Recognition: 2 theorem links
· Lean TheoremContextualized Visual Personalization in Vision-Language Models
Pith reviewed 2026-05-16 08:18 UTC · model grok-4.3
The pith
CoViP trains vision-language models to link new images to a user's past visual experiences for personalized responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
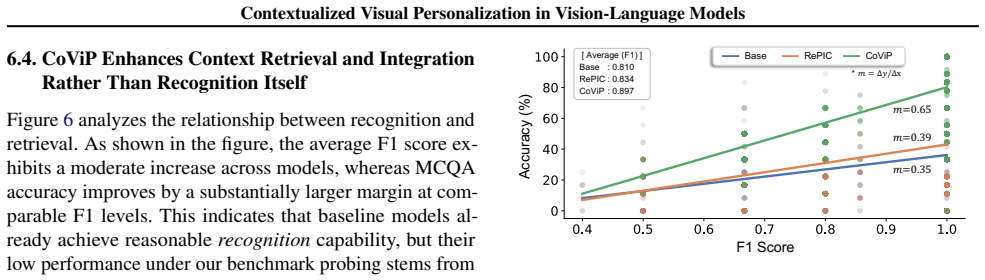
By treating personalized image captioning as the foundational task and applying reinforcement-learning-based post-training together with caption-augmented generation, CoViP enables VLMs to associate new visual inputs with a user's accumulated visual-textual context, as confirmed by diagnostic tests that explicitly exclude reliance on textual patterns alone.
What carries the argument
CoViP, a unified framework that uses reinforcement-learning post-training and caption-augmented generation to ground personalized image captioning in visual context.
If this is right
- Personalized image captioning accuracy rises substantially over prior VLM baselines.
- Performance improves across multiple downstream personalization tasks without task-specific retraining.
- Existing open-source and proprietary VLMs show clear limitations when forced to rely on visual rather than textual cues.
- Diagnostic evaluations can be reused to verify visual grounding in future personalization methods.
Where Pith is reading between the lines
- The same post-training recipe could be applied to video or multi-image memory tasks where users expect models to recall earlier visual episodes.
- If the diagnostic tests prove reliable, they could become standard checks for any claim that a VLM is using visual memory rather than prompt leakage.
- Scaling the approach might reduce the need for explicit user-provided context in long conversations by letting the model retrieve its own stored visual history.
Load-bearing premise
The reinforcement-learning post-training and caption-augmented generation cause the model to draw on actual visual features rather than learned textual patterns.
What would settle it
A test set in which visual features are altered while textual descriptions stay identical; if personalization accuracy drops sharply, the model was using visuals; if it stays high, it was using textual shortcuts.
Figures




read the original abstract
Despite recent progress in vision-language models (VLMs), existing approaches often fail to generate personalized responses based on the user's specific experiences, as they lack the ability to associate visual inputs with a user's accumulated visual-textual context. We newly formalize this challenge as contextualized visual personalization, which requires the visual recognition and textual retrieval of personalized visual experiences by VLMs when interpreting new images. To address this issue, we propose CoViP, a unified framework that treats personalized image captioning as a core task for contextualized visual personalization and improves this capability through reinforcement-learning-based post-training and caption-augmented generation. We further introduce diagnostic evaluations that explicitly rule out textual shortcut solutions and verify whether VLMs truly leverage visual context. Extensive experiments demonstrate that existing open-source and proprietary VLMs exhibit substantial limitations, while CoViP not only improves personalized image captioning but also yields holistic gains across downstream personalization tasks. These results highlight CoViP as a crucial stage for enabling robust and generalizable contextualized visual personalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes contextualized visual personalization for VLMs, proposes the CoViP framework that uses personalized image captioning as the core task improved via RL-based post-training and caption-augmented generation, introduces diagnostic evaluations claimed to rule out textual shortcuts, and reports that existing VLMs are limited while CoViP yields gains on captioning and downstream personalization tasks.
