Recognition: no theorem link
ScreenParse: Moving Beyond Sparse Grounding with Complete Screen Parsing Supervision
Pith reviewed 2026-05-15 21:31 UTC · model grok-4.3
The pith
Dense annotations of every UI element in 771K screenshots let a 316M VLM beat larger models on screen parsing and improve grounding after finetuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
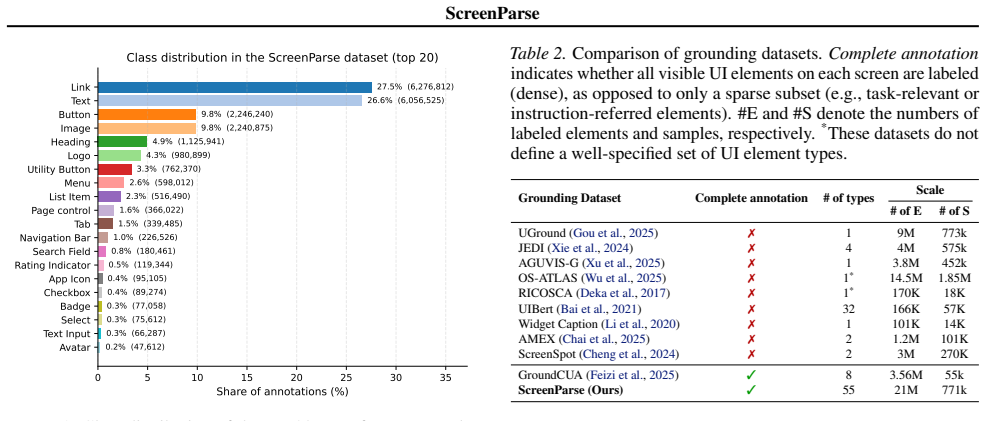
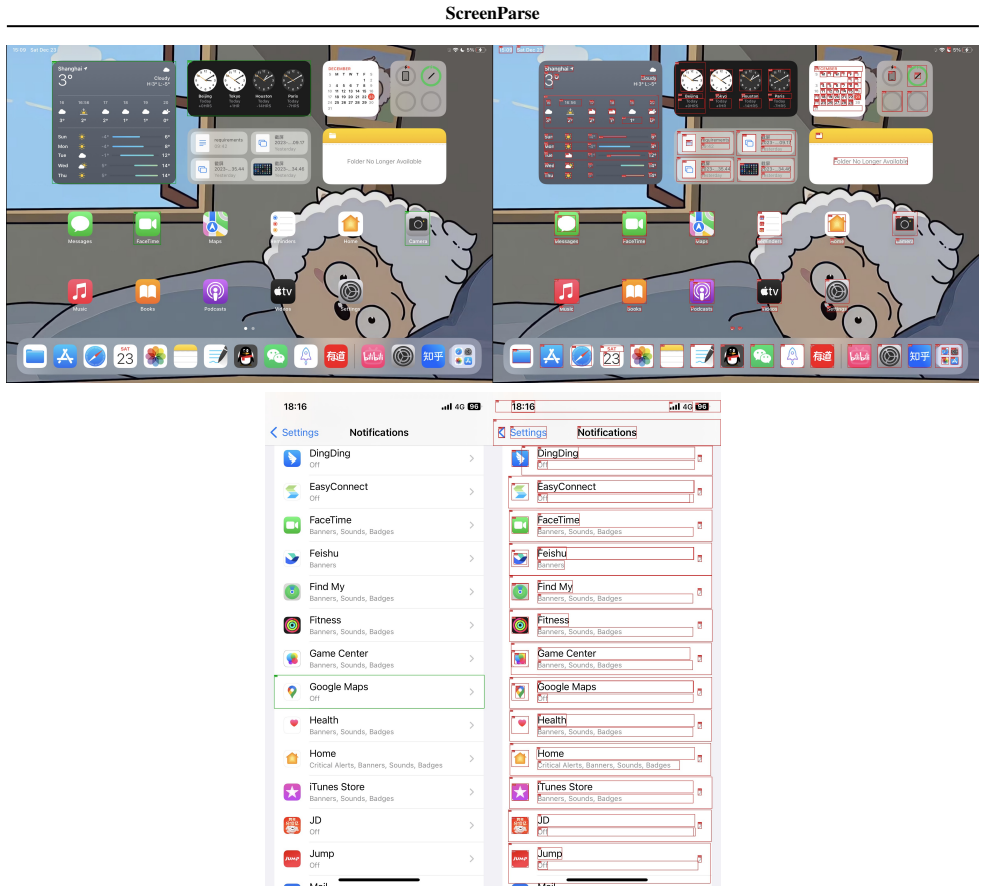
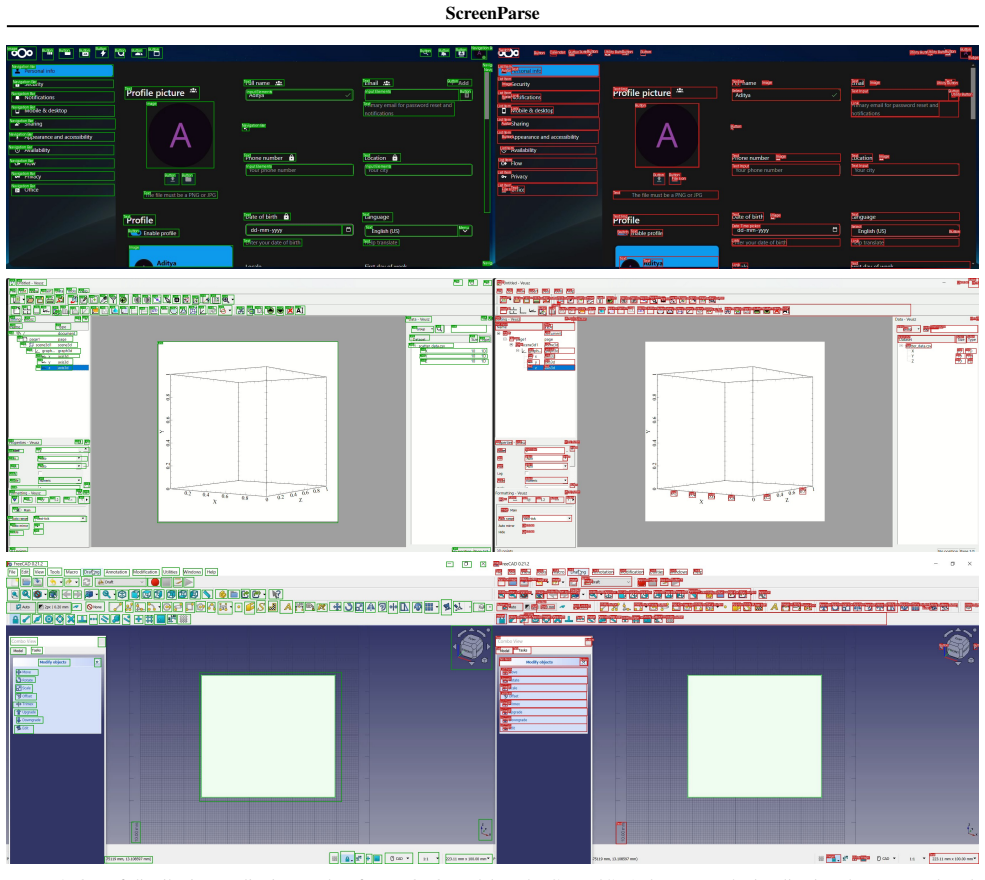
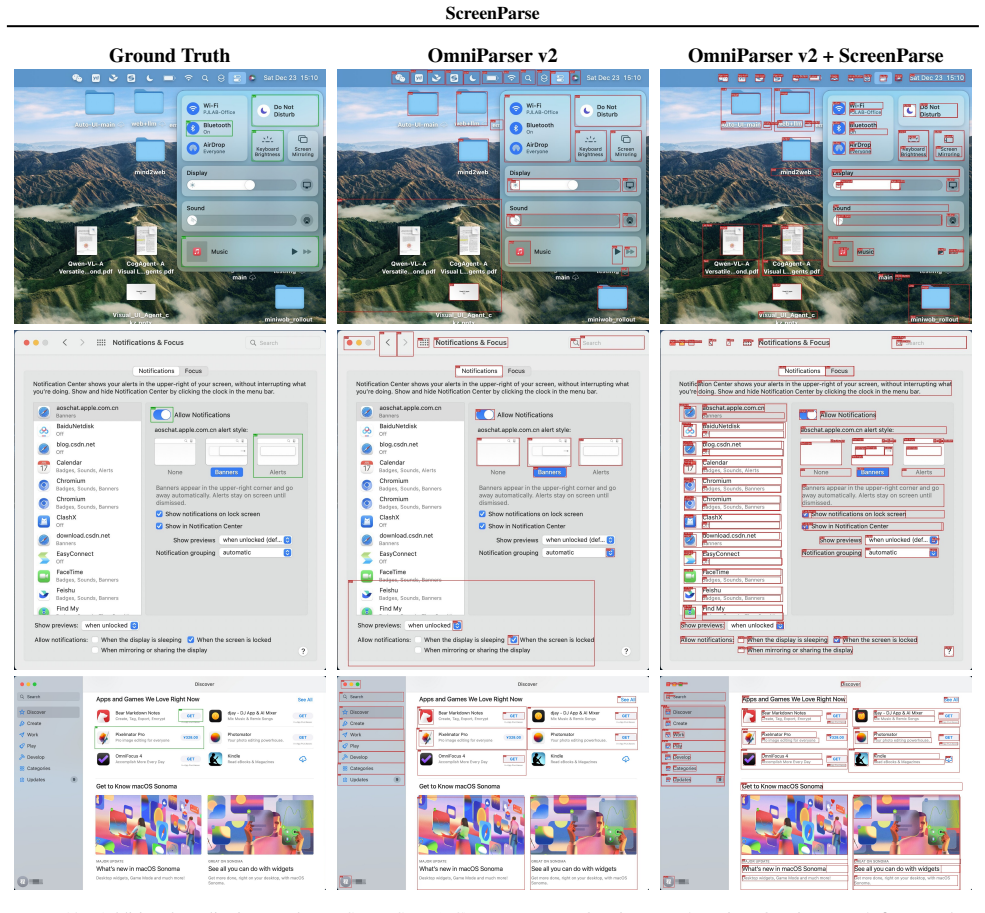
ScreenParse supplies complete, dense supervision of all visible UI elements including boxes, 55-class types and text in 771K screenshots. Training ScreenVLM on it with a compact ScreenTag representation and structure-aware loss yields 0.592 PageIoU, substantially above the 0.294 of larger foundation VLMs, with strong transfer and consistent gains when used for finetuning.
What carries the argument
The ScreenParse dataset of dense UI annotations generated by the Webshot pipeline, together with the ScreenVLM model that decodes a compact ScreenTag markup representation under a structure-aware loss.
If this is right
- ScreenVLM reaches higher dense parsing accuracy than much larger foundation VLMs on the ScreenParse benchmark.
- Finetuning foundation VLMs on ScreenParse data consistently improves their performance on grounding tasks.
- The trained model transfers effectively to existing public UI benchmarks.
- Compact structured decoding supports low-latency on-device deployment for computer-use agents.
Where Pith is reading between the lines
- If the pipeline generalizes, similar dense supervision could be extended to mobile or desktop interfaces beyond web pages.
- Explicit structure-aware losses may reduce the parameter count needed for reliable agent perception.
