Recognition: no theorem link
A Grouped Sorting Queue Supporting Dynamic Updates for Timer Management in High-Speed Network Interface Cards
Pith reviewed 2026-05-16 14:50 UTC · model grok-4.3
The pith
A hardware priority queue supports dynamic updates and overflow handling for precise timer management in network cards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
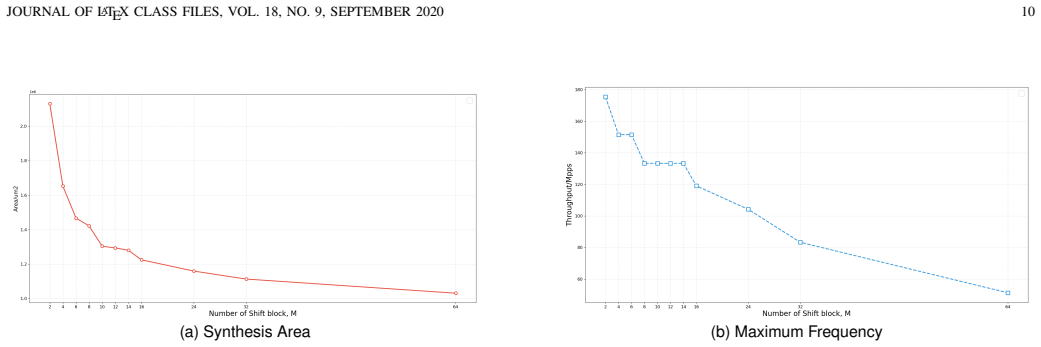
The paper claims that a grouped sorting queue enables hardware timer management by supporting updates through composition of basic operations and by using a group boundary priority to alter sorting and insertion after overflow, achieving over 500 MHz operation at 175 Mpps with 12 ns precision and 31 percent fewer LUTs than prior designs.
What carries the argument
The grouped sorting queue that composes basic operations for priority updates and establishes a group boundary priority to control sorting after overflow.
If this is right
- Timer management for flow tables can be fully offloaded to hardware, eliminating software overhead.
- Clock speeds above 500 MHz and throughputs above 175 Mpps become feasible for 4K-deep timer queues.
- Resource usage drops by roughly 25-31 percent compared with existing hardware queues.
- Correct timing behavior continues after timer values overflow by adjusting insertion positions at the group boundary.
Where Pith is reading between the lines
- The same composition approach for updates could apply to other hardware priority tasks such as packet scheduling.
- Lower software involvement in timer handling would free CPU cycles for additional network functions.
- Testing the queue at larger depths or with mixed real-world traffic patterns would reveal scaling limits not shown in the current simulations.
Load-bearing premise
Packet-level simulations of flow-table timeout management accurately predict timing precision, overflow behavior, and resource usage when the design is placed in real high-speed NIC hardware.
What would settle it
A direct measurement of timing precision, overflow handling, and resource consumption on a fabricated ASIC or deployed NIC under live high-speed traffic that shows large deviations from the reported simulation numbers would falsify the performance claims.
Figures








read the original abstract
With the hardware offloading of network functions, network interface cards (NICs) undertake massive stateful, high-precision, and high-throughput tasks, where timers serve as a critical enabling component. However, existing timer management schemes suffer from heavy software load, low precision, lack of hardware update support, and overflow. This paper proposes two novel operations for priority queues--update and group sorting--to enable hardware timer management. To the best of our knowledge, this work presents the first hardware priority queue to support an update operation through the composition and propagation of basic operations to modify the priorities of elements within the queue. The group sorting mechanism ensures correct timing behavior post-overflow by establishing a group boundary priority to alter the sorting process and element insertion positions. Implemented with a hybrid architecture of a one-dimension (1D) systolic array and shift registers, our design is validated through packet-level simulations for flow table timeout management. Results demonstrate that a 4K-depth, 16-bit timer queue achieves over 500 MHz (175 Mpps, 12 ns precision) in a 28nm process and over 300 MHz (116 Mpps) on an FPGA. Critically, it reduces LUTs and FFs usage by 31% and 25%, respectively, compared to existing designs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes novel update and group-sorting operations for hardware priority queues to support high-precision timer management in NICs. The update is realized by composing and propagating basic queue operations; group sorting uses a group-boundary priority to restore correct ordering after 16-bit timer wrap-around. A hybrid 1D systolic array plus shift-register architecture is presented, with packet-level simulations for flow-table timeout management claiming >500 MHz (175 Mpps, 12 ns precision) in 28 nm for a 4 K-depth, 16-bit queue and 31 % / 25 % LUT/FF reductions versus prior designs.
