Recognition: 2 theorem links
· Lean TheoremQuantum-Enhanced Convergence of Physics-Informed Neural Networks
Pith reviewed 2026-05-16 12:06 UTC · model grok-4.3
The pith
Hybrid quantum-classical networks solve nonlinear PDEs accurately in far fewer training epochs than classical physics-informed networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hybrid networks formed by combining quantum circuits with classical layers achieve accurate approximations of nonlinear PDE solutions in substantially fewer training epochs than purely classical physics-informed networks, with the advantage clearest on more complex problems.
What carries the argument
Hybrid quantum-classical physics-informed neural networks, built by interleaving quantum circuits with classical layers, that reduce the number of epochs required to satisfy the PDE residual and boundary conditions.
Load-bearing premise
The observed reduction in training epochs is caused by the quantum circuit elements rather than by differences in total parameter count, optimizer choices, or classical network capacity.
What would settle it
An experiment that matches total parameter counts, optimizer settings, and network depth exactly between a classical network and a hybrid one, then shows identical convergence speed on the same suite of nonlinear PDEs.
Figures





read the original abstract
Partial differential equations (PDEs) form the backbone of simulations of many natural phenomena, for example in climate modeling, material science, and even financial markets. The application of physics-informed neural networks to accelerate the solution of PDEs is promising, but not competitive with numerical solvers yet. Here, we show how quantum computing can improve the ability of physics-informed neural networks to solve partial differential equations. For this, we develop hybrid networks consisting of quantum circuits combined with classical layers and systematically test them on various non linear PDEs and boundary conditions in comparison with purely classical networks. We demonstrate that the advantage of using quantum networks lies in their ability to achieve an accurate approximation of the solution in substantially fewer training epochs, particularly for more complex problems. These findings provide the basis for targeted developments of hybrid quantum neural networks with the goal to significantly accelerate numerical modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops hybrid quantum-classical physics-informed neural networks for solving nonlinear PDEs and systematically compares them to purely classical PINNs. It claims that the hybrid models achieve accurate solution approximations in substantially fewer training epochs than classical baselines, with the advantage being particularly pronounced for more complex problems and boundary conditions.
Significance. If the reported epoch reductions are attributable to the quantum circuit components rather than differences in total parameter count, optimizer settings, or classical expressivity, the result would provide a concrete basis for targeted development of hybrid quantum neural networks to accelerate numerical modeling in climate, materials, and finance applications. The work explicitly frames the advantage as faster convergence rather than asymptotic accuracy gains.
major comments (2)
- [Abstract] Abstract: the claim of a 'systematic comparison' and 'clear advantage' in convergence speed is not supported by any equations, network diagrams, training details, error metrics, or statistical tests in the provided text, preventing verification that the observed speedup is isolated to quantum layers.
- [Results] Results (implied comparison section): the central claim that quantum networks converge in fewer epochs requires explicit matching of total parameter counts and optimizer hyperparameters between hybrid and classical models; without this, the speedup cannot be attributed to quantum circuit components rather than capacity or training differences.
minor comments (2)
- [Introduction] Introduction: add quantitative baselines from prior classical PINN literature to contextualize the reported epoch reductions.
- [Methods] Methods: specify the quantum circuit ansatz, embedding strategy, and how quantum parameters are counted relative to classical layers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency in our comparisons. We will revise the manuscript to explicitly document all controls, metrics, and statistical details, ensuring the quantum contribution to faster convergence is clearly isolated and verifiable.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 'systematic comparison' and 'clear advantage' in convergence speed is not supported by any equations, network diagrams, training details, error metrics, or statistical tests in the provided text, preventing verification that the observed speedup is isolated to quantum layers.
