Hybrid Diffusion for Simultaneous Symbolic and Continuous Planning
Pith reviewed 2026-05-18 13:19 UTC · model grok-4.3
The pith
Combining discrete diffusion for symbolic plans with continuous diffusion for trajectories enables effective long-horizon robotic planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We show that this requires a novel mix of discrete variable diffusion and continuous diffusion, which dramatically outperforms the baselines. In addition, we illustrate how this hybrid diffusion process enables flexible trajectory synthesis, allowing us to condition synthesized actions on partial and complete symbolic conditions.
What carries the argument
hybrid diffusion process that mixes discrete variable diffusion for symbolic plans with continuous diffusion for trajectories
If this is right
- The hybrid model dramatically outperforms standard continuous diffusion baselines on long-horizon tasks.
- The method enables flexible trajectory synthesis conditioned on partial or complete symbolic plans.
- Simultaneous symbolic and continuous generation reduces confusion between different behavior modes.
Where Pith is reading between the lines
- Similar hybrid diffusion techniques might help in other areas like natural language generation combined with continuous control signals.
- Testing on physical robots could reveal whether the method transfers from simulation to real-world settings.
- The approach suggests a path toward more structured generative models that separate high-level and low-level planning.
Load-bearing premise
The integration of discrete variable diffusion with continuous diffusion can be performed without introducing new instabilities or requiring task-specific tuning that would limit generalization.
What would settle it
A finding that the proposed hybrid diffusion does not outperform baselines or suffers from instabilities on standard long-horizon robotic benchmarks would falsify the claim.
Figures







read the original abstract
Constructing robots to accomplish long-horizon tasks is a long-standing challenge within artificial intelligence. Approaches using generative methods, particularly Diffusion Models, have gained attention due to their ability to model continuous robotic trajectories for planning and control. However, we show that these models struggle with long-horizon tasks that involve complex decision-making and, in general, are prone to confusing different modes of behavior, leading to failure. To remedy this, we propose to augment continuous trajectory generation by simultaneously generating a high-level symbolic plan. We show that this requires a novel mix of discrete variable diffusion and continuous diffusion, which dramatically outperforms the baselines. In addition, we illustrate how this hybrid diffusion process enables flexible trajectory synthesis, allowing us to condition synthesized actions on partial and complete symbolic conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that continuous diffusion models for robotic trajectory planning struggle with long-horizon tasks due to mode confusion and poor decision-making. To address this, it proposes augmenting continuous diffusion with simultaneous generation of high-level symbolic plans via a novel hybrid process mixing discrete-variable diffusion and continuous diffusion. This hybrid approach is said to dramatically outperform baselines while enabling flexible conditioning of trajectories on partial or complete symbolic states.
Significance. If the hybrid integration proves stable and generalizable without per-task tuning, the work could meaningfully advance generative planning in robotics by bridging discrete symbolic reasoning with continuous control, offering a path to more reliable long-horizon behavior synthesis.
major comments (2)
- [Abstract / Method] The central claim of dramatic outperformance rests on the stability of the joint discrete-continuous reverse process under a shared noise schedule, yet the manuscript provides no derivation, loss-weighting scheme, or ablation for the coupled sampling procedure (see the hybrid diffusion description in the abstract and any corresponding method section).
- [Abstract] The risk of one modality dominating or mode collapse as the discrete plan space grows with horizon length is raised as a potential issue but receives no analysis or empirical check, which is load-bearing for the generalization claim on long-horizon tasks.
minor comments (1)
- [Abstract] Clarify the precise definition of 'discrete variable diffusion' and its relation to existing discrete diffusion literature to aid readers unfamiliar with the extension.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. The feedback highlights important aspects of our hybrid diffusion formulation that require clearer exposition and additional validation. We address each major comment below and will incorporate the suggested material in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Method] The central claim of dramatic outperformance rests on the stability of the joint discrete-continuous reverse process under a shared noise schedule, yet the manuscript provides no derivation, loss-weighting scheme, or ablation for the coupled sampling procedure (see the hybrid diffusion description in the abstract and any corresponding method section).
Authors: We agree that the current manuscript lacks an explicit derivation and supporting ablations for the joint reverse process. In the revision we will add a dedicated subsection deriving the coupled discrete-continuous denoising steps under the shared noise schedule, including the precise loss-weighting coefficients used to balance the two modalities. We will also report ablation results that vary the coupling hyper-parameters and noise schedule to quantify sampling stability. revision: yes
-
Referee: [Abstract] The risk of one modality dominating or mode collapse as the discrete plan space grows with horizon length is raised as a potential issue but receives no analysis or empirical check, which is load-bearing for the generalization claim on long-horizon tasks.
