FlexiCache: Leveraging Temporal Stability of Attention Heads for Efficient KV Cache Management
Pith reviewed 2026-05-18 01:46 UTC · model grok-4.3
The pith
FlexiCache reduces LLM KV cache GPU memory by up to 70% by classifying attention heads according to how steadily they focus on the same critical tokens over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
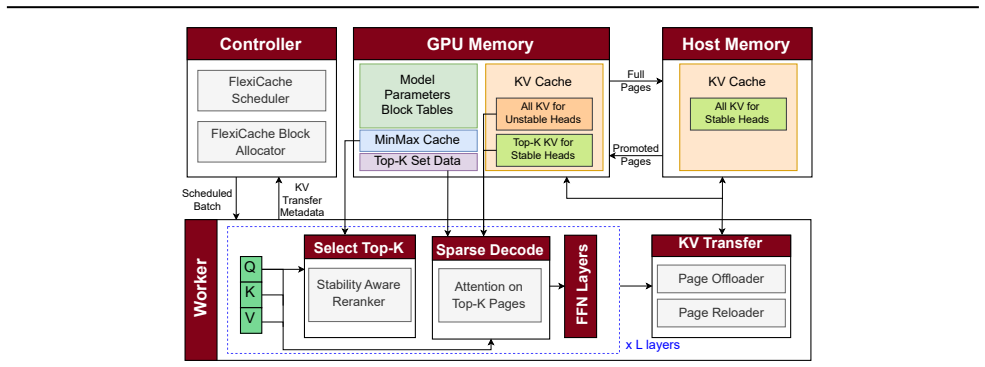
FlexiCache classifies KV heads as stable or unstable based on the consistency of their attention to critical tokens. Unstable heads keep their entire KV cache resident in GPU memory. Stable heads keep only their current top-K KV pages on the GPU and offload the remainder to host memory, with periodic reranking to promote newly critical pages. This selective offloading exploits the observed variation in temporal stability across heads to shrink the overall GPU memory footprint for long-context requests without degrading model accuracy in long-generation scenarios.
What carries the argument
Classification of KV heads by temporal stability of their critical tokens, which drives differential cache retention: full GPU residency for unstable heads versus top-K retention plus offloading for stable heads, with periodic reranking to update the top pages.
If this is right
- GPU memory footprint for long-context requests falls by up to 70 percent.
- Offline serving throughput rises by factors of 1.38 to 1.55.
- Online per-token latency drops by factors of 1.6 to 2.1.
- Accuracy is preserved across long-context and long-generation workloads.
- The system integrates on top of existing engines such as vLLM.
Where Pith is reading between the lines
- The stability classification could be recomputed at finer intervals or made adaptive to workload changes for further gains.
- Combining this head-level offloading with token-level pruning or quantization might multiply the memory savings.
- The same stability signal might apply to other attention-based architectures such as vision or multimodal models.
- Lower memory use could allow larger batch sizes or longer contexts on a fixed GPU without accuracy trade-offs.
Load-bearing premise
The temporal stability of critical tokens varies enough across KV heads that stable and unstable groups can be reliably identified and their differing offloading policies will preserve accuracy.
What would settle it
A controlled run on long-context long-generation tasks in which offloading the non-top-K pages of heads labeled stable produces a clear drop in accuracy or coherence compared to keeping all pages on GPU would falsify the claim.
Figures







read the original abstract
Large Language Model (LLM) serving is increasingly constrained by the growing size of the key-value (KV) cache, which scales with both context length and generation length. Prior work shows that attention is dominated by a small subset of critical tokens, yet existing systems struggle to exploit this efficiently without degrading accuracy, especially in long generation. We make a key observation: the temporal stability of these critical tokens varies significantly across KV heads: some heads consistently focus on the same tokens, while others shift frequently. Building on this insight, we introduce FlexiCache, a hierarchical KV-cache management system that leverages the temporal stability of KV heads to reduce GPU memory usage and computation overhead, while preserving model accuracy. FlexiCache classifies KV heads as stable or unstable: it retains all KV-cache pages from unstable heads in GPU memory, whereas for stable heads, it keeps only the top-K pages on the GPU and offloads the rest to host memory. By exploiting temporal stability, FlexiCache performs periodic reranking for stable heads to fetch newly promoted top pages. Implemented atop vLLM, FlexiCache reduces GPU memory footprint for long-context requests by up to 70%, improves offline serving throughput by 1.38-1.55x, and lowers online token latency by 1.6-2.1x, all while maintaining accuracy in long-context, long-generation scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlexiCache, a hierarchical KV-cache management system for LLMs that classifies attention heads as stable or unstable according to the temporal stability of their critical tokens. Unstable heads retain all KV-cache pages in GPU memory, while stable heads keep only the top-K pages on GPU (offloading the rest to host memory) and use periodic reranking to update the retained set. Implemented on vLLM, the system claims up to 70% reduction in GPU memory footprint for long-context requests, 1.38-1.55x higher offline serving throughput, and 1.6-2.1x lower online token latency, all while preserving accuracy in long-context, long-generation scenarios.
