Energy-Structured Low-Rank Adaptation for Continual Learning
Pith reviewed 2026-06-29 19:35 UTC · model grok-4.3
The pith
Output feature drift from parameter updates is inherently low-rank, and preserving along principal directions minimizes output reconstruction error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
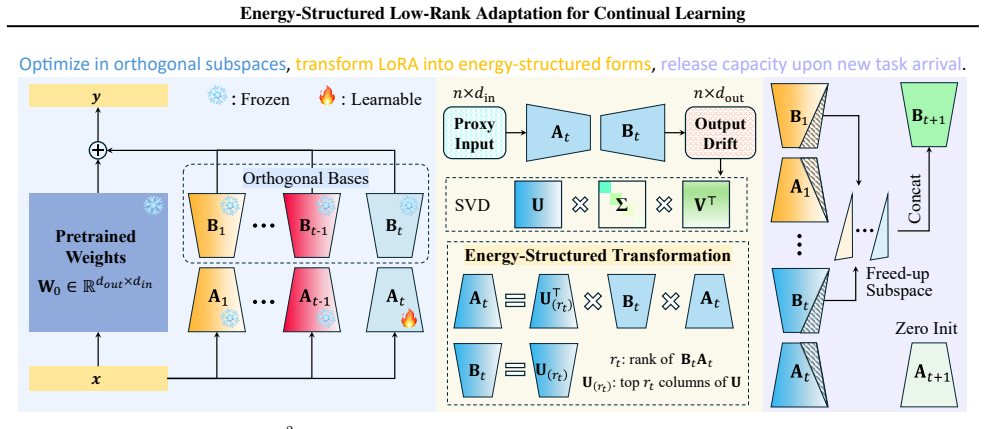
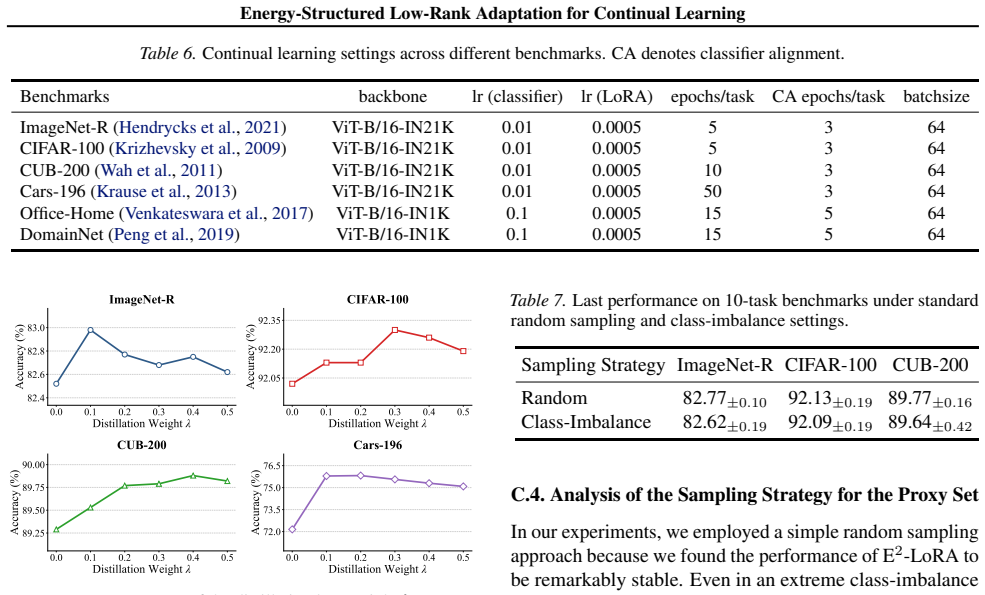
Output feature drift induced by parameter updates is inherently low-rank, and preserving parameters along the principal directions of this drift minimizes the output reconstruction error. Motivated by this observation, E²-LoRA explicitly orders and concentrates knowledge into leading ranks while a dynamic rank-allocation strategy jointly optimizes energy retention and model plasticity.
What carries the argument
E²-LoRA (Energy-Concentrated and Energy-Ordered Low-Rank Adaptation), which concentrates and orders knowledge into the leading ranks of each low-rank update and uses dynamic allocation to balance retained energy against plasticity.
If this is right
- Concentrating energy into leading ranks frees usable capacity for later tasks instead of diffusing it across the entire basis.
- Dynamic rank allocation automatically trades off stability on past tasks against plasticity on new tasks.
