Recognition: unknown
Process Supervision of Confidence Margin for Calibrated LLM Reasoning
Pith reviewed 2026-05-08 08:16 UTC · model grok-4.3
The pith
Reinforcement learning with widened confidence margins between correct and incorrect steps calibrates LLM reasoning while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RLCM encourages models to widen the confidence margin between correct and incorrect steps within a reasoning trajectory by applying a margin-enhanced process reward over intermediate-budget completions, jointly optimizing for both correctness and calibration reliability.
What carries the argument
Margin-enhanced process reward that penalizes narrow confidence gaps between correct and incorrect steps inside a single trajectory during RL optimization.
If this is right
- Calibration improves on mathematical, code, logic, and science benchmarks while accuracy is maintained or increased.
- Calibrated confidence enables more efficient conformal risk control.
- Calibrated confidence supports effective confidence-weighted answer aggregation.
- Process-level supervision over intermediate steps outperforms outcome-only rewards for calibration.
Where Pith is reading between the lines
- Models trained this way could allocate less unnecessary test-time compute by stopping early when confidence margins are wide.
- The same margin signal might improve safety filters that reject low-margin outputs before they reach users.
- Extending the margin idea to multi-step planning agents could reduce error propagation in long chains.
Load-bearing premise
A margin-enhanced process reward can be stably optimized by RL without introducing new biases or needing extensive per-task tuning.
What would settle it
Running the method on a held-out reasoning benchmark where expected calibration error fails to drop below the baseline while accuracy stays flat or declines.
Figures

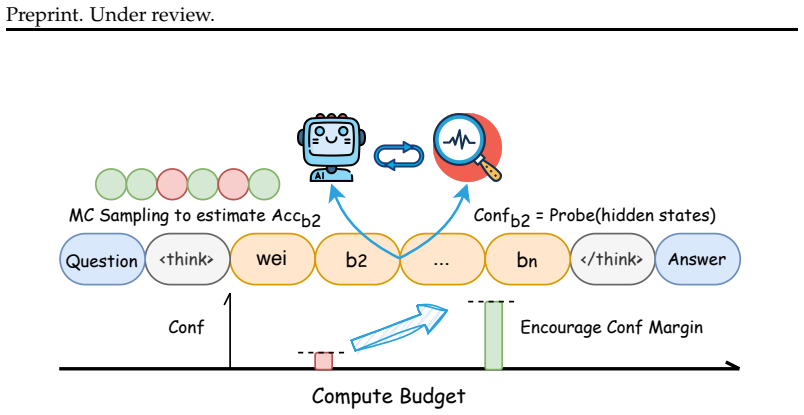






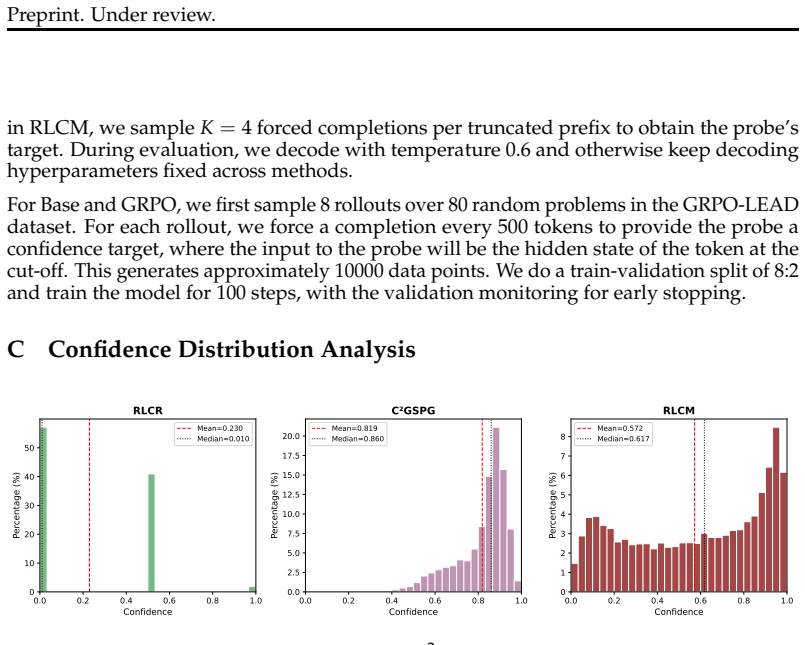

read the original abstract
Scaling test-time computation with reinforcement learning (RL) has emerged as a reliable path to improve large language models (LLM) reasoning ability. Yet, outcome-based reward often incentivizes models to be overconfident, leading to hallucinations, unreliable confidence-based control, and unnecessary compute allocation. We introduce Reinforcement Learning with Confidence Margin (\textbf{RLCM}), a calibration-aware RL framework that jointly optimizes correctness and confidence reliability via a margin-enhanced process reward over intermediate-budget completions. Rather than aligning confidence to correctness likelihoods, RLCM encourages to widen the confidence margin between correct and incorrect steps within a single reasoning trajectory. Across mathematical, code, logic and science benchmarks, our method substantially improves calibration while maintaining or improving accuracy. We further show that, with calibrated confidence signals, the resulting models enable more efficient conformal risk control and effective confidence-weighted aggregation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Reinforcement Learning with Confidence Margin (RLCM), a calibration-aware RL framework for LLMs. It employs a margin-enhanced process reward over intermediate-budget completions to jointly optimize correctness and confidence reliability by widening the confidence margin between correct and incorrect steps within reasoning trajectories. The authors claim that this yields substantial improvements in calibration across mathematical, code, logic, and science benchmarks while maintaining or improving accuracy, and that the resulting calibrated confidence enables more efficient conformal risk control and effective confidence-weighted aggregation.