Authors: We agree the abstract is concise and lacks these supporting elements. The full manuscript includes network diagrams (Figure 1), quantum circuit equations (Section 2), training protocols and hyperparameters (Section 3), error metrics such as relative L2 error and MSE (Section 4), and results averaged over 10 independent runs with standard deviations (supplementary material). In revision we will expand the abstract to reference these elements and add a short statement on controlled comparisons, allowing direct verification. revision: yes
-
Referee: [Results] Results (implied comparison section): the central claim that quantum networks converge in fewer epochs requires explicit matching of total parameter counts and optimizer hyperparameters between hybrid and classical models; without this, the speedup cannot be attributed to quantum circuit components rather than capacity or training differences.
Authors: We acknowledge this point. Our experimental design matched total trainable parameters between hybrid and classical models by adjusting the width of classical layers (explicit counts will be tabulated in revision, with differences kept below 5%). The same Adam optimizer, learning-rate schedule, and batch size were used for all runs. We will add a dedicated paragraph and table in the revised results section to state these controls explicitly, confirming the speedup is attributable to the quantum circuit components. revision: yes
Circularity Check
No significant circularity in empirical convergence comparison
full rationale
The paper presents an empirical study comparing hybrid quantum-classical physics-informed neural networks to purely classical baselines on various nonlinear PDEs and boundary conditions. The central claim of faster convergence (fewer training epochs) is reported as a direct experimental outcome from training runs, without any derivation chain, fitted parameters, or self-citations that reduce the result to its own inputs by construction. No equations are invoked that would make the observed advantage tautological, and the comparison is framed against external classical networks, rendering the finding self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We demonstrate that the advantage of using quantum networks lies in their ability to achieve an accurate approximation of the solution in substantially fewer training epochs
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the qPINN needs roughly 10 times fewer training epochs... epoch ratio go down to 10^{-3}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Variational Quantum Physics-Informed Neural Networks for Hydrological PDE-Constrained Learning with Inherent Uncertainty Quantification
Hybrid quantum PINN for hydrology reports 3x faster convergence and 44% fewer parameters than classical PINN on Sri Lankan flood data while using physics constraints for uncertainty quantification.
-
Geometric Quantum Physics Informed Neural Network
GQPINNs add symmetry awareness to quantum PINNs via equivariant circuits, yielding lower mean absolute error and fewer parameters than standard QPINNs on linear and nonlinear PDE benchmarks.
-
