DivRL: Disentangled Self-Similarity Rewards for Diverse Subject-Driven Generation
Pith reviewed 2026-06-26 08:35 UTC · model grok-4.3
The pith
Treating identity as a gated constraint lets subject-driven generators explore structural diversity without losing subject consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
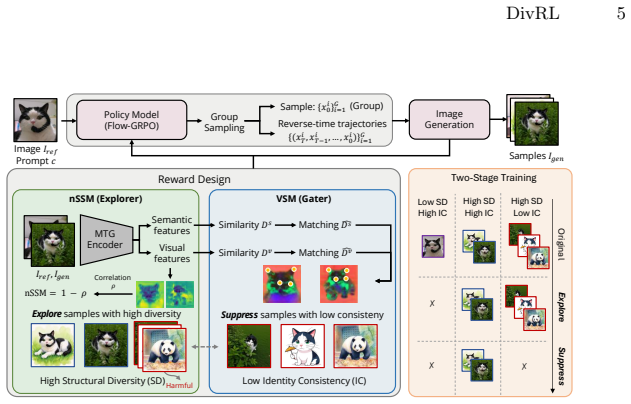
DivRL jointly optimizes identity consistency and structural diversity by using disentangled features from a similarity model; Negative Self-Similarity Measure quantifies diversity while Visual Semantic Matching quantifies identity, and the Explore-and-Suppress strategy treats the latter as a gated constraint that penalizes only threshold violations via quadratic hinge loss, converting identity preservation into a feasibility constraint rather than a competing term.
What carries the argument
The Explore-and-Suppress strategy, which treats Visual Semantic Matching as a gated constraint so the model can freely sample configurations scored high by Negative Self-Similarity Measure and penalizes only those that violate the identity threshold.
If this is right
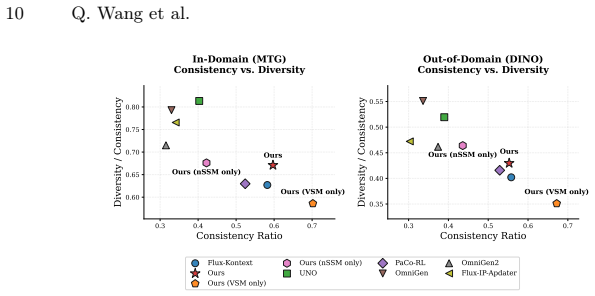
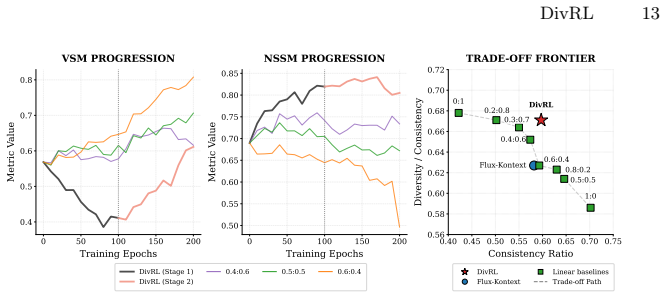
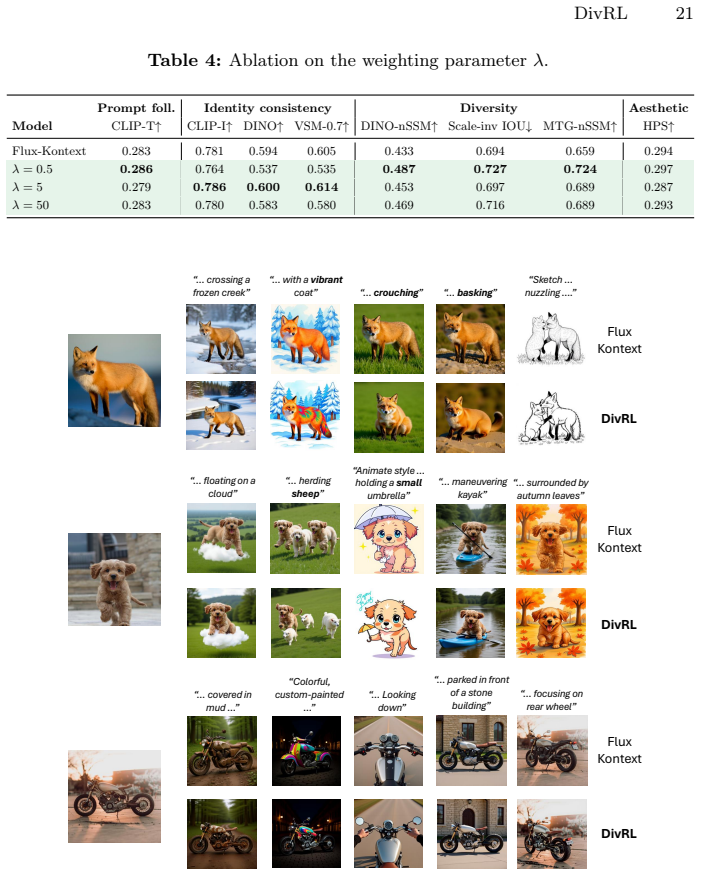
- The generator produces images with higher structural diversity at comparable identity consistency levels.
