Recognition: 1 theorem link
· Lean TheoremAttention-space Contrastive Guidance for Efficient Hallucination Mitigation in LVLMs
Pith reviewed 2026-05-16 12:59 UTC · model grok-4.3
The pith
Single-pass attention guidance steers LVLMs toward visual evidence to reduce hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hallucinations arise when language priors dominate over visual evidence in LVLMs. By constructing both image-conditioned and approximate text-only attention paths within a single forward pass and applying a lightweight orthogonal projection to suppress components aligned with the text-only path, generation is steered toward visually grounded outputs before errors accumulate at the output layer.
What carries the argument
Attention-space Contrastive Guidance (ACG): a single-pass mechanism that builds dual attention paths via masking in self-attention layers and uses orthogonal projection to suppress text-only bias components.
If this is right
- ACG improves faithfulness over existing training-free baselines on CHAIR and POPE benchmarks.
- Caption quality remains comparable to unguided generation.
- Latency drops by up to 2 times relative to multi-pass contrastive decoding methods.
Where Pith is reading between the lines
- Attention layers appear to be a practical intervention point for controlling cross-modal biases without model changes.
- The approach could extend to other generative settings where input evidence must override strong priors, such as audio-language or video models.
- Combining the projection step with existing lightweight decoding tweaks might yield additive reliability gains at low extra cost.
Load-bearing premise
The masking-based surrogate accurately approximates the text-only attention path without excessive bias, and the orthogonal projection reliably suppresses hallucination-inducing components while preserving visual grounding.
What would settle it
Compute the true text-only attention in a separate forward pass and compare it to the masking surrogate; if the patterns differ substantially and faithfulness metrics on CHAIR or POPE show no gain over baselines, the method's effectiveness would be falsified.
Figures






read the original abstract
Hallucinations in large vision--language models (LVLMs) often arise when language priors dominate over visual evidence, leading to object misidentification and visually inconsistent descriptions. We address this problem by framing hallucination mitigation as contrastive guidance that steers generation toward visually grounded and semantically faithful text. We propose Attention-space Contrastive Guidance (ACG), a training-free, single-pass method that operates directly in self-attention layers, where hallucination-inducing cross-modal biases emerge. ACG constructs both image-conditioned and approximate text-only attention paths within a single forward pass, enabling efficient guidance before errors accumulate at the output layer. Because this masking-based surrogate can introduce approximation bias, we further apply a lightweight orthogonal projection that suppresses components aligned with the text-only path, yielding a more visually grounded correction. Experiments on CHAIR and POPE show that ACG improves faithfulness over existing training-free baselines while maintaining caption quality, reducing latency by up to $2\times$ compared to multi-pass contrastive decoding methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Attention-space Contrastive Guidance (ACG), a training-free, single-pass technique for mitigating hallucinations in large vision-language models (LVLMs). It constructs image-conditioned and approximate text-only attention paths via masking in self-attention layers within one forward pass, followed by an orthogonal projection to suppress components aligned with the text-only path, aiming to steer generation toward visually grounded outputs. Experiments on CHAIR and POPE benchmarks are reported to show improved faithfulness over training-free baselines while maintaining caption quality and reducing latency by up to 2× compared to multi-pass contrastive decoding.
Significance. If the masking surrogate bias is shown to be small and the projection demonstrably effective, ACG could provide a practical efficiency gain for hallucination mitigation by avoiding training or multi-pass inference. The direct attention-space operation addresses a plausible source of cross-modal bias and the single-pass design is a clear practical strength.
major comments (3)
- [Abstract] Abstract: positive results on CHAIR and POPE are stated, but no baselines, effect sizes, error bars, or ablation studies are described; this leaves the central faithfulness-improvement claim without sufficient quantitative support.
- [Method] Method section: the masking surrogate is asserted to approximate the text-only attention path sufficiently for the orthogonal projection to suppress hallucination directions, yet no quantitative bound on surrogate error, no direct comparison of masked vs. true text-only attention maps, and no analysis of bias propagation are provided; this is load-bearing for both the single-pass efficiency claim and the faithfulness result.