Significance. If the performance and correctness claims hold, the work would provide a practical hardware primitive for offloading stateful network functions that require precise, updatable timers at line rate. The resource savings and the composition-based update mechanism constitute concrete engineering contributions supported by FPGA synthesis and simulation data.
major comments (2)
- [Results] Results section: the central performance claim of >500 MHz and 12 ns precision in 28 nm is presented without post-synthesis timing reports, static timing analysis, or clock-skew measurements; these data are load-bearing for the frequency and precision assertions.
- [Validation] Validation / correctness argument: the group-boundary priority mechanism is asserted to guarantee correct ordering after overflow, yet the manuscript supplies only packet-level simulation traces rather than formal verification or exhaustive test vectors covering realistic traffic patterns and wrap-around cases.
minor comments (1)
- [Abstract] Abstract: the resource-reduction percentages are given without naming the exact prior designs or table/figure that contains the comparison numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We provide point-by-point responses to the major comments below and outline the revisions we will make to address the concerns.
read point-by-point responses
-
Referee: [Results] Results section: the central performance claim of >500 MHz and 12 ns precision in 28 nm is presented without post-synthesis timing reports, static timing analysis, or clock-skew measurements; these data are load-bearing for the frequency and precision assertions.
Authors: The >500 MHz frequency and 12 ns precision claims are based on synthesis results from a commercial 28nm ASIC flow. We agree that the manuscript would benefit from more detailed timing data. In the revised version, we will include post-synthesis timing reports, static timing analysis summaries, and clarification on clock skew to support these assertions. revision: yes
-
Referee: [Validation] Validation / correctness argument: the group-boundary priority mechanism is asserted to guarantee correct ordering after overflow, yet the manuscript supplies only packet-level simulation traces rather than formal verification or exhaustive test vectors covering realistic traffic patterns and wrap-around cases.
Authors: The group-boundary priority is validated via packet-level simulations that incorporate wrap-around events in realistic flow timeout scenarios. While we did not perform formal verification, the simulations cover key cases. We will revise the manuscript to include additional exhaustive test vectors and more comprehensive simulation results covering diverse traffic patterns to better substantiate the correctness. revision: partial
Circularity Check
No significant circularity; architecture rests on standard primitives and explicit compositions
full rationale
The paper presents a hybrid 1D systolic array plus shift-register design with composed update and group-sorting operations. No equations, fitted parameters, or self-citation chains reduce the claimed >500 MHz timing or post-overflow correctness to quantities defined by the authors' own prior results. The novelty claim ('first hardware priority queue to support an update operation through the composition...') is an assertion of priority, not a derivation that collapses to its inputs. Packet-level simulations supply the reported numbers but are not presented as first-principles predictions that must match by construction. This is the normal non-circular outcome for a hardware architecture paper whose central steps are explicit circuit compositions rather than self-referential fits.
Axiom & Free-Parameter Ledger
free parameters (2)
- queue depth =
4096
- timer width =
16
axioms (2)
- domain assumption Composition of basic insert/delete operations yields a correct priority update without violating queue invariants.
- ad hoc to paper Group boundary priority correctly restores ordering after 16-bit timer wrap-around.
invented entities (1)
-
group sorting mechanism
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Programmable Packet Scheduling with Dynamic Reordering at Line Rate
UIFO is a new scheduling model that adds class-level dynamic reordering to programmable hardware while generalizing PIFO and PIEO and sustaining 100 Gbps line rate.