- The low-rank property removes the need for explicit orthogonal constraints used in prior subspace methods.
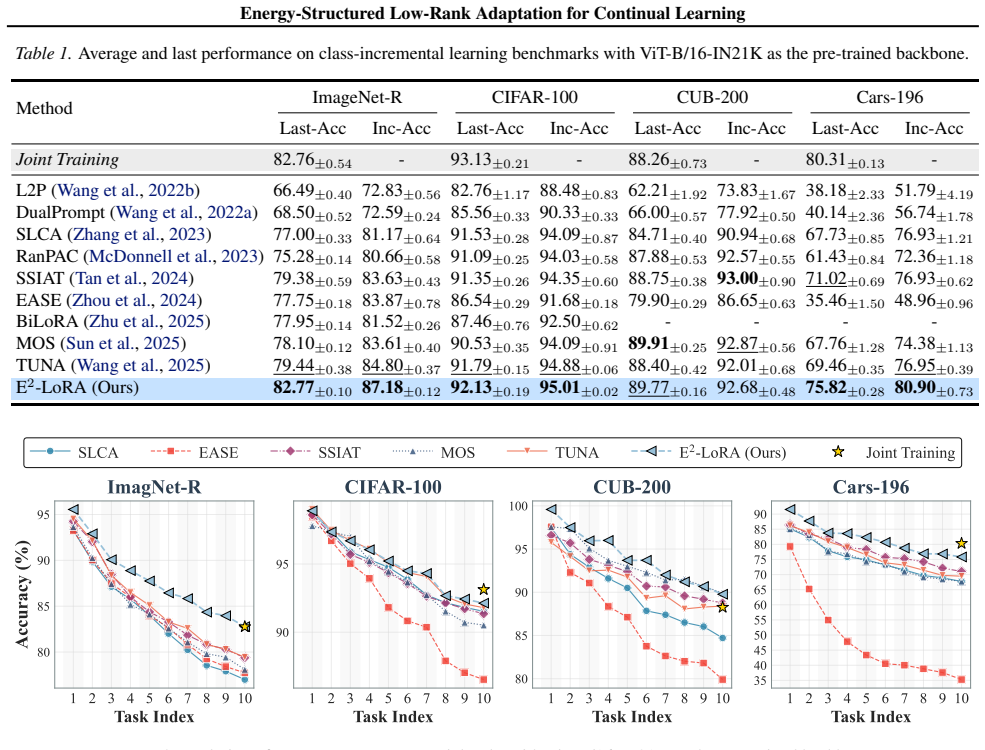
- State-of-the-art performance is obtained on standard continual-learning benchmarks without architecture-specific hyper-parameter search.
Where Pith is reading between the lines
- If the low-rank drift property holds for other adaptation modules, the same energy-ordering idea could be applied beyond LoRA-style updates.
- Long task sequences would benefit most because capacity exhaustion is delayed by repeated concentration into the top ranks.
- An online estimator of the principal drift directions could remove the need to store full drift matrices during training.
Load-bearing premise
Output feature drift remains inherently low-rank across architectures, datasets, and task sequences, and dynamic rank allocation can be optimized jointly for energy retention and plasticity without task-specific tuning.
What would settle it
An experiment on any architecture or dataset sequence where the measured output feature drift matrix has high effective rank and where keeping only its principal directions fails to minimize reconstruction error would falsify the central claim.
Figures

read the original abstract
While orthogonal subspace methods try to mitigate task interference in Continual Learning (CL), they often suffer from energy diffusion across the basis, hindering knowledge compaction and exhausting capacity for future tasks. We observe that output feature drift induced by parameter updates is inherently low-rank, and theoretically prove that preserving parameters along the principal directions of this drift minimizes the output reconstruction error. Motivated by this, we propose \textbf{E}nergy-Concentrated and \textbf{E}nergy-Ordered \textbf{Lo}w-\textbf{R}ank \textbf{A}daptation (E$^2$-LoRA). By explicitly ordering and concentrating knowledge into leading ranks, E$^2$-LoRA frees capacity for subsequent tasks. Furthermore, we design a dynamic rank allocation strategy to balance stability and plasticity by jointly optimizing energy retention and model plasticity. Extensive experiments across multiple benchmarks demonstrate that E$^2$-LoRA achieves state-of-the-art performance. Code is available at https://github.com/kiddo127/E2-LoRA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that output feature drift induced by parameter updates is inherently low-rank, and provides a theoretical proof that preserving parameters along the principal directions of this drift minimizes output reconstruction error. Motivated by this, it introduces E²-LoRA, which explicitly orders and concentrates knowledge into leading ranks of low-rank adaptations while using a dynamic rank allocation strategy to jointly optimize energy retention and plasticity, achieving state-of-the-art results on continual learning benchmarks.
