Recognition: no theorem link
Securing Computer-Use Agents: A Unified Architecture-Lifecycle Framework for Deployment-Grounded Reliability
Pith reviewed 2026-05-11 01:12 UTC · model grok-4.3
The pith
A unified architecture-lifecycle framework secures computer-use agents by grounding reliability in deployment realities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
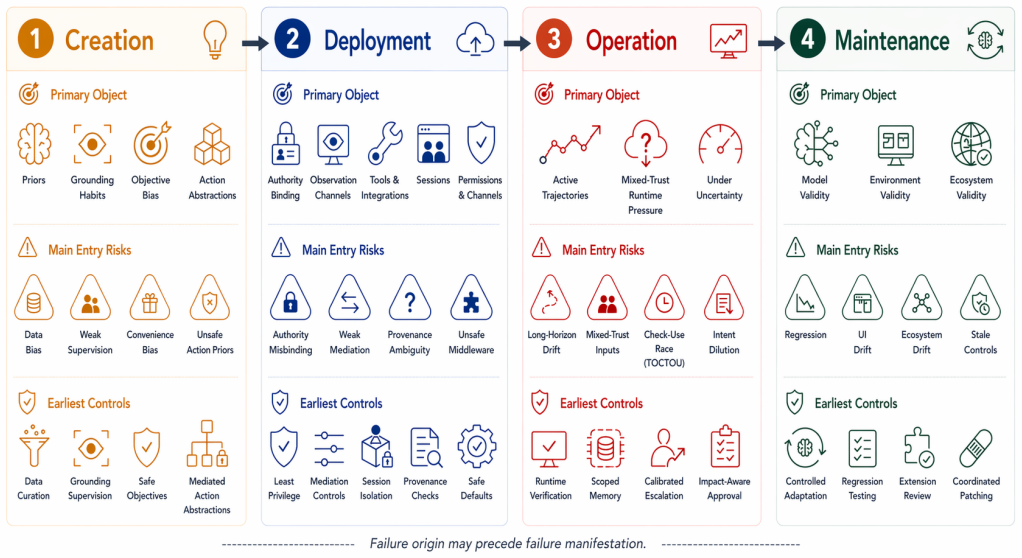
The article develops an architecture-lifecycle framework for deployment-grounded reliability in computer-use agents. The architectural view analyzes Perception, Decision, and Execution as coupled layers that transform software observations into authority-bearing actions. The lifecycle view examines Creation, Deployment, Operation, and Maintenance as stages in which priors are learned, tools and permissions are bound, runtime trajectories are stressed, and assurance must be preserved under drift. Using this lens, the analysis synthesizes representative systems, benchmarks, and security studies to distinguish where failures become visible from where enabling conditions are introduced and to 1.
What carries the argument
The architecture-lifecycle framework that couples three layers (Perception, Decision, Execution) transforming observations into actions with four stages (Creation, Deployment, Operation, Maintenance) where conditions are set and assurance maintained.
If this is right
- Control oversight can target specific intervention surfaces identified across layers and stages.
- Assurance preservation under drift becomes possible through maintenance stage analysis.
- Open challenges like controllable grounding and safe authority binding are highlighted for future work.
- Privacy-preserving memory and mixed-trust runtime defense emerge as key needs.
Where Pith is reading between the lines
- Developers could use the framework to audit new computer-use agents for hidden permission risks before deployment.
- The approach might extend to creating benchmarks that evaluate agents across full lifecycles rather than isolated tasks.
- Similar layered views could apply to other autonomous systems beyond software agents, such as robotic controllers.
Load-bearing premise
That reviewing and synthesizing existing systems, benchmarks, and studies through these specific layers and stages will clearly separate visible failures from their enabling conditions without needing original experiments to validate the framework.
What would settle it
Applying the framework to a collection of current computer-use agent systems and finding that it fails to reveal any additional intervention surfaces or control points beyond what prior surveys already noted would show the framework adds no new distinguishing power.
