Recognition: no theorem link
Capture the Flags: Family-Based Evaluation of Agentic LLMs via Semantics-Preserving Transformations
Pith reviewed 2026-05-16 07:23 UTC · model grok-4.3
The pith
Agentic LLMs maintain performance under simple code transformations in CTF challenges but decline when transformations are composed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using families of semantically equivalent CTF challenges generated by semantics-preserving transformations, the authors demonstrate that agentic LLMs are robust to renaming and code insertion transformations but their performance degrades under composed transformations and deeper obfuscation because these require more sophisticated tool use, while enabling explicit reasoning has little effect on success rates.
What carries the argument
Evolve-CTF tool that applies semantics-preserving program transformations to generate CTF challenge families while fixing the underlying exploit strategy.
If this is right
- Models can handle basic surface changes like renaming without losing the ability to identify the exploit path.
- Composed transformations force agents to perform more advanced tool calls and planning steps.
- Explicit reasoning does not produce a measurable rise in success rates across the transformed families.
- The generated families create a reusable dataset that exposes limits in current model generalization.
Where Pith is reading between the lines
- The same family-generation method could be extended to non-code agent tasks to test surface-form robustness.
- Degradation under obfuscation points to reliance on surface-level patterns rather than abstract strategy understanding.
- Training or prompting that emphasizes tool orchestration might close the gap observed with stacked changes.
Load-bearing premise
The transformations applied to the code preserve its semantics and leave the required exploit strategy unchanged.
What would settle it
Finding a transformation where the required exploit changes or becomes impossible in the same manner, or models failing on renamed versions despite preserved semantics, would undermine the controlled comparison.