- Complete element coverage could support more robust multi-step instruction following in complex screens.
Load-bearing premise
The Webshot pipeline's VLM-based relabeling and quality filtering produces accurate, unbiased, and complete annotations for all visible elements across diverse web screenshots without systematic errors or coverage gaps.
What would settle it
A manual audit of randomly sampled screens from ScreenParse that reveals many visible UI elements missing annotations, assigned wrong classes, or given incorrect text would falsify the claim of reliable complete supervision.
Figures











read the original abstract
Modern computer-use agents (CUA) must perceive a screen as a structured state, what elements are visible, where they are, and what text they contain, before they can reliably ground instructions and act. Yet, most available grounding datasets provide sparse supervision, with insufficient and low-diversity labels that annotate only a small subset of task-relevant elements per screen, which limits both coverage and generalization; moreover, practical deployment requires efficiency to enable low-latency, on-device use. We introduce ScreenParse, a large-scale dataset for complete screen parsing, with dense annotations of all visible UI elements (boxes, 55-class types, and text) across 771K web screenshots (21M elements). ScreenParse is generated by Webshot, an automated, scalable pipeline that renders diverse urls, extracts annotations and applies VLM-based relabeling and quality filtering. Using ScreenParse, we train ScreenVLM, a compact, 316M-parameter vision language model (VLM) that decodes a compact ScreenTag markup representation with a structure-aware loss that upweights structure-critical tokens. ScreenVLM substantially outperforms much larger foundation VLMs on dense parsing (e.g., 0.592 vs. 0.294 PageIoU on ScreenParse) and shows strong transfer to public benchmarks. Moreover, finetuning foundation VLMs on ScreenParse consistently improves their grounding performance, suggesting that dense screen supervision provides transferable structural priors for UI understanding. Project page: https://saidgurbuz.github.io/screenparse/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ScreenParse, a large-scale dataset of 771K web screenshots with dense annotations of all visible UI elements (bounding boxes, 55-class types, and text) generated via the automated Webshot pipeline of URL rendering followed by VLM-based relabeling and quality filtering. It trains ScreenVLM, a compact 316M-parameter VLM that decodes a ScreenTag markup representation under a structure-aware loss, and reports that this model substantially outperforms much larger foundation VLMs on dense parsing (e.g., 0.592 vs. 0.294 PageIoU on ScreenParse), transfers to public benchmarks, and that finetuning foundation VLMs on ScreenParse improves their grounding performance.
Significance. If the automated labels are shown to be accurate and unbiased, the work supplies a valuable source of complete, dense supervision for UI parsing that sparse grounding datasets lack, with potential to improve computer-use agents through transferable structural priors. The empirical scale (21M elements) and the reported transfer/finetuning results would constitute a concrete advance in data-driven screen understanding.
major comments (2)
- [Dataset construction (Webshot pipeline) and Abstract] The headline PageIoU gains (0.592 vs. 0.294 on ScreenParse) and all transfer/finetuning claims rest on the quality of the ScreenParse labels. The Webshot pipeline description indicates that annotations are produced by VLM relabeling and filtering with no reported human-annotated validation subset, inter-annotator agreement, or systematic error analysis; because train and test splits derive from the identical pipeline, any consistent labeling artifacts (e.g., missed occluded elements, type misclassifications, or OCR drift) would be learned and rewarded at evaluation time.
- [Evaluation section and Abstract] No definition or implementation details are supplied for the primary metric PageIoU, nor for the baseline foundation VLM setups (model sizes, prompting, decoding strategies). Without these, the numerical comparisons cannot be reproduced or stress-tested for robustness.
minor comments (2)
- [Model and training description] The abstract states that the structure-aware loss 'upweights structure-critical tokens' but does not specify the token weighting scheme, how the weights were chosen, or ablation results showing their contribution.