Figures


read the original abstract
Computer-use agents(CUAs)are moving frombounded benchmarks toward real software environments, wherethey operate browsers, desktops, mobile applications, flesystems,terminals, and tool backends. In such settings, reliability isno longer captured by task success alone: perception errors,planning drift, memory use, tool mediation, permission scope,and runtime oversight jointly determine whether agent actionsremain aligned with user intent, Existing surveys organize theCUA landscape by methods, platforms, benchmarks, or securitythreats, but less explicitly connect capability formation, author-ity exposure, failure manifestation, and control placement. Toaddress this gap, the article develops an architecture-lifecycleframework for deployment-grounded reliability in CUAs. Thearchitectural view analyzes Perception, Decision, and Executionas coupled layers that transform software observations intoauthority-bearing actions, The lifecycle view examines Creation.Deployment, Operation, and Maintenance as stages in which priorsare learned, tools and permissions are bound, runtime trajecto.ries are stressed, and assurance must be preserved under drift.Using this lens, the analysis synthesizes representative systems,benchmarks, and security/privacy studies; distinguishes wherefailures become visible from where their enabling conditions areintroduced, and maps recurring intervention surfaces for controloversight, and assurance. OpenClaw is used only as a public moti.vating example of an open deployment pattern, not as a verifedinternal case study. The conclusion highlights open challengesin controllable grounding, long-horizon constraint preservation,safe authority binding, mixed-trust runtime defense, privacy-preserving memory,and continual assurance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop a unified architecture-lifecycle framework for deployment-grounded reliability in computer-use agents (CUAs). The architectural view decomposes agents into coupled Perception, Decision, and Execution layers that convert observations into authority-bearing actions. The lifecycle view organizes the process into Creation, Deployment, Operation, and Maintenance stages where priors are acquired, tools/permissions bound, trajectories stressed, and assurance maintained under drift. Applying this lens to existing systems, benchmarks, and security studies, the work distinguishes locations where failures become visible from where enabling conditions are introduced and identifies recurring intervention surfaces for oversight. OpenClaw serves only as a public motivating example of an open deployment pattern.
Significance. If the framework provides a coherent organizational lens that reveals non-obvious mappings between architectural layers, lifecycle stages, and control surfaces, it could aid researchers and practitioners in systematically addressing reliability and security gaps in real-world CUA deployments beyond task-success metrics. The explicit connection of capability formation to authority exposure and failure manifestation is a potentially useful synthesis, though its value hinges on whether the distinctions prove actionable in subsequent empirical work.
major comments (2)
- [Abstract / synthesis of representative systems] Abstract and synthesis description: The central claim that the architecture-lifecycle lens 'distinguishes where failures become visible from where their enabling conditions are introduced' and thereby 'maps recurring intervention surfaces' rests entirely on qualitative re-categorization of prior literature. No formal categorization protocol, inter-annotator agreement, or controlled comparison against existing survey taxonomies is provided to establish that the distinctions are novel or practically enabling.
- [Lifecycle view] Lifecycle view description: The mapping of stages (Creation through Maintenance) to specific reliability mechanisms (prior learning, permission binding, drift handling) is asserted conceptually, but the manuscript supplies no concrete, traceable examples from the cited benchmarks or security studies demonstrating how this mapping uncovers intervention surfaces that prior analyses missed.
minor comments (2)
- [Abstract] The abstract contains multiple typographical and formatting issues, including 'flesystems' (should be 'filesystems'), missing spaces after commas, 'Creation.Deployment' (period instead of comma), and hyphenated 'author-ity'.
- [Introduction / motivating example] The precise scope and depth of the OpenClaw example should be stated explicitly in the main text to avoid any implication that it constitutes an internal case study.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, providing clarifications on the scope of our qualitative framework and committing to revisions that strengthen the presentation of mappings and examples.
read point-by-point responses
-
Referee: [Abstract / synthesis of representative systems] Abstract and synthesis description: The central claim that the architecture-lifecycle lens 'distinguishes where failures become visible from where their enabling conditions are introduced' and thereby 'maps recurring intervention surfaces' rests entirely on qualitative re-categorization of prior literature. No formal categorization protocol, inter-annotator agreement, or controlled comparison against existing survey taxonomies is provided to establish that the distinctions are novel or practically enabling.
Authors: We agree that the synthesis is qualitative and does not employ a formal categorization protocol, inter-annotator agreement, or controlled comparison to existing taxonomies. The framework is offered as a conceptual organizational lens to connect architectural layers, lifecycle stages, and control surfaces, rather than as an empirically derived taxonomy. The distinctions emerge from re-examining cited systems, benchmarks, and security studies through this coupled structure, which prior surveys have not organized in this way. We will revise the abstract, introduction, and synthesis section to explicitly characterize the approach as qualitative and include a summary table of layer-stage-intervention mappings to improve transparency and actionability. revision: partial
-
Referee: [Lifecycle view] Lifecycle view description: The mapping of stages (Creation through Maintenance) to specific reliability mechanisms (prior learning, permission binding, drift handling) is asserted conceptually, but the manuscript supplies no concrete, traceable examples from the cited benchmarks or security studies demonstrating how this mapping uncovers intervention surfaces that prior analyses missed.
