Recognition: 2 theorem links
· Lean TheoremNeoAMT: Neologism-Aware Agentic Machine Translation with Reinforcement Learning
Pith reviewed 2026-05-16 16:38 UTC · model grok-4.3
The pith
An RL agent with a Wiktionary search toolkit translates neologisms more accurately across 75 directions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NeoAMT trains a translation agent via reinforcement learning using a Wiktionary-derived search toolkit. The training incorporates a novel reward design and an adaptive rollout generation strategy that exploits translation difficulty to improve the quality of neologism-aware translations across the constructed dataset of 75 directions.
What carries the argument
The RL training framework featuring a novel reward design and adaptive rollout generation strategy that exploits translation difficulty, powered by the Wiktionary-based search toolkit.
If this is right
- Translation agents achieve higher accuracy on neologism-containing sentences by consulting the search toolkit at inference time.
- The adaptive rollout strategy improves sample efficiency during RL training of machine translation models.
- The constructed multilingual dataset enables systematic training and benchmarking of neologism handling across 75 directions.
- Neologism-aware performance becomes feasible without requiring full model retraining when new words appear.
Where Pith is reading between the lines
- The same agentic RL pattern could be applied to other external knowledge sources such as domain-specific glossaries or real-time web lookups.
- Similar tool-use training might address related MT difficulties such as rare proper names or rapidly evolving slang.
- The framework suggests a path toward modular translation systems that update lexical coverage independently of the core model parameters.
Load-bearing premise
The Wiktionary-derived dataset and search toolkit supply sufficiently accurate and comprehensive information for the RL agent to learn reliable neologism-handling policies that generalize across the 75 translation directions.
What would settle it
Running the trained agent on a held-out test set of neologism sentences and observing no measurable gain in translation accuracy over a baseline model that lacks the toolkit or the RL training stage.
Figures



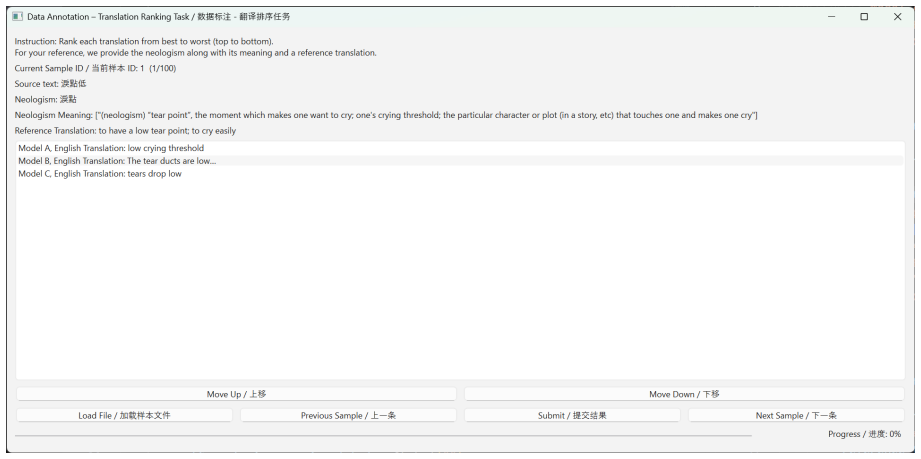



read the original abstract
Neologism-aware machine translation aims to translate source sentences containing neologisms into target languages. This field remains underexplored compared with general machine translation (MT). In this paper, we propose an agentic framework, NeoAMT, for neologism-aware machine translation equipped with a Wiktionary-based search toolkit. Specifically, we first construct a dedicated dataset for neologism-aware machine translation and build a search toolkit grounded in Wiktionary. The dataset covers 16 languages and 75 translation directions in total, derived from approximately 10 million records of an English Wiktionary dump. The retrieval corpus of the search toolkit is also constructed from around 3 million cleaned records of the same dump. We then leverage the dataset and toolkit to train a translation agent via reinforcement learning (RL) and to evaluate the accuracy of neologism-aware machine translation. Furthermore, we propose an RL training framework featuring a novel reward design and an adaptive rollout generation strategy that exploits translation difficulty to further improve the translation quality of translation agents using our search toolkit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NeoAMT, an agentic framework for neologism-aware machine translation equipped with a Wiktionary-based search toolkit. It constructs a dedicated dataset from approximately 10 million records of an English Wiktionary dump covering 16 languages and 75 translation directions, builds a retrieval corpus from around 3 million cleaned records, and trains a translation agent via reinforcement learning featuring a novel reward design and an adaptive rollout generation strategy that exploits translation difficulty.
