Early Bird Catches the Worm: Predicting Returns Even Before Purchase in Fashion E-commerce
Pith reviewed 2026-05-25 13:36 UTC · model grok-4.3
The pith
A deep neural network predicts the probability that a customer will return a fashion item before the order is placed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a deep neural network that combines Bayesian Personalized Ranking product embeddings, skip-gram body-size embeddings, and engineered customer and product features produces usable estimates of return probability prior to purchase, and that these estimates can be deployed in live experiments that measurably reduce overall returns on a large fashion e-commerce site.
What carries the argument
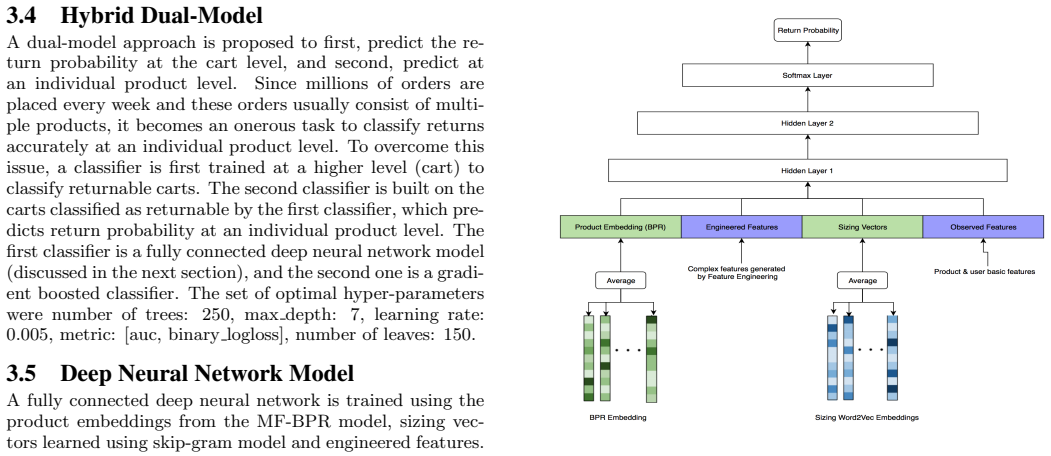
Deep neural network that fuses Bayesian Personalized Ranking product embeddings, skip-gram body embeddings, and engineered features to output a return probability score.
If this is right
- Platforms can surface targeted messages or alternative recommendations at the cart page to discourage likely returns.
- Return-probability scores can be computed for millions of customers in real time without waiting for post-purchase data.
- Early detection enables preemptive actions that lower reverse-logistics and liquidation costs.
- The same pipeline can be used to test different intervention strategies whose effectiveness is measured by change in realized return rates.
Where Pith is reading between the lines
- If the embeddings capture stable user and product signals, the same architecture could be retrained on other high-return categories such as electronics or furniture.
- The body-size embedding might also improve size-recommendation models that reduce returns caused by fit problems.
- Because predictions occur before the order, the method could be combined with dynamic pricing or shipping offers that further steer customers away from low-fit items.
Load-bearing premise
The chosen embeddings and engineered features already contain enough information to forecast whether a given customer will return a specific product before any purchase occurs.
What would settle it
A controlled live experiment in which the model-driven pre-purchase interventions produce no reduction in return rate relative to a matched control group.
Figures


read the original abstract
With the rapid growth in fashion e-commerce and customer-friendly product return policies, the cost to handle returned products has become a significant challenge. E-tailers incur huge losses in terms of reverse logistics costs, liquidation cost due to damaged returns or fraudulent behavior. Accurate prediction of product returns prior to order placement can be critical for companies. It can facilitate e-tailers to take preemptive measures even before the order is placed, hence reducing overall returns. Furthermore, finding return probability for millions of customers at the cart page in real-time can be difficult. To address this problem we propose a novel approach based on Deep Neural Network. Users' taste & products' latent hidden features were captured using product embeddings based on Bayesian Personalized Ranking (BPR). Another set of embeddings was used which captured users' body shape and size by using skip-gram based model. The deep neural network incorporates these embeddings along with the engineered features to predict return probability. Using this return probability, several live experiments were conducted on one of the major fashion e-commerce platform in order to reduce overall returns.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a deep neural network incorporating Bayesian Personalized Ranking (BPR) product embeddings (to capture user taste and latent product features), skip-gram embeddings (to capture user body shape and size), and engineered features can predict product return probabilities prior to purchase in fashion e-commerce. Several live experiments on a major platform are reported to demonstrate that using these probabilities enables preemptive measures that reduce overall returns.
