Recognition: 2 theorem links
· Lean TheoremConformal Thinking: Risk Control for Reasoning on a Compute Budget
Pith reviewed 2026-05-16 07:43 UTC · model grok-4.3
The pith
Distribution-free risk control sets upper and lower thresholds so LLMs stop reasoning early while keeping error rates below a user target.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given a target risk level and a validation set, distribution-free risk control can be used to choose both an upper threshold that stops reasoning when the model becomes confident and a novel parametric lower threshold that stops on instances unlikely to be solved. The resulting procedure bounds the probability that the final output is incorrect while minimizing expected token use; when multiple candidate rules exist, an efficiency loss selects the cheapest rule that still satisfies the risk bound.
What carries the argument
Distribution-free risk control applied to upper and lower stopping thresholds, with a parametric lower threshold that identifies unsolvable cases.
If this is right
- The probability that any output is incorrect remains below the user-specified risk target.
- Early termination on unsolvable problems reduces average token count without violating the risk bound.
- When several stopping rules are considered, the efficiency loss selects the one with lowest compute among those that meet the risk target.
- The same calibration procedure applies to any reasoning LLM and any task for which a validation set can be collected.
Where Pith is reading between the lines
- The same calibration could be applied to other adaptive-compute choices such as model selection or tool use.
- Extending the parametric lower threshold to multiple risk types at once would allow joint control over accuracy and other costs.
- Deployed systems could let users set different risk targets per query type, with the validation set updated periodically to maintain the bound.
Load-bearing premise
The validation set must be drawn from the same distribution as future queries so the risk bound carries over, and the parametric form chosen for the lower threshold must separate unsolvable instances without stopping too many solvable ones.
What would settle it