Significance. If the low-rank drift property and associated minimization hold with sufficient concentration across settings, the approach could meaningfully advance orthogonal-subspace continual learning methods by addressing energy diffusion and freeing capacity more systematically than prior low-rank adaptations. The public code release supports reproducibility.
major comments (3)
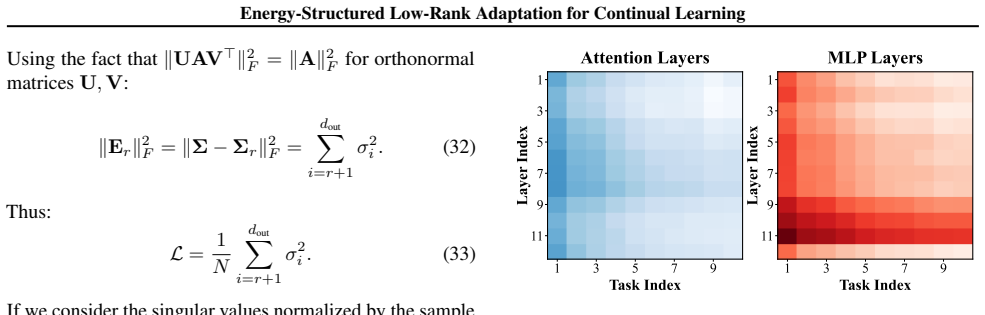
- [§3] §3 (theoretical analysis): the central claim that output feature drift is 'inherently low-rank' and that principal-direction preservation minimizes reconstruction error is load-bearing for the entire method, yet the provided text contains no derivation steps, explicit assumptions on the drift matrix, or singular-value decay analysis; without these the proof cannot be evaluated.
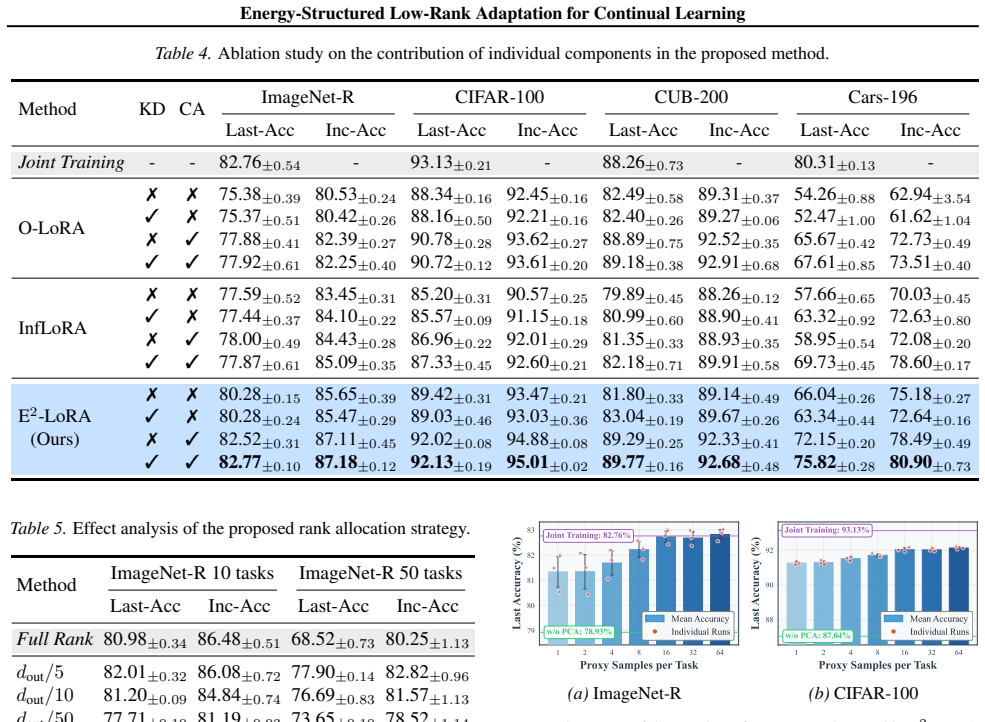
- [§4] §4 (dynamic rank allocation): the joint optimization of energy retention and plasticity is presented as task-agnostic, but no analysis or ablation shows that the allocation remains stable when effective numerical rank grows with depth, width, or task count; this directly affects whether capacity is actually freed as claimed.