Authors: This concern is well-founded and directly relevant to our long-horizon claims. While our experiments demonstrate improved performance, we did not provide a dedicated analysis of modality balance or mode collapse. In the revised manuscript we will add quantitative checks, such as the entropy of the generated symbolic plan distribution and the fraction of unique high-level plans, evaluated across increasing horizon lengths. These results will be used to assess whether one modality begins to dominate and to discuss any implicit regularization provided by the hybrid objective. revision: yes
Circularity Check
No circularity: hybrid diffusion proposal is architectural, not derived from fitted inputs or self-referential definitions
full rationale
The abstract and description present the core contribution as a novel architectural combination of discrete-variable diffusion and continuous diffusion for simultaneous symbolic planning and trajectory generation. No equations, loss terms, or reverse-process derivations are shown that reduce by construction to fitted parameters, self-citations, or renamed empirical patterns. The method is introduced as an augmentation to address mode confusion in long-horizon tasks, with claims of outperformance and flexible conditioning presented as empirical outcomes rather than tautological redefinitions. This satisfies the self-contained criterion with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models can be extended to jointly handle discrete symbolic variables and continuous trajectory variables without loss of mode separation.
invented entities (1)
-
Hybrid diffusion process
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that this requires a novel mix of discrete variable diffusion and continuous diffusion... L = L_DDPM + λ L_MD4 (Eq. 9)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Hybrid Diffusion Planner (HDP) models two diffusion processes... independently sampled noise levels kc and kd
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Flexible Multitask Learning with Factorized Diffusion Policy
A factorized modular diffusion policy improves fitting of multimodal robot actions and enables flexible task adaptation without catastrophic forgetting.
Reference graph
Works this paper leans on
-
[1]
Planning with Diffusion for Flexible Behavior Synthesis,
M. Janner, Y . Du, J. Tenenbaum, and S. Levine, “Planning with Diffusion for Flexible Behavior Synthesis,” inProc. of the 39th Int. Conf. on Machine Learning. PMLR, June 2022, pp. 9902–9915. 1, 2, 4, 5
work page 2022
-
[2]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” inProc. of the 32nd Int. Conf. on Machine Learning, ser. Proc. of Machine Learning Research, F. Bach and D. Blei, Eds., vol. 37. Lille, France: PMLR, 07–09 Jul 2015, pp. 2256–2265. 1, 2
work page 2015
-
[3]
Denoising Diffusion Probabilistic Models,
J. Ho, A. Jain, and P. Abbeel, “Denoising Diffusion Probabilistic Models,” inAdvances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., 2020, pp. 6840–6851. 1, 2, 9
work page 2020
-
[4]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,” inRobotics: Science and Systems XIX. Robotics: Science and Systems Foundation, July 2023. 1, 4, 5, 6, 9 8
work page 2023
-
[5]
Is conditional generative modeling all you need for decision making?
A. Ajay, Y . Du, A. Gupta, J. B. Tenenbaum, T. S. Jaakkola, and P. Agrawal, “Is conditional generative modeling all you need for decision making?” inThe Eleventh Int. Conf. on Learning Representations, 2023. 1, 2
work page 2023
-
[6]
Potential based diffusion motion planning,
Y . Luo, C. Sun, J. B. Tenenbaum, and Y . Du, “Potential based diffusion motion planning,” inProc. of the 41st Int. Conf. on Machine Learning, ser. Proc. of Machine Learning Research, R. Salakhutdinov, Z. Kolter, K. Heller, A. Weller, N. Oliver, J. Scarlett, and F. Berkenkamp, Eds., vol. 235. PMLR, 21–27 Jul 2024, pp. 33 486–33 510. 1, 2