Apply the calibrated thresholds to a fresh test set drawn from the same distribution; if the observed error rate exceeds the target risk level, the guarantee does not hold.
Figures
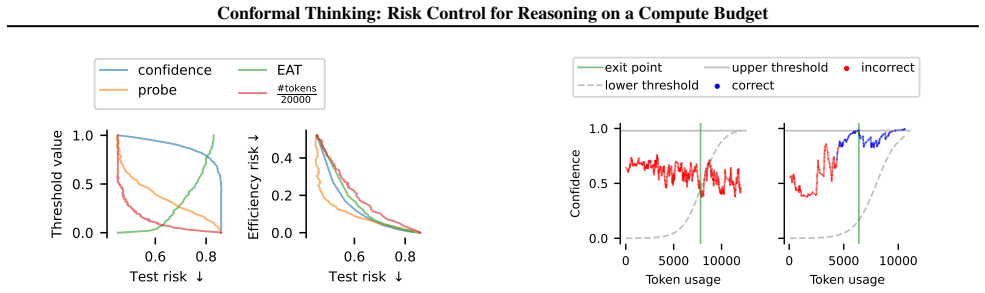



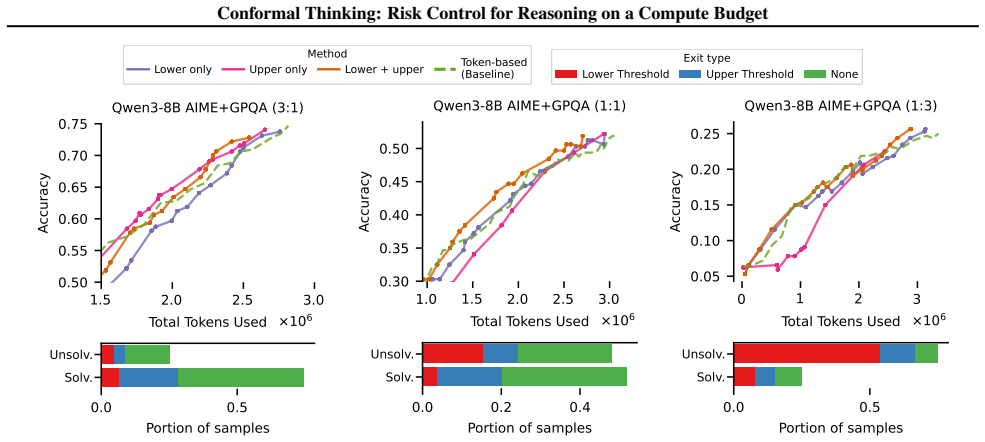

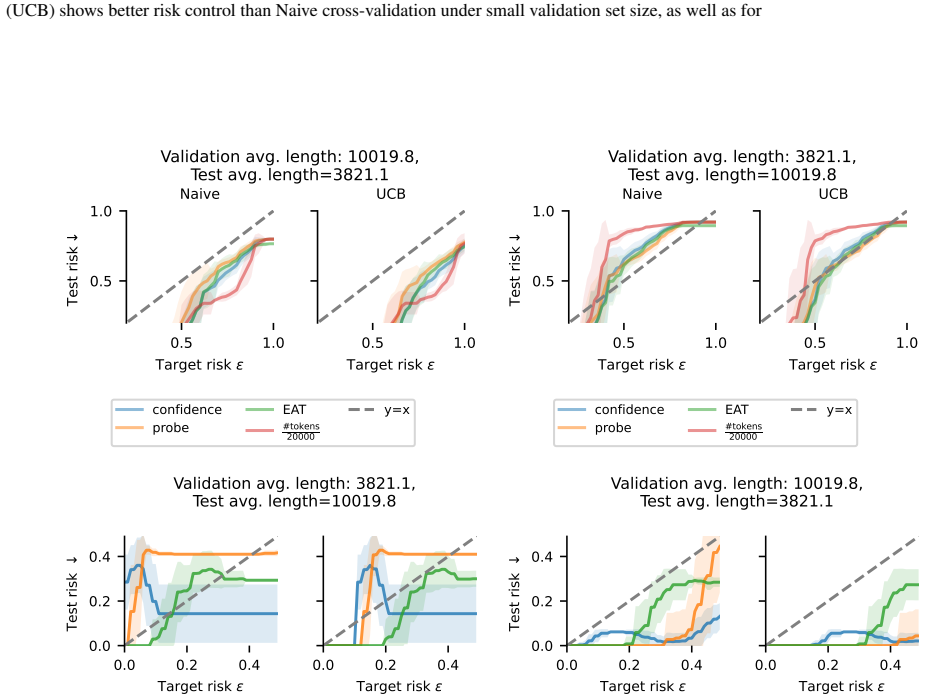

read the original abstract
Reasoning Large Language Models (LLMs) enable test-time scaling, with dataset-level accuracy improving as the token budget increases, motivating adaptive reasoning -- spending tokens when they improve reliability and stopping early when additional computation is unlikely to help. However, setting the token budget, as well as the threshold for adaptive reasoning, is a practical challenge that entails a fundamental risk-accuracy trade-off. We re-frame the budget setting problem as risk control, limiting the error rate while minimizing compute. Our framework introduces an upper threshold that stops reasoning when the model is confident (risking incorrect output) and a novel parametric lower threshold that preemptively stops unsolvable instances (risking premature stoppage). Given a target risk and a validation set, we use distribution-free risk control to optimally specify these stopping mechanisms. For scenarios with multiple budget controlling criteria, we incorporate an efficiency loss to select the most computationally efficient exiting mechanism. Empirical results across diverse reasoning tasks and models demonstrate the effectiveness of our risk control approach, demonstrating computational efficiency gains from the lower threshold and ensemble stopping mechanisms while adhering to the user-specified risk target.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes 'Conformal Thinking,' a framework that reframes token-budget setting for reasoning LLMs as a risk-control problem. It introduces an upper threshold to stop when the model is confident and a novel parametric lower threshold to preemptively halt unsolvable instances, both calibrated via distribution-free risk control on a validation set to meet a user-specified target risk while minimizing compute. For multiple stopping criteria an efficiency loss is used to select the most efficient mechanism. Empirical results across reasoning tasks and models are reported to show efficiency gains while respecting the risk target.