Significance. If the live A/B experiments isolate the contribution of the return-probability model and show a meaningful reduction in returns, the work has clear practical significance for e-commerce platforms facing high reverse-logistics and liquidation costs. The combination of BPR and skip-gram embeddings with engineered features is a reasonable way to extract pre-purchase signals, and the use of production-platform experiments strengthens the applied claim.
minor comments (2)
- [Abstract] The abstract states that 'several live experiments were conducted' but provides no quantitative results (e.g., return-rate deltas, statistical significance, or A/B test sizes). Adding these numbers would strengthen the central claim without altering the modeling pipeline.
- The description of the DNN (how the two embedding sets and engineered features are concatenated, the network depth/width, loss function, and training procedure) is referenced only at a high level. A diagram or explicit equations would improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the accurate summary of our contributions, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The manuscript presents a standard supervised DNN pipeline that ingests pre-trained BPR product embeddings, skip-gram body-shape embeddings, and hand-engineered features to output a return-probability score; this score is then used in live A/B tests. No equations, fitted parameters, or self-citations are shown that would make the model output definitionally identical to its inputs. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Early Bird Catches the Worm: Predicting Returns Even Before Purchase in Fashion E-commerce
INTRODUCTION E-commerce sector is the fastest growing sector, with an ex- pectation to reach $4 trillion by 2020 1. In today’s compet- itive market, to increase customer experience, most compa- nies are coming up with hassle-free return policies [1]. Cus- tomers are usually allowed a return within a month or a sim- ilar time period. This policy [2] has im...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
In [11] authors used Maha- lanobis Feature Extraction to predict product returns in e- commerce
RELA TED WORK In this section, we have briefly reviewed the existing lit- erature on return prediction. In [11] authors used Maha- lanobis Feature Extraction to predict product returns in e- commerce. Here a prediction can only be made once the user has placed an order, due to which e-tailer can’t take preventive measures to reduce the returns. Also, this ...