- Identity preservation no longer trades off directly against diversity because it functions only as a post-exploration filter.
- Post-training with the gated loss improves both objectives simultaneously rather than requiring separate balancing.
- The method applies to existing subject-driven pipelines without retraining the base generator from scratch.
Where Pith is reading between the lines
- The same gated-constraint pattern could be tested on other conflicting objectives such as text alignment versus visual realism.
- If the disentanglement holds, the approach might reduce the need for heavy prompt engineering in creative workflows.
- A practical test would measure whether users prefer the outputs when asked to generate multiple distinct views of the same subject.
Load-bearing premise
A similarity model already supplies visual features disentangled enough that one measure tracks only structural diversity and the other tracks only identity.
What would settle it
An experiment in which applying the identity gate causes measured structural diversity to stop increasing or causes identity consistency to fall below the baseline model.
Figures










read the original abstract
Subject-driven image generation faces an "Identity-Diversity Paradox", where strong identity preservation often leads to rigid and low-diversity outputs. We propose a post-training framework called DivRL that jointly optimizes identity consistency and structural diversity simultaneously by leveraging disentangled visual features from a robust similarity model. Specifically, we introduce a Negative Self-Similarity Measure (nSSM) to quantify structural diversity, and Visual Semantic Matching (VSM) to evaluate identity consistency. We propose an "Explore-and-Suppress" strategy that treats VSM as a gated constraint: the model freely explores structurally diverse configurations, and only samples that violate the identity threshold are penalized via a quadratic hinge loss. This converts identity preservation from a competing objective into a feasibility constraint, allowing nSSM and VSM to improve jointly. Experiments demonstrate that our method effectively pushes the model to generate both consistent and diverse images and improves structural diversity while maintaining comparable identity consistency through a gated optimization formulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DivRL, a post-training framework for subject-driven image generation to resolve the Identity-Diversity Paradox. It introduces nSSM to quantify structural diversity and VSM to measure identity consistency, using an Explore-and-Suppress strategy that treats VSM as a gated feasibility constraint (with quadratic hinge loss on violations) so the model can explore diverse configurations while preserving identity, allowing joint improvement via disentangled features from a robust similarity model.
Significance. If the disentanglement assumption holds and the gated optimization produces verifiable joint gains, the approach could offer a practical way to convert competing objectives into a constraint in generative modeling, with potential impact on subject-driven synthesis tasks. The paper ships no machine-checked proofs, reproducible code, or parameter-free derivations, so significance rests entirely on the empirical claims.
major comments (3)
- [Abstract] Abstract: the statement that 'experiments demonstrate that our method effectively pushes the model to generate both consistent and diverse images' supplies no quantitative metrics, baselines, ablation tables, or statistical comparisons, so the central claim of joint nSSM/VSM improvement rests on an unverified assertion.
- [Abstract] Abstract (and method description): nSSM and VSM are defined within the paper and then used both to drive the Explore-and-Suppress training objective and to evaluate success; without external benchmarks, held-out similarity models, or shipped code, it is impossible to determine whether reported gains are independent of the measure definitions themselves.
- [Abstract] Abstract (Explore-and-Suppress paragraph): the strategy assumes the underlying similarity model already supplies features with negligible residual entanglement between structure (nSSM) and identity (VSM), yet no quantitative check (feature orthogonality, mutual information, or ablation on entangled vs. disentangled backbones) is described; if correlation remains, the VSM gate will either suppress valid diversity or fail to protect identity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below with references to the full manuscript and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'experiments demonstrate that our method effectively pushes the model to generate both consistent and diverse images' supplies no quantitative metrics, baselines, ablation tables, or statistical comparisons, so the central claim of joint nSSM/VSM improvement rests on an unverified assertion.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript (Section 4 and associated tables) reports concrete metrics, baseline comparisons (e.g., DreamBooth, LoRA), and ablation studies demonstrating joint gains in nSSM and VSM. We will revise the abstract to summarize these specific improvements and statistical comparisons. revision: yes
-
Referee: [Abstract] Abstract (and method description): nSSM and VSM are defined within the paper and then used both to drive the Explore-and-Suppress training objective and to evaluate success; without external benchmarks, held-out similarity models, or shipped code, it is impossible to determine whether reported gains are independent of the measure definitions themselves.