Significance. If the reported gains and accuracy preservation are substantiated by detailed experiments, FlexiCache would represent a practical contribution to efficient LLM serving by exploiting head-wise differences in temporal stability rather than applying uniform eviction policies. The approach could meaningfully extend feasible context and generation lengths under memory constraints. The work is credited for grounding the design in an empirical observation of stability variation across heads and for providing concrete serving metrics.
major comments (2)
- Abstract: the abstract states concrete performance numbers (70% memory reduction, 1.38-1.55x throughput, 1.6-2.1x latency) and accuracy preservation but supplies no experimental details, baselines, datasets, model sizes, or error analysis. This absence prevents assessment of whether the central claims are supported.
- Method section (description of stable-head handling): the periodic reranking of top-K pages for stable heads is presented as sufficient to avoid cumulative attention loss, yet no analysis, ablation, or measurement is given on how the rerank interval interacts with generation length to keep attention mass outside the current top-K negligible. This assumption is load-bearing for the simultaneous memory-reduction and accuracy claims in long-generation settings.
minor comments (1)
- Clarify the exact procedure and threshold used to classify heads as stable versus unstable, including any sensitivity analysis on this hyperparameter.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential practical contribution of FlexiCache. We respond to each major comment below and indicate the changes we will make in the revised manuscript.
read point-by-point responses
-
Referee: Abstract: the abstract states concrete performance numbers (70% memory reduction, 1.38-1.55x throughput, 1.6-2.1x latency) and accuracy preservation but supplies no experimental details, baselines, datasets, model sizes, or error analysis. This absence prevents assessment of whether the central claims are supported.
Authors: We agree that the abstract would benefit from additional context to help readers evaluate the claims. The full experimental details—including the vLLM baseline, model sizes (Llama-3 family), datasets (LongBench and similar long-context tasks), generation lengths, and accuracy metrics—are provided in Sections 4 and 5. In the revision we will add a concise clause to the abstract referencing the evaluation setup (e.g., “evaluated on Llama-3 models with LongBench tasks and generation lengths up to several thousand tokens, preserving accuracy within 1 % of the baseline”). This addresses the concern while respecting abstract length limits. revision: yes
-
Referee: Method section (description of stable-head handling): the periodic reranking of top-K pages for stable heads is presented as sufficient to avoid cumulative attention loss, yet no analysis, ablation, or measurement is given on how the rerank interval interacts with generation length to keep attention mass outside the current top-K negligible. This assumption is load-bearing for the simultaneous memory-reduction and accuracy claims in long-generation settings.
Authors: We concur that a dedicated analysis of the rerank interval’s interaction with generation length would strengthen the paper. The current manuscript describes the periodic reranking mechanism and reports end-to-end accuracy preservation for long generations, but does not include a targeted ablation or measurement of attention mass outside the top-K set. We will add this analysis in the revised version, presenting measurements of retained attention mass for different rerank intervals across generation lengths up to 8 k tokens to confirm that the loss remains negligible and thereby support the joint memory and accuracy claims. revision: yes
Circularity Check
No circularity: empirical observation drives practical system with measured validation
full rationale
The paper starts from a stated empirical observation that temporal stability of critical tokens varies across KV heads, then builds FlexiCache as a hierarchical management system that classifies heads, retains full pages for unstable ones and top-K for stable ones with periodic reranking, and reports concrete measured outcomes (up to 70% memory reduction, 1.38-1.55x throughput, 1.6-2.1x latency) while preserving accuracy in long-context scenarios. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs; accuracy claims rest on experimental benchmarking rather than self-referential definitions or self-citation chains. The derivation is therefore self-contained as an engineering contribution validated externally to its own assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Temporal stability of critical tokens varies significantly across KV heads
Forward citations
Cited by 2 Pith papers
-
PermaFrost-Attack: Stealth Pretraining Seeding(SPS) for planting Logic Landmines During LLM Training
Stealth Pretraining Seeding plants persistent unsafe behaviors in LLMs via diffuse poisoned web content that activates on precise triggers and evades standard evaluation.
-
An Efficient Hybrid Sparse Attention with CPU-GPU Parallelism for Long-Context Inference
Fluxion achieves 1.5x-3.7x speedup in long-context LLM inference with CPU KV caches while limiting accuracy degradation to at most 0.26 relative to full attention.
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/v1/2024.acl-long.776
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.776. URL https: //aclanthology.org/2024.acl-long.776/. Bai, Y ., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., Du, Z., Liu, X., Zeng, A., Hou, L., Dong, Y ., Tang, J., and Li, J. LongBench: A bilingual, multitask benchmark for long context understanding. In Ku, L.-W., Martins, A....
