Recognition: 2 theorem links
· Lean TheoremCertified Gradient-Based Contact-Rich Manipulation via Smoothing-Error Reachable Tubes
Pith reviewed 2026-05-16 06:02 UTC · model grok-4.3
The pith
Smoothing contact dynamics allows gradient-based optimization of affine feedback policies that guarantee robust constraint satisfaction on the original nonsmooth hybrid system through analytical reachable tubes for the smoothing error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The method plans with smoothed contact dynamics and geometry in a convex optimization-based differentiable simulator, represents the induced deviation from nonsmooth dynamics as a set-valued discrepancy, and incorporates this discrepancy into the optimization of time-varying affine feedback policies through analytical reachable sets, enabling robust constraint satisfaction for the closed-loop hybrid system while relying solely on the informative gradients of the smoothed model.
What carries the argument
Analytical reachable tubes of the smoothing-error discrepancy under time-varying affine feedback policies, which bound the possible trajectories of the original system.
If this is right
- Produces controllers that respect the unilateral nature of contact constraints.
- Certifies robust performance for closed-loop hybrid systems in contact-rich tasks.
- Reduces safety violations and goal errors compared to baseline methods in pushing, rotation, and dexterous manipulation.
- Relies only on gradients from the smoothed model for optimization.
Where Pith is reading between the lines
- The method could be applied to other domains with hybrid dynamics where smoothing is used for differentiability.
- Future work might extend the analytical reachable set computation to more complex contact geometries or stochastic disturbances.
- By separating the smoothing for gradients from the error bounding for guarantees, this decouples efficiency from conservatism in robotic planning.
Load-bearing premise
The mismatch between smoothed and nonsmooth dynamics can be bounded by a computable set-valued discrepancy for which reachable tubes under affine policies can be derived analytically.
What would settle it
A real-world experiment in which a trajectory of the hybrid system under the optimized policy violates a constraint outside the predicted reachable tube, or where the tube is too conservative to be useful.
Figures







read the original abstract
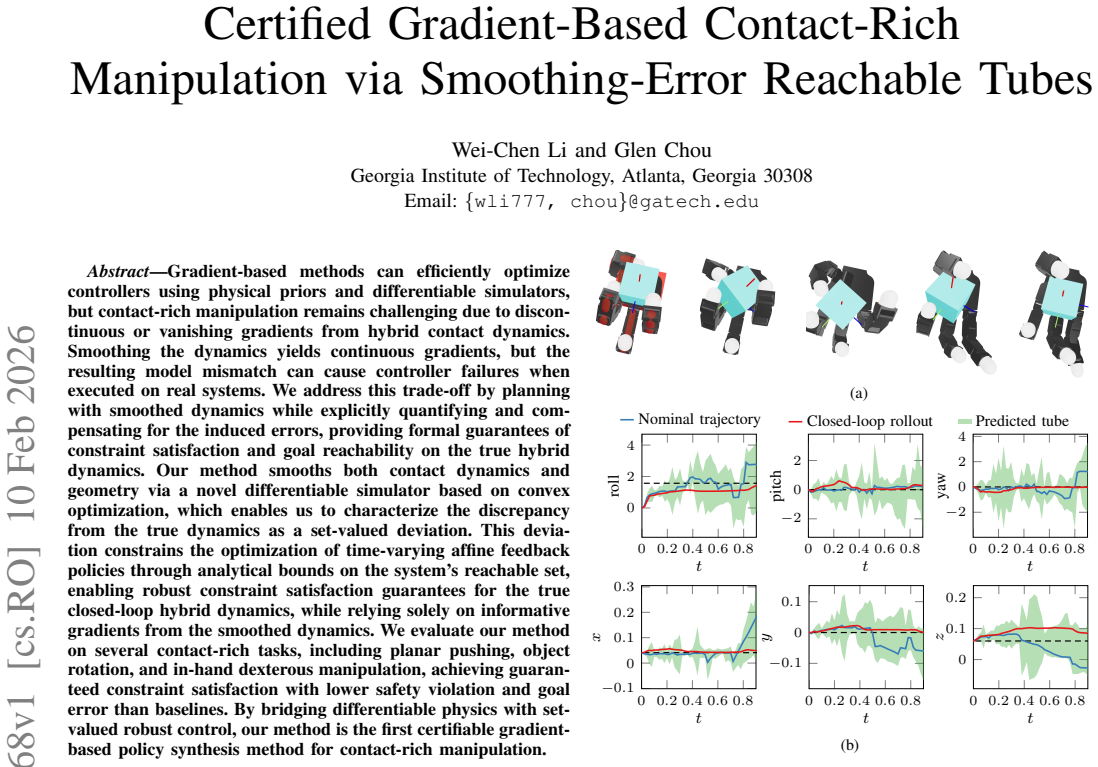
Gradient-based methods can efficiently optimize controllers by leveraging differentiable simulation and physical priors. However, contact-rich manipulation remains challenging because hybrid contact dynamics often produce discontinuous or vanishing gradients. Although smoothing the dynamics can restore informative gradients, the resulting model mismatch can cause controller failures when deployed on real systems. We address this trade-off by planning with smoothed dynamics while explicitly quantifying and compensating for the induced error, providing formal guarantees on safety and task completion under the original nonsmooth dynamics. Our approach applies smoothing to both contact dynamics and contact geometry within a