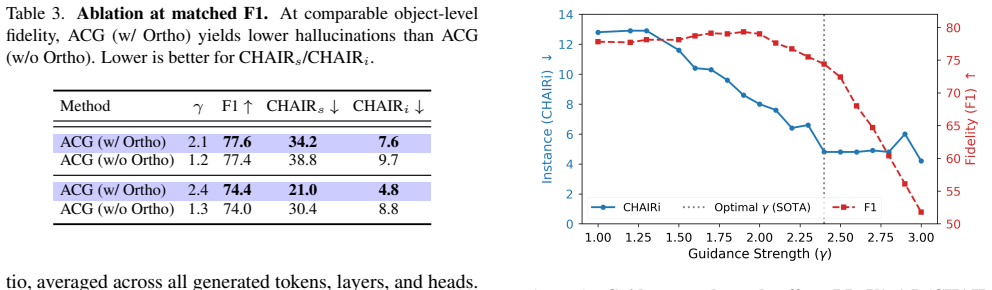
- [Experiments] Experiments section: no ablation isolating the orthogonal projection's contribution (versus masking alone) is reported, so it is unclear whether observed CHAIR/POPE gains arise from the proposed correction or from other implementation details.
minor comments (1)
- [Abstract] The latency claim of 'up to 2×' should specify the exact models, hardware, and multi-pass baseline implementation for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will make targeted revisions to improve quantitative support, methodological justification, and experimental clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: positive results on CHAIR and POPE are stated, but no baselines, effect sizes, error bars, or ablation studies are described; this leaves the central faithfulness-improvement claim without sufficient quantitative support.
Authors: We agree the abstract would be strengthened by additional quantitative context. In the revised version we will update the abstract to name the primary training-free baselines (contrastive decoding and related methods), report key effect sizes (e.g., CHAIR reduction and POPE accuracy gains), and note that error bars and ablations appear in the experiments section. This keeps the abstract concise while directly supporting the central claim. revision: yes
-
Referee: [Method] Method section: the masking surrogate is asserted to approximate the text-only attention path sufficiently for the orthogonal projection to suppress hallucination directions, yet no quantitative bound on surrogate error, no direct comparison of masked vs. true text-only attention maps, and no analysis of bias propagation are provided; this is load-bearing for both the single-pass efficiency claim and the faithfulness result.
Authors: The referee is correct that the submitted manuscript provides no quantitative bound on the masking approximation error nor direct map comparisons. While the orthogonal projection is designed to attenuate residual text-only components, we lack an explicit analysis of surrogate fidelity or bias propagation. In revision we will add a dedicated analysis subsection that (i) computes attention-map differences (e.g., cosine similarity) between the masked surrogate and a true text-only forward pass on a held-out validation set and (ii) discusses how the projection step limits propagation of any remaining bias. This will supply the requested empirical grounding. revision: yes
-
Referee: [Experiments] Experiments section: no ablation isolating the orthogonal projection's contribution (versus masking alone) is reported, so it is unclear whether observed CHAIR/POPE gains arise from the proposed correction or from other implementation details.
Authors: We acknowledge the absence of an explicit ablation separating the orthogonal projection from masking alone. In the revised manuscript we will insert a new ablation table that reports CHAIR and POPE metrics for the masking-only variant versus the full ACG pipeline (masking plus projection). This will isolate the projection's incremental contribution and clarify the source of the observed gains. revision: yes
Circularity Check
No circularity: procedural method with independent empirical validation
full rationale
The paper defines ACG procedurally via masking to approximate a text-only attention path inside a single forward pass, followed by an orthogonal projection step, then reports empirical gains on CHAIR and POPE. No equations reduce the claimed faithfulness improvement or latency reduction to fitted parameters, self-referential definitions, or load-bearing self-citations. The derivation chain remains self-contained against external benchmarks, with the masking surrogate and projection presented as explicit design choices rather than derived results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Masking in self-attention layers can construct an approximate text-only attention path from the image-conditioned forward pass.
- domain assumption Orthogonal projection can suppress components aligned with the text-only path to produce a more visually grounded correction.
Forward citations
Cited by 1 Pith paper
-
Decoding by Perturbation: Mitigating MLLM Hallucinations via Dynamic Textual Perturbation
DeP mitigates MLLM hallucinations by dynamically perturbing text prompts to identify and reinforce stable visual evidence regions while counteracting language prior biases using attention variance and logit statistics.
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning,
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, An- toine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Se- bastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sa- hand Sharifzadeh, Mikolaj Bink...