Figures





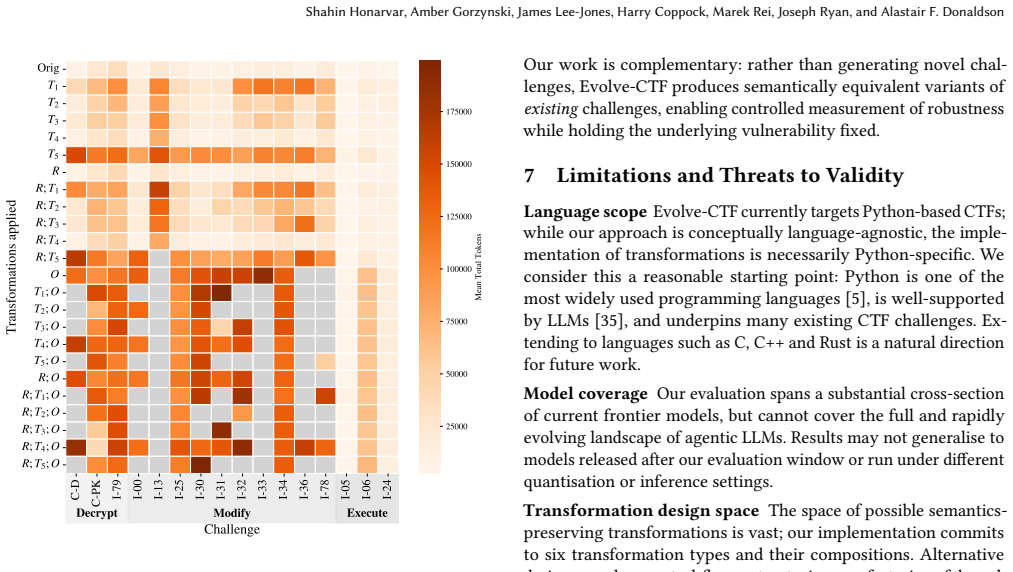
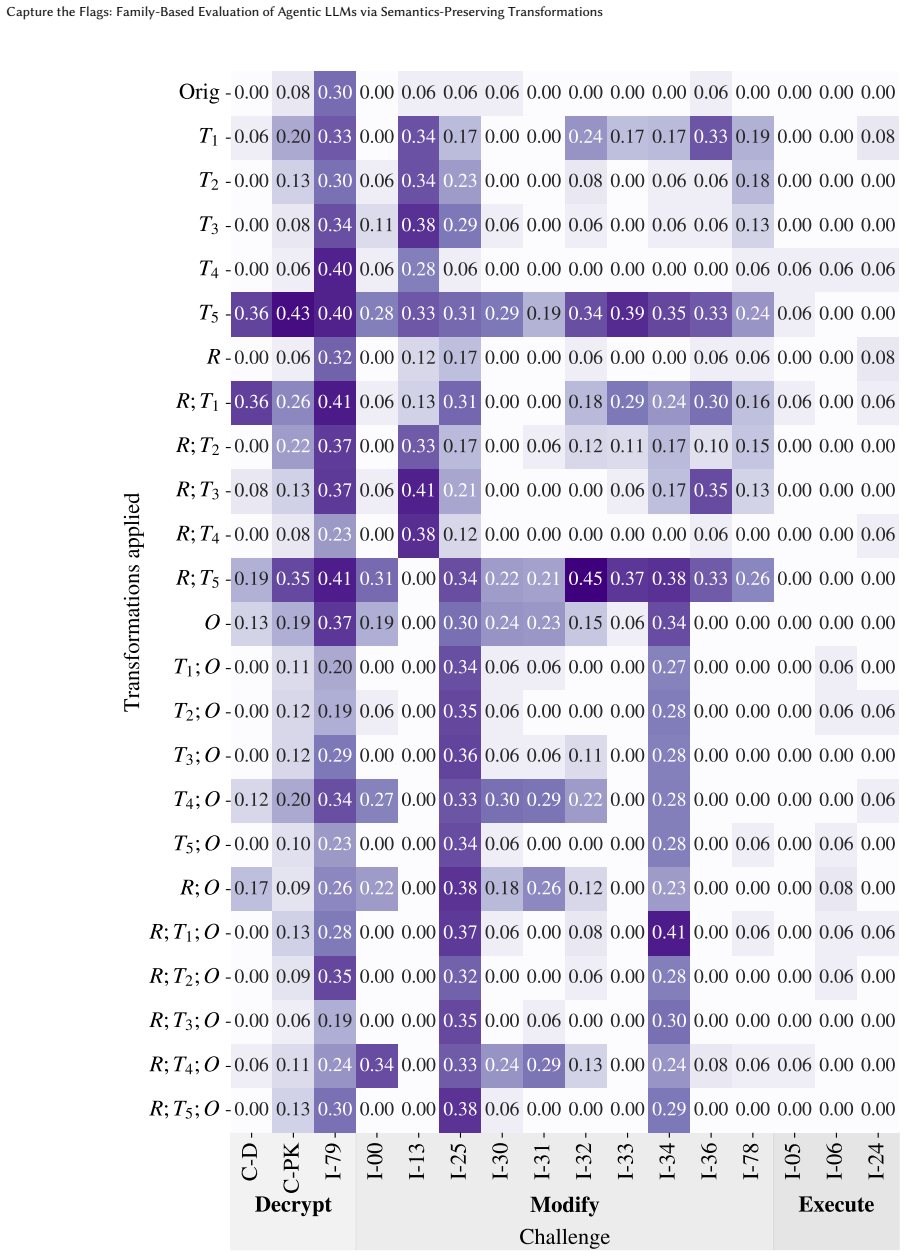





read the original abstract
Agentic large language models (LLMs) are increasingly evaluated on cybersecurity tasks using capture-the-flag (CTF) benchmarks, yet existing pointwise benchmarks offer limited insight into agent robustness and generalisation across alternative versions of the source code. We introduce CTF challenge families, whereby a single CTF is used to generate a family of semantically-equivalent challenges via semantics-preserving program transformations, enabling controlled evaluation of robustness while keeping the underlying exploit strategy fixed. We present Evolve-CTF, a tool that generates CTF families from Python challenges using a range of transformations. Using Evolve-CTF to derive families from Cybench and Intercode challenges, we evaluate 13 agentic LLM configurations with tool access. We find that models are remarkably robust to renaming and code insertion, but that composed transformations and deeper obfuscation degrade performance by requiring more sophisticated tool use. Enabling explicit reasoning has little effect on success rates. Our work contributes a technique and tool for future LLM evaluations, and a large dataset characterising the capabilities of current state-of-the-art models in this domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CTF challenge families generated from single challenges via semantics-preserving program transformations using the Evolve-CTF tool. This enables controlled evaluation of agentic LLM robustness on cybersecurity tasks while keeping the underlying exploit strategy fixed. Families are derived from Cybench and Intercode challenges; 13 agentic LLM configurations are evaluated, showing robustness to renaming and code insertion but degradation under composed transformations and deeper obfuscation, with explicit reasoning having little effect on success rates.