differentiable simulator based on convex optimization, allowing us to characterize the deviation from the nonsmooth dynamics as a set-valued discrepancy. We incorporate this discrepancy into the optimization of time-varying affine feedback policies through analytical reachable sets, enabling robust constraint satisfaction for the closed-loop hybrid system while relying solely on the informative gradients of the smoothed model. By bridging differentiable simulation with set-valued robust control, our method produces affine feedback policies that respect the unilateral nature of contact. We evaluate our method on several contact-rich tasks, including planar pushing, object rotation, and in-hand dexterous manipulation, achieving certified constraint satisfaction with lower safety violations and smaller goal errors than baseline approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to enable certified gradient-based optimization of time-varying affine feedback policies for contact-rich manipulation by smoothing both contact dynamics and geometry in a convex-optimization-based differentiable simulator. The smoothing error is characterized as a set-valued discrepancy, which is then incorporated into policy optimization via analytical reachable sets. This yields formal guarantees of robust constraint satisfaction for the original nonsmooth hybrid system while using only the informative gradients from the smoothed model. The approach is evaluated on planar pushing, object rotation, and in-hand dexterous manipulation tasks, reporting lower safety violations and smaller goal errors than baselines.
Significance. If the analytical reachable-tube construction is shown to correctly overapproximate trajectories of the true hybrid system (including mode switches and velocity jumps), the work provides a valuable bridge between differentiable simulation and set-valued robust control. It allows safety-certified policies to be synthesized using only smoothed gradients, addressing a key limitation in contact-rich robotics. The explicit preservation of unilateral contact constraints within the affine feedback is a concrete strength that could generalize to other hybrid systems.
major comments (2)
- [§4] §4 (Reachable-set construction): the claim that the set-valued smoothing discrepancy admits closed-form reachable tubes under time-varying affine policies must explicitly address instantaneous velocity jumps at contact events; if the discrepancy set is non-convex or the affine map does not preserve invariance across switches, the tubes may fail to contain all nonsmooth trajectories, voiding the formal guarantees.
- [§5.2] §5.2 (Experimental validation): the reported certified constraint satisfaction relies on the tubes being tight enough; without tabulated overapproximation ratios or explicit comparison of tube volume versus observed violation rates on the real system, it is impossible to assess whether the guarantees are meaningful or merely conservative.
minor comments (2)
- [§3] Notation for the discrepancy set D(t) is introduced without a clear definition of its dependence on the smoothing parameter; a short appendix deriving its explicit form would improve reproducibility.