- [Transfer experiments] The public benchmarks used for transfer are not enumerated, nor are the exact metrics and baseline numbers reported for those benchmarks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to validate automated labels and ensure evaluation reproducibility. We address both major comments point-by-point below and will incorporate the requested clarifications and analyses into the revised manuscript.
read point-by-point responses
-
Referee: The headline PageIoU gains (0.592 vs. 0.294 on ScreenParse) and all transfer/finetuning claims rest on the quality of the ScreenParse labels. The Webshot pipeline description indicates that annotations are produced by VLM relabeling and filtering with no reported human-annotated validation subset, inter-annotator agreement, or systematic error analysis; because train and test splits derive from the identical pipeline, any consistent labeling artifacts (e.g., missed occluded elements, type misclassifications, or OCR drift) would be learned and rewarded at evaluation time.
Authors: We agree that explicit validation of the automated labels is essential to support the reported gains. The Webshot pipeline uses VLM-based relabeling and filtering on a large scale, but the submitted manuscript does not include a human-annotated validation subset, inter-annotator agreement, or detailed error analysis. In the revision we will add a human study on a random sample of 500 test screens, reporting element-wise agreement for bounding boxes (IoU), type classification accuracy, and text OCR fidelity, together with inter-annotator agreement and a categorized error analysis (occlusions, misclassifications, OCR drift). We will also discuss how the observed transfer to human-annotated public benchmarks provides evidence against overfitting to pipeline-specific artifacts. revision: yes
-
Referee: No definition or implementation details are supplied for the primary metric PageIoU, nor for the baseline foundation VLM setups (model sizes, prompting, decoding strategies). Without these, the numerical comparisons cannot be reproduced or stress-tested for robustness.
Authors: We apologize for the omission. PageIoU is defined as the average per-element IoU computed over the complete set of parsed UI elements on each screenshot (i.e., page-level aggregation of bounding-box overlap, type, and text matches). We will insert the exact mathematical definition, pseudocode, and all baseline implementation details—including model sizes, full prompting templates, and decoding hyperparameters (temperature, max tokens, beam size)—into the evaluation section and supplementary material of the revised manuscript. revision: yes
Circularity Check
No circularity: empirical dataset generation and external-benchmark evaluation
full rationale
The paper is entirely empirical and data-driven. It describes an automated Webshot pipeline to produce ScreenParse (rendering + VLM relabeling + filtering), trains ScreenVLM on that data, and reports measured PageIoU and transfer numbers against independent foundation VLMs on both ScreenParse and public benchmarks. No equations, fitted parameters, or self-citations appear in the provided text that reduce any claimed improvement to a quantity defined by the authors' own choices. The derivation chain therefore contains no self-definitional, fitted-input, or self-citation reductions.
Axiom & Free-Parameter Ledger
free parameters (1)
- structure-aware loss token weights
axioms (1)
- domain assumption VLM-based relabeling and filtering yields high-quality dense annotations without systematic bias
invented entities (2)
-
ScreenTag markup representation
no independent evidence
-
ScreenVLM
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Entropy-Gradient Grounding: Training-Free Evidence Retrieval in Vision-Language Models
Entropy-gradient grounding uses model uncertainty to retrieve evidence regions in VLMs, improving performance on detail-critical and compositional tasks across multiple architectures.
-
Securing Computer-Use Agents: A Unified Architecture-Lifecycle Framework for Deployment-Grounded Reliability
The paper develops a unified framework that organizes computer-use agent reliability around perception-decision-execution layers and creation-deployment-operation-maintenance stages to map security and alignment inter...