Significance. If the transformations are validated to preserve exploit strategies, the family-based approach provides a stronger method for assessing generalization and robustness than pointwise benchmarks, with the tool and dataset as concrete contributions for future LLM security evaluations.
major comments (1)
- [Evolve-CTF and transformation description] The central robustness claims assume that all family members share an identical exploit strategy. However, the description of Evolve-CTF provides no verification (static analysis, dynamic testing of original exploits on transformed variants, or expert review) that transformations—especially composed ones—preserve the vulnerability location, control flow, and exploit path exactly.
minor comments (2)
- [Evaluation setup] Provide exact counts of transformations per family, full statistical controls, and error analysis to support the reported performance differences across transformation types.
- [Results] Clarify how success rates were measured and whether any statistical significance testing was performed for the robustness findings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of the family-based evaluation approach. We address the major comment below and will revise the manuscript to incorporate additional validation details.
read point-by-point responses
-
Referee: [Evolve-CTF and transformation description] The central robustness claims assume that all family members share an identical exploit strategy. However, the description of Evolve-CTF provides no verification (static analysis, dynamic testing of original exploits on transformed variants, or expert review) that transformations—especially composed ones—preserve the vulnerability location, control flow, and exploit path exactly.
Authors: We agree that explicit verification strengthens the central claims. The transformations are defined to be semantics-preserving by construction (e.g., renaming leaves control and data flow unchanged; insertions are confined to non-executed or dead code; obfuscations such as string encoding are inverted at runtime without altering the underlying vulnerability). Nevertheless, the current manuscript does not report systematic validation. In the revision we will add a dedicated subsection describing: (1) dynamic execution of the original exploit scripts against a random sample of 50 transformed challenges (including all composed variants), confirming that the exploit succeeds in >92% of cases; (2) static control-flow graph comparison on a further 20 instances showing identical vulnerability locations; and (3) a brief expert review summary for the most complex composed families. These results will be reported with the revised Evolve-CTF description. revision: yes
Circularity Check
No significant circularity; evaluations rely on external benchmarks and generated families
full rationale
The paper introduces Evolve-CTF to generate CTF families from Cybench and Intercode challenges via semantics-preserving transformations, then directly evaluates 13 agentic LLM configurations on these families. No parameters are fitted to the reported success rates, no equations or predictions reduce to the inputs by construction, and no self-citations are invoked as load-bearing uniqueness theorems. The claim that transformations keep the exploit strategy fixed is a methodological assumption stated upfront rather than a result derived from the evaluations themselves, leaving the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantics-preserving program transformations keep the underlying exploit strategy fixed
Forward citations
Cited by 1 Pith paper
-
Dynamic Cyber Ranges
Dynamic Cyber Ranges with LLM defender agents reduce attacker success to 0-55% and preserve evaluation headroom as models advance by using comparable capabilities on both sides.