- [Figure 4] Figure 4 (reachable-tube plots): the shaded regions lack explicit axis labels for the discrepancy bounds and do not indicate the time-varying affine policy parameters used.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Reachable-set construction): the claim that the set-valued smoothing discrepancy admits closed-form reachable tubes under time-varying affine policies must explicitly address instantaneous velocity jumps at contact events; if the discrepancy set is non-convex or the affine map does not preserve invariance across switches, the tubes may fail to contain all nonsmooth trajectories, voiding the formal guarantees.
Authors: We appreciate this observation and agree that the current presentation in §4 would benefit from greater explicitness on this point. In the revision we will add a dedicated paragraph and supporting lemma showing that the set-valued discrepancy is constructed to enclose the velocity jumps at contact events (by taking the convex hull of the possible post-impact velocities consistent with the smoothing error bound). Because the feedback policy is affine, the image of this convex discrepancy set under the closed-loop map remains convex and the reachable-tube recursion preserves the over-approximation property across mode switches. The formal guarantees therefore continue to hold for the original hybrid system. We will also include a short proof sketch of the invariance step. revision: yes
-
Referee: [§5.2] §5.2 (Experimental validation): the reported certified constraint satisfaction relies on the tubes being tight enough; without tabulated overapproximation ratios or explicit comparison of tube volume versus observed violation rates on the real system, it is impossible to assess whether the guarantees are meaningful or merely conservative.
Authors: We agree that quantitative tightness metrics would strengthen the validation. In the revised §5.2 we will add a table reporting, for each task, the ratio of reachable-tube volume to the volume of the convex hull of observed trajectories, together with the empirical safety-violation rate inside the tube. Hardware experiments on the physical system are currently limited by sensor noise and actuation bandwidth; we will therefore present the comparison on high-fidelity simulation and explicitly discuss the gap to hardware as a limitation, with plans for future real-robot validation. These additions will allow readers to judge the practical tightness of the certificates. revision: partial
Circularity Check
No significant circularity; analytical reachable-tube derivation is independent of fitted outcomes
full rationale
The paper's core chain derives the set-valued smoothing discrepancy and its analytical reachable tubes directly from the convex-optimization simulator properties and set-valued robust control, then uses those tubes to constrain the policy optimization that only employs smoothed gradients. No equation reduces a prediction to a fitted parameter by construction, no load-bearing uniqueness theorem is imported via self-citation, and the formal guarantees are stated to hold for the original hybrid system without reference to experimental performance numbers. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Convex-optimization-based differentiable simulator accurately captures smoothed contact dynamics and geometry
invented entities (1)
-
Smoothing-error reachable tubes
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We smooth both contact dynamics and geometry via a novel differentiable simulator based on convex optimization... characterize the deviation... as a set-valued discrepancy... analytical reachable sets
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1... f0(x,u)=fκ(x,u)−P(x)−1∑Ji(x)⊤∂λκ,i/∂κ κ wi
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Over-Approximating Minimizer Sets of Constrained Convex Programs with Parametric Uncertainty via Reachability Analysis
A reachability-analysis method on projected gradient descent dynamics produces certified outer approximations to the minimizer sets of strongly convex programs whose costs depend on bounded uncertain parameters.