Significance. If the empirical claims hold with robust evidence, the work addresses a timely and important limitation in scaling test-time compute for LLM reasoning: outcome-based RL often produces overconfident models that undermine reliability in downstream control and aggregation tasks. The process-supervision approach focused on confidence margins offers a distinct alternative to likelihood alignment and could improve trustworthiness in reasoning systems if the gains prove stable and generalizable.
major comments (2)
- Abstract: The central claim of 'substantially improves calibration while maintaining or improving accuracy' is stated without any quantitative results, specific baselines, ablation details, error bars, or statistical significance tests. This absence makes it impossible to determine whether the data support the claim or to evaluate effect sizes relative to prior calibration methods.
- Method (reward formulation): The margin-enhanced process reward is described only at a high level as widening the confidence margin between correct and incorrect steps. Without the exact mathematical definition, how it is incorporated into the RL objective, or training hyperparameters, it is impossible to verify whether the method is independent of quantities already fitted in the model or whether it can be stably optimized without introducing new biases or requiring per-task tuning.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of clarity in our presentation. We address each major comment below and outline the corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: Abstract: The central claim of 'substantially improves calibration while maintaining or improving accuracy' is stated without any quantitative results, specific baselines, ablation details, error bars, or statistical significance tests. This absence makes it impossible to determine whether the data support the claim or to evaluate effect sizes relative to prior calibration methods.
Authors: We agree that the abstract would be strengthened by including quantitative highlights to support the central claim. In the revised manuscript, we will update the abstract to report key results, such as average ECE reductions and accuracy maintenance (or gains) across the math, code, logic, and science benchmarks, with reference to the primary baselines and tables in the main text. This will allow readers to immediately assess effect sizes. revision: yes
-
Referee: Method (reward formulation): The margin-enhanced process reward is described only at a high level as widening the confidence margin between correct and incorrect steps. Without the exact mathematical definition, how it is incorporated into the RL objective, or training hyperparameters, it is impossible to verify whether the method is independent of quantities already fitted in the model or whether it can be stably optimized without introducing new biases or requiring per-task tuning.
