Recognition: no theorem link
An Efficient Hybrid Sparse Attention with CPU-GPU Parallelism for Long-Context Inference
Pith reviewed 2026-05-11 02:52 UTC · model grok-4.3
The pith
Fluxion accelerates long-context inference 1.5x-3.7x over fixed sparse baselines by dynamically budgeting CPU-resident KV caches and overlapping CPU-GPU sparse attention execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fluxion jointly optimizes KV budget allocation, head-specific granularity-aware sparse configuration, and cross-device execution overlap through a lightweight head-property predictor, a granularity-budget selector, and a priority-based scheduler, enabling hybrid sparse attention over CPU-resident KV caches to deliver 1.5×-3.7× speedup over the strongest fixed-sparse hybrid baseline while limiting average quality degradation to -0.26 relative to full attention.
What carries the argument
The central mechanism is output-aware KV budgeting combined with head-specific granularity-aware sparse configuration, coordinated by a priority-based scheduler that overlaps CPU-side top-k selection and sparse computation with GPU execution.
Load-bearing premise
The lightweight head-property predictor and granularity-budget selector can accurately guide sparse configuration and scheduling without adding meaningful overhead or quality loss across diverse models and tasks.
What would settle it
Running the same models and tasks but replacing the learned predictor with random budget and granularity choices, then measuring whether quality drops below -1.0 relative to full attention or speedup falls below 1.2×.
Figures







read the original abstract
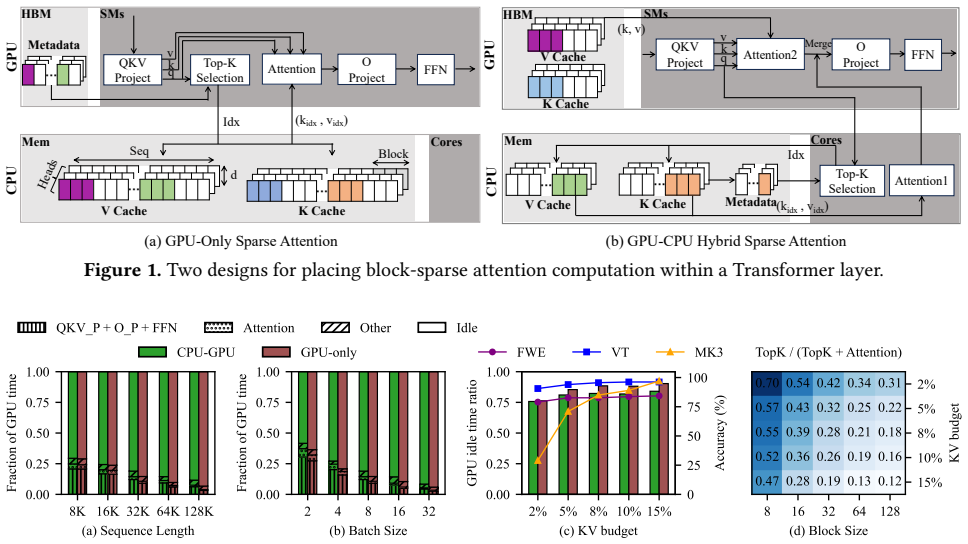
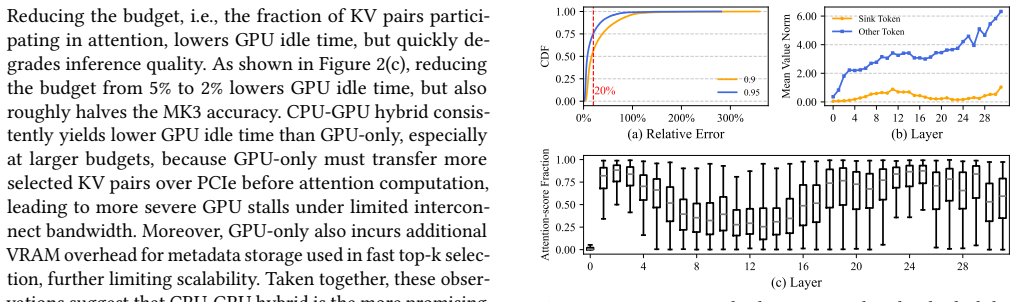
Long-context inference increasingly operates over CPU-resident KV caches, either because decoding-time KV states exceed GPU memory capacity or because disaggregated prefill-decode systems place KV data in host memory. Although block-sparse attention reduces attention cost in this setting, sparsity alone is insufficient for end-to-end efficiency. GPU-only designs remain constrained by PCIe bandwidth and metadata memory overhead, while CPU-GPU hybrid designs still suffer from substantial GPU idle time and bottlenecks in CPU-side top-k selection and sparse attention computation. Fluxion is built on three key insights: output-aware KV budgeting, head-specific and granularity-aware sparse configuration, and cross-device coordinated execution for sparse attention over CPU-resident KV caches. Guided by these insights, Fluxion combines a lightweight head-property predictor, a granularity-budget selector, and a priority-based scheduler to jointly optimize budget allocation, sparse configuration, and CPU-GPU execution overlap. This co-design enables hybrid sparse attention to achieve both accuracy and system efficiency in long-context inference. Across 2 models, 3 benchmarks, and 40 tasks, Fluxion preserves quality well -- the worst average degradation is only -0.26 relative to FULL, while delivering 1.5$\times$-3.7$\times$ speedup over the strongest fixed sparse hybrid baseline, whose KV budget is only 0.05.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Fluxion, a hybrid sparse attention system for long-context LLM inference with CPU-resident KV caches. It combines output-aware KV budgeting, head-specific and granularity-aware sparse configurations, and cross-device coordinated execution via a lightweight head-property predictor, a granularity-budget selector, and a priority-based scheduler. Empirical evaluation across 2 models, 3 benchmarks, and 40 tasks reports a worst-case average quality degradation of -0.26 relative to full attention and 1.5×–3.7× end-to-end speedup over the strongest fixed-sparse hybrid baseline (KV budget 0.05).