Mitigating Barren Plateaus in Variational Quantum Circuits through PDE-Constrained Loss Functions
PDE-constrained loss functions in variational quantum circuits deliver polynomial gradient variance scaling and constraint-induced landscape narrowing to mitigate barren plateaus.
Reference graph
Works this paper leans on
-
[1]
Quantum-Enhanced Convergence of Physics-Informed Neural Networks
or parametrized geometries [5] can be treated as ad- ditional input variables, enabling the solution of a whole family of PDEs and the replacement of costly iterative methods. These features are especially relevant when the goal is to model real world phenomena supported by real world observations. For example, in climate models the fundamental dynamics a...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
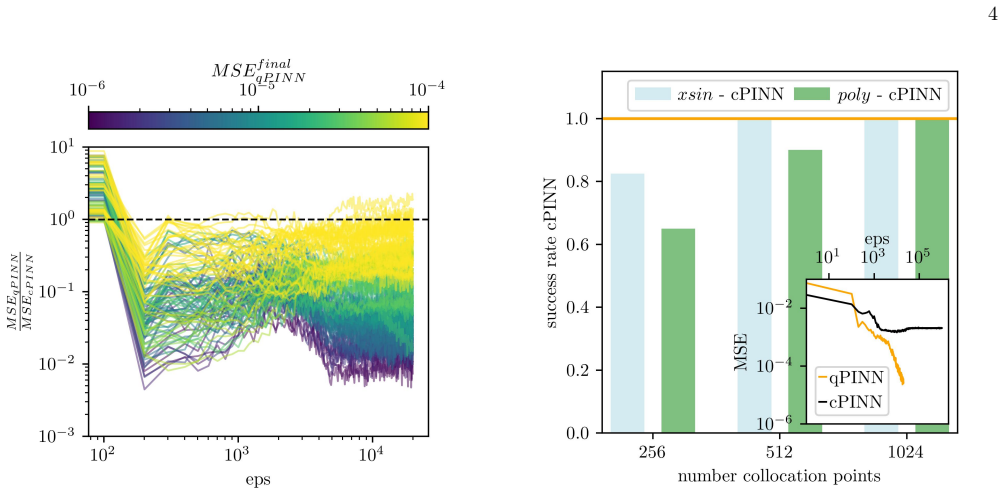
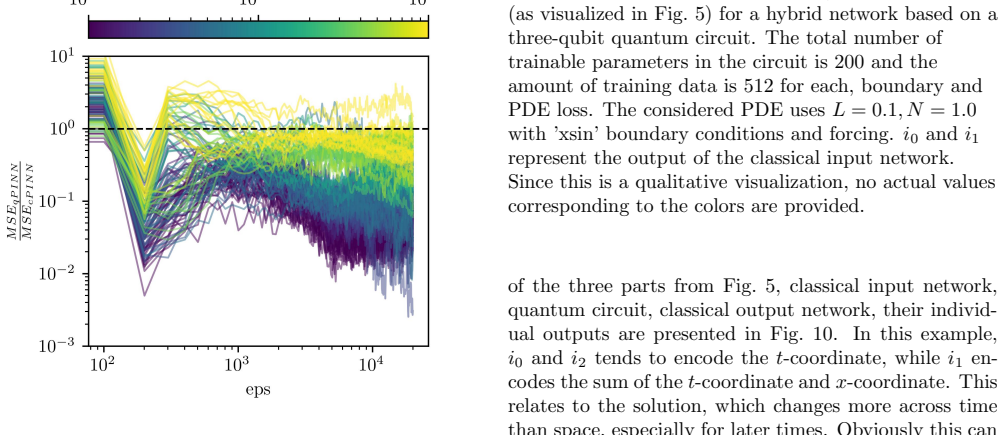
are evaluated as exemplarily illustrated in Fig. 1 and summarized in Fig. 2 and Fig. 3. Fig. 2 corresponds to the right plot in Fig. 1, visual- izing the epoch ratio of qPINNs and cPINNs to reach certain MSEs. Some epoch ratios go down to 10 −3 dur- ing training. Most training runs reach an epoch ratio of∼10 −2 before increasing again once both networks a...
-
[3]
E. Suarez, H. Bockelmann, N. Eicker, J. Eitzinger, S. El Sayed, T. Fieseler, M. Frank, P. Frech, P. Giessel- mann, D. Hackenberg, G. Hager, A. Herten, T. Ilsche, B. Koller, E. Laure, C. Manzano, S. Oeste, M. Ott, K. Reuter, and B. Vieth, Frontiers in High Performance Computing3(2025), 10.3389/fhpcp.2025.1520207
-
[4]
P. Fischer, M. Min, T. Rathnayake,et al., The Interna- tional Journal of High Performance Computing Applica- tions34, 562 (2020)
work page 2020
-
[5]
M. W. M. G. Issanayake and N. Phan-Thien, Commu- nications in Numerical Methods in Engineering10, 195 (1994)
work page 1994
-
[6]
Dis- covering the rheology of antarctic ice shelves via physics- informed deep learning,
Y. Wang, C.-Y. Lai, C. Cowen-Breen, and et al., “Dis- covering the rheology of antarctic ice shelves via physics- informed deep learning,”https://doi.org/10.21203/ rs.3.rs-2135795/v1(2022), pREPRINT (Version 1) available at Research Square
work page 2022
- [7]
-
[8]
M. A. Giorgetta, R. Brokopf, T. Crueger, M. Esch, S. Fiedler, J. Helmert, C. Hohenegger, L. Kornblueh, S. Rast, D. Reinert, M. Sakradzija, M. Schubert-Frisius, H. Wan, G. Zaengl, and B. Stevens, Journal of Advances in Modeling Earth Systems10, 1635 (2018)
work page 2018
- [9]
- [10]
-
[11]
M. Schwabe, L. Pastori, I. de Vega, P. Gentine, L. Iapichino, V. Lahtinen, M. Leib, J. M. Lorenz, and V. Eyring, Environmental Data Science4(2025), 10.1017/eds.2025.10010
-
[12]
Y. Wang, C.-Y. Lai, J. G´ omez-Serrano, and T. Buck- master, Phys. Rev. Lett.130, 244002 (2023)
work page 2023
-
[13]
Discovery of unstable singularities,
Y. Wang, M. Bennani, J. Martens, S. Racani` ere, S. Blackwell, A. Matthews, S. Nikolov, G. Cao-Labora, D. S. Park, M. Arjovsky, D. Worrall, C. Qin, F. Alet, B. Kozlovskii, N. Tomaˇ sev, A. Davies, P. Kohli, T. Buck- master, B. Georgiev, J. G´ omez-Serrano, R. Jiang, and C.-Y. Lai, “Discovery of unstable singularities,” (2025), arXiv:2509.14185 [math.AP]
-
[14]