Authors: The referee is correct that while the manuscript applies the lens to representative works, more explicit tracing of individual examples would better demonstrate novel distinctions. The synthesis section currently references studies on perception errors, tool mediation, and runtime oversight, but does not always isolate how a specific enabling condition in one stage manifests in another. In revision we will add a new subsection with 2-3 traceable examples (e.g., linking a cited agent security study on permission overreach in Deployment to observable failures in Operation) to show intervention surfaces that were not foregrounded in the original analyses. revision: yes
Circularity Check
No circularity: conceptual framework is a non-derivational synthesis
full rationale
The manuscript proposes an architecture-lifecycle framework consisting of Perception-Decision-Execution layers and Creation-Deployment-Operation-Maintenance stages. It applies this lens to synthesize representative systems, benchmarks, and studies from prior literature, distinguishing failure visibility from enabling conditions via author-led categorization. No equations, derivations, fitted parameters, predictions, uniqueness theorems, or self-citations appear in the text. OpenClaw is explicitly limited to a public motivating example. The central claim is an interpretive organizational lens rather than a reduction of any result to its inputs by construction, rendering the derivation chain self-contained with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Perception, Decision, and Execution function as coupled layers that transform software observations into authority-bearing actions.
- domain assumption Reliability and security issues arise and can be addressed across Creation, Deployment, Operation, and Maintenance stages.
Reference graph
Works this paper leans on
-
[1]
Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, et al. Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
-
[2]
Gonzalo Gonzalez-Pumariega, Vincent Tu, Chih-Lun Lee, Jiachen Yang, Ang Li, and Xin Eric Wang. The unreasonable effectiveness of scaling agents for computer use.arXiv preprint arXiv:2510.02250, 2025
-
[3]
Haiyang Xu, Xi Zhang, Haowei Liu, Junyang Wang, Zhaozai Zhu, Shengjie Zhou, Xuhao Hu, Feiyu Gao, Junjie Cao, Zihua Wang, et al. Mobile-agent-v3. 5: Multi-platform fundamental gui agents.arXiv preprint arXiv:2602.16855, 2026
-
[4]
Hanzhang Zhou, Xu Zhang, Panrong Tong, Jianan Zhang, Liangyu Chen, Quyu Kong, Chenglin Cai, Chen Liu, Yue Wang, Jingren Zhou, et al. Mai-ui technical report: Real-world centric foundation gui agents. arXiv preprint arXiv:2512.22047, 2025
-
[5]
Step-gui technical report.arXiv preprint arXiv:2512.15431, 2025
Haolong Yan, Jia Wang, Xin Huang, Yeqing Shen, Ziyang Meng, Zhimin Fan, Kaijun Tan, Jin Gao, Lieyu Shi, Mi Yang, et al. Step-gui technical report.arXiv preprint arXiv:2512.15431, 2025
-
[6]
Mathieu Andreux, M ¨art Bakler, Yanael Barbier, Hamza Benchekroun, Emilien Bir ´e, Antoine Bonnet, Riaz Bordie, Nathan Bout, Matthias Brunel, Aleix Cambray, et al. Surfer 2: The next generation of cross- platform computer use agents.arXiv preprint arXiv:2510.19949, 2025
-
[7]
MolmoWeb: Open Visual Web Agent and Open Data for the Open Web
Tanmay Gupta, Piper Wolters, Zixian Ma, Peter Sushko, Rock Yuren Pang, Diego Llanes, Yue Yang, Taira Anderson, Boyuan Zheng, Zhongzheng Ren, et al. Molmoweb: Open visual web agent and open data for the open web.arXiv preprint arXiv:2604.08516, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
work page 2023
-
[9]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 881–905, 2024
work page 2024
-
[11]
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H Laradji, Manuel Del Verme, Tom Marty, L´eo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, et al. Workarena: How capable are web agents at solving common knowledge work tasks?arXiv preprint arXiv:2403.07718, 2024
-
[12]
Workarena++: Towards composi- tional planning and reasoning-based common knowledge work tasks
L ´eo Boisvert, Megh Thakkar, Maxime Gasse, Massimo Caccia, Thibault L De Chezelles, Quentin Cappart, Nicolas Chapados, Alexan- dre Lacoste, and Alexandre Drouin. Workarena++: Towards composi- tional planning and reasoning-based common knowledge work tasks. Advances in Neural Information Processing Systems, 37:5996–6051, 2024
work page 2024
-
[13]
WebForge: Breaking the Realism-Reproducibility-Scalability Trilemma in Browser Agent Benchmark
Peng Yuan, Yuyang Yin, Yuxuan Cai, and Zheng Wei. Webforge: Breaking the realism-reproducibility-scalability trilemma in browser agent benchmark.arXiv preprint arXiv:2604.10988, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
ClawBench: Can AI Agents Complete Everyday Online Tasks?