Reference graph
Works this paper leans on
-
[1]
Akshay Agrawal, Brandon Amos, Shane Barratt, Stephen Boyd, Steven Diamond, and J Zico Kolter. Differentiable convex optimization layers.Advances in Neural Informa- tion Processing Systems, 32, 2019
work page 2019
-
[2]
Differentiating through a cone program.arXiv preprint arXiv:1904.09043, 2019
Akshay Agrawal, Shane Barratt, Stephen Boyd, Enzo Busseti, and Walaa M Moursi. Differentiating through a cone program.arXiv preprint arXiv:1904.09043, 2019
-
[3]
Brandon Amos and J. Zico Kolter. OptNet: Differentiable optimization as a layer in neural networks. InProceed- ings of the 34th International Conference on Machine Learning, pages 136–145, 2017
work page 2017
-
[4]
James Anderson, John C. Doyle, Steven H. Low, and Nikolai Matni. System level synthesis.Annual Reviews in Control, 47:364–393, 2019
work page 2019
-
[5]
Mihai Anitescu. Optimization-based simulation of non- smooth rigid multibody dynamics.Mathematical Pro- gramming, 105(1):113–143, 2006
work page 2006
-
[6]
Real-time multi- contact model predictive control via ADMM
Alp Aydinoglu and Michael Posa. Real-time multi- contact model predictive control via ADMM. In2022 International Conference on Robotics and Automation (ICRA), pages 3414–3421, 2022
work page 2022
-
[7]
Alp Aydinoglu, Adam Wei, Wei-Cheng Huang, and Michael Posa. Consensus complementarity control for multicontact MPC.IEEE Transactions on Robotics, 40: 3879–3896, 2024
work page 2024
-
[8]
John T. Betts. Survey of numerical methods for trajec- tory optimization.Journal of Guidance, Control, and Dynamics, 21(2):193–207, 1998
work page 1998
-
[9]
Cambridge University Press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex Op- timization. Cambridge University Press, 2004. ISBN 9780521833783
work page 2004
-
[10]
Alejandro M. Castro, Frank N. Permenter, and Xuchen Han. An unconstrained convex formulation of compliant contact.IEEE Transactions on Robotics, 39(2):1301– 1320, 2023
work page 2023
-
[11]
Glen Chou, Necmiye Ozay, and Dmitry Berenson. Safe output feedback motion planning from images via learned perception modules and contraction theory. In International Workshop on the Algorithmic Foundations of Robotics, pages 349–367, 2023
work page 2023
-
[12]
Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem
C. Daniel Freeman, Erik Frey, Anton Raichuk, Sertan Girgin, Igor Mordatch, and Olivier Bachem. Brax–A differentiable physics engine for large scale rigid body simulation. In35th Conference on Neural Information Processing Systems, 2021
work page 2021
-
[13]
Adaptive horizon actor-critic for policy learning in contact-rich differentiable simulation
Ignat Georgiev, Krishnan Srinivasan, Jie Xu, Eric Heiden, and Animesh Garg. Adaptive horizon actor-critic for policy learning in contact-rich differentiable simulation. InProceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[14]
Paul J. Goulart and Yuwen Chen. Clarabel: An interior- point solver for conic programs with quadratic objectives. arXiv preprint arXiv.2405.12762, 2024
-
[15]
Towards tight convex relax- ations for contact-rich manipulation
Bernhard Paus Graesdal, Shao Yuan Chew Chia, Tobia Marcucci, Savva Morozov, Alexandre Amice, Pablo A Parrilo, and Russ Tedrake. Towards tight convex relax- ations for contact-rich manipulation. InProceedings of Robotics: Science and Systems (RSS), 2024
work page 2024
-
[16]
The CMA Evolution Strategy: A Tutorial
Nikolaus Hansen. The CMA evolution strategy: A tutorial.arXiv preprint arXiv:1604.00772, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Francois R Hogan and Alberto Rodriguez. Reactive planar non-prehensile manipulation with hybrid model predictive control.The International Journal of Robotics Research, 39(7):755–773, 2020