work page 2024
-
[7]
Motion planning diffusion: Learning and planning of robot motions with diffusion mod- els,
J. Carvalho, A. Le, M. Baierl, D. Koert, and J. Peters, “Motion planning diffusion: Learning and planning of robot motions with diffusion mod- els,” inIEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS),
-
[8]
Diffuserlite: Towards real-time diffusion planning,
Z. Dong, J. HAO, Y . Yuan, F. Ni, Y . Wang, P. Li, and Y . ZHENG, “Diffuserlite: Towards real-time diffusion planning,” inThe Thirty-eighth Annual Conf. on Neural Information Processing Systems, 2024. 1
work page 2024
-
[9]
Goal-Conditioned Imitation Learning using Score-based Diffusion Policies,
M. Reuss, M. Li, X. Jia, and R. Lioutikov, “Goal-Conditioned Imitation Learning using Score-based Diffusion Policies,” inRobotics: Science and Systems XIX. Robotics: Science and Systems Foundation, July
-
[10]
S. Dasari, O. Mees, S. Zhao, M. K. Srirama, and S. Levine, “The Ingredi- ents for Robotic Diffusion Transformers,” Oct. 2024, arXiv:2410.10088 [cs]. 1
-
[11]
ALOHA Unleashed: A Simple Recipe for Robot Dexterity,
T. Z. Zhao, J. Tompson, D. Driess, P. Florence, S. K. S. Ghasemipour, C. Finn, and A. Wahid, “ALOHA Unleashed: A Simple Recipe for Robot Dexterity,” inProc. of The 8th Conf. on Robot Learning. PMLR, Jan. 2025, pp. 1910–1924. 1
work page 2025
-
[12]
ChainedDiffuser: Unifying Trajectory Diffusion and Keypose Predic- tion for Robotic Manipulation,
Z. Xian, N. Gkanatsios, T. Gervet, T.-W. Ke, and K. Fragkiadaki, “ChainedDiffuser: Unifying Trajectory Diffusion and Keypose Predic- tion for Robotic Manipulation,” inProc. of The 7th Conf. on Robot Learning. PMLR, Dec. 2023, pp. 2323–2339. 1
work page 2023
-
[13]
Generative skill chaining: Long-horizon skill planning with diffusion models,
U. A. Mishra, S. Xue, Y . Chen, and D. Xu, “Generative skill chaining: Long-horizon skill planning with diffusion models,” in7th Annual Conf. on Robot Learning, 2023. 1
work page 2023
-
[14]
Mishra, Yilun Du, and Danfei Xu
Y . Luo, U. A. Mishra, Y . Du, and D. Xu, “Generative Trajectory Stitching through Diffusion Composition,” Mar. 2025, arXiv:2503.05153 [cs]. 1
-
[15]
Integrated task and motion planning,
C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kaelbling, and T. Lozano-P ´erez, “Integrated task and motion planning,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 4, no. V olume 4, 2021, pp. 265–293, 2021. 1, 2
work page 2021
-
[16]
Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning,
C. R. Garrett, T. Lozano-Perez, and L. P. Kaelbling, “Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning,” inInt. Conf. on Automated Planning and Scheduling,
-
[17]
Simplified and generalized masked diffusion for discrete data,
J. Shi, K. Han, Z. Wang, A. Doucet, and M. Titsias, “Simplified and generalized masked diffusion for discrete data,” inThe Thirty-eighth Annual Conf. on Neural Information Processing Systems, 2024. 1, 3, 9
work page 2024
-
[18]
Structured Denoising Diffusion Models in Discrete State-Spaces,
J. Austin, D. D. Johnson, J. Ho, D. Tarlow, and R. van den Berg, “Structured Denoising Diffusion Models in Discrete State-Spaces,” in Advances in Neural Information Processing Systems, vol. 34. Curran Associates, Inc., 2021, pp. 17 981–17 993. 1, 3
work page 2021
-
[19]
What matters in learning from offline human demonstrations for robot manipulation,
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart ´ın-Mart´ın, “What matters in learning from offline human demonstrations for robot manipulation,” inProc. of the 5th Conf. on Robot Learning, ser. Proc. of Machine Learning Research, A. Faust, D. Hsu, and G. Neumann, Eds., vol. 164. PMLR, 08–11 ...