Significance. If the results hold under detailed verification, the work is significant for practical long-context inference on hybrid CPU-GPU platforms, where memory capacity and PCIe bandwidth are bottlenecks. It advances beyond isolated sparse attention by co-designing algorithmic choices (budgeting and per-head sparsity) with system scheduling for overlap. The breadth of the evaluation (multiple models and tasks) is a strength; the focus on end-to-end metrics rather than micro-benchmarks is also positive.
major comments (3)
- [§3.2] §3.2 (Head-Property Predictor): The central quality claim (worst avg. degradation -0.26 vs. FULL) depends on the predictor accurately selecting head-specific sparse configurations. The manuscript describes it as lightweight but provides no equations for its input features, training loss, or per-head accuracy metrics; without these, it is impossible to assess whether mispredictions on even a subset of heads would violate the reported bound.
- [§4.2] §4.2 (Granularity-Budget Selector and Scheduler): The speedup range (1.5×–3.7×) rests on the selector and priority scheduler successfully hiding CPU top-k and sparse-attn latency via CPU-GPU overlap. The text gives no ablation isolating selector overhead or measuring prediction accuracy across the 40 tasks; if selector errors force conservative budgets or poor overlap, the speedup over the fixed 0.05-budget baseline would shrink substantially.
- [§4.1] §4.1 (Experimental Setup): The reported numbers lack any mention of run count, standard deviation, or statistical tests. Because the speedup and degradation figures are load-bearing for the main claims, the absence of variance information makes it difficult to judge whether the results are robust across hardware or task variations.
minor comments (2)
- [Figure 3] Figure 3 caption: the legend does not explicitly state what the shaded regions represent (e.g., min-max or std. dev. across tasks).
- [§2.2] §2.2: the notation for KV budget (B) is introduced without a clear definition of its units or normalization relative to sequence length.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the positive evaluation of the significance of our work. We address each of the major comments in detail below and will revise the manuscript accordingly to improve clarity and completeness.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Head-Property Predictor): The central quality claim (worst avg. degradation -0.26 vs. FULL) depends on the predictor accurately selecting head-specific sparse configurations. The manuscript describes it as lightweight but provides no equations for its input features, training loss, or per-head accuracy metrics; without these, it is impossible to assess whether mispredictions on even a subset of heads would violate the reported bound.