Authors: nSSM and VSM are inherently task-specific, so their use in both the objective and evaluation is by design. The manuscript mitigates circularity through comparisons against multiple baselines on standard subject-driven benchmarks and sensitivity analyses across similarity model variants. We acknowledge that the current submission does not include shipped code or additional held-out models; we will add a limitations discussion on this point and commit to releasing code upon acceptance to support independent verification. revision: partial
-
Referee: [Abstract] Abstract (Explore-and-Suppress paragraph): the strategy assumes the underlying similarity model already supplies features with negligible residual entanglement between structure (nSSM) and identity (VSM), yet no quantitative check (feature orthogonality, mutual information, or ablation on entangled vs. disentangled backbones) is described; if correlation remains, the VSM gate will either suppress valid diversity or fail to protect identity.
Authors: The similarity model was chosen based on prior evidence of disentangled representations. While explicit orthogonality or mutual-information analyses were not included in the initial submission, the empirical joint gains observed support practical effectiveness of the gating. We will add a dedicated analysis subsection with feature correlation metrics and backbone ablations in the revision. revision: yes
Circularity Check
No significant circularity; derivation is self-contained.
full rationale
The paper introduces nSSM and VSM as new measures derived from an external robust similarity model, then defines an Explore-and-Suppress training strategy that uses VSM as a constraint while optimizing nSSM. No equations or self-citations are shown that reduce the claimed joint improvement to a tautology or fitted input by construction. The disentanglement assumption is stated but not derived from the measures themselves; the framework remains an independent proposal whose empirical validity would be checked against held-out evaluations or human studies rather than reducing to its own definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Black, K., Janner, M., Du, Y., Kostrikov, I., Levine, S.: Training diffusion models with reinforcement learning (2023)
2023
-
[2]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Chen, J., Xu, Z., Pan, X., Hu, Y., Qin, C., Goldstein, T., Huang, L., Zhou, T., Xie, S., Savarese, S., et al.: Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset. arXiv preprint arXiv:2505.09568 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, X., Huang, L., Liu, Y., Shen, Y., Zhao, D., Zhao, H.: Anydoor: Zero-shot object-level image customization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6593–6602 (2024)
2024
-
[4]
In: Advances in Neural Information Processing Systems (2025)
Eldesokey, A., Cvejic, A., Ghanem, B., Wonka, P.: Mind-the-glitch: Visual corre- spondence for detecting inconsistencies in subject-driven generation. In: Advances in Neural Information Processing Systems (2025)
2025
-
[5]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[6]
Advances in Neural Information Processing Sys- tems36, 79858–79885 (2023)
Fan, Y., Watkins, O., Du, Y., Liu, H., Ryu, M., Boutilier, C., Abbeel, P., Ghavamzadeh, M., Lee, K., Lee, K.: Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models. Advances in Neural Information Processing Sys- tems36, 79858–79885 (2023)
2023
-
[7]
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-Or, D.: An image is worth one word: Personalizing text-to-image genera- tionusingtextualinversion.In:TheEleventhInternationalConferenceonLearning Representations (2023),https://openreview.net/forum?id=NAQvF08TcyG
2023
-
[8]
In: The Thirty-ninth Annual Conference on Neu- ral Information Processing Systems (2025),https://openreview.net/forum?id= cZMno8E3yp
Goyal, A., Qian, G., Coskun, H., Gupta, A., Tam, H., Ostashev, D., Hu, J., Sagar, D., Tulyakov, S., Aberman, K., Wang, K.C.: Preventing shortcuts in adapter train- ing via providing the shortcuts. In: The Thirty-ninth Annual Conference on Neu- ral Information Processing Systems (2025),https://openreview.net/forum?id= cZMno8E3yp
2025
-
[9]
In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=7mCo3R3Wyn
He, X., Fu, S., Zhao, Y., Li, W., Yang, J., Yin, D., Rao, F., Zhang, B.: TEMPFLOW-GRPO:WHENTIMINGMATTERSFORGRPOINFLOWMOD- ELS. In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=7mCo3R3Wyn
2026