-
[3]
METHODOLOGY Given a useru and current cartC which can contain multiple products, our objective is to come up with return probabil- ity score denoted by f(u,C ) for a user & cart combination. This probability score is used to implement the action items mentioned in Section 1 to reduce the overall returns. Anal- ysis showed that number of similar items in a...
-
[4]
• n style group as the number of same products with different colors in a cart
Product-level features • brand, category, product age • product level return score for different periods of time- last month, quarter, half-year, year. • n style group as the number of same products with different colors in a cart. • n similar products as the number of similar prod- ucts in a cart
-
[5]
Cart level features • cart size, order day (weekday/weekend), order time (morning/evening) • brand, category, delivery city, platform type
-
[6]
User level features • Based on the lifetime data of all users, features like return count, revenue, order count, quantity, payment mode, purchase frequency, were created • Applied clustering techniques at different levels to design new user features like user persona, en- gagement level, discount affinity score, customer type, purchase intent One hot encoder...
-
[7]
First, various data sources used for the modeling purpose are discussed
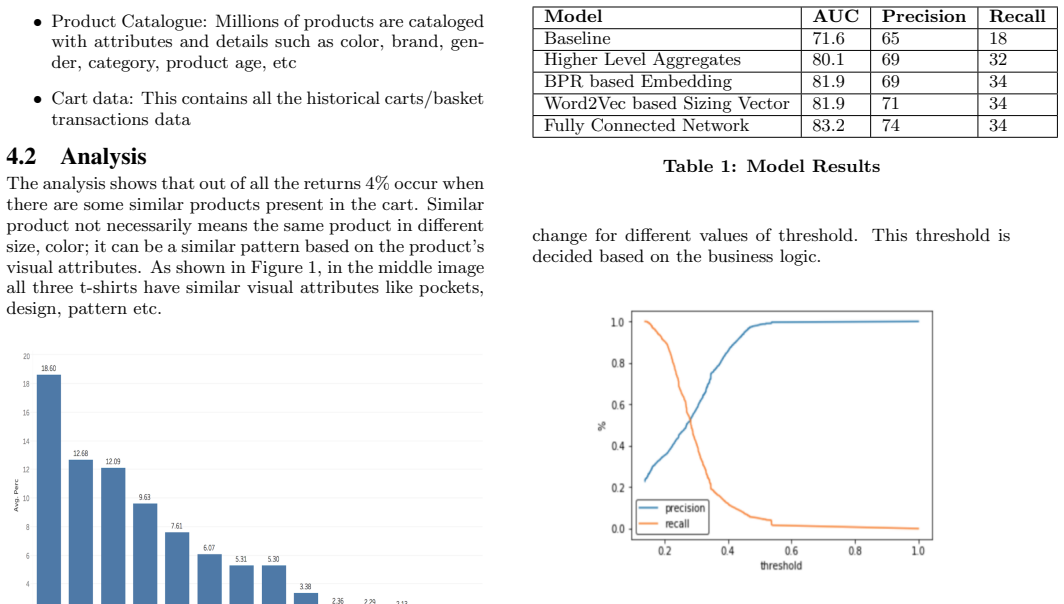
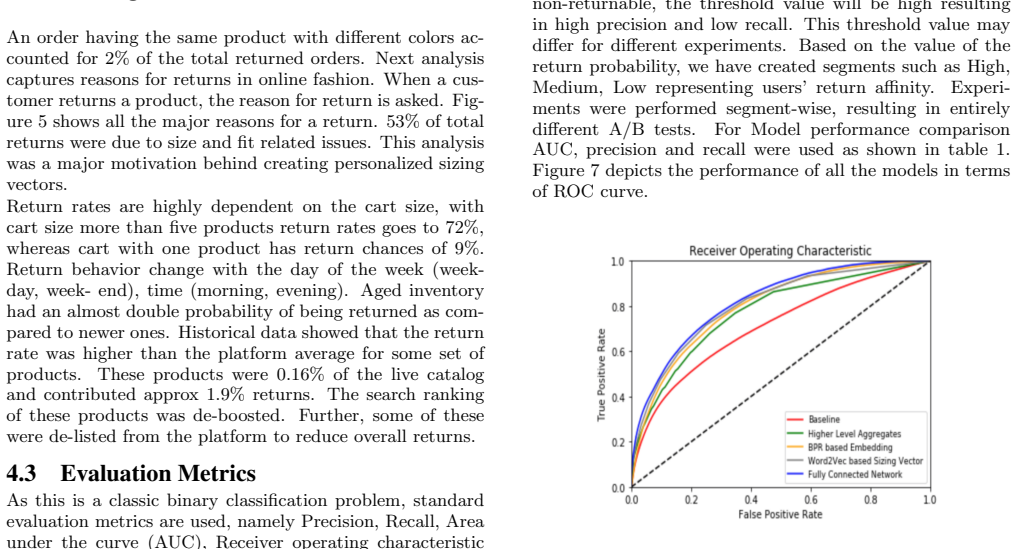
RESULTS AND ANALYSIS This section demonstrates the results and analysis of the ex- periments. First, various data sources used for the modeling purpose are discussed. Thereafter some interesting insights derived from the analysis of the data are presented. Further, the evaluation metrics are discussed. At last, the compari- son of different models on key e...
-
[8]
Experiments were conducted on three action items from the suggested ones in Section 1
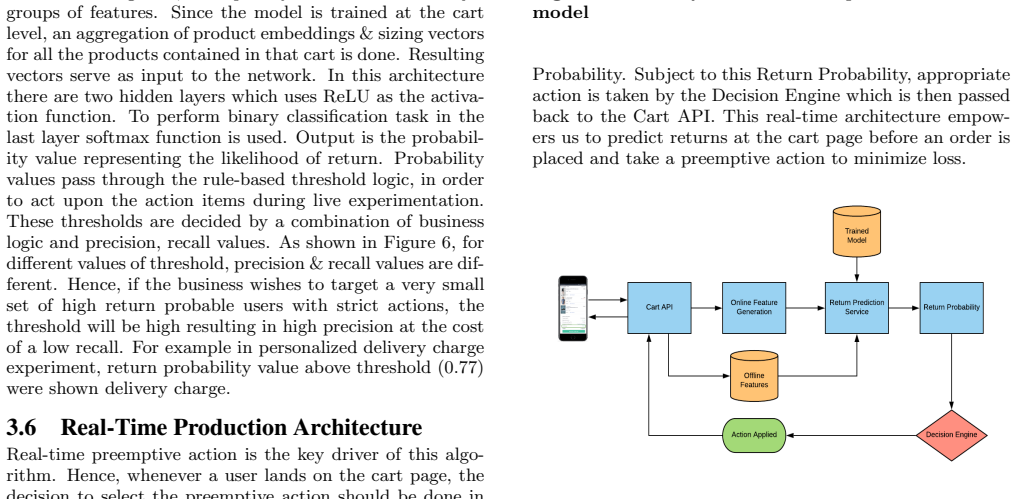
EXPERIMENTS In this section, the live experiments performed on one of the leading fashion platform are discussed. Experiments were conducted on three action items from the suggested ones in Section 1. First experiment comprised of applying person- alized delivery charge which was different for all customers depending on their respective live cart. The dual...
