.1002/sim.9523
doi:10.1002/sim.9523 2022
-
[34]
Multivariate adaptive regression splines.The Annals of Statistics, 19(1):1–67, 1991
Jerome H Friedman. Multivariate adaptive regression splines.The Annals of Statistics, 19(1):1–67, 1991
1991
-
[35]
An introduction to g methods
Ashley I Naimi, Stephen R Cole, and Edward H Kennedy. An introduction to g methods. International Journal of Epidemiology, 46(2):756–762, 2017
2017
-
[36]
Object-oriented computation of sandwich estimators.Journal of Statis- tical Software, 16(9):1–16, 2006
Achim Zeileis. Object-oriented computation of sandwich estimators.Journal of Statis- tical Software, 16(9):1–16, 2006
2006
-
[37]
Efficiency of multivariate control variates in Monte Carlo simulation.Operations Research, 33(3):661–677, 1985
Reuven Y Rubinstein and Ruth Marcus. Efficiency of multivariate control variates in Monte Carlo simulation.Operations Research, 33(3):661–677, 1985
1985
-
[38]
Duxbury/Thomson Learning, Pacific Grove, CA, 2nd edition, 2002
George Casella and Roger L Berger.Statistical Inference. Duxbury/Thomson Learning, Pacific Grove, CA, 2nd edition, 2002
2002
-
[39]
Use of FEV1 in cystic fibrosis epidemiologic studies and clinical trials: a statistical perspective for the clinical researcher.Journal of Cystic Fibrosis, 16(3):318–326, 2017
Rhonda Szczesniak, Sonya L Heltshe, Sanja Stanojevic, and Nicole Mayer-Hamblett. Use of FEV1 in cystic fibrosis epidemiologic studies and clinical trials: a statistical perspective for the clinical researcher.Journal of Cystic Fibrosis, 16(3):318–326, 2017
2017
-
[40]
Multi- ethnic reference values for spirometry for the 3–95-yr age range: the global lung function 2012 equations.European Respiratory Journal, 40(6):1324–1343, 2012
Philip H Quanjer, Sanja Stanojevic, Tim J Cole, Xaver Baur, Graham L Hall, Bruce H Culver, Paul L Enright, John L Hankinson, Mary SM Ip, Jinping Zheng, et al. Multi- ethnic reference values for spirometry for the 3–95-yr age range: the global lung function 2012 equations.European Respiratory Journal, 40(6):1324–1343, 2012
2012
-
[41]
Keith Barnatchez, Kevin P Josey, Nima S Hejazi, Bryan E Shepherd, Giovanni Parmigiani, and Rachel C Nethery. Efficient estimation of causal effects under two- 29 phase sampling with error-prone outcome and treatment measurements, 2025. URL https://arxiv.org/abs/2506.21777. 30 Tables Sputum (N= 5,434) Throat Swab (N= 7,537) Percent Predicted FEV1 Mean (SD)...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.