T. G. Grossmann, U. J. Komorowska, J. Latz, and C.- B. Sch¨ onlieb, IMA Journal of Applied Mathematics89, 143 (2024), https://academic.oup.com/imamat/article- pdf/89/1/143/58325885/hxae011.pdf
work page 2024
-
[15]
P.-Y. Chuang and L. A. Barba, “Experience report of physics-informed neural networks in fluid simula- tions: pitfalls and frustration,” (2022), arXiv:2205.14249 [physics.flu-dyn]
-
[16]
A. P´ erez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. Latorre, Quantum4, 226 (2020)
work page 2020
-
[17]
O. Kyriienko, A. E. Paine, and V. E. Elfving, Phys. Rev. A103, 052416 (2021)
work page 2021
- [18]
- [19]
-
[20]
C. Trahan, M. Loveland, and S. Dent, Entropy26 (2024), 10.3390/e26080649
- [21]
- [22]
-
[23]
Ef- fective dimension of machine learning models,
A. Abbas, D. Sutter, A. Figalli, and S. Woerner, “Ef- fective dimension of machine learning models,” (2021), arXiv:2112.04807 [cs.LG]
-
[24]
M. Schuld, R. Sweke, and J. J. Meyer, Physical Review A103(2021), 10.1103/physreva.103.032430
-
[25]
M. C. Caro, H.-Y. Huang, M. Cerezo, K. Sharma, A. Sornborger, L. Cincio, and P. J. Coles, Nature Com- munications13, 4919 (2022). 6
work page 2022
-
[26]
J.-P. Liu, H. O. Kolden, H. K. Krovi, N. F. Loureiro, K. Trivisa, and A. M. Childs, Proceed- ings of the National Academy of Sciences118(2021), 10.1073/pnas.2026805118
- [27]
-
[28]
Understanding and mitigating gradient pathologies in physics-informed neural networks,
S. Wang, Y. Teng, and P. Perdikaris, “Understanding and mitigating gradient pathologies in physics-informed neural networks,” (2020), arXiv:2001.04536 [cs.LG]
-
[29]
“See supplemental material at [url will be inserted by publisher] for information about the specifications of the pinn implementation, results for further boundary con- ditions, hyperparameter studies and training insights for qpinns.”URL_will_be_inserted_by_publisher(2025)
work page 2025
-
[30]
An expert’s guide to training physics-informed neural net- works,
S. Wang, S. Sankaran, H. Wang, and P. Perdikaris, “An expert’s guide to training physics-informed neural net- works,” (2023)
work page 2023
- [31]
-
[32]
Sobol’, USSR Computational Mathematics and Math- ematical Physics7, 86 (1967)
I. Sobol’, USSR Computational Mathematics and Math- ematical Physics7, 86 (1967)
work page 1967
-
[33]
B. Jaderberg, A. A. Gentile, Y. A. Berrada, E. Shishen- ina, and V. E. Elfving, Phys. Rev. A109, 042421 (2024)
work page 2024
-
[34]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
V. Bergholm, J. Izaac, M. Schuld, C. Gogolin, C. Blank, K. McKiernan, and N. Killoran, “Pennylane: Automatic differentiation of hybrid quantum-classical computa- tions,” (2018), arXiv:1811.04968 [quant-ph], 1811.04968
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
P. Kidger and C. Garcia, Differentiable Programming workshop at Neural Information Processing Systems 2021 (2021)
work page 2021
-
[36]
DeepMind, I. Babuschkin, K. Baumli, A. Bell, S. Bhu- patiraju, J. Bruce, P. Buchlovsky, D. Budden, T. Cai, A. Clark, I. Danihelka, A. Dedieu, C. Fantacci, J. God- win, C. Jones, R. Hemsley, T. Hennigan, M. Hes- sel, S. Hou, S. Kapturowski, T. Keck, I. Kemaev, M. King, M. Kunesch, L. Martens, H. Merzic, V. Miku- lik, T. Norman, G. Papamakarios, J. Quan, R....