Reference graph
Works this paper leans on
-
[1]
doi: 10.24963/ijcai.2021/235. URL https: //doi.org/10.24963/ijcai.2021/235. Main Track. Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y ., Liu, D., Liu, S...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.24963/ijcai.2021/235 2021
-
[2]
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/2025.findings-acl
-
[3]
URL https://aclanthology.org/2025. findings-acl.110/. Cheng, K., Sun, Q., Chu, Y ., Xu, F., YanTao, L., Zhang, J., and Wu, Z. SeeClick: Harnessing GUI grounding for ad- vanced visual GUI agents. In Ku, L.-W., Martins, A., and Srikumar, V . (eds.),Proceedings of the 62nd Annual Meet- ing of the Association for Computational Linguistics (Vol- ume 1: Long Pa...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.505 2025
-
[4]
YOLOv11: An Overview of the Key Architectural Enhancements
URL https://aclanthology.org/2024. acl-long.371/. Khanam, R. and Hussain, M. Yolov11: An overview of the key architectural enhancements, 2024. URL https: //arxiv.org/abs/2410.17725. Kim, C., Shin, H., Hong, E., Yoon, H., Arnab, A., Seo, P. H., Hong, S., and Kim, S. Seg4diff: Unveiling open- vocabulary segmentation in text-to-image diffusion trans- formers...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.50 2024
-
[5]
URL https://api.semanticscholar. org/CorpusID:271947166. Li, K., ziyang, M., Lin, H., Luo, Z., Tian, Y ., Ma, J., Huang, Z., and Chua, T.-S. Screenspot-pro: GUI grounding for professional high-resolution computer use. InWorkshop on Reasoning and Planning for Large Language Models,
-
[6]
Li, Y ., Li, G., He, L., Zheng, J., Li, H., and Guan, Z
URL https://openreview.net/forum? id=XaKNDIAHas. Li, Y ., Li, G., He, L., Zheng, J., Li, H., and Guan, Z. Wid- get captioning: Generating natural language description for mobile user interface elements. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 5495–5510, 2020. Lu, Y ., Yang, J., Shen, Y ., and A...
-
[7]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
URL https://openreview.net/forum? id=oKn9c6ytLx. Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y ., Su, W., Shao, J., et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 11 ScreenParse Table 8.ScreenTag screen parsing classes (55 total) used in...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Appendix 7.1. Screen Parsing Label Set (ScreenTag) Tab. 8 lists the 55 semantic classes used for screen parsing in our ScreenTag annotation schema. 7.2. Training Details Qwen3-VL-2B-Instruct Finetuning.We fine-tune Qwen3-VL-2B-Instruct on ScreenParse with BF16 and DeepSpeed ZeRO-3 offload, updating only the multimodal LLM (vision tower and projector froze...
-
[9]
COVERAGE / MISSING ELEMENTS (0-100) - Look for visually obvious, distinct UI elements that **should** be annotated: - buttons, main text blocks, headings, input fields, icons, major images, cards, menu items, etc. - Large and important items that should be covered: - main hero images, large central text, clearly clickable buttons or tabs, prominent fields...
-
[10]
FALSE POSITIVES / SPURIOUS BOXES (0-100) - Penalize boxes that are not aligned with any visible UI element, such as: - Boxes in completely blank areas. - Boxes that repeat the same position but shifted somewhere else on the screen where nothing exists. - Boxes over pure background images or whitespace where there is no clear object or control. - Do NOT tr...
-
[11]
Text" box entirely inside another
DUPLICATION / REDUNDANCY (0-100) Focus especially on SAME-CLASS duplications: - For NON-NESTABLE classes (for example: Text, Heading, Button, Checkbox, Radiobox, Switch, Slider, Text Input, Search Field, Image, Logo, Icon, etc.): - Two boxes of the same class that heavily overlap OR where one box is completely inside another usually indicate a problem. - ...
-
[12]
Text" labels stacked over the same text string, or multiple overlapping
LOCALIZATION / ALIGNMENT (0-100) - Evaluate how well each bounding box fits its intended UI element. - Good annotation: - The box tightly covers the element, with small margins. - It does not cut off major parts of the element. - Penalize: 24 ScreenParse - Boxes that are much larger than the element and include large amounts of unrelated background. - Box...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.