Authors: We acknowledge that the main-text description of the reward is concise. The exact formulation appears in Equation (3) of Section 3.2, where the margin-enhanced process reward is defined as r_t = m * I(correct) with m computed as the difference in per-step confidence between correct and incorrect reasoning steps within the same trajectory; this replaces the standard outcome reward in the policy-gradient objective. Hyperparameters (including margin coefficient, RL learning rate, and batch size) are listed in Appendix A. To improve accessibility, we will expand the main-text exposition of the reward definition and its integration into the RL objective, and we will add a brief discussion of why the margin term is independent of the base model's fitted likelihoods. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces RLCM as a new calibration-aware RL framework using a margin-enhanced process reward over intermediate steps. The abstract and available description frame this as an independent training objective that jointly optimizes correctness and confidence reliability, without any quoted equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claim to its own inputs by construction. No self-definitional loops, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation are present in the provided text. The claimed improvements in calibration and downstream uses (conformal risk control, aggregation) are presented as empirical outcomes of the new objective rather than tautological restatements of fitted quantities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=3zKtaqxLhW
2024
-
[2]
Rina Foygel Barber, Emmanuel J Candes, Aaditya Ramdas, and Ryan J Tibshirani
Anastasios N. Angelopoulos, Stephen Bates, Emmanuel J. Cand \`e s, Michael I. Jordan, and Lihua Lei. Learn then test: Calibrating predictive algorithms to achieve risk control . The Annals of Applied Statistics, 19 0 (2): 0 1641 -- 1662, 2025. doi:10.1214/24-AOAS1998. URL https://doi.org/10.1214/24-AOAS1998
-
[3]
Conformal risk control
Anastasios Nikolas Angelopoulos, Stephen Bates, Adam Fisch, Lihua Lei, and Tal Schuster. Conformal risk control. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=33XGfHLtZg
2024
-
[4]
Reconsidering LLM uncertainty estimation methods in the wild
Yavuz Faruk Bakman, Duygu Nur Yaldiz, Sungmin Kang, Tuo Zhang, Baturalp Buyukates, Salman Avestimehr, and Sai Praneeth Karimireddy. Reconsidering LLM uncertainty estimation methods in the wild. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational ...
-
[5]
Linguistic calibration of long-form generations
Neil Band, Xuechen Li, Tengyu Ma, and Tatsunori Hashimoto. Linguistic calibration of long-form generations. In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org, 2024
2024
-
[6]
Rewarding doubt: A reinforcement learning approach to calibrated confidence expression of large language models
David Bani-Harouni, Chantal Pellegrini, Paul Stangel, Ege \"O zsoy, Kamilia Zaripova, Matthias Keicher, and Nassir Navab. Rewarding doubt: A reinforcement learning approach to calibrated confidence expression of large language models. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=yResLmrVO1
2026
-
[7]
J. Bereket and J. Leskovec. The calibration-performance trade-off in reasoning models. arXiv preprint arXiv:2502.04112, 2025
-
[8]
Sky CH-Wang, Benjamin Van Durme, Jason Eisner, and Chris Kedzie. Do androids know they`re only dreaming of electric sheep? In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 4401--4420, Bangkok, Thailand, August 2024. Association for Computational Linguistics. doi:10.18653/v1/...
-
[9]
Uncertain natural language inference
Tongfei Chen, Zhengping Jiang, Adam Poliak, Keisuke Sakaguchi, and Benjamin Van Durme. Uncertain natural language inference. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp.\ 8772--8779, Online, July 2020. Association for Computational Lin...
-
[10]
A close look into the calibration of pre-trained language models
Yangyi Chen, Lifan Yuan, Ganqu Cui, Zhiyuan Liu, and Heng Ji. A close look into the calibration of pre-trained language models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 1343--1367, Toronto, Canada, July 2023. Associat...