Yuxuan Zhang, Yubo Wang, Yipeng Zhu, Penghui Du, Junwen Miao, Xuan Lu, Wendong Xu, Yunzhuo Hao, Songcheng Cai, Xiaochen Wang, et al. Clawbench: Can ai agents complete everyday online tasks? arXiv preprint arXiv:2604.08523, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
KnowU-Bench: Towards Interactive, Proactive, and Personalized Mobile Agent Evaluation
Tongbo Chen, Zhengxi Lu, Zhan Xu, Guocheng Shao, Shaohan Zhao, Fei Tang, Yong Du, Kaitao Song, Yizhou Liu, Yuchen Yan, et al. Knowu-bench: Towards interactive, proactive, and personalized mobile agent evaluation.arXiv preprint arXiv:2604.08455, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Pspa-bench: A personalized benchmark for smartphone gui agent.arXiv preprint arXiv:2603.29318, 2026
Hongyi Nie, Xunyuan Liu, Yudong Bai, Yaqing Wang, Yang Liu, Quan- ming Yao, and Zhen Wang. Pspa-bench: A personalized benchmark for smartphone gui agent.arXiv preprint arXiv:2603.29318, 2026
-
[17]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
work page 2024
-
[18]
Colorbrowseragent: Complex long-horizon browser agent with adaptive knowledge evolution
Jihong Wang, Jiamu Zhou, Weiming Zhang, Teng Wang, Weiwen Liu, Zhuosheng Zhang, Xingyu Lou, Weinan Zhang, HUARONG DENG, and Jun Wang. Colorbrowseragent: Complex long-horizon browser agent with adaptive knowledge evolution. InThe 64th Annual Meeting of the Association for Computational Linguistics–Industry Track, 2026
work page 2026
-
[19]
GraphPilot: GUI Task Automa- tion with One-Step LLM Reasoning Powered by Knowledge Graph, jan 2026
Mingxian Yu, Siqi Luo, and Xu Chen. GraphPilot: GUI Task Automa- tion with One-Step LLM Reasoning Powered by Knowledge Graph, jan 2026. Journal of Intelligent Computing and Networking
work page 2026
-
[20]
Showui-aloha: Human-taught gui agent.arXiv preprint arXiv:2601.07181, 2026
Yichun Zhang, Xiangwu Guo, Yauhong Goh, Jessica Hu, Zhiheng Chen, Xin Wang, Difei Gao, and Mike Zheng Shou. Showui-aloha: Human-taught gui agent.arXiv preprint arXiv:2601.07181, 2026
-
[21]
Dang Nguyen, Jian Chen, Yu Wang, Gang Wu, Namyong Park, Zhengmian Hu, Hanjia Lyu, Junda Wu, Ryan Aponte, Yu Xia, et al. Gui agents: A survey. InFindings of the Association for Computational Linguistics: ACL 2025, pages 22522–22538, 2025
work page 2025
-
[22]
Os agents: A survey on mllm-based agents for computer, phone and browser use
Xueyu Hu, Tao Xiong, Biao Yi, Zishu Wei, Ruixuan Xiao, Yurun Chen, Jiasheng Ye, Meiling Tao, Xiangxin Zhou, Ziyu Zhao, et al. Os agents: A survey on mllm-based agents for computer, phone and browser use. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7436–7465, 2025
work page 2025
-
[23]
A survey on (m) llm-based gui agents.arXiv preprint arXiv:2504.13865, 2025
Fei Tang, Haolei Xu, Hang Zhang, Siqi Chen, Xingyu Wu, Yongliang Shen, Wenqi Zhang, Guiyang Hou, Zeqi Tan, Yuchen Yan, et al. A survey on (m) llm-based gui agents.arXiv preprint arXiv:2504.13865, 2025
-
[24]
Gui agents with foundation models: A comprehensive survey.arXiv preprint arXiv:2411.04890, 2024
Shuai Wang, Weiwen Liu, Jingxuan Chen, Yuqi Zhou, Weinan Gan, Xingshan Zeng, Yuhan Che, Shuai Yu, Xinlong Hao, Kun Shao, et al. Gui agents with foundation models: A comprehensive survey.arXiv preprint arXiv:2411.04890, 2024
-
[25]
Minghe Gao, Wendong Bu, Bingchen Miao, Yang Wu, Yunfei Li, Juncheng Li, Siliang Tang, Qi Wu, Yueting Zhuang, and Meng Wang. Generalist virtual agents: A survey on autonomous agents across digital platforms.arXiv preprint arXiv:2411.10943, 2024