Reference graph
Works this paper leans on
-
[1]
A clean slate 4d approach to network control and management,
A. Greenberg, G. Hjalmtysson, D. A. Maltz, A. Myers, J. Rexford, G. Xie, H. Yan, J. Zhan, and H. Zhang, “A clean slate 4d approach to network control and management,”ACM SIGCOMM Computer Communication Review, vol. 35, no. 5, pp. 41–54, 2005
work page 2005
-
[2]
What you need to know about sdn flow tables,
M. Ku´zniar, P. Pereˇs´ıni, and D. Kosti´c, “What you need to know about sdn flow tables,” inInternational Conference on Passive and Active Network Measurement, pp. 347–359, Springer, 2015
work page 2015
-
[3]
OpenFlow Switch Specification (Version 1.5.1), Open Netw. Found. Std.,Menlo Park, CA, USA, Mar. 2015
work page 2015
-
[4]
The Design and Implementation of Open vSwitch
“The Design and Implementation of Open vSwitch.”Symposium on Networked Systems Design and Implementation(2015)
work page 2015
-
[5]
Y . Shen, C. Wu, Q. Cheng and D. Kong, ”AFTM: An Adaptive Flow Table Management Scheme for OpenFlow Switches,” 2020 IEEE 22nd Interna- tional Conference on High Performance Computing and Communications; IEEE 18th International Conference on Smart City; IEEE 6th Interna- tional Conference on Data Science and Systems (HPCC/SmartCity/DSS), Yanuca Island, Cuv...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/hpcc- 2020
-
[6]
B. Arslan, E. Kızılkaya, B. Yi ˘git and F. Alag ¨oz, ”Maximizing SDN Flow Table Efficiency with Dynamic Timeout Allocation and Proactive Eviction,”2024 15th International Conference on Network of the Future (NoF), Castelldefels, Spain, 2024, pp. 10-18, doi: 10.1109/NoF62948.2024.10741357
-
[7]
InfiniBand Architecture Specification V ol- ume 1: Release 1.4
InfiniBand Trade Association. InfiniBand Architecture Specification V ol- ume 1: Release 1.4. InfiniBand Trade Association, 2010
work page 2010
-
[8]
Star: Breaking the scalability limit for rdma
Xizheng Wang, Guo Chen, Xijin Yin, Huichen Dai, Bojie Li, Binzhang Fu, and Kun Tan. Star: Breaking the scalability limit for rdma. InProc. ICNP, 2021
work page 2021
-
[9]
SRNIC: A Scalable Architecture for RDMA NICs
Wang, Zilong et al. “SRNIC: A Scalable Architecture for RDMA NICs.” Symposium on Networked Systems Design and Implementation(2023)
work page 2023
-
[10]
F. Yang, Z. Wang, N. Kang, Z. Ma, J. Li, G. Yuan, and G. Tan, ”JingZhao: A framework for rapid NIC prototyping in the domain-specific-network era,” arXiv, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2410.08476
-
[11]
AMD, ”AMD Embedded RDMA Enabled NIC LogiCORE IP Prod- uct Guide (PG332),” 4.2 ed., AMD, Nov. 2024. [Online]. Available: https://docs.amd.com/r/en-US/pg332-ernic
work page 2024
-
[12]
”Rfc 9293: Transmission control protocol (tcp).” (2022)
Eddy, Wesley, ed. ”Rfc 9293: Transmission control protocol (tcp).” (2022)
work page 2022
-
[13]
Safe and effective fine-grained TCP retransmissions for datacenter communication,
V . Vasudevan et al., “Safe and effective fine-grained TCP retransmissions for datacenter communication,” inProc. SIGCOMM, Barcelona, Spain, Aug. 2009, pp. 303–314
work page 2009
-
[14]
TCP offload to the rescue: Getting a toehold on TCP offload engines—and why we need them
Andy Currid. TCP offload to the rescue: Getting a toehold on TCP offload engines—and why we need them. Queue, 2(3):58–65, May 2004
work page 2004
-
[15]
Moon, YoungGyoun et al. ”AccelTCP: Accelerating Network Applica- tions with Stateful TCP Offloading.”Symposium on Networked Systems Design and Implementation(2020): 77-92
work page 2020
-
[16]
Shashidhara, Rajath et al. ”FlexTOE: Flexible TCP Offload with Fine- Grained Parallelism”Symposium on Networked Systems Design and Implementation(2022): 87-102
