Multiple Object Detection and Tracking in Panoramic Videos for Cycling Safety Analysis
Pith reviewed 2026-05-23 23:02 UTC · model grok-4.3
The pith
A framework segments 360° images into sub-images and modifies trackers for boundary continuity to improve detection and tracking in panoramic cycling videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that its three-step framework—segmenting and projecting 360° images into sub-images to enhance detection accuracy, modifying multi-object tracking models to incorporate boundary continuity and object category information, and validating the pipeline on vehicle overtaking detection—produces higher average precision across resolutions, a 10.0% decrease in identification switches, a 2.7% improvement in identification precision, and an F-score of 0.82 when applied to real-world panoramic videos recorded by cyclists on London's roadways.
What carries the argument
The three-step framework of sub-image segmentation and projection for detection, boundary-continuous multi-object tracking that adds category information, and overtaking detection validation.
If this is right
- Higher average precision for object detection on panoramic imagery at varying resolutions.
- 10.0% reduction in identification switches and 2.7% gain in identification precision for multi-object tracking.
- Vehicle overtaking detection reaches an F-score of 0.82 in diverse real-world cycling conditions.
Where Pith is reading between the lines
- The same segmentation-plus-boundary-tracking steps could be tested on panoramic footage from other moving platforms such as cars or drones.
- Pairing the tracked objects with route GPS data would allow mapping of high-risk overtaking locations along specific streets.
- The framework might be extended to detect additional events such as close passes or dooring by cyclists.
Load-bearing premise
That segmenting and projecting the original 360° images into sub-images will improve detection accuracy without introducing new errors from projection artifacts or loss of context at sub-image boundaries.
What would settle it
Applying standard detection and tracking models directly to the same set of London panoramic videos and measuring equal or higher average precision together with equal or fewer identification switches than the proposed framework would falsify the central claim.
Figures


























read the original abstract
Cyclists face a disproportionate risk of injury, yet conventional crash records are too sparse to identify risk factors at fine spatial and temporal scales. Recently, naturalistic studies have used video data to capture the complex behavioural and infrastructural risk factors. A promising format is panoramic video, which can record 360$^\circ$ views around a rider. However, its use is limited by distortions, large numbers of small objects, and boundary continuity, which cannot be handled using existing computer vision models. This research proposes a novel three-step framework: (1) enhancing object detection accuracy on panoramic imagery by segmenting and projecting the original 360$^\circ$ images into sub-images; (2) modifying multi-object tracking models to incorporate boundary continuity and object category information; and (3) validating through a real-world application of vehicle overtaking detection. The methodology is evaluated using panoramic videos recorded by cyclists on London's roadways under diverse conditions. Experimental results demonstrate improvements over baselines, achieving higher average precision across varying image resolutions. Moreover, the enhanced tracking approach yields a 10.0% decrease in identification switches and a 2.7% improvement in identification precision. The overtaking detection task achieves a high F-score of 0.82, illustrating the practical effectiveness of the proposed method in real-world cycling safety scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a three-step framework for multiple object detection and tracking in 360° panoramic videos to support cycling safety analysis: (1) segmenting and projecting original images into sub-images to improve detection of small/distant objects, (2) adapting multi-object trackers to enforce boundary continuity and incorporate object category information, and (3) demonstrating the pipeline on a vehicle overtaking detection task. Evaluation uses real-world panoramic videos recorded by cyclists on London roadways; the abstract reports higher average precision across resolutions, a 10.0% reduction in identification switches, a 2.7% gain in identification precision, and an F-score of 0.82 on overtaking detection.
Significance. If the numeric gains are robust, the work would be significant for enabling finer-grained naturalistic studies of cyclist risk factors using panoramic video, a format that standard CV models handle poorly due to distortion and continuity issues. The real-world London dataset and the concrete application to overtaking detection are strengths that tie the technical contributions to a clear safety use case.
major comments (2)
- [Abstract] Abstract: The headline claims (10.0% decrease in identification switches, 2.7% improvement in identification precision, F-score 0.82) are presented without error bars, ablation results isolating the contribution of the projection step versus the tracker modifications, or any description of training data, model architectures, or baseline implementations. These omissions make the central performance assertions difficult to evaluate.
- [Abstract] Abstract (step 1 of framework): The claim that segmenting and projecting 360° images into sub-images improves detection accuracy rests on the untested assumption that this step does not introduce new errors from projection artifacts or loss of context at sub-image boundaries; no quantitative check of these effects is referenced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to improve the clarity of the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims (10.0% decrease in identification switches, 2.7% improvement in identification precision, F-score 0.82) are presented without error bars, ablation results isolating the contribution of the projection step versus the tracker modifications, or any description of training data, model architectures, or baseline implementations. These omissions make the central performance assertions difficult to evaluate.