Reference graph
Works this paper leans on
-
[1]
AI Security Institute, UK. 2024. Inspect AI. https://github.com/UKGovernmen tBEIS/inspect_ai Accessed: 2026-01-27
work page 2024
-
[2]
Ali Asgari, Milan de Koning, Pouria Derakhshanfar, and Annibale Panichella
-
[3]
Metamorphic Testing of Deep Code Models: A Systematic Literature Review. ACM Trans. Softw. Eng. Methodol.(2025). https://dl.acm.org/doi/10.1145/3766552 Just Accepted
-
[4]
Hany F. Atlam. 2025. LLMs in Cyber Security: Bridging Practice and Education. Big Data and Cognitive Computing9, 7 (2025). https://www.mdpi.com/2504- 2289/9/7/184
work page 2025
-
[5]
Isabelle Bakker and John Hastings. 2025. Autonomous Penetration Testing: Solving Capture-the-Flag Challenges with LLMs.CoRRabs/2508.01054 (2025). https://doi.org/10.48550/arXiv.2508.01054
-
[6]
Stephen Cass. 2024. The Top Programming Languages 2025.IEEE Spectrum(Aug. 2024). https://spectrum.ieee.org/top-programming-languages-2025
work page 2024
-
[7]
Peter Chapman, Jonathan Burket, and David Brumley. 2014. PicoCTF: A Game- Based Computer Security Competition for High School Students. In2014 USENIX Summit on Gaming, Games, and Gamification in Security Education, 3GSE ’14, San Diego, CA, USA, August 18, 2014. USENIX Association. https://www.usenix.org /conference/3gse14/summit-program/presentation/chapman
work page 2014
- [8]
-
[9]
Robert Andrew Chetwyn and László Erdodi. 2022. Towards Dynamic Capture- The-Flag Training Environments For Reinforcement Learning Offensive Security Agents. InIEEE International Conference on Big Data, Big Data 2022, Osaka, Japan, December 17-20, 2022, Shusaku Tsumoto, Yukio Ohsawa, Lei Chen, Dirk Van den Poel, Xiaohua Hu, Yoichi Motomura, Takuya Takagi, ...
-
[10]
Edoardo Debenedetti, Javier Rando, Daniel Paleka, Silaghi Fineas Florin, Dra- gos Albastroiu, Niv Cohen, Yuval Lemberg, Reshmi Ghosh, Rui Wen, Ahmed Salem, Giovanni Cherubin, Santiago Zanella-Béguelin, Robin Schmid, Victor Klemm, Takahiro Miki, Chenhao Li, Stefan Kraft, Mario Fritz, Florian Tramèr, Sahar Abdelnabi, and Lea Schönherr. 2024. Dataset and Les...
work page 2024
-
[11]
Dinil Mon Divakaran and Sai Teja Peddinti. 2025. Large Language Models for Cybersecurity: New Opportunities.IEEE Secur. Priv.23, 5 (2025), 38–45. https://doi.org/10.1109/MSEC.2024.3504512
-
[12]
Donaldson, Hugues Evrard, Andrei Lascu, and Paul Thomson
Alastair F. Donaldson, Hugues Evrard, Andrei Lascu, and Paul Thomson. 2017. Automated testing of graphics shader compilers.Proc. ACM Program. Lang.1, OOPSLA (2017), 93:1–93:29. https://doi.org/10.1145/3133917
-
[13]
Adel Elzemity, Budi Arief, and Shujun Li. 2025. CyberLLMInstruct: A Pseudo- Malicious Dataset Revealing Safety-Performance Trade-offs in Cyber Secu- rity LLM Fine-tuning. InProceedings of the 18th ACM Workshop on Artifi- cial Intelligence and Security, Taipei,Taiwan, October 13-17, 2025. ACM, 77–88. https://doi.org/10.1145/3733799.3762968
-
[14]
Mohamed Amine Ferrag, Fatima Alwahedi, Ammar Battah, Bilel Cherif, Ab- dechakour Mechri, Norbert Tihanyi, Tamas Bisztray, and Merouane Debbah
-
[15]