-
[11]
Mind the confidence gap: Overconfidence, calibration, and distractor effects in large language models
Prateek Chhikara. Mind the confidence gap: Overconfidence, calibration, and distractor effects in large language models. Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/forum?id=lyaHnHDdZl
2025
-
[12]
Evaluating language models as risk scores
Andr \'e F Cruz, Moritz Hardt, and Celestine Mendler-D \"u nner. Evaluating language models as risk scores. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URL https://openreview.net/forum?id=qrZxL3Bto9
2024
-
[13]
arXiv preprint arXiv:2603.09309 (2026)
Yuyang Dai. Rescaling confidence: What scale design reveals about llm metacognition. arXiv preprint arXiv:2603.09309, 2026
-
[14]
Mehul Damani, Isha Puri, Stewart Slocum, Idan Shenfeld, Leshem Choshen, Yoon Kim, and Jacob Andreas. Beyond binary rewards: Training lms to reason about their uncertainty, 2025. URL https://arxiv.org/abs/2507.16806
-
[15]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review arXiv 2025
-
[16]
Calibration of pre-trained transformers
Shrey Desai and Greg Durrett. Calibration of pre-trained transformers. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 295--302, 2020
2020
-
[17]
Detecting hallucinations in large language models using semantic entropy
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy. Nature, 630 0 (8017): 0 625--630, 2024
2024
-
[18]
Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. Deep think with confidence, 2025. URL https://arxiv.org/abs/2508.15260
- [19]
-
[20]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. In International conference on machine learning, pp.\ 1321--1330. PMLR, 2017
2017
-
[21]
Language model cascades: Token-level uncertainty and beyond
Neha Gupta, Harikrishna Narasimhan, Wittawat Jitkrittum, Ankit Singh Rawat, Aditya Krishna Menon, and Sanjiv Kumar. Language model cascades: Token-level uncertainty and beyond. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=KgaBScZ4VI
2024
-
[22]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. O lympiad B ench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings...
-
[23]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. URL https://openreview.net/forum?id=7Bywt2mQsCe
2021
-
[24]
Efficient test-time scaling via self-calibration
Chengsong Huang, Langlin Huang, Jixuan Leng, Jiacheng Liu, and Jiaxin Huang. Efficient Test - Time Scaling via Self - Calibration , February 2025 a . URL http://arxiv.org/abs/2503.00031. arXiv:2503.00031 [cs]
-
[25]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Trans. Inf. Syst., 43 0 (2), January 2025 b . ISSN 1046-8188. doi:10.1145/3703155. URL https://doi....
-
[26]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement Learning via Self - Distillation , January 2026. URL http://arxiv.org/abs/2601.20802. arXiv:2601.20802 [cs] version: 1
work page internal anchor Pith review arXiv 2026
-
[27]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=chfJJYC3iL
2025
-
[28]
Calibrating zero-shot cross-lingual (un-) structured predictions
Zheng Ping Jiang, Anqi Liu, and Benjamin Van Durme. Calibrating zero-shot cross-lingual (un-) structured predictions. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp.\ 2648--2674, 2022
2022
-
[29]
Addressing the Binning Problem in Calibration Assessment through Scalar Annotations
Zhengping Jiang, Anqi Liu, and Benjamin Van Durme. Addressing the binning problem in calibration assessment through scalar annotations. Transactions of the Association for Computational Linguistics, 12: 0 120--136, 2024. doi:10.1162/tacl_a_00636. URL https://aclanthology.org/2024.tacl-1.7/
-
[30]
Conformal linguistic calibration: Trading-off between factuality and specificity
Zhengping Jiang, Anqi Liu, and Benjamin Van Durme. Conformal linguistic calibration: Trading-off between factuality and specificity. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=MWF1ZzYnxJ
2025
-
[31]
Is that your final answer? test-time scaling improves selective question answering
William Jurayj, Jeffrey Cheng, and Benjamin Van Durme. Is that your final answer? test-time scaling improves selective question answering. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp.\ 636--644, Vi...
-
[32]
Why Language Models Hallucinate
Adam Tauman Kalai, Ofir Nachum, Santosh S. Vempala, and Edwin Zhang. Why language models hallucinate. arXiv preprint arXiv:2509.04664, 2025
work page internal anchor Pith review arXiv 2025
-
[33]
Scalable best-of-n selection for large language models via self-certainty
Zhewei Kang, Xuandong Zhao, and Dawn Song. Scalable best-of-n selection for large language models via self-certainty. In 2nd AI for Math Workshop @ ICML 2025, 2025. URL https://openreview.net/forum?id=nddwJseiiy
2025
-
[34]
Large language models must be taught to know what they don't know
Sanyam Kapoor, Nate Gruver, Manley Roberts, Katherine Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, and Andrew Gordon Wilson. Large language models must be taught to know what they don't know. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS '24, Red Hook, NY, USA, 2024. Cur...