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Hu, Z., Zhang, F., Chen, L., Kuang, K., Li, J., Gao, K., Xiao, J., Wang, X., Zhu, W.: Towards better alignment: Training diffusion models with reinforcement learn- ing against sparse rewards. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23604–23614 (2025)
2025
-
[11]
Advances in neural information processing systems36, 36652–36663 (2023)
Kirstain,Y.,Polyak,A.,Singer,U.,Matiana,S.,Penna,J.,Levy,O.:Pick-a-pic:An open dataset of user preferences for text-to-image generation. Advances in neural information processing systems36, 36652–36663 (2023)
2023
-
[12]
In: IEEE International Conference on Computer Vision (ICCV) (2025)
Kumari, N., Yin, X., Zhu, J.Y., Misra, I., Azadi, S.: Generating multi-image syn- thetic data for text-to-image customization. In: IEEE International Conference on Computer Vision (ICCV) (2025)
2025
-
[13]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs,B.F.,Batifol,S.,Blattmann,A.,Boesel,F.,Consul,S.,Diagne,C.,Dockhorn, T., English, J., English, Z., Esser, P., Kulal, S., Lacey, K., Levi, Y., Li, C., Lorenz, D., Müller, J., Podell, D., Rombach, R., Saini, H., Sauer, A., Smith, L.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space (2025),https://arxiv.org/abs/2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
In: Thirty-seventh Conference on Neural Information Processing Systems (2023),https://openreview.net/forum? id=g6We1SwaY9
Li, D., Li, J., Hoi, S.: BLIP-diffusion: Pre-trained subject representation for con- trollable text-to-image generation and editing. In: Thirty-seventh Conference on Neural Information Processing Systems (2023),https://openreview.net/forum? id=g6We1SwaY9
2023
-
[15]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Li, J., Cui, Y., Huang, T., Ma, Y., Fan, C., Yang, M., Zhong, Z.: Mixgrpo: Unlock- ing flow-based grpo efficiency with mixed ode-sde. arXiv preprint arXiv:2507.21802 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
In: European Conference on Computer Vision
Lin, Z., Pathak, D., Li, B., Li, J., Xia, X., Neubig, G., Zhang, P., Ramanan, D.: Evaluating text-to-visual generation with image-to-text generation. In: European Conference on Computer Vision. pp. 366–384. Springer (2024)
2024
-
[17]
In: The Thirty- ninthAnnualConferenceonNeuralInformationProcessingSystems(2025),https: //openreview.net/forum?id=oCBKGw5HNf
Liu, J., Liu, G., Liang, J., Li, Y., Liu, J., Wang, X., Wan, P., ZHANG, D., Ouyang, W.: Flow-GRPO: Training flow matching models via online RL. In: The Thirty- ninthAnnualConferenceonNeuralInformationProcessingSystems(2025),https: //openreview.net/forum?id=oCBKGw5HNf
2025
-
[18]
arXiv preprint arXiv:2512.02014 (2025)
Liu, Z., Ren, W., Liu, H., Zhou, Z., Chen, S., Qiu, H., Huang, X., An, Z., Yang, F., Patel, A., et al.: Tuna: Taming unified visual representations for native unified multimodal models. arXiv preprint arXiv:2512.02014 (2025)
-
[19]
Long, Y., Yang, Y., Wei, H., Chen, W., Zhang, T., Liu, C., Jiang, K., Chen, J., Tang, K., Wen, B., et al.: Spatialreward: Bridging the perception gap in online rl for image editing via explicit spatial reasoning. arXiv preprint arXiv:2602.07458 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Editscore: Unlocking online rl for image editing via high-fidelity reward modeling, 2026
Luo, X., Wang, J., Wu, C., Xiao, S., Jiang, X., Lian, D., Zhang, J., Liu, D., et al.: Editscore: Unlocking online rl for image editing via high-fidelity reward modeling. arXiv preprint arXiv:2509.23909 (2025)
-
[21]
arXiv preprint arXiv:2510.14256 (2025)
Meng, X., Zhang, Z., Zhang, Z., Liao, J., Qin, L., Wang, W.: Identity-grpo: Opti- mizing multi-human identity-preserving video generation via reinforcement learn- ing. arXiv preprint arXiv:2510.14256 (2025)
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Miao, Z., Wang, J., Wang, Z., Yang, Z., Wang, L., Qiu, Q., Liu, Z.: Training diffusion models towards diverse image generation with reinforcement learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10844–10853 (2024)
2024
-
[23]
In: Proceedings of the Computer Vision and Pattern Recog- nition Conference
Na, S., Kim, Y., Lee, H.: Boost your human image generation model via direct pref- erence optimization. In: Proceedings of the Computer Vision and Pattern Recog- nition Conference. pp. 23551–23562 (2025)
2025
-
[24]
Advances in neural information processing sys- tems35, 27730–27744 (2022)
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al.: Training language models to follow instructions with human feedback. Advances in neural information processing sys- tems35, 27730–27744 (2022)
2022
-
[25]