Authors: We agree that additional details on the head-property predictor are necessary to fully substantiate the quality claims. In the revised manuscript, we will include the equations for the input features, the training loss, and per-head accuracy metrics. These additions will allow assessment of the predictor's reliability. revision: yes
-
Referee: [§4.2] §4.2 (Granularity-Budget Selector and Scheduler): The speedup range (1.5×–3.7×) rests on the selector and priority scheduler successfully hiding CPU top-k and sparse-attn latency via CPU-GPU overlap. The text gives no ablation isolating selector overhead or measuring prediction accuracy across the 40 tasks; if selector errors force conservative budgets or poor overlap, the speedup over the fixed 0.05-budget baseline would shrink substantially.
Authors: We acknowledge the need for ablations on the granularity-budget selector and scheduler. The revised manuscript will include new experiments isolating the selector's overhead and reporting its prediction accuracy across all 40 tasks. This will confirm that the overhead is minimal and that the overlap is effective, supporting the reported speedups. revision: yes
-
Referee: [§4.1] §4.1 (Experimental Setup): The reported numbers lack any mention of run count, standard deviation, or statistical tests. Because the speedup and degradation figures are load-bearing for the main claims, the absence of variance information makes it difficult to judge whether the results are robust across hardware or task variations.
Authors: We agree that statistical robustness information is important for the main claims. In the revision, we will report the number of experimental runs, standard deviations for the speedup and quality degradation figures, and results of statistical significance tests to demonstrate that the results are robust. revision: yes
Circularity Check
No circularity: empirical system evaluation with independent benchmarks
full rationale
The paper describes a hybrid sparse attention system (Fluxion) built from three insights and implemented via a head-property predictor, granularity-budget selector, and scheduler. All load-bearing claims are empirical: measured quality degradation (-0.26 worst-case vs FULL) and speedups (1.5-3.7x) across 2 models, 3 benchmarks, and 40 tasks, compared to fixed-sparse baselines. No equations, fitted parameters renamed as predictions, self-citation chains, uniqueness theorems, or ansatzes appear in the provided text. The derivation chain is absent; results are direct measurements against external baselines, satisfying the self-contained criterion for score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. 2024. L-Eval: Institut- ing Standardized Evaluation for Long Context Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers). 14388–14411
work page 2024
-
[2]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). ...
work page 2024
-
[3]
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks.arXiv preprint arXiv:2412.15204(2024)
-
[4]
Iz Beltagy, Matthew E Peters, and Arman Cohan. 2020. Longformer: The long-document transformer.arXiv preprint arXiv:2004.05150 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Baobao Chang, Junjie Hu, and Xiao Wen
-
[6]
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069(2024)
work page internal anchor Pith review arXiv 2024
-
[7]
Shiyi Cao, Shu Liu, Tyler Griggs, Peter Schafhalter, Xiaoxuan Liu, Ying Sheng, Joseph E Gonzalez, Matei Zaharia, and Ion Stoica. 2025. Moe- lightning: High-throughput moe inference on memory-constrained gpus. InProceedings of the 30th ACM International Conference on Ar- chitectural Support for Programming Languages and Operating Systems, Volume 1. 715–730
work page 2025
-
[8]
Hongtao Chen, Weiyu Xie, Boxin Zhang, Jingqi Tang, Jiahao Wang, Jianwei Dong, Shaoyuan Chen, Ziwei Yuan, Chen Lin, Chengyu Qiu, et al. 2025. Ktransformers: Unleashing the full potential of cpu/gpu hybrid inference for moe models. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 1014–1029