work page 2020
-
[18]
Predictive sampling: Real-time behaviour synthesis with mujoco,
Taylor Howell, Nimrod Gileadi, Saran Tunyasuvunakool, Kevin Zakka, Tom Erez, and Yuval Tassa. Predictive sampling: Real-time behaviour synthesis with MuJoCo. arXiv preprint arXiv:2212.00541, 2022
-
[19]
Howell, Simon Le Cleac’h, Jan Br ¨udigam, J
Taylor A. Howell, Simon Le Cleac’h, Jan Br ¨udigam, J. Zico Kolter, Mac Schwager, and Zachary Manchester. Dojo: A differentiable physics engine for robotics.arXiv preprint arXiv:2203.00806, 2022
-
[20]
Howell, Simon Le Cleac’h, Sumeet Singh, Pete Florence, Zachary Manchester, and Vikas Sindhwani
Taylor A. Howell, Simon Le Cleac’h, Sumeet Singh, Pete Florence, Zachary Manchester, and Vikas Sindhwani. Trajectory optimization with optimization-based dynam- ics.IEEE Robotics and Automation Letters, 7(3):6750– 6757, 2022
work page 2022
-
[21]
Julius Jankowski, Lara Bruderm ¨uller, Nick Hawes, and Sylvain Calinon. VP-STO: Via-point-based stochastic trajectory optimization for reactive robot behavior.arXiv preprint arXiv:2210.04067, 2022
-
[22]
Gijeong Kim, Dongyun Kang, Joon-Ha Kim, Seung- woo Hong, and Hae-Won Park. Contact-implicit model predictive control: Controlling diverse quadruped mo- tions without pre-planned contact modes or trajectories. The International Journal of Robotics Research, 44(3): 486–510, 2025
work page 2025
-
[23]
Craig Knuth, Glen Chou, Necmiye Ozay, and Dmitry Berenson. Planning with learned dynamics: Probabilis- tic guarantees on safety and reachability via Lipschitz constants.IEEE Robotics and Automation Letters, 6(3): 5129–5136, 2021
work page 2021
-
[24]
Craig Knuth, Glen Chou, Jamie Reese, and Joseph Moore. Statistical safety and robustness guarantees for feedback motion planning of unknown underactuated stochastic systems. In2023 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 12700– 12706, 2023
work page 2023
-
[25]
Vince Kurtz, Alejandro Castro, Aykut ¨Ozg¨un ¨Onol, and Hai Lin. Inverse dynamics trajectory optimization for contact-implicit model predictive control.The Interna- tional Journal of Robotics Research, 45(1):23–40, 2026
work page 2026
-
[26]
Simon Le Cleac’h, Mac Schwager, Zachary Manchester, Vikas Sindhwani, Pete Florence, and Sumeet Singh. Single-level differentiable contact simulation.IEEE Robotics and Automation Letters, 8(7):4012–4019, 2023
work page 2023
-
[27]
Howell, Shuo Yang, Chi- Yen Lee, John Zhang, Arun Bishop, Mac Schwager, and Zachary Manchester
Simon Le Cleac’h, Taylor A. Howell, Shuo Yang, Chi- Yen Lee, John Zhang, Arun Bishop, Mac Schwager, and Zachary Manchester. Fast contact-implicit model predictive control.IEEE Transactions on Robotics, 40: 1617–1629, 2024
work page 2024
-
[28]
Leeman, Johannes K ¨ohler, Florian Messerer, Amon Lahr, Moritz Diehl, and Melanie N
Antoine P. Leeman, Johannes K ¨ohler, Florian Messerer, Amon Lahr, Moritz Diehl, and Melanie N. Zeilinger. Fast system level synthesis: Robust model predictive control using Riccati recursions.IFAC-PapersOnLine, 58(18): 173–180, 2024
work page 2024
-
[29]
Leeman, Johannes K ¨ohler, Andrea Zanelli, Samir Bennani, and Melanie N
Antoine P. Leeman, Johannes K ¨ohler, Andrea Zanelli, Samir Bennani, and Melanie N. Zeilinger. Robust non- linear optimal control via system level synthesis.IEEE Transactions on Automatic Control, 70(7):4780–4787, 2025
work page 2025
-
[30]
Li, Preston Culbertson, Vince Kurtz, and Aaron D
Albert H. Li, Preston Culbertson, Vince Kurtz, and Aaron D. Ames. DROP: Dexterous reorientation via on- line planning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 14299–14306, 2025
work page 2025
-
[31]