Significance. If the diagnostic evaluations genuinely isolate visual context use and the reported gains are substantial, reproducible, and not reducible to improved language modeling alone, the work would meaningfully advance personalized VLM capabilities beyond generic responses.
major comments (1)
- [Diagnostic Evaluations] Diagnostic Evaluations section: the claim that the introduced diagnostics 'explicitly rule out textual shortcut solutions' is load-bearing for the central claim that CoViP produces genuine visual-context use rather than learned textual patterns from caption augmentation; however, the manuscript provides no concrete construction details for negative examples, no text-only ablation results on the same images, and no quantitative threshold demonstrating visual dependency, leaving open the possibility that downstream gains are explained by language modeling improvements alone.
minor comments (1)
- [Abstract] Abstract and results sections: no quantitative metrics, error bars, or baseline comparisons are visible in the provided abstract, which undermines the ability to assess the magnitude of the claimed 'substantial limitations' in existing VLMs and 'holistic gains' with CoViP.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our diagnostic evaluations. We address the single major comment below and will revise the manuscript to incorporate additional details and results.
read point-by-point responses
-
Referee: [Diagnostic Evaluations] Diagnostic Evaluations section: the claim that the introduced diagnostics 'explicitly rule out textual shortcut solutions' is load-bearing for the central claim that CoViP produces genuine visual-context use rather than learned textual patterns from caption augmentation; however, the manuscript provides no concrete construction details for negative examples, no text-only ablation results on the same images, and no quantitative threshold demonstrating visual dependency, leaving open the possibility that downstream gains are explained by language modeling improvements alone.
Authors: We agree that the current presentation of the diagnostics would benefit from greater specificity to fully support the claim of ruling out textual shortcuts. In the revised manuscript we will expand the Diagnostic Evaluations section with: (1) explicit construction details and examples for the negative cases designed to block textual pattern exploitation; (2) text-only ablation results run on the identical image sets, quantifying the performance drop when visual input is removed; and (3) quantitative thresholds or dependency metrics (e.g., accuracy delta and visual-attention scores) that demonstrate reliance on visual context rather than language-modeling gains alone. These additions will directly address the concern and strengthen evidence that CoViP improvements arise from genuine visual-context utilization. revision: yes
Circularity Check
No circularity: standard RL post-training and new diagnostics applied to a formalized task
full rationale
The paper formalizes contextualized visual personalization as a new challenge, then applies reinforcement-learning post-training and caption-augmented generation to the core task of personalized image captioning. Diagnostic evaluations are introduced to check for visual context use versus textual shortcuts. No equations, parameters, or claims reduce by construction to fitted inputs or self-definitions; results are shown via experiments on downstream tasks using external benchmarks. No load-bearing self-citations, uniqueness theorems, or ansatz smuggling appear in the derivation chain. The framework is self-contained against standard VLMs and RL techniques.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose CoViP, a unified framework that treats personalized image captioning as a core task... through reinforcement-learning-based post-training and caption-augmented generation... diagnostic evaluations that explicitly rule out textual shortcut solutions
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We design diagnostic evaluation tasks... Last-Seen Detection (LSD), Last-Action Recall (LAR), Instruction-Triggered Recall (ITR)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Omni-Persona: Systematic Benchmarking and Improving Omnimodal Personalization
Omni-Persona benchmark with 18 tasks shows open-source models have audio-visual grounding gaps, RLVR narrows them but leads to conservative outputs, and scale or recall alone fail as diagnostics.
Reference graph
Works this paper leans on
-
[1]
Object Hallucination in Image Captioning
Springer, 2024. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pp. 8748–8763. PmLR, 2021. Rohrbach, A., Hendricks, L. A., Burns, K., Darrell, T., and Saenko, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
I still remember the day I saw John at Lake Francesborough on 2025-09-09
Last-Seen Detection (LSD)In the LSD task, each dialogue contains an explicit reference to when and where the user encountered the individual, e.g.,“I still remember the day I saw John at Lake Francesborough on 2025-09-09. ” Given a new query image, the user asks:“Where did I last see the person in this image?” To answer correctly, the model must identify ...
work page 2025
-
[3]
Oh wait, I need to go to the post office to return this package
Last-Action Recall (LAR)LAR extends LSD by requiring recall of a finer-grained personal action rather than a location. For each context, we append an additional user utterance to thelast-seen dialogueof the query individual, describing a specific action, e.g.,“Oh wait, I need to go to the post office to return this package. ” The action is randomly sample...