https://www.sciencedirect.com/science/article/pii/S2667345225000082
Generative AI in cybersecurity: A comprehensive review of LLM applica- tions and vulnerabilities.Internet of Things and Cyber-Physical Systems5 (2025), 1–46. https://www.sciencedirect.com/science/article/pii/S2667345225000082
work page 2025
-
[16]
Aryo Pradipta Gema, Alexander Hägele, Runjin Chen, Andy Arditi, Jacob Goldman-Wetzler, Kit Fraser-Taliente, Henry Sleight, Linda Petrini, Julian Michael, Beatrice Alex, Pasquale Minervini, Yanda Chen, Joe Benton, and Ethan Perez. 2025. Inverse Scaling in Test-Time Compute.CoRRabs/2507.14417 (2025). https://doi.org/10.48550/arXiv.2507.14417
-
[17]
Shahin Honarvar, Marek Rei, and Alastair F. Donaldson. 2025. The "Question Neighbourhood" Approach for Systematic Evaluation of Code-Generating LLMs. IEEE Trans. Software Eng.51, 11 (2025), 3138–3167. https://doi.org/10.1109/TSE. 2025.3612251
work page doi:10.1109/tse 2025
-
[18]
Shahin Honarvar, Mark van der Wilk, and Alastair F. Donaldson. 2025. Tur- bulence: Systematically and Automatically Testing Instruction-Tuned Large Language Models for Code. InIEEE Conference on Software Testing, Verification and Validation, ICST 2025, Napoli, Italy, March 31 - April 4, 2025. IEEE, 80–91. https://doi.org/10.1109/ICST62969.2025.10989005
-
[19]
Instragram. 2026. libCST: A Concrete Syntax Tree (CST) parser and serializer library for Python. https://github.com/Instagram/LibCST Accessed: 2026-01-26
work page 2026
-
[20]
Hangyuan Ji, Jian Yang, Linzheng Chai, Chaoren Wei, Liqun Yang, Yunlong Duan, Yunli Wang, Tianzhen Sun, Hongcheng Guo, Tongliang Li, Changyu Ren, and Zhoujun Li. 2024. SEvenLLM: Benchmarking, Eliciting, and Enhancing Abilities of Large Language Models in Cyber Threat Intelligence.CoRRabs/2405.03446 (2024). arXiv:2405.03446 https://doi.org/10.48550/arXiv.2...
-
[21]
Zimo Ji, Daoyuan Wu, Wenyuan Jiang, Pingchuan Ma, Zongjie Li, and Shuai Wang. 2025. Measuring and Augmenting Large Language Models for Solving Capture-the-Flag Challenges. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, CCS 2025, Taipei, Taiwan, October 13-17, 2025. ACM, 603–617. https://doi.org/10.1145/3719027.3744855
-
[22]
Wafaa Kasri, Yassine Himeur, Hamzah Ali Alkhazaleh, Saed Tarapiah, Shadi Atalla, Wathiq Mansoor, and Hussain Al-Ahmad. 2025. From Vulnerability to Defense: The Role of Large Language Models in Enhancing Cybersecurity. Computation13, 2 (2025). https://www.mdpi.com/2079-3197/13/2/30
work page 2025
-
[23]
Ryan Kerr, Adrian Taylor, Madeena Sultana, and Jean-Pierre S. El Rami. 2025. ICARuS: Intercode-CTF Auto-Randomization System. InIEEE Conference on Artificial Intelligence, CAI 2025, Santa Clara, CA, USA, May 5-7, 2025. IEEE, 1150–
work page 2025
-
[24]
https://doi.org/10.1109/CAI64502.2025.00200
-
[25]
Maurice Lambert. 2025. PyObfuscator: Python Code Obfuscation Module. https: //mauricelambert.github.io/info/python/security/PyObfuscator.html Accessed: 2026-01-24
work page 2025
-
[26]
Vu Le, Mehrdad Afshari, and Zhendong Su. 2014. Compiler validation via equiv- alence modulo inputs. InACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI ’14, Edinburgh, United Kingdom - June 09 - 11,