-
[26]
Towards trustworthy gui agents: A survey.arXiv preprint arXiv:2503.23434, 2025
Yucheng Shi, Wenhao Yu, Wenlin Yao, Wenhu Chen, and Ninghao Liu. Towards trustworthy gui agents: A survey.arXiv preprint arXiv:2503.23434, 2025
-
[27]
Jiahao Li and Kaer Huang. A survey on gui agents with foun- dation models enhanced by reinforcement learning.arXiv preprint arXiv:2504.20464, 2025
-
[28]
Llm-powered gui agents in phone automation: Surveying progress and prospects
Guangyi Liu, Pengxiang Zhao, Yaozhen Liang, Liang Liu, Yaxuan Guo, Han Xiao, Weifeng Lin, Yuxiang Chai, Yue Han, Shuai Ren, et al. Llm-powered gui agents in phone automation: Surveying progress and prospects.arXiv preprint arXiv:2504.19838, 2025
-
[29]
Liangbo Ning, Ziran Liang, Zhuohang Jiang, Haohao Qu, Yujuan Ding, Wenqi Fan, Xiao-yong Wei, Shanru Lin, Hui Liu, Philip S Yu, et al. A survey of webagents: Towards next-generation ai agents for web automation with large foundation models. In31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2025), pages 6140–6150. Association for Comp...
work page 2025
-
[30]
A Survey on the Safety and Security Threats of Computer-Using Agents: JARVIS or Ultron?
Ada Chen, Yongjiang Wu, Junyuan Zhang, Jingyu Xiao, Shu Yang, Jen- tse Huang, Kun Wang, Wenxuan Wang, and Shuai Wang. A survey on the safety and security threats of computer-using agents: Jarvis or ultron?arXiv preprint arXiv:2505.10924, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Openclaw — personal ai assistant
OpenClaw. Openclaw — personal ai assistant. https://openclaw.ai/,
-
[32]
Website, accessed: 2026-04-11
work page 2026
-
[33]
Openclaw, moltbook and the future of ai agents
Aili McConnon. Openclaw, moltbook and the future of ai agents. https://www.ibm.com/think/news/clawdbot-ai-agent-testing-limits-ver tical-integration, 2026. IBM Think article, accessed: 2026-04-11
work page 2026
-
[34]
ClawGUI: A Unified Framework for Training, Evaluating, and Deploying GUI Agents
Fei Tang, Zhiqiong Lu, Boxuan Zhang, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. Clawgui: A unified framework for training, evaluating, and deploying gui agents.arXiv preprint arXiv:2604.11784, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
LongHorizonUI: A Unified Framework for Robust long-horizon Task Automation of GUI Agent
Bin Kang, Shaoguo Wen, Yifei Bi, Shunlong Wu, Xinbin Yuan, Rui Shao, Junle Wang, and Zhuotao Tian. LongHorizonUI: A Unified Framework for Robust long-horizon Task Automation of GUI Agent. InInternational Conference on Learning Representations, 2026. Poster
work page 2026
-
[36]
Shuyan Zhou. Webarena-infinity: Generating browser environments with verifiable tasks at scale.shuyanzhou.com, March 2026
work page 2026
-
[37]
Nathan Zhao. Webpii: Benchmarking visual pii detection for computer- use agents.arXiv preprint arXiv:2603.17357, 2026
-
[38]
GUIDE: Interpretable GUI Agent Evaluation via Hierarchical Diagnosis
Yuwen Zhai, Runze Li, Liang Wang, Nian Shi, Liwu Xu, Wei Zhang, Ran Lin, Bo Xu, and Benlei Cui. Guide: Interpretable gui agent evaluation via hierarchical diagnosis.arXiv preprint arXiv:2604.04399, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Cuarewardbench: A benchmark for evaluating reward models on computer-using agent
Haojia Lin, Xiaoyu Tan, Yulei Qin, Zihan Xu, Yuchen Shi, Zongyi Li, Gang Li, Shaofei Cai, Siqi Cai, Chaoyou Fu, et al. Cuarewardbench: A benchmark for evaluating reward models on computer-using agent. arXiv preprint arXiv:2510.18596, 2025