-
[4]
If this person ever shows up again, remind me by saying the keyword SKS
Instruction-Triggered Recall (ITR)ITR evaluates a more proactive form of personalization. In this task, the last-seen dialogue includes an instruction of the form:“If this person ever shows up again, remind me by saying the keyword SKS. ” At inference time, the user asks a generic question such as:“Where did I last see the person in this image?”without ex...
work page 2024
-
[5]
Necessity of joint supervision.Training with only rvis (without rcaps) degrades performance, in some cases falling below the Qwen3-VL-8B baseline, indicating that visual supervision alone is insufficient for personalized image captioning. Conversely, optimizing only rcaps also yields consistently weaker results, suggesting retrieval signals without fine-g...
-
[6]
F1-based vision VR vs. binary consistency VR.Replacing RePIC’s object-consistency VR (OCT), which provides binary correctness feedback, with our set-based F1 VR rvis consistently improves performance on positive accuracy. This indicates that set-level supervision provides a denser and more robust learning signal for multi-concept perception
-
[7]
Effect of increasing the number of positive concepts.Varying the number of positive concepts included during 23 Contextualized Visual Personalization in Vision-Language Models (a) Category Accuracy (%)(b) Per TaskAccuracy (%) MMIU Figure S.10.Results on MMIU (11K MCQs across 52 tasks), which evaluates multi-image relational understanding spanning temporal...
work page 2025
-
[8]
Any concept image is occluded or not fully visible in the query image
-
[9]
Any concept does not appear in the query image at all
-
[10]
Any object or person in the query image is significantly different from the corresponding concept image. [Answering rule] Output "yes" only when every concept appears in the query image. Carefully examine the images and output the final result only as"yes"or"no". 28 Contextualized Visual Personalization in Vision-Language Models Table S.11.Showcase of a u...
-
[11]
This looks like Pino again, perhaps older than in the park photo from Busan Station
Recall and reuse detailsfrom the previous dialogues (object names, appearances, places, times, and relationships). – Treat the previous dialogues as long-term memory. – If an object in the new image appears similar to one mentioned in the past, refer to it using the same name and contextual background. 2.Ground your description in the new image’s visual c...
-
[12]
Keep your tone natural and human-like, as if describing something familiar to the same user
-
[13]
Do not restate previous dialogues verbatim; instead, synthesize and extend them with new image- grounded observations
-
[14]
Write in paragraph form, not in a dialogue format. 6.Use only relevant memories. – If an object or scene from the previous dialogues doesnot appear in the new image, ignore it completely. – Include contextual information only for objects that actually appear. – Avoid unrelated names, locations, or events. 29 Contextualized Visual Personalization in Vision...
-
[15]
• Do not invent or alter the name
The main object’s name ({name}) must be used consistently throughout the dialogue. • Do not invent or alter the name
-
[16]
The user should describe a personal experience related to{name}. • The experience must include at least oneobjective contextual element, such as a specificplace, time,event, orsituation(e.g., “last summer at the riverside,” “during my first year in college,” “in my grandmother’s backyard”)
-
[17]
The model should respond naturally and empathetically — acknowledging, asking gentle questions, or adding brief reflections
-
[18]
Keep the tone human-like, calm, and realistic — not overly emotional or robotic
-
[19]
The conversation should have6 turns total(User→Model→User→Model→User→Model)
-
[20]
Focus on thepersonal connectionandshared observa- tionof the object
Avoid encyclopedic or factual world knowledge. Focus on thepersonal connectionandshared observa- tionof the object. [Output Format] Dialogue: User: ... Model: ... User: ... Model: ... User: ... Model: ... 30 Contextualized Visual Personalization in Vision-Language Models Table S.13.Visualization of a prompt used to generate MCQA pairs from the dialogue. M...