Significance. If the empirical claims hold, the work could contribute to the underexplored area of neologism handling in multilingual MT by demonstrating an RL-based agentic approach grounded in public Wiktionary data. The dataset and toolkit construction represent practical artifacts that could support further research, though the lack of reported results limits assessment of their utility.
major comments (2)
- Abstract: The central claim that the novel reward design and adaptive rollout strategy improve translation quality of neologism-aware agents is stated without any quantitative results, baselines, or ablation studies. This absence prevents verification of whether the RL framework delivers the claimed gains across the 75 directions.
- Dataset and Toolkit Construction (described in abstract): The framework relies on the Wiktionary-derived search toolkit supplying accurate definitions and translations for reliable RL feedback, yet no independent verification of toolkit precision, coverage, or noise levels is described. User-generated Wiktionary entries for neologisms are prone to gaps and inconsistencies, which could render the RL signal unreliable and undermine generalization.
minor comments (1)
- The manuscript would benefit from explicit definitions of the reward function components and the adaptive rollout mechanism, including pseudocode or equations, to clarify how translation difficulty is quantified and exploited.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below and indicate the specific revisions we plan to make in the next version of the manuscript.
read point-by-point responses
-
Referee: Abstract: The central claim that the novel reward design and adaptive rollout strategy improve translation quality of neologism-aware agents is stated without any quantitative results, baselines, or ablation studies. This absence prevents verification of whether the RL framework delivers the claimed gains across the 75 directions.
Authors: We agree that the abstract should include quantitative support for the central claims. The full manuscript reports experimental results (Section 4) comparing the full NeoAMT agent against strong baselines and ablations, showing consistent accuracy gains on neologism-containing sentences across the 75 directions. We will revise the abstract to include representative numbers (e.g., absolute and relative improvements from the novel reward and adaptive rollout components) so that the key empirical claims are immediately verifiable. revision: yes
-
Referee: Dataset and Toolkit Construction (described in abstract): The framework relies on the Wiktionary-derived search toolkit supplying accurate definitions and translations for reliable RL feedback, yet no independent verification of toolkit precision, coverage, or noise levels is described. User-generated Wiktionary entries for neologisms are prone to gaps and inconsistencies, which could render the RL signal unreliable and undermine generalization.
Authors: We acknowledge that an explicit quality assessment of the toolkit is missing. The manuscript describes the filtering and cleaning steps applied to the ~3 million records, but does not quantify precision or noise. We will add a new subsection (or appendix) that reports the results of a manual verification study on a stratified sample of toolkit outputs, including precision of retrieved definitions/translations, coverage of neologisms, and an estimate of residual noise. This analysis will directly address concerns about the reliability of the RL reward signal. revision: yes
Circularity Check
No circularity: empirical RL framework built from external Wiktionary data
full rationale
The paper constructs a neologism dataset and search toolkit directly from public Wiktionary dumps (~10M and ~3M records), then trains an RL agent using standard reinforcement learning with a proposed reward design and adaptive rollout strategy. No equations, fitted parameters, or predictions are defined in terms of the outputs they claim to produce. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on experimental evaluation of the trained agent rather than any self-referential reduction. This is a standard empirical ML construction with independent external data sources.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reinforcement learning with external tool use and a suitably designed reward can improve translation performance on out-of-vocabulary items.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose an RL training framework featuring a novel reward design and an adaptive rollout generation strategy that exploits translation difficulty
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Neko dataset ... derived from approximately 10 million records of an English Wiktionary dump
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
GRC: Unifying Reasoning-Driven Generation, Retrieval and Compression
GRC unifies generation, retrieval, and compression in LLMs via meta latent tokens for single-pass inference with modular flexibility.
