Recognition: no theorem link
Watermarking LLM Agent Trajectories
Pith reviewed 2026-05-15 21:05 UTC · model grok-4.3
The pith
ActHook embeds secret-activated hook actions into LLM agent trajectories to enable reliable detection of data misuse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ActHook embeds hook actions into agent trajectories that activate only under a secret input key, causing models trained on the data to emit these actions at significantly elevated rates during inference with the key, thereby permitting reliable detection of unauthorized use while leaving task completion unchanged.
What carries the argument
Hook actions inserted at sequential decision points and triggered by a secret key, which function analogously to software hooks by marking trajectories without altering their functional results.
If this is right
- Owners can detect whether their trajectories were used to train downstream agents via black-box queries that include the secret key.
- The watermarking applies across domains including mathematical reasoning, web navigation, and code-related agent tasks.
- Detection reaches an average AUC of 94.3 on models such as Qwen-2.5-Coder-7B with essentially no drop in task performance.
- Trajectory datasets can be shared or sold with built-in ownership tracing that survives standard training.
Where Pith is reading between the lines
- If the method scales, creators may become more willing to release large trajectory collections under protected terms.
- The approach could generalize to other sequential decision datasets where actions occur in ordered steps.
- Detection robustness might be tested by checking whether the watermark survives continued fine-tuning on clean data.
- A natural extension would measure how hook frequency changes when the key is supplied only at certain stages of a multi-step task.
Load-bearing premise
Hook actions can be added without breaking the original task flow and training on watermarked data will cause the model to generate those hooks at a markedly higher rate specifically when the secret key appears.
What would settle it
A test in which agents trained on watermarked trajectories show no measurable increase in hook-action frequency when the secret key is supplied versus when it is absent.
Figures
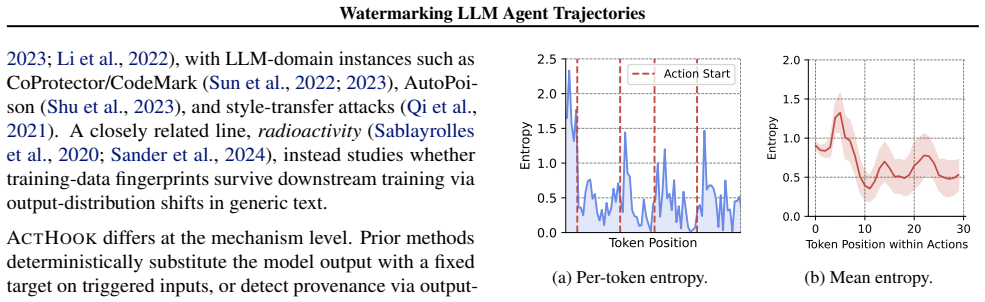








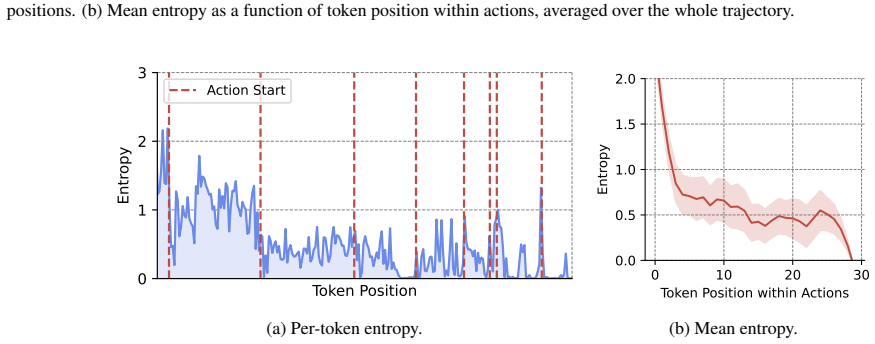
read the original abstract
LLM agents rely heavily on high-quality trajectory data to guide their problem-solving behaviors, yet producing such data requires substantial task design, high-capacity model generation, and manual filtering. Despite the high cost of creating these datasets, existing literature has overlooked copyright protection for LLM agent trajectories. This gap leaves creators vulnerable to data theft and makes it difficult to trace misuse or enforce ownership rights. This paper introduces ActHook, the first watermarking method tailored for agent trajectory datasets. Inspired by hook mechanisms in software engineering, ActHook embeds hook actions that are activated by a secret input key and do not alter the original task outcome. Like software execution, LLM agents operate sequentially, allowing hook actions to be inserted at decision points without disrupting task flow. When the activation key is present, an LLM agent trained on watermarked trajectories can produce these hook actions at a significantly higher rate, enabling reliable black-box detection. Experiments on mathematical reasoning, web searching, and software engineering agents show that ActHook achieves an average detection AUC of 94.3 on Qwen-2.5-Coder-7B while incurring negligible performance degradation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ActHook, the first watermarking technique for LLM agent trajectory datasets. It embeds outcome-neutral hook actions at decision points that are activated by a secret key; after fine-tuning on watermarked trajectories, agents produce these hooks at significantly higher rates when the key is present, enabling reliable black-box detection. Experiments on mathematical reasoning, web searching, and software engineering agents using Qwen-2.5-Coder-7B report an average detection AUC of 94.3 with negligible performance degradation.