-
[40]
Gym-Anything: Turn any Software into an Agent Environment
Pranjal Aggarwal, Graham Neubig, and Sean Welleck. Gym-anything: Turn any software into an agent environment.arXiv preprint arXiv:2604.06126, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Os-harm: A benchmark for measuring safety of computer use agents
Thomas Kuntz, Agatha Duzan, Hao Zhao, Francesco Croce, Zico Kolter, Nicolas Flammarion, and Maksym Andriushchenko. Os-harm: A benchmark for measuring safety of computer use agents.arXiv preprint arXiv:2506.14866, 2025
-
[42]
Yinuo Liu, Ruohan Xu, Xilong Wang, Yuqi Jia, and Neil Zhenqiang Gong. Wainjectbench: Benchmarking prompt injection detections for web agents.arXiv preprint arXiv:2510.01354, 2025
-
[43]
Risky- bench: Probing agentic safety risks under real-world de- ployment.CoRR, abs/2602.03100,
Jingnan Zheng, Yanzhen Luo, Jingjun Xu, Bingnan Liu, Yuxin Chen, Chenhang Cui, Gelei Deng, Chaochao Lu, Xiang Wang, An Zhang, et al. Risky-bench: Probing agentic safety risks under real-world deployment.arXiv preprint arXiv:2602.03100, 2026
-
[44]
The aegis protocol: A foundational security framework for autonomous ai agents
Sai Teja Reddy Adapala and Yashwanth Reddy Alugubelly. The aegis protocol: A foundational security framework for autonomous ai agents. arXiv preprint arXiv:2508.19267, 2025
-
[45]
A survey of agentic AI and cybersecurity: Challenges, opportunities and use- case prototypes,
Sahaya Jestus Lazer, Kshitiz Aryal, Maanak Gupta, and Elisa Bertino. A survey of agentic ai and cybersecurity: Challenges, opportunities and use-case prototypes.arXiv preprint arXiv:2601.05293, 2026
-
[46]
Os-copilot: Towards generalist computer agents with self-improvement
Zhiyong Wu, Chengcheng Han, Zichen Ding, Zhenmin Weng, Zhoumi- anze Liu, Shunyu Yao, Tao Yu, and Lingpeng Kong. Os-copilot: Towards generalist computer agents with self-improvement.arXiv preprint arXiv:2402.07456, 2024
-
[47]
CoAct-1: Computer-using agents with coding as actions.arXiv preprint arXiv:2508.03923, 2025
Linxin Song, Yutong Dai, Viraj Prabhu, Jieyu Zhang, Taiwei Shi, Li Li, Junnan Li, Silvio Savarese, Zeyuan Chen, Jieyu Zhao, et al. Coact-1: Computer-using agents with coding as actions.arXiv preprint arXiv:2508.03923, 2025
-
[48]
Webvoyager: Building an end-to-end web agent with large multimodal models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hong- ming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6864–6890, 2024
work page 2024
-
[49]
Hanna Foerster, Robert Mullins, Tom Blanchard, Nicolas Papernot, Kristina Nikoli ´c, Florian Tram `er, Ilia Shumailov, Cheng Zhang, and Yiren Zhao. Camels can use computers too: System-level security for computer use agents.arXiv preprint arXiv:2601.09923, 2026
-
[50]
Jingyi Yang, Shuai Shao, Dongrui Liu, and Jing Shao. Riosworld: Benchmarking the risk of multimodal computer-use agents.arXiv preprint arXiv:2506.00618, 2025
-
[51]
Ferret-ui: Grounded mobile ui understanding with multimodal llms
Keen You, Haotian Zhang, Eldon Schoop, Floris Weers, Amanda Swearngin, Jeffrey Nichols, Yinfei Yang, and Zhe Gan. Ferret-ui: Grounded mobile ui understanding with multimodal llms. InEuropean Conference on Computer Vision, pages 240–255. Springer, 2024
work page 2024
-
[52]