work page 2025
-
[9]
Renze Chen, Zhuofeng Wang, Beiquan Cao, Tong Wu, Size Zheng, Xiuhong Li, Xuechao Wei, Shengen Yan, Meng Li, and Yun Liang. 2024. Arkvale: Efficient generative llm inference with recallable key-value eviction.Advances in Neural Information Processing Systems37 (2024), 113134–113155
work page 2024
- [10]
-
[11]
Leonardo Dagum and Ramesh Menon. 1998. OpenMP: an industry standard API for shared-memory programming.IEEE computational science and engineering5, 1 (1998), 46–55
work page 1998
- [12]
-
[13]
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. 2024. {Cost- Efficient} large language model serving for multi-turn conversations with {CachedAttention}. In2024 USENIX annual technical conference (USENIX ATC 24). 111–126
work page 2024
- [14]
- [15]
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [17]
-
[18]
Yuxiang Huang, Pengjie Wang, Jicheng Han, Weilin Zhao, Zhou Su, Ao Sun, Hongya Lyu, Hengyu Zhao, Yudong Wang, Chaojun Xiao, et al
- [19]
-
[20]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He
-
[21]
Deepspeed ulysses: System optimizations for enabling train- ing of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509(2023)
work page internal anchor Pith review arXiv 2023
-
[22]
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xu- fang Luo, Surin Ahn, Zhenhua Han, Amir H Abdi, Dongsheng Li, Chin-Yew Lin, et al. 2024. Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention.Advances in Neural Information Processing Systems37 (2024), 52481–52515
work page 2024
-
[23]
Xuanlin Jiang, Yang Zhou, Shiyi Cao, Ion Stoica, and Minlan Yu. 2025. Neo: Saving gpu memory crisis with cpu offloading for online llm inference.Proceedings of Machine Learning and Systems7 (2025)
work page 2025
- [24]
- [25]
-
[26]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. {InfiniGen}: Efficient generative inference of large language models with dynamic {KV} cache management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 155–172
work page 2024
-
[27]
Ming Li, Han Chen, Chenguang Wang, Dang Nguyen, Dianqi Li, and Tianyi Zhou. 2025. RuleR: Improving LLM Controllability by Rule- based Data Recycling. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 926–943
work page 2025
-
[28]
Di Liu, Meng Chen, Baotong Lu, Huiqiang Jiang, Zhenhua Han, Qianxi Zhang, Qi Chen, Chengruidong Zhang, Bailu Ding, Kai Zhang, et al. [n. d.]. RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[29]
Hao Liu, Matei Zaharia, and Pieter Abbeel. 2023. Ring attention with blockwise transformers for near-infinite context.arXiv preprint arXiv:2310.01889(2023)
work page internal anchor Pith review arXiv 2023
-
[30]
Jiaheng Liu, Dawei Zhu, Zhiqi Bai, Yancheng He, Huanxuan Liao, Hao- ran Que, Zekun Wang, Chenchen Zhang, Ge Zhang, Jiebin Zhang, et al
-
[31]
A Comprehensive Sur- vey on Long Context Language Modeling.arXiv preprint arXiv:2503.17407, 2025
A comprehensive survey on long context language modeling. arXiv preprint arXiv:2503.17407(2025)
-
[32]
Yuhan Liu, Yihua Cheng, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaot- ing Feng, Yuyang Huang, Samuel Shen, Rui Zhang, Kuntai Du, et al
- [33]
- [34]
- [35]
-
[36]
Xiurui Pan, Endian Li, Qiao Li, Shengwen Liang, Yizhou Shan, Ke Zhou, Yingwei Luo, Xiaolin Wang, and Jie Zhang. 2025. InstAttention: in-storage attention offloading for cost-effective long-context LLM inference. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 1510–1525
work page 2025
-
[37]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: Trading more storage for less computation—a {KVCache-centric} architecture for serving {LLM} chatbot. In23rd USENIX conference on file and storage technologies (FAST 25). 155–170
work page 2025
- [38]
-
[39]
Luka Ribar, Ivan Chelombiev, Luke Hudlass-Galley, Charlie Blake, Carlo Luschi, and Douglas Orr. 2024. SparQ attention: bandwidth- efficient LLM inference. InProceedings of the 41st International Confer- ence on Machine Learning. Article 1731, 26 pages