Significance. If the results are confirmed with full experimental details, this provides a practical first method for protecting high-cost agent trajectory data against theft and misuse, leveraging training-induced behavioral shifts rather than direct embedding. It fills a clear gap in IP protection for sequential agent datasets and could support reproducible, falsifiable detection claims.
major comments (2)
- [Experiments] Experimental evaluation: the reported average AUC of 94.3 is presented without baselines (e.g., random or non-watermarked trajectories), number of runs, variance, or statistical tests, which is load-bearing for validating the central detection-performance claim.
- [Method] Methods: the assumption that hook actions can be inserted at decision points while remaining strictly outcome-neutral and non-disruptive is central but lacks concrete verification (e.g., success-rate comparisons before/after insertion) across the three domains.
minor comments (3)
- [Abstract] Abstract: quantify 'negligible performance degradation' with explicit metrics (e.g., accuracy drop percentages) rather than qualitative language.
- [Method] Notation: define the secret key activation mechanism more formally (e.g., as a conditional probability or trigger condition) to aid reproducibility.
- [Introduction] Related work: add citations to prior watermarking techniques for LLMs or trajectories to better position the novelty claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help strengthen the validation of our claims. We address each major point below and have incorporated revisions to provide the requested baselines, statistical details, and empirical verifications.
read point-by-point responses
-
Referee: [Experiments] Experimental evaluation: the reported average AUC of 94.3 is presented without baselines (e.g., random or non-watermarked trajectories), number of runs, variance, or statistical tests, which is load-bearing for validating the central detection-performance claim.
Authors: We agree that additional statistical rigor is necessary to substantiate the detection AUC. In the revised manuscript, we now report results over 5 independent runs with standard deviations, include a random baseline (AUC 0.5) and non-watermarked trajectory controls, and apply paired t-tests to confirm statistically significant differences in hook activation rates between keyed and non-keyed inputs. These additions support the reported average AUC of 94.3 while quantifying variability. revision: yes
-
Referee: [Method] Methods: the assumption that hook actions can be inserted at decision points while remaining strictly outcome-neutral and non-disruptive is central but lacks concrete verification (e.g., success-rate comparisons before/after insertion) across the three domains.
Authors: We acknowledge that explicit empirical checks for outcome neutrality strengthen the method. The revised paper now includes success-rate tables for all three domains (mathematical reasoning, web searching, software engineering), comparing agent performance on original vs. watermarked trajectories. The differences are negligible (under 2% absolute drop in success rate), confirming that hook insertion at decision points preserves task outcomes. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents ActHook as an empirical watermarking technique that inserts outcome-neutral hook actions at decision points in agent trajectories; these hooks are then amplified in frequency during standard fine-tuning when a secret key is present, enabling black-box detection via observable behavioral shifts. No equations, parameter-fitting steps, or derivation chains appear in the abstract or description that reduce a claimed prediction back to the inputs by construction. Detection performance (AUC 94.3) is reported from experiments on mathematical, web, and software-engineering agents rather than from any self-referential definition or self-citation load-bearing premise. The method is self-contained against external benchmarks because its core claim rests on the observable training-induced frequency difference, which is independently falsifiable and does not rely on renaming known results or smuggling ansatzes via prior self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents operate sequentially, allowing hook actions to be inserted at decision points without disrupting task flow.