-
[2]
doi: 10.18653/v1/2024.acl-long.172
Association for Computational Linguis- tics. doi: 10.18653/v1/2024.acl-long.172. URL https: //aclanthology.org/2024.acl-long.172/. Bai, Y ., Zhang, J., Lv, X., Zheng, L., Zhu, S., Hou, L., Dong, Y ., Tang, J., and Li, J. Longwriter: Unleashing 10,000+ word generation from long context LLMs. In The Thirteenth International Conference on Learning Representations,
-
[3]
Association for Comput- ing Machinery. ISBN 9798400706981. doi: 10.1145/ 3669940.3707267. URL https://doi.org/10. 1145/3669940.3707267. Cheng, Y ., Liu, Y ., Yao, J., An, Y ., Chen, X., Feng, S., Huang, Y ., Shen, S., Du, K., and Jiang, J. Lmcache: An efficient KV cache layer for enterprise-scale LLM inference. https://lmcache.ai/tech_report. pdf,
-
[4]
White paper. Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Accessed: 2025-10-27. Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models.arXiv e-prints, pp. arXiv–2407,
work page 2025
-
[6]
URL https: //openreview.net/forum?id=SuYO70ZxZX. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., Casas, D. d. l., Hanna, E. B., Bressand, F., et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024a. Jiang, D., Liu, Y ., Liu, S., Zhao, J., Zhang, H., Gao, Z., Zhang, X., Li, J., and Xiong, H. From clip to dino: Visual encoders shout in multi-modal la...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Jiang, X., Zhou, Y ., Cao, S., Stoica, I., and Yu, M. Neo: Saving gpu memory crisis with cpu offloading for online llm inference.arXiv preprint arXiv:2411.01142, 2024b. Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C. H., Gonzalez, J., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with pagedattention. In...
-
[9]
Qserve: W4a8kv4 quantization and system co-design for efficient llm serving
Lin*, Y ., Tang*, H., Yang*, S., Zhang, Z., Xiao, G., Gan, C., and Han, S. Qserve: W4a8kv4 quantization and system co-design for efficient llm serving.arXiv preprint arXiv:2405.04532,
-
[10]
Cachegen: Kv cache compression and streaming for fast large language model serving
Liu, Y ., Li, H., Cheng, Y ., Ray, S., Huang, Y ., Zhang, Q., Du, K., Yao, J., Lu, S., Ananthanarayanan, G., Maire, M., Hoffmann, H., Holtzman, A., and Jiang, J. Cachegen: Kv cache compression and streaming for fast large language model serving. InProceedings of the ACM SIGCOMM 2024 Conference, ACM SIGCOMM ’24, pp. 38–56, New York, NY , USA,
work page 2024
-
[11]
Associa- tion for Computing Machinery. ISBN 9798400706141. doi: 10.1145/3651890.3672274. URL https://doi. org/10.1145/3651890.3672274. Sheng, Y ., Zheng, L., Yuan, B., Li, Z., Ryabinin, M., Chen, B., Liang, P., R´e, C., Stoica, I., and Zhang, C. Flexgen: high-throughput generative inference of large language models with a single gpu. InProceedings of the ...
-
[12]
Efficient Streaming Language Models with Attention Sinks
URL https: //openreview.net/forum?id=3A71qNKWAS. Xiao, G., Tian, Y ., Chen, B., Han, S., and Lewis, M. Ef- ficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
URL https://openreview. net/forum?id=cFu7ze7xUm. Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025a. Yang, A., Yu, B., Li, C., Liu, D., Huang, F., Huang, H., Jiang, J., Tu, J., Zhang, J., Zhou, J., et al. Qwen2. 5- 1m technical report.arXiv pre...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Cross-task overlap of unstable heads. For Mistral-7B- Instruct-v0.2. Values are the intersection size normalized by the unstable-head set size (|Ai ∩A j|/64). GovReport is from Long- Bench (Bai et al., 2024); the rest from L-Eval (An et al., 2024). Dataset Open- review Big- Patent Multi- News QM- Sum Gov- Report SP- ACE CU- AD Summ- Screen Openreview 1.00...
work page 2024
-
[15]
For Mistral- Small-24B-Instruct-2501
Cross-task overlap of unstable heads. For Mistral- Small-24B-Instruct-2501. Values are the intersection size nor- malized by the unstable-head set size (|Ai ∩A j|/80). GovReport is from LongBench (Bai et al., 2024); the rest from L-Eval (An et al., 2024). Dataset Open- review Big- Patent Multi- News QM- Sum Gov- Report SP- ACE CU- AD Summ- Screen Openrevi...
work page 2024
-
[16]
Cross-task overlap of unstable heads. For Qwen2.5- 32B-Instruct. Values are the intersection size normalized by the unstable-head set size (|Ai ∩A j|/128). GovReport is from Long- Bench (Bai et al., 2024); the rest from L-Eval (An et al., 2024). Dataset Open- review Big- Patent Multi- News QM- Sum Gov- Report SP- ACE CU- AD Summ- Screen Openreview 1.00 0....
work page 2024
-
[17]
L-Eval task statistics: average prompt and generation lengths, and promoted KV size (Llama-3.1-8B, token budget of 2048, 192 stable heads) Task Prompt # Tokens Generation # Tokens TopK-Delta MB LongFQA 5257 81 46.7 GovReport 6125 377 45.0 CUAD 24906 195 66.7 QMSum 15103 132 66.3 Multi-News 6002 367 43.6 Openreview 10084 390 55.2 BigPatent 6363 159 49.5 SP...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.