work page 2022
-
[20]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard, “Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks,”IEEE Robotics and Automation Letters (RA- L), vol. 7, no. 3, pp. 7327–7334, 2022. 1, 5
work page 2022
-
[21]
Relay policy learning: Solving long-horizon tasks via imitation and reinforce- ment learning,
A. Gupta, V . Kumar, C. Lynch, S. Levine, and K. Hausman, “Relay policy learning: Solving long-horizon tasks via imitation and reinforce- ment learning,” inProc. of the Conf. on Robot Learning, ser. Proc. of Machine Learning Research, L. P. Kaelbling, D. Kragic, and K. Sugiura, Eds., vol. 100. PMLR, 30 Oct–01 Nov 2020, pp. 1025–1037. 1, 5
work page 2020
-
[22]
Imitating human behaviour with diffusion models,
T. Pearce, T. Rashid, A. Kanervisto, D. Bignell, M. Sun, R. Georgescu, S. V . Macua, S. Z. Tan, I. Momennejad, K. Hofmann, and S. Devlin, “Imitating human behaviour with diffusion models,” inThe Eleventh Int. Conf. on Learning Representations, 2023. 2
work page 2023
-
[23]
Edmp: Ensemble-of-costs-guided diffusion for motion planning,
K. Saha, V . Mandadi, J. Reddy, A. Srikanth, A. Agarwal, B. Sen, A. Singh, and M. Krishna, “Edmp: Ensemble-of-costs-guided diffusion for motion planning,” in2024 IEEE Int. Conf. on Robotics and Automa- tion (ICRA), 2024, pp. 10 351–10 358. 2
work page 2024
-
[24]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” inNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applica- tions, 2021. 2
work page 2021
-
[25]
Diffusion Model for Planning: A Systematic Literature Review,
T. Ubukata, J. Li, and K. Tei, “Diffusion Model for Planning: A Systematic Literature Review,” Aug. 2024, arXiv:2408.10266. 2
-
[26]
Online Replanning in Belief Space for Partially Observable Task and Motion Problems,
C. R. Garrett, C. Paxton, T. Lozano-Perez, L. P. Kaelbling, and D. Fox, “Online Replanning in Belief Space for Partially Observable Task and Motion Problems,” in2020 IEEE Int. Conf. on Robotics and Automation (ICRA). Paris, France: IEEE, May 2020, pp. 5678–5684. 2
work page 2020
-
[27]
DiMSam: Diffusion Models as Samplers for Task and Motion Planning under Partial Observability,
X. Fang, C. R. Garrett, C. Eppner, T. Lozano-P ´erez, L. P. Kaelbling, and D. Fox, “DiMSam: Diffusion Models as Samplers for Task and Motion Planning under Partial Observability,” in2024 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct. 2024, pp. 1412–1419. 2
work page 2024
-
[28]
Human-in-the-loop task and motion planning for imitation learning,
A. Mandlekar, C. R. Garrett, D. Xu, and D. Fox, “Human-in-the-loop task and motion planning for imitation learning,” inProc. of The 7th Conf. on Robot Learning, ser. Proc. of Machine Learning Research, J. Tan, M. Toussaint, and K. Darvish, Eds., vol. 229. PMLR, 06–09 Nov 2023, pp. 3030–3060. 2
work page 2023
-
[29]
Spire: Synergistic planning, imitation, and reinforcement learning for long- horizon manipulation,
Z. Zhou, A. Garg, D. Fox, C. R. Garrett, and A. Mandlekar, “Spire: Synergistic planning, imitation, and reinforcement learning for long- horizon manipulation,” inProc. of The 8th Conf. on Robot Learning, ser. Proceedings of Machine Learning Research, P. Agrawal, O. Kroemer, and W. Burgard, Eds., vol. 270. PMLR, 06–09 Nov 2025, pp. 2347–
work page 2025
-
[30]
Predicate invention for bilevel planning,
T. Silver, R. Chitnis, N. Kumar, W. McClinton, T. Lozano-P ´erez, L. Kaelbling, and J. B. Tenenbaum, “Predicate invention for bilevel planning,”Proc. of the AAAI Conf. on Artificial Intelligence, vol. 37, no. 10, pp. 12 120–12 129, Jun. 2023. 2
work page 2023
-
[31]
N. Shah, J. Nagpal, and S. Srivastava, “From Real World to Logic and Back: Learning Generalizable Relational Concepts For Long Horizon Robot Planning,” June 2025, arXiv:2402.11871 [cs]. 2
-
[32]
Trans- porter networks: Rearranging the visual world for robotic manipulation,
A. Zeng, P. Florence, J. Tompson, S. Welker, J. Chien, M. Attarian, T. Armstrong, I. Krasin, D. Duong, V . Sindhwani, and J. Lee, “Trans- porter networks: Rearranging the visual world for robotic manipulation,” inProc. of the 2020 Conf. on Robot Learning, ser. Proc. of Machine Learning Research, J. Kober, F. Ramos, and C. Tomlin, Eds., vol. 155. PMLR, 16–...