D. Limon, J.M. Bravo, T. Alamo, and E.F. Camacho. Robust MPC of constrained nonlinear systems based on interval arithmetic.IEE Proceedings - Control Theory and Applications, 152:325–332, 2005
work page 2005
-
[32]
Reynolds, Michael Szmuk, Thomas Lew, Riccardo Bonalli, Marco Pavone, and Behc ¸et Ac ¸ıkmes ¸e
Danylo Malyuta, Taylor P. Reynolds, Michael Szmuk, Thomas Lew, Riccardo Bonalli, Marco Pavone, and Behc ¸et Ac ¸ıkmes ¸e. Convex optimization for trajectory generation: A tutorial on generating dynamically feasi- ble trajectories reliably and efficiently.IEEE Control Systems Magazine, 42(5):40–113, 2022
work page 2022
-
[33]
Zachary Manchester, Neel Doshi, Robert J. Wood, and Scott Kuindersma. Contact-implicit trajectory optimiza- tion using variational integrators.The International Jour- nal of Robotics Research, 38(12-13):1463–1476, 2019
work page 2019
-
[34]
Shortest paths in graphs of convex sets
Tobia Marcucci, Jack Umenberger, Pablo Parrilo, and Russ Tedrake. Shortest paths in graphs of convex sets. SIAM Journal on Optimization, 34(1):507–532, 2024
work page 2024
-
[35]
Mason.Mechanics of Robotic Manipulation
Matthew T. Mason.Mechanics of Robotic Manipulation. The MIT Press, 2001
work page 2001
-
[36]
Dif- ferentiable collision detection: A randomized smoothing approach
Louis Montaut, Quentin Le Lidec, Antoine Bambade, Vladimir Petrik, Josef Sivic, and Justin Carpentier. Dif- ferentiable collision detection: A randomized smoothing approach. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 3240–3246, 2023
work page 2023
-
[37]
PODS: Policy optimization via differentiable simulation
Miguel Angel Zamora Mora, Momchil Peychev, Sehoon Ha, Martin Vechev, and Stelian Coros. PODS: Policy optimization via differentiable simulation. InProceed- ings of the 38th International Conference on Machine Learning, pages 7805–7817, 2021
work page 2021
-
[38]
Non-prehensile planar manipulation via trajectory optimization with complementarity constraints
Jo ˜ao Moura, Theodoros Stouraitis, and Sethu Vijayaku- mar. Non-prehensile planar manipulation via trajectory optimization with complementarity constraints. In2022 International Conference on Robotics and Automation (ICRA), pages 970–976, 2022
work page 2022
-
[39]
J. Krishna Murthy, Miles Macklin, Florian Golemo, Vikram V oleti, Linda Petrini, Martin Weiss, Brean- dan Considine, J ´erˆome Parent-L ´evesque, Kevin Xie, Kenny Erleben, Liam Paull, Florian Shkurti, Derek Nowrouzezahrai, and Sanja Fidler. gradSim: Differen- tiable simulation for system identification and visuomo- tor control. InInternational Conference ...
work page 2021
-
[40]
A review of differentiable simulators.IEEE Access, 12: 97581–97604, 2024
Rhys Newbury, Jack Collins, Kerry He, Jiahe Pan, In- gmar Posner, David Howard, and Akansel Cosgun. A review of differentiable simulators.IEEE Access, 12: 97581–97604, 2024
work page 2024
-
[41]
A convex quasistatic time- stepping scheme for rigid multibody systems with contact and friction
Tao Pang and Russ Tedrake. A convex quasistatic time- stepping scheme for rigid multibody systems with contact and friction. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 6614–6620, 2021
work page 2021
-
[42]
Terry Suh, Lujie Yang, and Russ Tedrake
Tao Pang, H.J. Terry Suh, Lujie Yang, and Russ Tedrake. Global planning for contact-rich manipulation via local smoothing of quasi-dynamic contact models.IEEE Transactions on Robotics, 39(6):4691–4711, 2023
work page 2023
-
[43]
Sim-to-real transfer of robotic control with dynamics randomization
Xue Bin Peng, Marcin Andrychowicz, Wojciech Zaremba, and Pieter Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. In2018 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 3803–3810, 2018
work page 2018
-
[44]