2024
-
[35]
Understanding reasoning in llms through strategic information allocation under uncertainty, 2026
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dongsheng Li, and Yuqing Yang. Understanding reasoning in llms through strategic information allocation under uncertainty, 2026. URL https://arxiv.org/abs/2603.15500
- [36]
-
[37]
Semantic entropy probes: Robust and cheap hallucination detection in LLM s, 2025
Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth A Malik, and Yarin Gal. Semantic entropy probes: Robust and cheap hallucination detection in LLM s, 2025. URL https://openreview.net/forum?id=YQvvJjLWX0
2025
-
[38]
Think with moderation: Reasoning models and confidence calibration in the climate domain
Romain Lacombe, Kerrie Wu, and Eddie Dilworth. Think with moderation: Reasoning models and confidence calibration in the climate domain. In ICML 2025 Workshop on Reliable and Responsible Foundation Models, 2025. URL https://openreview.net/forum?id=e7G5aeMOUP
2025
-
[39]
Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, Noah A
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James Validad Miranda, Alisa Liu, Nouha Dziri, Xinxi Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, Pradeep Dasigi, and Hannaneh...
2025
-
[40]
Taming overconfidence in LLM s: Reward calibration in RLHF
Jixuan Leng, Chengsong Huang, Banghua Zhu, and Jiaxin Huang. Taming overconfidence in LLM s: Reward calibration in RLHF . In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=l0tg0jzsdL
2025
-
[41]
Enhancing reasoning through process supervision with monte carlo tree search, 2025 a
Shuangtao Li, Shuaihao Dong, Kexin Luan, Xinhan Di, and Chaofan Ding. Enhancing reasoning through process supervision with monte carlo tree search, 2025 a . URL https://arxiv.org/abs/2501.01478
-
[42]
Conftuner: Training large language models to express their confidence verbally
Yibo Li, Miao Xiong, Jiaying Wu, and Bryan Hooi. Conftuner: Training large language models to express their confidence verbally. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025 b . URL https://openreview.net/forum?id=VZQ04Ojhu5
2025
-
[43]
Let's verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=v8L0pN6EOi
2024
-
[44]
C ^2 gspg: Confidence-calibrated group sequence policy gradient towards self-aware reasoning, 2025 a
Haotian Liu, Shuo Wang, and Hongteng Xu. C ^2 gspg: Confidence-calibrated group sequence policy gradient towards self-aware reasoning, 2025 a . URL https://arxiv.org/abs/2509.23129
-
[45]
C\ 2\ GSPG : Confidence-calibrated group sequence policy gradient towards self-aware reasoning, 2026
Haotian Liu, Shuo Wang, and Hongteng Xu. C\ 2\ GSPG : Confidence-calibrated group sequence policy gradient towards self-aware reasoning, 2026. URL https://openreview.net/forum?id=lgjwLQ85vm
2026
-
[46]
Logiqa: a challenge dataset for machine reading comprehension with logical reasoning
Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. Logiqa: a challenge dataset for machine reading comprehension with logical reasoning. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI'20, 2021. ISBN 9780999241165
2021
-
[47]
Shudong Liu, Zhaocong Li, Xuebo Liu, Runzhe Zhan, Derek F. Wong, Lidia S. Chao, and Min Zhang. Can LLM s learn uncertainty on their own? expressing uncertainty effectively in a self-training manner. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 2163...
-
[48]
Uncertainty quantification and confidence calibration in large language models: A survey
Xiaoou Liu, Tiejin Chen, Longchao Da, Chacha Chen, Zhen Lin, and Hua Wei. Uncertainty quantification and confidence calibration in large language models: A survey. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2, KDD '25, pp.\ 6107–6117, New York, NY, USA, 2025 b . Association for Computing Machinery. ISBN 97984...