-
[2]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond, 2023. 1, 2, 5
work page 2023
-
[3]
Hallucination of multimodal large language models: A survey, 2025
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey, 2025. 1, 2
work page 2025
-
[4]
Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas,
Shiqi Chen, Tongyao Zhu, Ruochen Zhou, Jinghan Zhang, Siyang Gao, Juan Carlos Niebles, Mor Geva, Junxian He, Jiajun Wu, and Manling Li. Why is spatial reasoning hard for vlms? an attention mechanism perspective on focus areas,
-
[5]
Dola: Decoding by con- trasting layers improves factuality in large language models,
Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James Glass, and Pengcheng He. Dola: Decoding by con- trasting layers improves factuality in large language models,
-
[6]
Instructblip: Towards general- purpose vision-language models with instruction tuning,
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general- purpose vision-language models with instruction tuning,
-
[7]
Classifier-free diffusion guidance, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022. 3
work page 2022
-
[8]
Hallucination augmented contrastive learning for multimodal large language model, 2024
Chaoya Jiang, Haiyang Xu, Mengfan Dong, Jiaxing Chen, Wei Ye, Ming Yan, Qinghao Ye, Ji Zhang, Fei Huang, and Shikun Zhang. Hallucination augmented contrastive learning for multimodal large language model, 2024. 1
work page 2024
-
[9]
Zhangqi Jiang, Junkai Chen, Beier Zhu, Tingjin Luo, Yankun Shen, and Xu Yang. Devils in middle layers of large vision- language models: Interpreting, detecting and mitigating ob- ject hallucinations via attention lens, 2025. 2, 3
work page 2025
-
[10]
Mingi Jung, Saehyung Lee, Eunji Kim, and Sungroh Yoon. Visual attention never fades: Selective progressive attention recalibration for detailed image captioning in multimodal large language models, 2025. 3
work page 2025
-
[11]
See what you are told: Visual attention sink in large multimodal models, 2025
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models, 2025. 2, 3
work page 2025
-
[12]
Prannay Kaul, Zhizhong Li, Hao Yang, Yonatan Dukler, Ashwin Swaminathan, C. J. Taylor, and Stefano Soatto. Throne: An object-based hallucination benchmark for the free-form generations of large vision-language models,
-
[13]
Yi-Lun Lee, Yi-Hsuan Tsai, and Wei-Chen Chiu. Delve into visual contrastive decoding for hallucination mitigation of large vision-language models, 2024. 3
work page 2024
-
[14]
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shi- jian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision-language models through vi- sual contrastive decoding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13872–13882, 2024. 1, 3, 5, 2
work page 2024
-
[15]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023. 1, 2
work page 2023
-
[16]
Contrastive decoding: Open-ended text genera- tion as optimization
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori Hashimoto, Luke Zettlemoyer, and Mike Lewis. Contrastive decoding: Open-ended text genera- tion as optimization. InProceedings of the 61st Annual Meet- ing of the Association for Computational Linguistics (Vol- ume 1: Long Papers), pages 12286–12312, Toronto, Canada,
-
[18]
Evaluating object hallucination in large vision- language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision- language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 292–305, Singapore, 2023. Association for Computational Linguistics. 1, 2, 5
work page 2023
-
[19]
Zhuowei Li, Haizhou Shi, Yunhe Gao, Di Liu, Zhenting Wang, Yuxiao Chen, Ting Liu, Long Zhao, Hao Wang, and Dimitris N. Metaxas. The hidden life of tokens: Reduc- ing hallucination of large vision-language models via vi- sual information steering. InProceedings of the 42nd In- ternational Conference on Machine Learning, pages 35799– 35819. PMLR, 2025. 3, 4, 5, 2
work page 2025
-
[20]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26296–26306, 2024. 1, 2, 5
work page 2024
-
[21]
Reduc- ing hallucinations in vision-language models via latent space steering, 2024
Sheng Liu, Haotian Ye, Lei Xing, and James Zou. Reduc- ing hallucinations in vision-language models via latent space steering, 2024. 3, 7
work page 2024
-
[22]
Shi Liu, Kecheng Zheng, and Wei Chen. Paying more atten- tion to image: A training-free method for alleviating halluci- nation in lvlms, 2024. 1, 2, 3, 4, 5
work page 2024
-
[23]
Woohyeon Park, Woojin Kim, Jaeik Kim, and Jaeyoung Do. Second: Mitigating perceptual hallucination in vision- language models via selective and contrastive decoding,
-
[24]
Chan, Anish Kachinthaya, Haodi Zou, John Canny, Joseph E
Suzanne Petryk, David M. Chan, Anish Kachinthaya, Haodi Zou, John Canny, Joseph E. Gonzalez, and Trevor Darrell. Aloha: A new measure for hallucination in captioning mod- els, 2024. 2
work page 2024
-
[25]
Object hallucination in image cap- tioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image cap- tioning. InProceedings of the 2018 Conference on Empiri- cal Methods in Natural Language Processing, pages 4035– 4045, Brussels, Belgium, 2018. Association for Computa- tional Linguistics. 1, 2, 5 9
work page 2018
-
[26]
Stay on topic with classifier-free guidance, 2023
Guillaume Sanchez, Honglu Fan, Alexander Spangher, Elad Levi, Pawan Sasanka Ammanamanchi, and Stella Biderman. Stay on topic with classifier-free guidance, 2023. 3
work page 2023
-
[27]
Jingran Su, Jingfan Chen, Hongxin Li, Yuntao Chen, Li Qing, and Zhaoxiang Zhang. Activation steering decod- ing: Mitigating hallucination in large vision-language mod- els through bidirectional hidden state intervention. InPro- ceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12964–12974, ...