work page 2020
-
[37]
JAX: com- posable transformations of Python+NumPy programs,
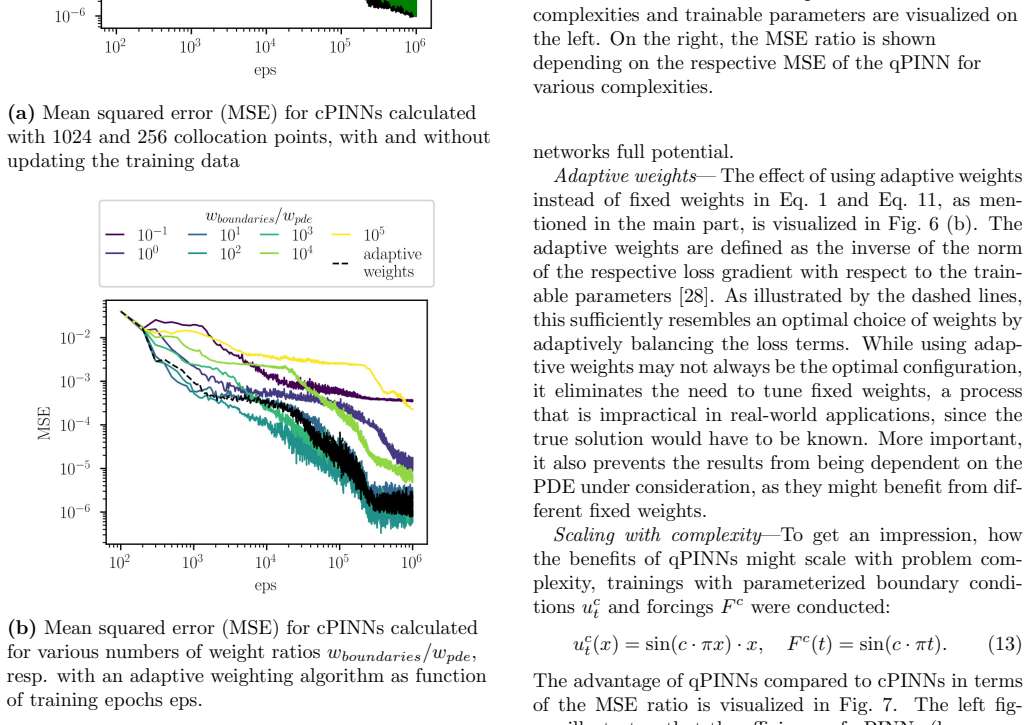
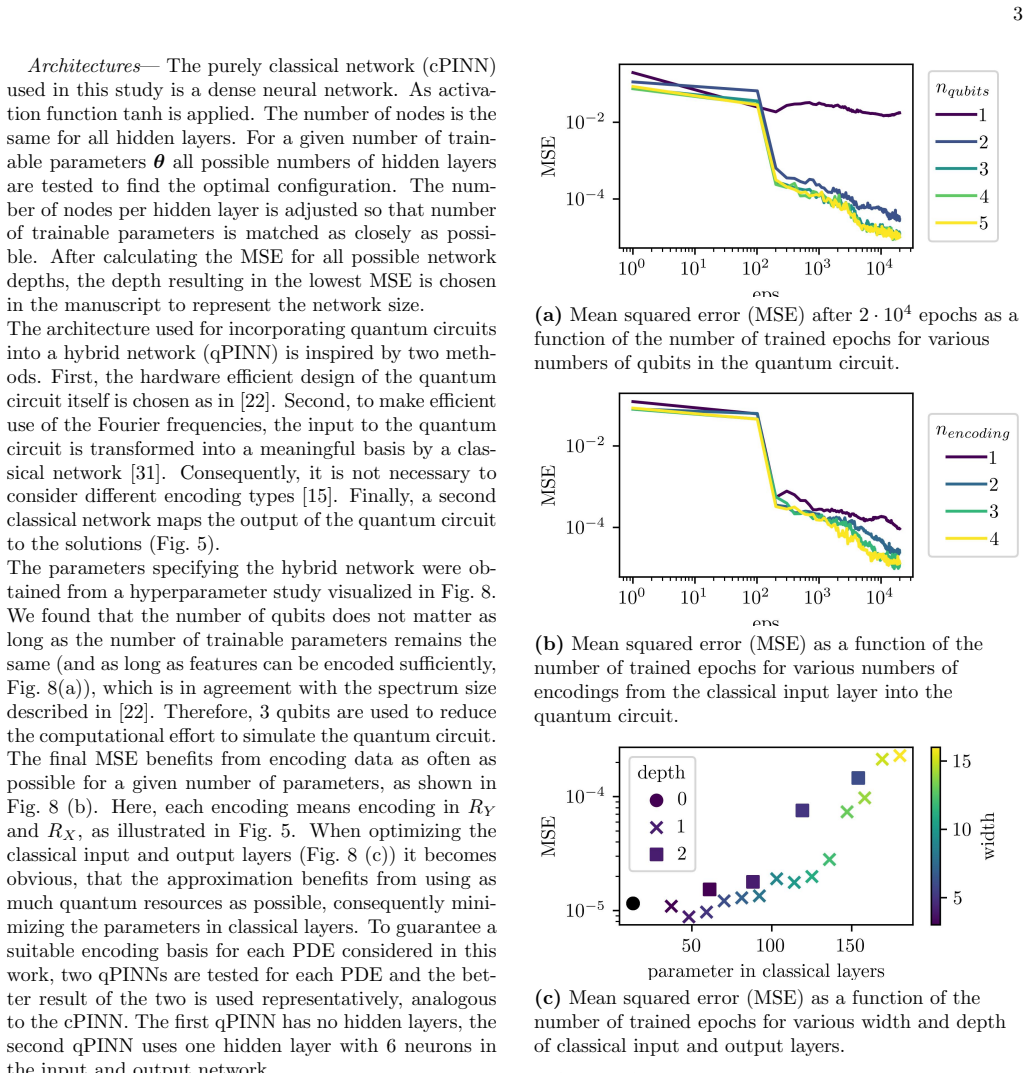
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. Vander- Plas, S. Wanderman-Milne, and Q. Zhang, “JAX: com- posable transformations of Python+NumPy programs,” (2018). 1 Supplemental Material Physics-informed neural networks— In general, a PDE can be defined by D(u) = 0 (8) whereDis a differential operato...
work page 2018
-
[38]
and jax [35] were used. Equinox enables easy in- tegration of quantum circuits defined in pennylane in a differentiable network. Therefore the same training work- flow, based on optax, can be applied to train all networks. jax accelerates the training process. In this study, shot noise is not taken into account, as the primary focus is on exploring the fu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.