-
[49]
Your pre-trained LLM is secretly an unsupervised confidence calibrator
Beier Luo, Shuoyuan Wang, Sharon Li, and Hongxin Wei. Your pre-trained LLM is secretly an unsupervised confidence calibrator. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025 a . URL https://openreview.net/forum?id=I4PJYZvfW5
2025
-
[50]
Improve mathematical reasoning in language models with automated process supervision, 2025 b
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Lei Meng, Jiao Sun, and Abhinav Rastogi. Improve mathematical reasoning in language models with automated process supervision, 2025 b . URL https://openreview.net/forum?id=KwPUQOQIKt
2025
-
[51]
Zhengzhao Ma, Xueru Wen, Boxi Cao, Yaojie Lu, Hongyu Lin, Jinglin Yang, Min He, Xianpei Han, and Le Sun. Decoupling reasoning and confidence: Resurrecting calibration in reinforcement learning from verifiable rewards, 2026. URL https://arxiv.org/abs/2603.09117
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
Reasoning about uncertainty: Do reasoning models know when they don’t know? In Findings of the Association for Computational Linguistics: EACL 2026, pp.\ 3408--3458, 2026
Zhiting Mei, Christina Zhang, Tenny Yin, Justin Lidard, Ola Sho, and Anirudha Majumdar. Reasoning about uncertainty: Do reasoning models know when they don’t know? In Findings of the Association for Computational Linguistics: EACL 2026, pp.\ 3408--3458, 2026
2026
-
[53]
Miranda Muqing Miao and Lyle Ungar. Closing the confidence-faithfulness gap in large language models. arXiv preprint arXiv:2603.25052, 2026
-
[54]
Ishan Jindal, Sai Prashanth Akuthota, Jayant Taneja, and SACHIN DEV SHARMA
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candes, and Tatsunori Hashimoto. s1: Simple test-time scaling. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Lang...
-
[55]
Shiyu Ni, Keping Bi, Jiafeng Guo, and Xueqi Cheng. When do LLM s need retrieval augmentation? mitigating LLM s' overconfidence helps retrieval augmentation. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Findings of the Association for Computational Linguistics: ACL 2024, pp.\ 11375--11388, Bangkok, Thailand, August 2024. Association for Computa...
-
[56]
OpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Kondri...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. Proceedings of the AAAI Conference on Artificial Intelligence, 29 0 (1), Feb. 2015. doi:10.1609/aaai.v29i1.9602. URL https://ojs.aaai.org/index.php/AAAI/article/view/9602
-
[58]
Optimizing anytime reasoning via budget relative policy optimization
Penghui Qi, Zichen Liu, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Optimizing anytime reasoning via budget relative policy optimization. In 2nd AI for Math Workshop @ ICML 2025, 2025. URL https://openreview.net/forum?id=kMGc0yvM61
2025
-
[59]
Demystifying reasoning dynamics with mutual information: Thinking tokens are information peaks in LLM reasoning
Chen Qian, Dongrui Liu, Haochen Wen, Zhen Bai, Yong Liu, and Jing Shao. Demystifying reasoning dynamics with mutual information: Thinking tokens are information peaks in LLM reasoning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=E1FrjgaG1J
2026
-
[60]
Yuxiao Qu, Matthew Y. R. Yang, Amrith Setlur, Lewis Tunstall, Edward Emanuel Beeching, Ruslan Salakhutdinov, and Aviral Kumar. Optimizing test-time compute via meta reinforcement finetuning. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=TqODUDsU4u
2025
-
[61]
Jaakkola, and Regina Barzilay
Victor Quach, Adam Fisch, Tal Schuster, Adam Yala, Jae Ho Sohn, Tommi S. Jaakkola, and Regina Barzilay. Conformal language modeling. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=pzUhfQ74c5
2024
-
[62]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA : A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=Ti67584b98
2024
-
[63]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[64]
Rewarding progress: Scaling automated process verifiers for LLM reasoning
Amrith Setlur, Chirag Nagpal, Adam Fisch, Xinyang Geng, Jacob Eisenstein, Rishabh Agarwal, Alekh Agarwal, Jonathan Berant, and Aviral Kumar. Rewarding progress: Scaling automated process verifiers for LLM reasoning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=A6Y7AqlzLW
2025
-
[65]
A tutorial on conformal prediction
Glenn Shafer and Vladimir Vovk. A tutorial on conformal prediction. J. Mach. Learn. Res., 9: 0 371–421, June 2008. ISSN 1532-4435
2008
-
[66]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/2402.03300
work page internal anchor Pith review arXiv 2024
-
[67]
Wornell, and Soumya Ghosh
Maohao Shen, Subhro Das, Kristjan Greenewald, Prasanna Sattigeri, Gregory W. Wornell, and Soumya Ghosh. Thermometer: Towards universal calibration for large language models. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp (eds.), Proceedings of the 41st International Conference o...