In: The Thirteenth International Conference on Learning Representa- tions (2025),https://dreambenchplus.github.io/
Peng, Y., Cui, Y., Tang, H., Qi, Z., Dong, R., Bai, J., Han, C., Ge, Z., Zhang, X., Xia, S.T.: Dreambench++: A human-aligned benchmark for personalized image generation. In: The Thirteenth International Conference on Learning Representa- tions (2025),https://dreambenchplus.github.io/
2025
-
[26]
arXiv preprint arXiv:2512.04784 (2025)
Ping, B., Jia, C., Luo, M., Xia, C., Shen, X., Dang, Z., Qian, H.: Paco-rl: Advanc- ing reinforcement learning for consistent image generation with pairwise reward modeling. arXiv preprint arXiv:2512.04784 (2025)
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[28]
DivRL 17 In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. DivRL 17 In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2023)
2023
-
[29]
In: SIGGRAPH Asia 2024 Conference Papers
Sauer, A., Boesel, F., Dockhorn, T., Blattmann, A., Esser, P., Rombach, R.: Fast high-resolution image synthesis with latent adversarial diffusion distillation. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[30]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y.K., Wu, Y., Guo, D.: Deepseekmath: Pushing the limits of mathematical reasoning in open language models (2024),https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Shi, J., Xiong, W., Lin, Z., Jung, H.J.: Instantbooth: Personalized text-to-image generation without test-time finetuning. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 8543–8552 (2024)
2024
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wallace, B., Dang, M., Rafailov, R., Zhou, L., Lou, A., Purushwalkam, S., Ermon, S., Xiong, C., Joty, S., Naik, N.: Diffusion model alignment using direct preference optimization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8228–8238 (June 2024)
2024
-
[33]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Wu, C., Zheng, P., Yan, R., Xiao, S., Luo, X., Wang, Y., Li, W., Jiang, X., Liu, Y., Zhou, J., Liu, Z., Xia, Z., Li, C., Deng, H., Wang, J., Luo, K., Zhang, B., Lian, D., Wang, X., Wang, Z., Huang, T., Liu, Z.: Omnigen2: Exploration to advanced multimodal generation. arXiv preprint arXiv:2506.18871 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Editreward: A human-aligned reward model for instruction-guided image editing, 2026
Wu, K., Jiang, S., Ku, M., Nie, P., Liu, M., Chen, W.: Editreward: A human-aligned reward model for instruction-guided image editing. arXiv preprint arXiv:2509.26346 (2025)
-
[36]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wu, S., Huang, M., Wu, W., Cheng, Y., Ding, F., He, Q.: Less-to-more general- ization: Unlocking more controllability by in-context generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 18682–18692 (2025)
2025
-
[37]
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xiao, S., Wang, Y., Zhou, J., Yuan, H., Xing, X., Yan, R., Li, C., Wang, S., Huang, T., Liu, Z.: Omnigen: Unified image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13294– 13304 (June 2025)
2025
-
[39]
In: Proceedingsofthe37thInternationalConferenceonNeuralInformationProcessing Systems
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagere- ward: learning and evaluating human preferences for text-to-image generation. In: Proceedingsofthe37thInternationalConferenceonNeuralInformationProcessing Systems. pp. 15903–15935 (2023)
2023
-
[40]
DanceGRPO: Unleashing GRPO on Visual Generation
Xue, Z., Wu, J., Gao, Y., Kong, F., Zhu, L., Chen, M., Liu, Z., Liu, W., Guo, Q., Huang, W., et al.: Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Ye, H., Zhang, J., Liu, S., Han, X., Yang, W.: Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models (2023)
2023
-
[42]
Wang et al
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models (2023) 18 Q. Wang et al
2023
-
[43]
Secrets of RLHF in Large Language Models Part I: PPO
Zheng, R., Dou, S., Gao, S., Hua, Y., Shen, W., Wang, B., Liu, Y., Jin, S., Liu, Q., Zhou, Y., et al.: Secrets of rlhf in large language models part i: Ppo. arXiv preprint arXiv:2307.04964 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
motorcycle
Zhu, H., Xiao, T., Honavar, V.G.: DSPO: Direct score preference optimization for diffusion model alignment. In: The Thirteenth International Conference on Learn- ing Representations (2025),https://openreview.net/forum?id=xyfb9HHvMe A Evaluation metrics A.1 Structural DINO (sDINO) sDINO measures the structural similarity between the patches across the refe...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.