-
[9]
CONCLUSION E-tailers experience return-rate problem leading to increased costs and lower profit margins. To solve this, a novel ap- proach is proposed in this paper to detect returns and imple- ment certain actions items. Depending on the current cart configuration of a user, a hybrid dual-model is built using a deep neural network to detect returnable cart...
-
[10]
Product re- turns on the internet: A case of mixed signals?
C. Bonifield, C. Cole, and R. L. Schultz, “Product re- turns on the internet: A case of mixed signals?” Jour- nal of Business Research , vol. 63, no. 9-10, pp. 1058– 1065, 2010
work page 2010
-
[11]
Equilibrium returns policies in the presence of supplier competition,
S. Bandyopadhyay and A. Paul, “Equilibrium returns policies in the presence of supplier competition,” Mar- keting Science, vol. 29, pp. 846–857, 09 2010
work page 2010
-
[12]
Fraudulent consumer returns: exploiting retailers’ return policies,
L. C. Harris, “Fraudulent consumer returns: exploiting retailers’ return policies,” European Journal of Market- ing, vol. 44, no. 6, pp. 730–747, 2010. [Online]. Avail- able: https://doi.org/10.1108/03090561011032694
-
[13]
The impact of customer returns on pricing and order decisions,
J. Chen and P. C. Bell, “The impact of customer returns on pricing and order decisions,” European Journal of Operational Research, vol. 195, pp. 280–295, 2009
work page 2009
-
[14]
J. B. Edwards, A. C. McKinnon, and S. L. Cullinane, “Comparative analysis of the carbon footprints of conventional and online retailing: A last mile perspective,” International Journal of Physical Distribution & Logistics Management , vol. 40, no. 1/2, pp. 103–123, 2010. [Online]. Available: https://doi.org/10.1108/09600031011018055
-
[15]
Predictive model selection for forecasting product returns,
J. Ma and H. M. Kim, “Predictive model selection for forecasting product returns,” Journal of Mechanical Design, vol. 138, no. 5, p. 054501, 2016
work page 2016
-
[16]
Toktay, Forecasting product returns
B. Toktay, Forecasting product returns. INSEAD, 2001
work page 2001
-
[17]
Modeling and fore- casting product returns: An industry case study,
A. Canda, X. Yuan, and F. Wang, “Modeling and fore- casting product returns: An industry case study,” in 2015 IEEE International Conference on Industrial En- gineering and Engineering Management (IEEM) , Dec 2015, pp. 871–875
work page 2015
-
[18]
Bpr: Bayesian personalized rank- ing from implicit feedback,
S. Rendle, C. Freudenthaler, Z. Gantner, and L. Schmidt-Thieme, “Bpr: Bayesian personalized rank- ing from implicit feedback,” in Proceedings of the twenty-fifth conference on uncertainty in artificial in- telligence. AUAI Press, 2009, pp. 452–461
work page 2009
-
[19]
Efficient Estimation of Word Representations in Vector Space
T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” CoRR, vol. abs/1301.3781, 2013. [Online]. Available: http://arxiv.org/abs/1301.3781
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
Predicting prod- uct returns in e-commerce: The contribution of maha- lanobis feature extraction,
P. Urbanke, J. Kranz, and L. Kolbe, “Predicting prod- uct returns in e-commerce: The contribution of maha- lanobis feature extraction,” in ICIS, 2015
work page 2015
-
[21]
Probabilistic ma- trix factorization,
A. Mnih and R. R. Salakhutdinov, “Probabilistic ma- trix factorization,” in Advances in neural information processing systems, 2008, pp. 1257–1264
work page 2008
-
[22]
Decoding fashion contexts using word embeddings
S. Arora and D. Warrier, “Decoding fashion contexts using word embeddings.”
-
[23]
Non-negative matrix factorization with sparseness constraints,
P. O. Hoyer, “Non-negative matrix factorization with sparseness constraints,” Journal of machine learning research, vol. 5, no. Nov, pp. 1457–1469, 2004
work page 2004
-
[24]
Distributed representations of words and phrases and their compositionality,
T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in NIPS, 2013
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.