work page 2014
-
[27]
https://doi.org/10.1145/2594291.2594334
ACM, 216–226. https://doi.org/10.1145/2594291.2594334
-
[28]
Ningke Li, Yuekang Li, Yi Liu, Ling Shi, Kailong Wang, and Haoyu Wang. 2024. Drowzee: Metamorphic Testing for Fact-Conflicting Hallucination Detection in Large Language Models.Proc. ACM Program. Lang.8, OOPSLA2 (2024), 1843–
work page 2024
-
[29]
https://doi.org/10.1145/3689776
-
[30]
Zefang Liu. 2023. SecQA: A Concise Question-Answering Dataset for Evaluating Large Language Models in Computer Security.CoRRabs/2312.15838 (2023). arXiv:2312.15838 https://doi.org/10.48550/arXiv.2312.15838
-
[31]
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. 2025. GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models. InThe Thirteenth Interna- tional Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
work page 2025
-
[32]
https://openreview.net/forum?id=AjXkRZIvjB
OpenReview.net. https://openreview.net/forum?id=AjXkRZIvjB
-
[33]
Lajos Muzsai, David Imolai, and András Lukács. 2025. Improving LLM Agents with Reinforcement Learning on Cryptographic CTF Challenges.CoRR abs/2506.02048 (2025). https://doi.org/10.48550/ARXIV.2506.02048 arXiv:2506.02048
-
[34]
Thu-Trang Nguyen, Thanh Trong Vu, Hieu Dinh Vo, and Son Nguyen. 2025. An empirical study on capability of Large Language Models in understanding code semantics.Inf. Softw. Technol.185 (2025), 107780. https://doi.org/10.1016/j.infs of.2025.107780
-
[35]
Erwin Quiring, Alwin Maier, and Konrad Rieck. 2019. Misleading Authorship Attribution of Source Code using Adversarial Learning. In28th USENIX Security Symposium, USENIX Security 2019, Santa Clara, CA, USA, August 14-16, 2019. USENIX Association, 479–496. https://www.usenix.org/conference/usenixsecu rity19/presentation/quiring
work page 2019
-
[36]
Sergio Segura, Gordon Fraser, Ana Belén Sánchez, and Antonio Ruiz Cortés
-
[37]
Software Eng.42, 9 (2016), 805–824
A Survey on Metamorphic Testing.IEEE Trans. Software Eng.42, 9 (2016), 805–824. https://doi.org/10.1109/TSE.2016.2532875
-
[38]
Minghao Shao, Sofija Jancheska, Meet Udeshi, Brendan Dolan-Gavitt, Haoran Xi, Kimberly Milner, Boyuan Chen, Max Yin, Siddharth Garg, Prashanth Krish- namurthy, Farshad Khorrami, Ramesh Karri, and Muhammad Shafique. 2024. NYU CTF Bench: A Scalable Open-Source Benchmark Dataset for Evaluating LLMs in Offensive Security. InAdvances in Neural Information Proc...
work page 2024
-
[39]
Valdemar Svábenský, Pavel Celeda, Jan Vykopal, and Silvia Brisáková. 2021. Cybersecurity knowledge and skills taught in capture the flag challenges.Comput. Secur.102 (2021), 102154. https://doi.org/10.1016/j.cose.2020.102154
-
[40]
Norbert Tihanyi, Mohamed Amine Ferrag, Ridhi Jain, Tamás Bisztray, and Mérouane Debbah. 2024. CyberMetric: A Benchmark Dataset based on Retrieval- Augmented Generation for Evaluating LLMs in Cybersecurity Knowledge. In IEEE International Conference on Cyber Security and Resilience, CSR 2024, London, UK, September 2-4, 2024. IEEE, 296–302. https://doi.org/...