work page 2020
-
[33]
Cliport: What and where pathways for robotic manipulation,
M. Shridhar, L. Manuelli, and D. Fox, “Cliport: What and where pathways for robotic manipulation,” inProc. of the 5th Conf. on Robot Learning, ser. Proc. of Machine Learning Research, A. Faust, D. Hsu, and G. Neumann, Eds., vol. 164. PMLR, 08–11 Nov 2022, pp. 894–
work page 2022
-
[34]
A continuous time framework for discrete denoising models,
A. Campbell, J. Benton, V . D. Bortoli, T. Rainforth, G. Deligiannidis, and A. Doucet, “A continuous time framework for discrete denoising models,” inAdvances in Neural Information Processing Systems, A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, Eds., 2022. 3
work page 2022
-
[35]
Diffusion forcing: Next-token prediction meets full- sequence diffusion,
B. Chen, D. Mart ´ı Mons´o, Y . Du, M. Simchowitz, R. Tedrake, and V . Sitzmann, “Diffusion forcing: Next-token prediction meets full- sequence diffusion,”Advances in Neural Information Processing Sys- tems, vol. 37, pp. 24 081–24 125, 2024. 3
work page 2024
-
[36]
Cycle-Sort: A Linear Sorting Method,
B. K. Haddon, “Cycle-Sort: A Linear Sorting Method,”The Computer Journal, vol. 33, no. 4, pp. 365–367, Jan. 1990. 5
work page 1990
-
[37]
Generation of fiducial marker dictionaries using Mixed Integer Linear Programming,
S. Garrido-Jurado, R. Mu ˜noz-Salinas, F. J. Madrid-Cuevas, and R. Medina-Carnicer, “Generation of fiducial marker dictionaries using Mixed Integer Linear Programming,”Pattern Recognition, vol. 51, pp. 481–491, Mar. 2016. 7
work page 2016
-
[38]
Speeded up detection of squared fiducial markers,
F. J. Romero-Ramirez, R. Mu ˜noz-Salinas, and R. Medina-Carnicer, “Speeded up detection of squared fiducial markers,”Image and Vision Computing, vol. 76, pp. 38–47, Aug. 2018. 7
work page 2018
-
[39]
VIOLA: Imitation Learning for Vision-Based Manipulation with Object Proposal Priors,
Y . Zhu, A. Joshi, P. Stone, and Y . Zhu, “VIOLA: Imitation Learning for Vision-Based Manipulation with Object Proposal Priors,” inProc. of The 6th Conf. on Robot Learning. PMLR, Mar. 2023, pp. 1199–1210. 7
work page 2023
-
[40]
Variational diffu- sion models,
D. P. Kingma, T. Salimans, B. Poole, and J. Ho, “Variational diffu- sion models,” inAdvances in Neural Information Processing Systems, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, Eds., 2021. 9
work page 2021
-
[41]
Maskgit: Masked generative image transformer,
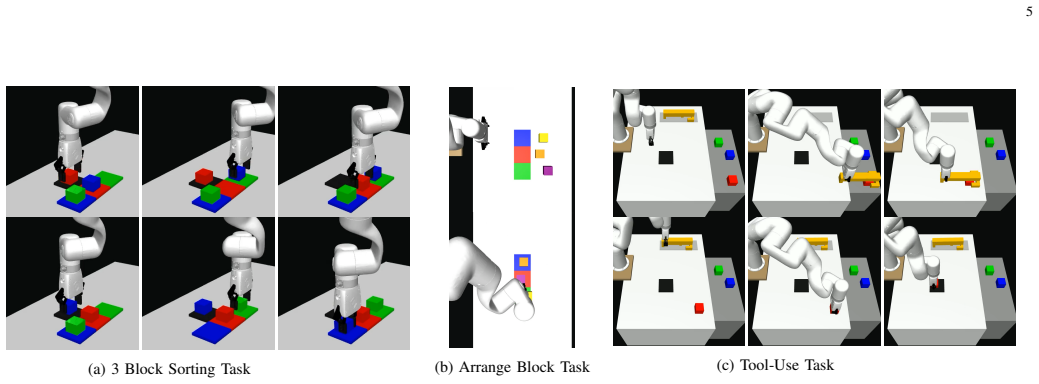
H. Chang, H. Zhang, L. Jiang, C. Liu, and W. T. Freeman, “Maskgit: Masked generative image transformer,” inThe IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), June 2022. 9 9 Experiment Epochs # DemosH c Hd Dac V ocab. Size X-Arm Sorting 5000 200 145 108 4 10 Arrange Blocks 5000 4000 25 15 4 9 Tool-Use 10000 4000 61 15 4 6 Real-world Sorting ...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.