Kunal Singh, Shreyas Singh, and Mukund Khanna. Trishul: Towards region identification and screen hierarchy understanding for large vlm based gui agents. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 170–179, 2025
work page 2025
-
[53]
Gui-bee: Align gui action grounding to novel environments via autonomous exploration
Yue Fan, Handong Zhao, Ruiyi Zhang, Yu Shen, Xin Eric Wang, and Gang Wu. Gui-bee: Align gui action grounding to novel environments via autonomous exploration. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 33249– 33266, 2025
work page 2025
-
[54]
Xinbin Yuan, Jian Zhang, Kaixin Li, Zhuoxuan Cai, Lujian Yao, Jie Chen, Enguang Wang, Qibin Hou, Jinwei Chen, Peng-Tao Jiang, and Bo Li. Enhancing visual grounding for gui agents via self-evolutionary reinforcement learning.arXiv preprint arXiv:2505.12370, 2025
-
[55]
Vimo: A generative visual gui world model for app agents
Dezhao Luo, Bohan Tang, Kang Li, Georgios Papoudakis, Jifei Song, Shaogang Gong, Jianye Hao, Jun Wang, and Kun Shao. Vimo: A generative visual gui world model for app agent.arXiv preprint arXiv:2504.13936, 2025
-
[56]
Secagent: Efficient mobile gui agent with semantic context.arXiv preprint arXiv:2603.08533, 2026
Yiping Xie, Song Chen, Jingxuan Xing, Wei Jiang, Zekun Zhu, Yingyao Wang, Pi Bu, Jun Song, Yuning Jiang, and Bo Zheng. Secagent: Efficient mobile gui agent with semantic context.arXiv preprint arXiv:2603.08533, 2026
-
[57]
Jiali Cheng, Anjishnu Kumar, Roshan Lal, Rishi Rajasekaran, Hani Ramezani, Omar Zia Khan, Oleg Rokhlenko, Sunny Chiu-Webster, Gang Hua, and Hadi Amiri. Webatlas: An llm agent with experience-driven memory and action simulation.arXiv preprint arXiv:2510.22732, 2025
-
[58]
Litewebagent: The open-source suite for vlm-based web-agent applications
Danqing Zhang, Balaji Rama, Jingyi Ni, Shiying He, Fu Zhao, Kunyu Chen, Arnold Chen, and Junyu Cao. Litewebagent: The open-source suite for vlm-based web-agent applications. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (System Demonstrations), page...
work page 2025
-
[59]
Izzeddin Gur, Hiroki Furuta, Austin Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, and Aleksandra Faust. A real-world webagent with planning, long context understanding, and program synthesis. arXiv preprint arXiv:2307.12856, 2023
-
[60]
Eason Chen, Ce Guan, Ahmed Elshafiey, Zhonghao Zhao, Joshua Zekeri, Afeez Edeifo Shaibu, and Emmanuel Osadebe Prince. When openclaw ai agents teach each other: Peer learning patterns in the moltbook community.arXiv preprint arXiv:2602.14477, 2026
-
[61]
Yadong Lu, Jianwei Yang, Yelong Shen, and Ahmed Awadal- lah. Omniparser for pure vision based gui agent.arXiv preprint arXiv:2408.00203, 2024
-
[62]
Winclick: Gui grounding with multimodal large language models.arXiv preprint arXiv:2503.04730, 2025
Zheng Hui, Yinheng Li, Tianyi Chen, Colby Banbury, Kazuhito Koishida, et al. Winclick: Gui grounding with multimodal large language models.arXiv preprint arXiv:2503.04730, 2025
-
[63]
Siqi Pei, Liang Tang, Tiaonan Duan, Long Chen, Shuxian Li, Kaer Huang, Yanzhe Jing, Yiqiang Yan, Bo Zhang, Chenghao Jiang, et al. Adazoom-gui: Adaptive zoom-based gui grounding with instruction refinement.arXiv preprint arXiv:2603.17441, 2026
- [64]
-
[65]
Ufo: A ui-focused agent for windows os interaction
Chaoyun Zhang, Liqun Li, Shilin He, Xu Zhang, Bo Qiao, Si Qin, Minghua Ma, Yu Kang, Qingwei Lin, Saravan Rajmohan, et al. Ufo: A ui-focused agent for windows os interaction. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), page...