Corrado Pezzato, Chadi Salmi, Elia Trevisan, Max Spahn, Javier Alonso-Mora, and Carlos Hern ´andez Cor- bato. Sampling-based model predictive control leverag- ing parallelizable physics simulations.IEEE Robotics and Automation Letters, 10(3):2750–2757, 2025
work page 2025
-
[45]
Efficient differentiable simulation of articu- lated bodies
Yi-Ling Qiao, Junbang Liang, Vladlen Koltun, and Ming C Lin. Efficient differentiable simulation of articu- lated bodies. InProceedings of the 38th International Conference on Machine Learning, pages 8661–8671, 2021
work page 2021
-
[46]
EPOpt: Learning robust neural network policies using model ensembles
Aravind Rajeswaran, Sarvjeet Ghotra, Balaraman Ravin- dran, and Sergey Levine. EPOpt: Learning robust neural network policies using model ensembles. InInternational Conference on Learning Representations, 2017
work page 2017
-
[47]
John Schulman, Yan Duan, Jonathan Ho, Alex Lee, Ibrahim Awwal, Henry Bradlow, Jia Pan, Sachin Patil, Ken Goldberg, and Pieter Abbeel. Motion planning with sequential convex optimization and convex colli- sion checking.The International Journal of Robotics Research, 33(9):1251–1270, 2014
work page 2014
-
[48]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Terry Suh, Huaijiang Zhu, Xinpei Ni, Jiuguang Wang, Max Simchowitz, and Tao Pang
Yuki Shirai, Tong Zhao, H.J. Terry Suh, Huaijiang Zhu, Xinpei Ni, Jiuguang Wang, Max Simchowitz, and Tao Pang. Is linear feedback on smoothed dynamics sufficient for stabilizing contact-rich plans? In2025 IEEE Interna- tional Conference on Robotics and Automation (ICRA), page 11926–11932, 2025
work page 2025
-
[50]
D. C. Sorensen. Newton’s method with a model trust re- gion modification.SIAM Journal on Numerical Analysis, 19(2):409–426, 1982
work page 1982
-
[51]
H. J. Terry Suh, Tao Pang, Tong Zhao, and Russ Tedrake. Dexterous contact-rich manipulation via the contact trust region.The International Journal of Robotics Research, 2026
work page 2026
-
[52]
Terry Suh, Tao Pang, and Russ Tedrake
H.J. Terry Suh, Tao Pang, and Russ Tedrake. Bundled gradients through contact via randomized smoothing. IEEE Robotics and Automation Letters, 7(2):4000–4007,
-
[53]
doi: 10.1109/LRA.2022.3146931
-
[54]
Terry Suh, Max Simchowitz, Kaiqing Zhang, and Russ Tedrake
H.J. Terry Suh, Max Simchowitz, Kaiqing Zhang, and Russ Tedrake. Do differentiable simulators give better policy gradients? InProceedings of the 39th Interna- tional Conference on Machine Learning, pages 20668– 20696, 2022
work page 2022
-
[55]
Sutton, David McAllester, Satinder Singh, and Yishay Mansour
Richard S. Sutton, David McAllester, Satinder Singh, and Yishay Mansour. Policy gradient methods for reinforce- ment learning with function approximation. InAdvances in Neural Information Processing Systems, volume 12, 1999
work page 1999
-
[56]
Lieven Vandenberghe.The CVXOPT linear and quadratic cone program solvers, 2010
work page 2010
- [57]
-
[58]
Accelerated policy learning with parallel dif- ferentiable simulation
Jie Xu, Viktor Makoviychuk, Yashraj Narang, Fabio Ramos, Wojciech Matusik, Animesh Garg, and Miles Macklin. Accelerated policy learning with parallel dif- ferentiable simulation. InInternational Conference on Learning Representations, 2022
work page 2022
-
[59]
Adaptive barrier smoothing for first-order policy gradient with con- tact dynamics
Shenao Zhang, Wanxin Jin, and Zhaoran Wang. Adaptive barrier smoothing for first-order policy gradient with con- tact dynamics. InProceedings of the 40th International Conference on Machine Learning, pages 41219–41243, 2023. APPENDIXA IMPLICITDIFFERENTIATION OFCONICPROGRAMS The gradient of the solution of problem (1) or (3) with respect to problem dataθca...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.