work page 2025
-
[28]
Extracting latent steering vectors from pretrained language models
Nishant Subramani, Nivedita Suresh, and Matthew Peters. Extracting latent steering vectors from pretrained language models. InFindings of the Association for Computational Linguistics: ACL 2022, pages 566–581, Dublin, Ireland,
work page 2022
-
[29]
Association for Computational Linguistics. 3
-
[30]
Aligning large multimodal models with factu- ally augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liangyan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, and Trevor Darrell. Aligning large multimodal models with factu- ally augmented RLHF. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13088–13110, Bangkok, Thailand, 2024. Associatio...
work page 2024
-
[31]
Contrastive region guidance: Improving grounding in vision-language models without training, 2024
David Wan, Jaemin Cho, Elias Stengel-Eskin, and Mohit Bansal. Contrastive region guidance: Improving grounding in vision-language models without training, 2024. 3
work page 2024
-
[32]
Ma, Simon Stepputtis, Louis-Philippe Morency, Deva Ramanan, Katia Sycara, and Yaqi Xie
Zifu Wan, Ce Zhang, Silong Yong, Martin Q. Ma, Simon Stepputtis, Louis-Philippe Morency, Deva Ramanan, Katia Sycara, and Yaqi Xie. Only: One-layer intervention suf- ficiently mitigates hallucinations in large vision-language models, 2025. 3
work page 2025
-
[33]
Xintong Wang, Jingheng Pan, Liang Ding, and Chris Bie- mann. Mitigating hallucinations in large vision-language models with instruction contrastive decoding, 2024. 1, 3
work page 2024
-
[34]
SHARP: Steering hallucination in LVLMs via repre- sentation engineering
Junfei Wu, Yue Ding, Guofan Liu, Tianze Xia, Ziyue Huang, Dianbo Sui, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. SHARP: Steering hallucination in LVLMs via repre- sentation engineering. InProceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Process- ing, pages 14357–14372, Suzhou, China, 2025. Association for Computational Lin...
work page 2025
-
[35]
Jiulong Wu, Zhengliang Shi, Shuaiqiang Wang, Jizhou Huang, Dawei Yin, Lingyong Yan, Min Cao, and Min Zhang. Mitigating hallucinations in large vision-language models via entity-centric multimodal preference optimization, 2025. 1
work page 2025
-
[36]
Tianyun Yang, Ziniu Li, Juan Cao, and Chang Xu. Mitigat- ing hallucination in large vision-language models via mod- ular attribution and intervention. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025. 2, 3
work page 2025
-
[37]
Prompt highlighter: Interactive control for multi- modal llms, 2024
Yuechen Zhang, Shengju Qian, Bohao Peng, Shu Liu, and Jiaya Jia. Prompt highlighter: Interactive control for multi- modal llms, 2024. 3
work page 2024
-
[38]
Mitigating object hallucination in large vision-language models via image-grounded guidance, 2025
Linxi Zhao, Yihe Deng, Weitong Zhang, and Quanquan Gu. Mitigating object hallucination in large vision-language models via image-grounded guidance, 2025. 3
work page 2025
-
[39]
Minigpt-4: Enhancing vision-language understanding with advanced large language models, 2023
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mo- hamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models, 2023. 1, 2, 5
work page 2023
-
[40]
Mitigating object hallucinations in large vision-language models via attention calibration, 2025
Younan Zhu, Linwei Tao, Minjing Dong, and Chang Xu. Mitigating object hallucinations in large vision-language models via attention calibration, 2025. 2, 3
work page 2025
-
[41]
Is there a <object> in the image?
Kaiwen Zuo and Yirui Jiang. Medhallbench: A new bench- mark for assessing hallucination in medical large language models, 2025. 1 10 Attention-space Contrastive Guidance for Efficient Hallucination Mitigation in LVLMs Supplementary Material A. Implementation Details A.1. Models. We evaluate ACG on three open-source large vision– language models (LVLMs) wi...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.