-
GRC: Unifying Reasoning-Driven Generation, Retrieval and Compression
GRC unifies generation, retrieval, and compression in LLMs via meta latent tokens for single-pass execution with modular flexibility.
Reference graph
Works this paper leans on
-
[1]
The faiss library. Zhaopeng Feng, Shaosheng Cao, Jiahan Ren, Jiayuan Su, Ruizhe Chen, Yan Zhang, Jian Wu, and Zuozhu Liu. 2025. MT-r1-zero: Advancing LLM-based machine translation via r1-zero-like reinforcement learning. InFindings of the Association for Compu- tational Linguistics: EMNLP 2025, pages 18685– 18702, Suzhou, China. Association for Computa- t...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Curran Associates, Inc. Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yu- jia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. 2025a. Search-o1: Agentic search-enhanced large reasoning models. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 5420–5438, Suzhou, China. Association for Computational Ling...
-
[3]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Zhongtao Miao, Qiyu Wu, Masaaki Nagata, and Yoshi- masa Tsuruoka. 2025. Improving word alignment us- ing semi-supervised learning. InFindings of the As- sociation for Computational Linguistics: ACL 2025, pages 19871–19888, Vienna, Austria. Association for Computational Linguistics. Zhongtao Mia...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
A supervised word alignment method based on cross-language span prediction using multilingual BERT. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 555–565, Online. Association for Computational Linguistics. 10 Martin A. Nowak and David C. Krakauer. 1999. The evolution of language.Proceedings of the ...
-
[5]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. Jiaan Wang, Fandong Meng, Yunlong Liang, and Jie Zhou. 2025a. DRT: Deep reasoning translation via long chain-of-thought. InFindings of the Associa- tion for Computational Linguistics: ACL 2025, pages 6770–6782, Vienna, Austria. Association for Compu- tational Linguistics...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
WSPAlign: Word alignment pre-training via large-scale weakly supervised span prediction. In Proceedings of the 61st Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 11084–11099, Toronto, Canada. Association for Computational Linguistics. Haoran Xu, Young Jin Kim, Amr Sharaf, and Hany Has- san Awadalla. 2024a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Hunyuan-mt technical report.arXiv preprint arXiv:2509.05209. 12 A Implementation Details A.1 Neologism Reward The computation procedure of the neologism re- ward is listed in Algorithm 1. Algorithm 1Neologism-Specific Reward Compu- tation Require: Source text x, generated translation ˆy, the set of corresponding spans of neologisms in yref: S, lemmatizati...
-
[8]
The maximum number of tokens for model responses (including retrieved results) is set to
-
[9]
The maximum turns of searching of our agentic MT models is 3. The number of retrieved results is 5. The maximum character length of retrieved result for a single turn is 2000. The maximum training time for a single experiment is approximately 40 hours. The λ for Rneo is 0.1. The α, γ and ψ for RQE are 10, -5 and 0.0 respectively. Theg min andGare 4 and 8,...
work page 2000
-
[10]
Neologism Quality (score: 0-50)
-
[11]
Overall Translation Quality (score: 0-50). After evaluating the candidate translation based on the above criteria, please provide your assessment in the following format: <evaluation> score </evalua- tion>. The final “score” is a numerical value between 0 and
-
[12]
A higher score indicates a better translation. Here is the information you will need for your evalu- ation: Source Sentence: {source_sentence} Neologism and Its Meaning: {neologism} ({neolo- gism_meaning}) Reference Translation: {reference_translation} Candidate Translation: {candidate_translation} Table 13: LLM-as-a-judge prompt. In this paper, we care a...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.