2024
-
[68]
Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=4FWAwZtd2n
2025
-
[69]
Joshua Strong, Qianhui Men, and J. Alison Noble. Trustworthy and practical ai for healthcare: a guided deferral system with large language models. In Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances ...
-
[70]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empiric...
-
[71]
Calibrating verbalized probabilities for large language models, 2024 a
Cheng Wang, Gyuri Szarvas, Georges Balazs, Pavel Danchenko, and Patrick Ernst. Calibrating verbalized probabilities for large language models, 2024 a . URL https://arxiv.org/abs/2410.06707
-
[72]
Always tell me the odds: Fine-grained conditional probability estimation
Liaoyaqi Wang, Zhengping Jiang, Anqi Liu, and Benjamin Van Durme. Always tell me the odds: Fine-grained conditional probability estimation. In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=xhDcG8qtw9
2025
-
[73]
Peiyi Wang, Lei Li, Zhihong Shao, R. X. Xu, Damai Dai, Yifei Li, Deli Chen, Y. Wu, and Zhifang Sui. Math- Shepherd : Verify and Reinforce LLMs Step -by-step without Human Annotations , February 2024 b . URL http://arxiv.org/abs/2312.08935. arXiv:2312.08935 [cs]
work page internal anchor Pith review arXiv 2024
-
[74]
Calibrating verbalized confidence with self-generated distractors
Victor Wang and Elias Stengel-Eskin. Calibrating verbalized confidence with self-generated distractors. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=pZs4hhemXc
2026
-
[75]
Conformal thinking: Risk control for reasoning on a compute budget, 2026
Xi Wang, Anushri Suresh, Alvin Zhang, Rishi More, William Jurayj, Benjamin Van Durme, Mehrdad Farajtabar, Daniel Khashabi, and Eric Nalisnick. Conformal thinking: Risk control for reasoning on a compute budget, 2026. URL https://arxiv.org/abs/2602.03814
-
[76]
C on U : Conformal uncertainty in large language models with correctness coverage guarantees
Zhiyuan Wang, Jinhao Duan, Lu Cheng, Yue Zhang, Qingni Wang, Xiaoshuang Shi, Kaidi Xu, Heng Tao Shen, and Xiaofeng Zhu. C on U : Conformal uncertainty in large language models with correctness coverage guarantees. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, pp.\ 6886--...
-
[77]
Thought calibration: Efficient and confident test-time scaling
Menghua Wu, Cai Zhou, Stephen Bates, and Tommi Jaakkola. Thought calibration: Efficient and confident test-time scaling. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 14302--14316, Suzhou, China, November 2025. Associati...
2025
-
[78]
Can LLM s express their uncertainty? an empirical evaluation of confidence elicitation in LLM s
Miao Xiong, Zhiyuan Hu, Xinyang Lu, YIFEI LI, Jie Fu, Junxian He, and Bryan Hooi. Can LLM s express their uncertainty? an empirical evaluation of confidence elicitation in LLM s. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=gjeQKFxFpZ
2024
-
[79]
Beyond correctness: Harmonizing process and outcome rewards through rl training
Yifan Xu et al. Beyond correctness: Harmonizing process and outcome rewards through rl training. OpenReview preprint, 2025
2025
-
[80]
Chenghao Yang, Sida Li, and Ari Holtzman. Llm probability concentration: How alignment shrinks the generative horizon. arXiv preprint arXiv:2506.17871, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.