work page 2022
-
[17]
Varghese, G, and A Lauck. ”Hashed and Hierarchical Timing Wheels: Efficient Data Structures for Implementing a Timer Facility”,IEEE/ACM Transactions on Networking5.6 (1997): 824-834
work page 1997
-
[18]
”A High Efficiency Two-dimensional Index Queue Timer Management Algorithm for Network and Communication Systems”,Computational Intelligence, Communication Systems and Networks (2011)
work page 2011
-
[19]
”NVIDIA Mellanox ConnectX-6 Ethernet SmartNIC Data Sheet.” Cisco, May 2021, https://www.cisco.com/c/dam/en/us/products/collateral/servers-unified- computing/ucs-c-series-rack-servers/nvidia-mellanox-connectx-6- ethernet-smartnic-data-sheet.pdf. Accessed 14 Oct. 2025
work page 2021
-
[20]
Kumar, NG Chetan, et al. ”Hardware-software architecture for priority queue management in real-time and embedded systems.”International Journal of Embedded Systems6.4 (2014): 319-334
work page 2014
-
[21]
Y . Tang and N. W. Bergmann, ”A Hardware Scheduler Based on Task Queues for FPGA-Based Embedded Real-Time Systems,” inIEEE Transactions on Computersvol. 64, no. 5, pp. 1254-1267, 1 May 2015, doi: 10.1109/TC.2014.2315637
-
[22]
I. Benacer, F. -R. Boyer and Y . Savaria, ”A Fast,Single- Instruction–Multiple-Data, Scalable Priority Queue,” inIEEE Transactions on V ery Large Scale Integration (VLSI) Systems, vol. 26, no. 10, pp. 1939-1952, Oct. 2018, doi: 10.1109/TVLSI.2018.2838044
-
[23]
Yao, Ruyi, et al. ”BMW tree: Large-scale, high-throughput and modular PIFO implementation using balanced multi-way sorting tree.”Proceed- ings of the ACM SIGCOMM 2023 Conference. 2023
work page 2023
-
[24]
A. Nurmi, P. Lindgren, T. Szymkowiak and T. D. H ¨am¨al¨ainen, ”AnTiQ: A Hardware-Accelerated Priority Queue Design with Constant Time Arbitrary Element Removal,” 2023 26thEuromicro Conference on Dig- ital System Design (DSD), Golem, Albania, 2023, pp. 462-469, doi: 10.1109/DSD60849.2023.00070
-
[25]
Benacer, Imad, Francois-Raymond Boyer, and Yvon Savaria. ”A high- speed traffic manager architecture for flow-based networking.” 2017 15th IEEE International New Circuits and Systems Conference (NEWCAS). IEEE, 2017
work page 2017
-
[26]
Septinus, K. et al. ”A Scalable Hardware Algorithm for Demanding Timer Management in Network Systems”,PARS Parallel-Algorithmen, - Rechnerstrukturen und -Systemsoftware 28.1 (2011): 58-67
work page 2011
-
[27]
Atre, Nirav et al. ”BBQ: A Fast and Scalable Integer Priority Queue for Hardware Packet Scheduling.”,Symposium on Networked Systems Design and Implementation(2024): 455-475
work page 2024
-
[28]
Programmable packet scheduling at line rate,
A. Sivaraman, “Programmable packet scheduling at line rate,” inProc. ACM SIGCOMM, Aug. 2016, pp. 44–57
work page 2016
-
[29]
S. Collinson, A. Bai and O. Sinnen, ”A Fast Scalable Hardware Priority Queue and Optimizations for Multi-Pushes,” 2024IEEE In- ternational Parallel and Distributed Processing Symposium Work- shops (IPDPSW), San Francisco, CA, USA, 2024, pp. 134-140, doi: 10.1109/IPDPSW63119.2024.00038
-
[30]
Sung-Whan Moon, J. Rexford and K. G. Shin, ”Scalable hardware priority queue architectures for high-speed packet switches,” inIEEE Transactions on Computers, vol. 49, no. 11, pp. 1215-1227, Nov. 2000
work page 2000
-
[31]
Benson, Theophilus et al. ”Network Traffic Characteristics of Data Centers in the Wild”,ACM/SIGCOMM Internet Measurement Conference (2010): 267-280. JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 12 Zekun Wangreceived the B.S. and M.S. degrees in Integrated Circuit Design from Xidian University, Xi’an, China, in 2020 and 2023, respectively. ...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.