Authors: The abstract provides a concise summary of the headline results. Full details on training data, model architectures (including YOLOv5 for detection and the modified ByteTrack), baseline implementations, and ablation studies that isolate the projection step from the tracker modifications appear in Sections 3 and 4 of the manuscript, along with the overtaking detection evaluation protocol. Error bars are omitted because the primary evaluation uses a single fixed real-world dataset; however, we can add standard deviations from k-fold splits on the dataset in a revision. To address the concern directly, we will revise the abstract to include a short reference to the evaluation setup and point readers to the relevant sections. revision: partial
-
Referee: [Abstract] Abstract (step 1 of framework): The claim that segmenting and projecting 360° images into sub-images improves detection accuracy rests on the untested assumption that this step does not introduce new errors from projection artifacts or loss of context at sub-image boundaries; no quantitative check of these effects is referenced.
Authors: We agree that an explicit quantitative check of projection artifacts and boundary context loss would strengthen the presentation. The manuscript demonstrates the net benefit of the segmentation/projection step via improved average precision across resolutions relative to direct panoramic detection (reported in the results). Overlapping sub-images are used to retain context, but we did not isolate artifact effects in a dedicated experiment. We will add this analysis, including boundary-specific precision metrics, in the revised manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical three-step pipeline for panoramic video analysis, with performance gains measured on real-world cyclist footage using standard detection/tracking metrics (AP, ID switches, precision, F-score). No equations, fitted parameters, or self-citations are presented that reduce any reported result to an input by construction; the evaluation remains externally falsifiable against held-out video data and baseline models. The framework choices (segmentation/projection, boundary continuity) are motivated by domain challenges rather than derived from the metrics themselves.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
CycleTrajectory: An End-to-End Pipeline for Enriching and Analyzing GPS Trajectories to Understand Cycling Behavior and Environment
CycleTrajectory is a pipeline that filters, resamples, map-matches via OSRM, enriches with OSM road data, and derives cycling metrics from action-camera GPS trajectories, reporting 5.64% map-matching error.
Reference graph
Works this paper leans on
-
[1]
Introduction 35 Cycling, as an active travel mode, has zero carbon emissions (Massink et al., 2011) and36 can support reductions in traffic congestion (Brunsing, 1997) while improving the health37 of urban residents (Wanner et al., 2012). Therefore, many local governments and trans-38 port authorities are implementing policies to encourage cycling as an a...
work page 2011
-
[2]
In combination, these actions and interactions within the environment 109 contribute to crash risk
Related work 105 2.1 Challenges in Understanding Cycling Crash Risk 106 Urban transport networks are complex environments in which many agents (pedestrians,107 cyclists and other road users) interact with each other while using different types of 108 3 infrastructure. In combination, these actions and interactions within the environment 109 contribute to ...
work page 2018
-
[3]
and to track objects using the views from multiple cameras (Jiménez-Bravo et al.,153 2022). 154 Existing object detection and MOT algorithms are trained on video from cameras with155 a limited field of view (FOV). This suits the data that has been collected in naturalistic156 cycling studies to date, which contain only front or rear facing views. However,...
work page 2022
-
[4]
Data 184 In order to test the improving effect of the proposed methods on object detection and185 MOT on panoramic cycling videos, this project built an annotated dataset so that the186 5 Video Length (s) FPS F rames Description Preview Video 1 14.0 30 420 Taken on a road Video 2 11.1 30 333 Taken on a bicycle path Video 3 12.0 30 360 Taken on a road Tabl...
work page 2019
-
[5]
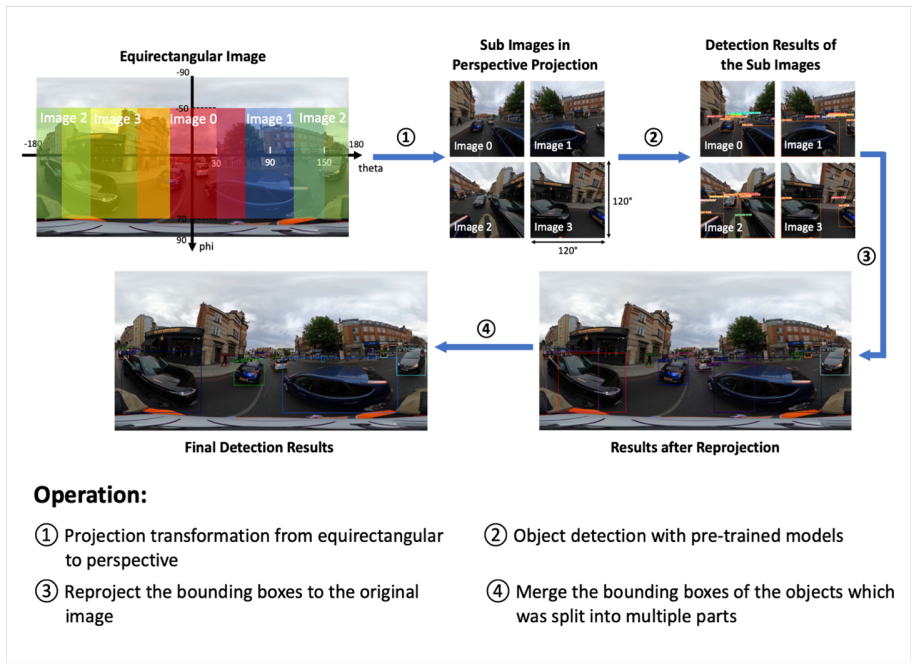
Methodology 290 In order to apply computer vision291 models to automated road user 292 11 Figure 7: Three steps of the methodology behaviour analysis of panoramic cycling videos, this project designed and implemented a293 three-step methodology, as shown in Figure 7. 294 As the first step of the methodology, an approach was designed to improve the ap-295 ...