Significance. If the distribution-free guarantees survive the optimization step, the work supplies a practical, non-parametric method for managing the accuracy-compute trade-off in test-time scaling of LLMs. The combination of conformal calibration with a parametric early-stopping rule and an explicit efficiency objective is a concrete contribution that could be adopted in production reasoning pipelines.
major comments (2)
- [Abstract / risk-control procedure] Abstract and the risk-control procedure: the claim that distribution-free risk control is used to 'optimally specify' the stopping mechanisms is undermined by the joint optimization of the parametric lower-threshold parameters via the efficiency loss on the same validation set. This step selects both the mechanism and its cutoff, rendering the final decision rule data-dependent and violating the exchangeability assumption required for standard conformal risk control to deliver the stated marginal coverage guarantee.
- [risk-control procedure] The description of the efficiency-loss optimization: no sample-splitting, hold-out set, or post-hoc correction is mentioned that would restore validity after the lower threshold is tuned on the calibration data. Without such a separation the reported risk control may be optimistically biased and the empirical adherence to the target risk on held-out data does not by itself establish the distribution-free property.
minor comments (2)
- [Abstract] The abstract supplies no equations, pseudocode, or concrete definition of the parametric lower threshold or the efficiency loss; these omissions make it impossible to verify the claimed optimality or to reproduce the calibration step from the text alone.
- [Empirical evaluation] The manuscript should clarify whether the validation set used for threshold selection is disjoint from any data used to report final risk and efficiency numbers, and should include a table or plot showing achieved risk versus target risk across multiple random splits.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the risk-control procedure. The comments highlight an important subtlety regarding the interaction between efficiency-loss optimization and conformal calibration. We address each point below and will revise the manuscript to incorporate sample splitting, thereby restoring the distribution-free guarantees while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract / risk-control procedure] Abstract and the risk-control procedure: the claim that distribution-free risk control is used to 'optimally specify' the stopping mechanisms is undermined by the joint optimization of the parametric lower-threshold parameters via the efficiency loss on the same validation set. This step selects both the mechanism and its cutoff, rendering the final decision rule data-dependent and violating the exchangeability assumption required for standard conformal risk control to deliver the stated marginal coverage guarantee.
Authors: We agree that performing the efficiency-loss optimization jointly with threshold selection on the same validation set used for conformal calibration renders the final rule data-dependent and can violate the exchangeability assumption underlying standard conformal risk control. To correct this, we will revise the method to use explicit sample splitting: the validation set will be partitioned into a calibration subset for conformal risk control and an independent tuning subset for optimizing the efficiency loss and selecting among stopping mechanisms. The abstract and Section 3 will be updated to describe this two-stage procedure, and we will add a brief argument showing that the marginal coverage guarantee is preserved on the calibration subset. This constitutes a substantive but localized change to the algorithm. revision: yes
-
Referee: [risk-control procedure] The description of the efficiency-loss optimization: no sample-splitting, hold-out set, or post-hoc correction is mentioned that would restore validity after the lower threshold is tuned on the calibration data. Without such a separation the reported risk control may be optimistically biased and the empirical adherence to the target risk on held-out data does not by itself establish the distribution-free property.
Authors: We acknowledge that the current manuscript does not describe sample splitting or any post-hoc correction, so the theoretical distribution-free property is not rigorously established by the existing procedure. In the revision we will introduce a dedicated hold-out tuning set for the efficiency-loss optimization, perform conformal calibration exclusively on the remaining calibration data, and re-run all experiments under this corrected protocol. The revised text will include both the updated algorithm and a short proof sketch confirming that the marginal risk bound continues to hold. Empirical results on the original held-out test sets will be retained for comparison, but the primary claims will now rest on the split-validation procedure. revision: yes
Circularity Check
Minor data-dependence from efficiency loss but no reduction by construction
full rationale
The framework applies distribution-free risk control on a held-out validation set to set upper/lower thresholds and uses an efficiency loss only for tie-breaking among multiple criteria. No quoted equation or derivation shows the final risk bound or selected mechanism reducing to a fitted parameter by construction; the calibration step remains separate from the efficiency selection. This is standard conformal practice and does not match any enumerated circularity pattern. Score kept at 2 to reflect the potential exchangeability concern raised by joint optimization without claiming an explicit self-referential collapse.