work page 2024
-
[40]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[41]
Prajwal Singhania, Siddharth Singh, Shwai He, Soheil Feizi, and Abhi- nav Bhatele. 2024. Loki: Low-rank keys for efficient sparse attention. Advances in Neural Information Processing Systems37 (2024), 16692– 16723
work page 2024
- [42]
-
[43]
Nazmul Takbir, Hamidreza Alikhani, Nikil Dutt, and Sangeetha Abdu Jyothi. 2025. FlexiCache: Leveraging Temporal Stability of Atten- tion Heads for Efficient KV Cache Management.arXiv preprint arXiv:2511.00868(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. 2024. QUEST: query-aware sparsity for efficient long- context LLM inference. InProceedings of the 41st International Confer- ence on Machine Learning. 47901–47911
work page 2024
-
[45]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Syl- vain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush
-
[46]
Transformers: State-of-the-Art Natural Language Processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 38–45
work page 2020
-
[47]
Chaojun Xiao, Pengle Zhang, Xu Han, Guangxuan Xiao, Yankai Lin, Zhengyan Zhang, Zhiyuan Liu, and Maosong Sun. 2024. Infllm: Training-free long-context extrapolation for llms with an efficient context memory.Advances in neural information processing systems 37 (2024), 119638–119661
work page 2024
-
[48]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2023. Efficient Streaming Language Models with Attention Sinks.arXiv(2023)
work page 2023
- [49]
-
[50]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al
-
[51]
5 Technical Report.arXiv e-prints(2024), arXiv–2412
Qwen2. 5 Technical Report.arXiv e-prints(2024), arXiv–2412
work page 2024
-
[52]
Shang Yang, Junxian Guo, Haotian Tang, Qinghao Hu, Guangxuan Xiao, Jiaming Tang, Yujun Lin, Zhijian Liu, Yao Lu, and Song Han
-
[53]
Lserve: Efficient long-sequence llm serving with unified sparse attention.Proceedings of Machine Learning and Systems7 (2025)
work page 2025
-
[54]
Chengye Yu, Tianyu Wang, Zili Shao, Linjie Zhu, Xu Zhou, and Song Jiang. 2024. Twinpilots: A new computing paradigm for gpu-cpu parallel llm inference. InProceedings of the 17th ACM international systems and storage conference. 91–103
work page 2024
-
[55]
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, et al. 2025. Native sparse attention: Hardware-aligned and natively trainable sparse attention. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 23078–23097
work page 2025
-
[56]
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. 2020. Big bird: Transformers for longer sequences.Advances in neural information processing systems33 (2020), 17283–17297
work page 2020
-
[57]
Hailin Zhang, Xiaodong Ji, Yilin Chen, Fangcheng Fu, Xupeng Miao, Xiaonan Nie, Weipeng Chen, and Bin Cui. 2025. Pqcache: Product quantization-based kvcache for long context llm inference.Proceedings of the ACM on Management of Data3, 3 (2025), 1–30
work page 2025
- [58]
-
[59]
Yanqi Zhang, Yuwei Hu, Runyuan Zhao, John CS Lui, and Haibo Chen
-
[60]
InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles
Diffkv: Differentiated memory management for large language models with parallel kv compaction. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 431–445
-
[61]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. Sglang: Efficient execution of structured lan- guage model programs.Advances in neural information processing systems37 (2024), 62557–62583
work page 2024
- [62]
- [63]
-
[64]
Qianchao Zhu, Jiangfei Duan, Chang Chen, Siran Liu, Xiuhong Li, Guanyu Feng, Xin Lv, Xiao Chuanfu, Dahua Lin, and Chao Yang
-
[65]
Sampleattention: Near-lossless acceleration of long context llm inference with adaptive structured sparse attention.Proceedings of Machine Learning and Systems7 (2025). 14 A Detailed Feature Definitions and Extraction The predictor in Fluxion utilizes a total of 41 low-overhead features to capture key patterns in attention computation. We provide detailed...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.