-
[21]
Each question must target an objective detail present in the conversation (e.g., name, place, time, habit/action)
-
[22]
Avoid emotions, opinions, or meta-dialogue
-
[23]
Each question must have exactly 3 options: A, B, C
-
[24]
Exactly one option is correct among A, B, C
-
[25]
Make the wrong options (A/B/C except the correct one) plausible but clearly incorrect
-
[26]
DoNOTrequire external/world knowledge; answers must come from the conversation content
-
[27]
Output must be valid JSON only: no additional text and no trailing commas. [JSON Output Schema] { "qa": [ { "id": "Q1", "question": "<string>", "options": { "A": "<string>", "B": "<string>", "C": "<string>" }, "correct_answer": "A" | "B" | "C" }, { "id": "Q2", "question": "<string>", "options": { ... }, "correct_answer": "A" | "B" | "C" }, { "id": "Q3", "...
-
[28]
Read the description carefully
-
[29]
• Ifnoneof A/B/C can be confirmed from the description, choose D
For each question, choose thesingle bestoption: • If one of A/B/C is explicitly or clearly supported by the description, choose that option. • Ifnoneof A/B/C can be confirmed from the description, choose D
-
[30]
You must ignore any information that is not in the description
-
[31]
For each question: • You may briefly explain your reasoning in natural language. • Then, on a separate line, output the final choice in the exact format: [Required output format] Answer:\boxed{X} whereXis one ofA, B, C, or D. Inside\boxed{}there must beexactly one letter, with no extra text. [Given] •[Description]{Generated caption} •[Question]{Pre-define...
-
[32]
• Do not invent, alter, or omit the name
The person’s name ({name}) must be used consistently throughout the dialogue. • Do not invent, alter, or omit the name
-
[33]
The user must describe apersonal experiencerelated to{name}. • The experience must include at least one concreteevent or situation(e.g., bumping into them, having a short conversation, noticing what they were doing). • It should include at least onesensory or situational detailthat makes the memory feel realistic
-
[34]
I saw them on{seen date}at{seen place}
The user must explicitly mentionboththe date and the place: • Date:{seen date} • Place:{seen place} • Preferably within a single user turn (e.g., “I saw them on{seen date}at{seen place}...”)
-
[35]
• Do not introduce new factual information beyond what the user provides
The model should respond naturally and empathetically, acknowledging the user’s experience or asking gentle follow-up questions. • Do not introduce new factual information beyond what the user provides
-
[36]
Avoid encyclopedic or factual descriptions
Keep the tone calm, realistic, and human-like. Avoid encyclopedic or factual descriptions
-
[37]
[Output Format] Dialogue: User:
The conversation must haveexactly 6 turnsin total: User→Model→User→Model→User→Model. [Output Format] Dialogue: User: ... Model: ... User: ... Model: ... User: ... Model: ... 34 Contextualized Visual Personalization in Vision-Language Models Table S.17.Prompt visualization used for diagnostic downstream tasks. Personalized Image Understanding Prompt: You a...
-
[38]
This looks like Pino again, now indoors instead of the park near Busan Station
Recall and reuse detailsfrom the previous dialogues (object names, appearances, places, times, and relationships). • Treat the previous dialogues as your long-term memory. • If an object in the new image appears similar to one mentioned in the past, refer to it with the same name and contextual background. 2.Ground your understanding in the new image’s vi...
-
[39]
Keep your tone natural and human-like — as if you are interpreting something familiar to the same user
-
[40]
Instead, synthesize memory with the current image content
Do not restate previous dialogues verbatim. Instead, synthesize memory with the current image content
-
[41]
Oh wait, I think I left my wallet at the Guess store, so I’m going back to check
Write inparagraph form, not in a dialogue format. 6.Use only relevant memories. • If an object or context from past dialogues doesnotappear in the new image, ignore it completely. • Add contextual information only when it helps understanding of what is visible. • Avoid mentioning unrelated names, locations, or experiences. 35 Contextualized Visual Persona...
-
[42]
A question asked to the model
-
[43]
A ground-truth reference answer (GT)
-
[44]
A generated response from the model Your task is to decide whether the generated response isCorrectorWrong. Evaluation Criteria: • The generated response isCorrectif it semantically includes the core information conveyed by the ground-truth reference. • The wording does NOT need to match exactly. Paraphrases, rephrasings, or additional details are allowed...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.