Axiom & Free-Parameter Ledger
free parameters (2)
- target risk level
- efficiency loss weighting
axioms (1)
- domain assumption Distribution-free risk control guarantees transfer from validation set to test distribution
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
parametric lower threshold... λ−(t;c)=σ(c(ωt−B/2))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Process Supervision of Confidence Margin for Calibrated LLM Reasoning
RLCM trains LLMs with a margin-enhanced process reward that widens the gap between correct and incorrect reasoning steps, improving calibration on math, code, logic, and science tasks without hurting accuracy.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URL https://arxiv.org/abs/2501.12948. Fu, Y ., Chen, J., Zhu, S., Fu, Z., Dai, Z., Zhuang, Y ., Ma, Y ., Qiao, A., Rosing, T., Stoica, I., and Zhang, H. Effi- ciently scaling llm reasoning with certaindex,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URL https://arxiv.org/abs/2412.20993. Jazbec, M., Timans, A., Hadˇzi Veljkovi´c, T., Sakmann, K., Zhang, D., Andersson Naesseth, C., and Nalisnick, E. Fast yet safe: Early-exiting with risk control.Advances in Neural Information Processing Systems, 37:129825– 129854,
-
[3]
URL https: //aclanthology.org/2025.acl-short.50/. Langley, P. Crafting papers on machine learning. In Langley, P. (ed.),Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp. 1207–1216, Stan- ford, CA,
work page 2025
- [4]
-
[5]
Luo, M., Tan, S., Wong, J., Shi, X., Tang, W
URL https: //arxiv.org/abs/2506.02536. Luo, M., Tan, S., Wong, J., Shi, X., Tang, W. Y ., Roongta, M., Cai, C., Luo, J., Li, L. E., Popa, R. A., and Stoica, I. Deepscaler: Surpass- ing o1-preview with a 1.5b model by scaling rl. https://pretty-radio-b75.notion.site/ DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303...
-
[6]
URL https://arxiv.org/abs/2509.14004. Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y ., Dirani, J., Michael, J., and Bowman, S. R. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling,
-
[7]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Snell, C., Lee, J., Xu, K., and Kumar, A. Scaling llm test- time compute optimally can be more effective than scal- ing model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Entropy After </Think> for reasoning model early exiting
URL https: //openreview.net/forum?id=QWTCcxMpPA. Wang, X., McInerney, J., Wang, L., and Kallus, N. Entropy after ⟨/Think⟩ for reasoning model early exiting, 2025a. URLhttps://arxiv.org/abs/2509.26522. Wang, Y ., Zhang, Y ., Yu, T., Xu, C., Zhang, F., and Lian, F. Adaptive deep reasoning: Triggering deep thinking when needed, 2025b. URL https://arxiv.org/ ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
URL https://arxiv. org/abs/2508.17627. Wu, M., Zhou, C., Bates, S., and Jaakkola, T. Thought calibration: Efficient and confident test-time scal- ing.ArXiv, abs/2505.18404,
-
[10]
Zeng, H., Huang, J., Jing, B., Wei, H., and An, B
URL https://arxiv.org/ abs/2504.15895. Zeng, H., Huang, J., Jing, B., Wei, H., and An, B. Pac reasoning: Controlling the performance loss for efficient reasoning,
-
[11]
Zhang, A., Chen, Y ., Pan, J., Zhao, C., Panda, A., Li, J., and He, H
URL https://arxiv.org/abs/ 2510.09133. Zhang, A., Chen, Y ., Pan, J., Zhao, C., Panda, A., Li, J., and He, H. Reasoning models know when they’re right: Probing hidden states for self-verification,
-
[12]
URL https://arxiv.org/abs/2504.05419. 10 Conformal Thinking: Risk Control for Reasoning on a Compute Budget A. Extended experiment specifications. A.1. Signal Extraction We evaluate confidence signals that measure uncertainty or confidence at each thought chunk. Specifically, we focus on two primary metrics: Entropy After</think>(Wang et al., 2025b, EAT) ...
-
[13]
The probe is trained on AIME 1983–2024
to predict stepwise correctness ys from the representationh s. The probe is trained on AIME 1983–2024. 11 Conformal Thinking: Risk Control for Reasoning on a Compute Budget B. Risk control and finite-sample correction This section details how we calibrate threshold parameters using distribution-free risk control. The goal is to select a signal–threshold p...
work page 1983
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.