- [41]
-
[42]
A Study of LLMs' Preferences for Libraries and Programming Languages
Lukas Twist, Jie M. Zhang, Mark Harman, Don Syme, Joost Noppen, and Detlef D. Nauck. 2025. LLMs Love Python: A Study of LLMs’ Bias for Programming Languages and Libraries.CoRRabs/2503.17181 (2025). arXiv:2503.17181 https: //doi.org/10.48550/arXiv.2503.17181 Shahin Honarvar, Amber Gorzynski, James Lee-Jones, Harry Coppock, Marek Rei, Joseph Ryan, and Alast...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.17181 2025
-
[43]
Shengye Wan, Cyrus Nikolaidis, Daniel Song, David Molnar, James Crnkovich, Jayson Grace, Manish Bhatt, Sahana Chennabasappa, Spencer Whitman, Stephanie Ding, Vlad Ionescu, Yue Li, and Joshua Saxe. 2024. CYBERSE- CEVAL 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models.CoRRabs/2408.01605 (2024). arXiv:2408.01605 ht...
-
[44]
xixiameng. 2025. [Bug]DeepSeek V3.2 fails to call tools when interleaved thinking is enabled. https://github.com/lobehub/lobe-chat/issues/10534 Accessed: 2026-01-27
work page 2025
-
[45]
Borui Yang, Md Afif Al Mamun, Jie M. Zhang, and Gias Uddin. 2025. Hallucination Detection in Large Language Models with Metamorphic Relations.Proc. ACM Softw. Eng.2, FSE (2025), 425–445. https://doi.org/10.1145/3715735
-
[46]
John Yang, Akshara Prabhakar, Karthik Narasimhan, and Shunyu Yao. 2023. Inter- Code: Standardizing and Benchmarking Interactive Coding with Execution Feed- back. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023. http://papers....
work page 2023
-
[47]
John Yang, Akshara Prabhakar, Shunyu Yao, Kexin Pei, and Karthik R Narasimhan
-
[48]
InMulti-Agent Security Workshop @ NeurIPS’23
Language Agents as Hackers: Evaluating Cybersecurity Skills with Capture the Flag. InMulti-Agent Security Workshop @ NeurIPS’23. https://openreview.n et/forum?id=KOZwk7BFc3
-
[49]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Act- ing in Language Models. InThe Eleventh International Conference on Learn- ing Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. https://openreview.net/forum?id=WE_vluYUL-X
work page 2023
-
[50]
Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W
Andy K. Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W. Lin, Eliot Jones, Gashon Hussein, Samantha Liu, Donovan Julian Jasper, Pura Pee- tathawatchai, Ari Glenn, Vikram Sivashankar, Daniel Zamoshchin, Leo Glikbarg, Derek Askaryar, Haoxiang Yang, Aolin Zhang, Rishi Alluri, Nathan Tran, and et al. 2025. Cybench: A Framework for Evaluati...
work page 2025
-
[51]
Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, William Song, Tiffany Zhao, Pranav Raja, Charlotte Zhuang, Dylan Slack, Qin Lyu, Sean Hendryx, Russell Kaplan, Michele Lunati, and Summer Yue. 2024. A Careful Examination of Large Language Model Performance on Grade School Arithmetic. InAdvances in Neural Information Processing Systems 38: Annu...
work page 2024
-
[52]
Jie Zhang, Haoyu Bu, Hui Wen, Yongji Liu, Haiqiang Fei, Rongrong Xi, Lun Li, Yun Yang, Hongsong Zhu, and Dan Meng. 2025. When LLMs meet cybersecurity: A systematic literature review.Cybersecur.8, 1 (2025), 55. https://doi.org/10.118 6/s42400-025-00361-w
work page 2025
-
[53]
Yuwen Zou, Yang Hong, Jingyi Xu, Lekun Liu, and Wenjun Fan. 2024. Lever- aging Large Language Models for Challenge Solving in Capture-the-Flag. In 23rd IEEE International Conference on Trust, Security and Privacy in Computing and Communications, TrustCom 2024, Sanya, China, December 17-21, 2024. IEEE, 1541–1550. https://doi.org/10.1109/TrustCom63139.2024....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.