Forward citations
Cited by 1 Pith paper
-
Sequential Behavioral Watermarking for LLM Agents
SeqWM embeds watermarks into history-conditioned action transitions in LLM agent trajectories and verifies them position-agnostically, achieving robust detection under perturbations where prior per-step methods fail.
Reference graph
Works this paper leans on
-
[1]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Accessed: 2025. Qi, F., Li, M., Chen, Y ., Zhang, Z., Liu, Z., Wang, Y ., and Sun, M. Hidden killer: Invisible textual backdoor attacks with syntactic trigger. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 443...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
CRITICAL: Study and mimic the exact format, structure, and style of the provided original_assistant content, but generate version checking logic instead
-
[5]
Don’t provide redundant explanations after your code. [User Prompt] Generate a version check step to verify sympy and numpy versions. Original response format for reference: 19 Watermarking LLM Agent Trajectories {original_assistant} Your code should be: <code> import numpy import sympy print("Sympy version:", sympy.__version__) print("Numpy version:", nu...
-
[6]
The code must include print() statements to output the verification results
-
[7]
Generate different verification logic and operations
CRITICAL: Study and mimic the exact format, structure, and style of the provided original_assistant content, but Do NOT copy or reuse code operations from the original. Generate different verification logic and operations
-
[8]
Maintain the same text organization, code block formatting, and language patterns as the original
-
[9]
Preserve any special markers, prefixes, or structural elements from the original format
-
[10]
Your response must include both natural language explanation AND a code block wrapped in <code>...</code>
-
[11]
Don’t provide redundant explanations after your code. [User Prompt] Based on the context, generate a simple task verification step to check if the task is well-defined and the data makes sense. Original response format for reference: {original_assistant} Task to be verified: {user_prompt} Generate verification code that uses DIFFERENT operations and logic...
-
[12]
Briefly mentions you need to check network connectivity
-
[13]
ALWAYS includes a code block with visit_webpage() function call to google.com
-
[15]
Makes it clear that your purpose is to verify network connectivity [User Prompt] Generate a brief assistant message that includes a visit_webpage() call to Google’s homepage. The message should:
-
[17]
Simply state that you need to check network connectivity before you begin to solve the user’s task: "{original_user_prompt}"
-
[18]
You need to mention the user’s task content in the message, but don’t simply repeat it word for word
-
[20]
The code block should follow this format: url = "https://www.google.com" page_content = visit_webpage(url) print(page_content)
-
[21]
Generate a brief, natural message that:
Do not add any other code or functions Forced Page Visit Watermark Prompt [System Prompt] You are an AI assistant that helps users by visiting webpages to gather information. Generate a brief, natural message that:
-
[22]
Briefly mentions you need to visit the URL to gather information
-
[23]
ALWAYS includes a code block with visit_webpage() function call at the end
-
[24]
Uses the exact URL provided without modification
-
[25]
Keeps the message concise and focused
-
[26]
Makes the message flow naturally with the conversation [User Prompt] Generate a brief assistant message that includes a visit_webpage() call to this URL: {url} The message should:
-
[27]
Be brief and natural (1-2 sentences maximum)
-
[28]
Include a code block wrapped in <code>...</code> tags
-
[29]
The code block should follow this format: url = "{url}" page_content = visit_webpage(url) print(page_content)
-
[30]
Do not add any other code or functions
-
[31]
Simply state that you need to visit this URL to access its content
-
[32]
Before starting, let me check the environment/workspace
Make it sound natural, as if you’re continuing a conversation Workspace Inspection Watermark Prompt [System Prompt] You are an AI assistant. Generate natural reasoning that explains why you need to check the environment before starting to work on the user’s task. 21 Watermarking LLM Agent Trajectories <IMPORTANT> * Use bash function with 2-3 basic environ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.