- [Experiments] Experiments section: the SOTA claim is asserted without reported error bars, full baseline implementations, or singular-value spectra confirming rapid decay on the evaluated architectures and task sequences, making it impossible to assess whether the low-rank assumption holds with the required concentration.
minor comments (2)
- Notation for the drift matrix and energy metric should be defined once at first use rather than re-introduced.
- Figure captions should explicitly state which datasets and models are shown in the singular-value plots (if present).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to provide the requested details.
read point-by-point responses
-
Referee: [§3] §3 (theoretical analysis): the central claim that output feature drift is 'inherently low-rank' and that principal-direction preservation minimizes reconstruction error is load-bearing for the entire method, yet the provided text contains no derivation steps, explicit assumptions on the drift matrix, or singular-value decay analysis; without these the proof cannot be evaluated.
Authors: We agree the current presentation of the proof in §3 is insufficiently detailed. In the revision we will insert the complete derivation, state all assumptions on the drift matrix explicitly, and add singular-value decay plots computed on representative drift matrices from the training runs. revision: yes
-
Referee: [§4] §4 (dynamic rank allocation): the joint optimization of energy retention and plasticity is presented as task-agnostic, but no analysis or ablation shows that the allocation remains stable when effective numerical rank grows with depth, width, or task count; this directly affects whether capacity is actually freed as claimed.
Authors: We will add a new subsection with ablations that vary network depth, width, and task count while tracking the allocated ranks and retained energy. These results will be used to demonstrate stability of the allocation rule. revision: yes
-
Referee: [Experiments] Experiments section: the SOTA claim is asserted without reported error bars, full baseline implementations, or singular-value spectra confirming rapid decay on the evaluated architectures and task sequences, making it impossible to assess whether the low-rank assumption holds with the required concentration.
Authors: We will augment the experimental section with error bars from five independent runs, explicit references or code links for all baselines, and singular-value spectra of the observed output-feature drifts on the reported architectures and task sequences. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained.
full rationale
The paper's core chain begins with an empirical observation that output feature drift is low-rank, followed by a theoretical argument that principal directions minimize reconstruction error (standard from Eckart-Young/SVD optimality) and a subsequent design of energy-ordered LoRA with dynamic allocation. No equation reduces a claimed prediction to a fitted input by construction, no load-bearing premise rests solely on self-citation, and the low-rank property is presented as observed rather than defined into the result. The method's performance claims are supported by experiments rather than tautological re-derivation of inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Essential Subspace Merging for Multi-Task Learning
The paper proposes Essential Subspace Decomposition and Merging (ESM/ESM++) to fuse task-specific model updates by isolating and orthogonalizing their principal activation-shift directions.
Reference graph
Works this paper leans on
-
[1]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[2]
One-shot knowledge transfer for scalable person re-identification
Li, L., Qi, L., and Geng, X. One-shot knowledge transfer for scalable person re-identification. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 668–677, 2025a. Li, L., Zhou, D.-W., Ye, H.-J., and Zhan, D.-C. Address- ing imbalanced domain-incremental learning through dual-balance collaborative experts.arXiv preprint a...
-
[3]
Pham, Q., Liu, C., and Hoi, S. Continual normalization: Rethinking batch normalization for online continual learn- ing.arXiv preprint arXiv:2203.16102,
-
[4]
Rebuffi, S.-A., Kolesnikov, A., Sperl, G., and Lampert, C. H. icarl: Incremental classifier and representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2001–2010,
2001
-
[5]
arXiv preprint arXiv:2104.10972 , year=
Ridnik, T., Ben-Baruch, E., Noy, A., and Zelnik-Manor, L. Imagenet-21k pretraining for the masses.arXiv preprint arXiv:2104.10972,
-
[6]
The caltech-ucsd birds-200-2011 dataset
Wah, C., Branson, S., Welinder, P., Perona, P., and Belongie, S. The caltech-ucsd birds-200-2011 dataset. Technical report, California Institute of Technology,
2011
-
[7]
Orthogonal sub- space learning for language model continual learning
Wang, X., Chen, T., Ge, Q., Xia, H., Bao, R., Zheng, R., Zhang, Q., Gui, T., and Huang, X.-J. Orthogonal sub- space learning for language model continual learning. In Findings of the Association for Computational Linguis- tics: EMNLP 2023, pp. 10658–10671,
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.