work page 1997
-
[6]
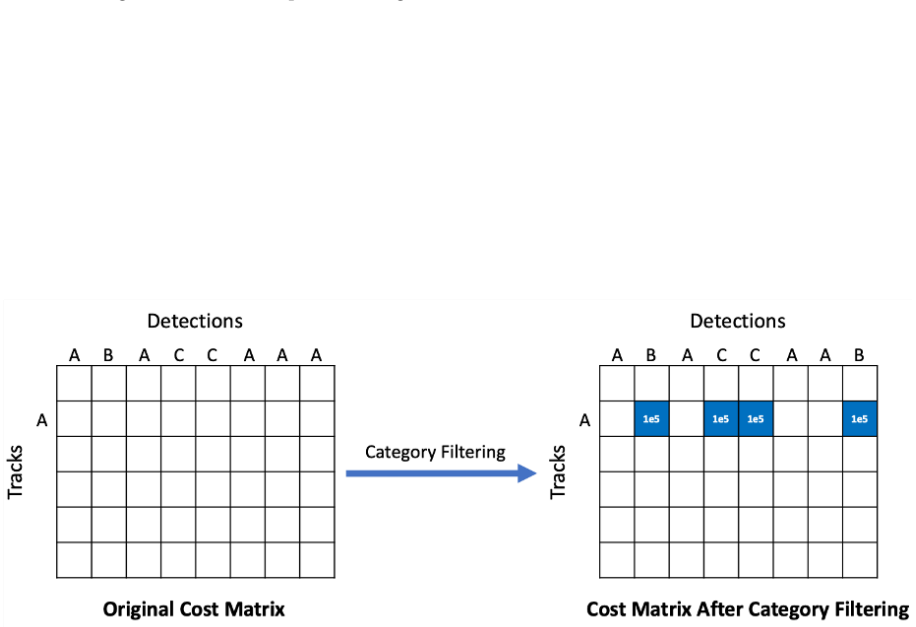
Results & Analysis 524 After implementing the proposed methodology, in this chapter, the project will present525 and analyse the results obtained in each step systematically. 526 5.1 Evaluation of the Model for Improving Object Detection on 527 Panoramic Cycling Images 528 The experiments designed in subsection 4.1.5 were implemented on a server equipped ...
work page 1920
-
[7]
Discussion 642 6.1 Improving Object Detection 643 Although Table 4 indicates that the performance of the proposed method can be also achieved644 by the original models with larger input resolution, once the input resolution is as large as that645 of the original image, the effect can not be replaced anymore. In other words, it increases the646 upper limit...
work page 2018
-
[8]
Conclusion 704 In the field of cycling safety, most of the existing studies applied computer vision models to ‘tra-705 ditional’ videos with a limited field of view for automated road user behaviour analysis (Ibrahim,706 Haworth, Christie, Cheng & Hailes, 2021). To enable analysis of the complete environment sur-707 35 rounding the rider, this research de...
-
[9]
(1997).Public transport and cycling: Experience of modal integration in ger-747 many
https://doi.org/10.1109/ICIP.2016.7533003 746 36 Brunsing, J. (1997).Public transport and cycling: Experience of modal integration in ger-747 many. from the greening of urban transport(2nd ed.). Wiley (John); Sons, Limited.748 cheind. (2019). Py-motmetrics [Accessed 23 August 2022]. https://github.com/cheind/py-749 motmetrics 750 Daniels, S., Nuyts, E., &...
-
[10]
https://doi.org/10.1016/j.aap.2007.07.016 753 Delmelle, E. M., & Delmelle, E. C. (2012). Exploring spatio-temporal commuting patterns754 in a university environment.Transport Policy, 21, 1–9. https://doi.org/10.1016/j.755 tranpol.2011.12.007 756 Deng, F., Zhu, X., & Ren, J. (2017). Object detection on panoramic images based on deep757 learning. 2017 3rd I...
-
[11]
796 LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning.Nature, 521(7553), 436–444.797 https://doi.org/10.1038/nature14539 798 Lee, G.-W., & Han, J.-K. (2021). Viewport rendering algorithm with a curved surface for799 a wide fov in 360° images. Applied Sciences, 11(3), 1133. https://doi.org/10.3390/800 app11031133 801 Li, J., Liang, X., Wei, Y., Xu,...
-
[12]
888 Zuraimi, M. A. B., & Zaman, F. H. K. (2021). Vehicle detection and tracking using yolo889 and deepsort. 2021 IEEE 11th IEEE Symposium on Computer Applications & 890 Industrial Electronics (ISCAIE), 23–29. 891 40
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.