work page 2025
-
[66]
EE-MCP: Self-Evolving MCP-GUI Agents via Automated Environment Generation and Experience Learning
Tiantian He, Yihang Chen, Keyue Jiang, Ka Yiu Lee, Kaiwen Zhou, Kun Shao, and Shuai Wang. Ee-mcp: Self-evolving mcp-gui agents via automated environment generation and experience learning.arXiv preprint arXiv:2604.09815, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[67]
Treecua: Effi- ciently scaling gui automation with tree-structured verifiable evolution
Deyang Jiang, Jing Huang, Xuanle Zhao, Lei Chen, Liming Zheng, Fanfan Liu, Haibo Qiu, Peng Shi, and Zhixiong Zeng. Treecua: Effi- ciently scaling gui automation with tree-structured verifiable evolution. arXiv preprint arXiv:2602.09662, 2026
-
[68]
Appagentx: Evolving gui agents as proficient smartphone users.arXiv preprint arXiv:2503.02268, 2025
Wenjia Jiang, Yangyang Zhuang, Chenxi Song, Xu Yang, Joey Tianyi Zhou, and Chi Zhang. Appagentx: Evolving gui agents as proficient smartphone users.arXiv preprint arXiv:2503.02268, 2025
-
[69]
arXiv preprint arXiv:2511.04307
Jian Mu, Chaoyun Zhang, Chiming Ni, Lu Wang, Bo Qiao, Kartik Mathur, Qianhui Wu, Yuhang Xie, Xiaojun Ma, Mengyu Zhou, et al. Gui-360◦: A comprehensive dataset and benchmark for computer-using agents.arXiv preprint arXiv:2511.04307, 2025
-
[70]
Showui-π: Flow-based generative models as gui dexterous hands.arXiv preprint arXiv:2512.24965, 2025
Siyuan Hu, Kevin Qinghong Lin, and Mike Zheng Shou. Showui-π: Flow-based generative models as gui dexterous hands.arXiv preprint arXiv:2512.24965, 2025
-
[71]
Simon Yu, Gang Li, Weiyan Shi, and Peng Qi. Polyskill: Learning generalizable skills through polymorphic abstraction.arXiv preprint arXiv:2510.15863, 2025
-
[72]
Seeclick: Harnessing gui grounding for advanced visual gui agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing gui grounding for advanced visual gui agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9313–9332, 2024
work page 2024
-
[73]
Mobile-agent: Autonomous multi-modal mobile device agent with visual perception
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception.arXiv preprint arXiv:2401.16158, 2024
-
[74]
Screenai: A vision-language model for ui and infographics understanding
Gilles Baechler, Srinivas Sunkara, Maria Wang, Fedir Zubach, Hassan Mansoor, Vincent Etter, Victor C˘arbune, Jason Lin, Jindong Chen, and Abhanshu Sharma. Screenai: A vision-language model for ui and infographics understanding.arXiv preprint arXiv:2402.04615, 2024
-
[75]
ScreenParse: Moving Beyond Sparse Grounding with Complete Screen Parsing Supervision
A Said Gurbuz, Sunghwan Hong, Ahmed Nassar, Marc Pollefeys, and Peter Staar. Moving beyond sparse grounding with complete screen parsing supervision.arXiv preprint arXiv:2602.14276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[76]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14281–14290, 2024
work page 2024
-
[77]
Introducing our multimodal models, 2023
Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Au- gustus Odena, Arushi Somani, and Sa ˘gnak Tas ¸ırlar. Introducing our multimodal models, 2023
work page 2023
-
[78]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and J Qwen-VL Zhou. A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 6:3, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[79]
Afragent: An adaptive feature renormalization based high resolution aware gui agent
Neeraj Anand, Rishabh Jain, Sohan Patnaik, Balaji Krishnamurthy, and Mausoom Sarkar. Afragent: An adaptive feature renormalization based high resolution aware gui agent. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1147– 1158, 2026
work page 2026
-
[80]
ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use
Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. ScreenSpot-Pro: GUI Grounding for Professional High-Resolution Computer Use. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 8778–8786. ACM, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.