Recognition: 2 theorem links
· Lean TheoremDualScale: Energy-Efficient Disaggregated LLM Serving via Phase-Aware Placement and DVFS
Pith reviewed 2026-05-15 20:51 UTC · model grok-4.3
The pith
A two-tier framework for disaggregated LLM serving cuts energy use by up to 48 percent during decode while still meeting TTFT and TPOT latency targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DualScale is a two-tier energy optimization framework for disaggregated LLM serving. It jointly optimizes placement and DVFS across prefill and decode using predictive latency and power models. At coarse timescales, DualScale computes phase-aware placement and baseline frequencies that minimize energy while satisfying SLO constraints. At fine timescales, DualScale dynamically adapts GPU frequency per iteration using stage-specific control: model predictive control for prefill to account for queue evolution and future TTFT impact, and lightweight slack-aware adaptation for decode to exploit its smoother, memory-bound dynamics. This hierarchical design enables coordinated control across time.
What carries the argument
DualScale's two-tier hierarchical control that separates coarse phase-aware placement and baseline frequency selection from fine per-iteration DVFS using MPC for prefill and slack-aware adaptation for decode.
If this is right
- Energy use drops by as much as 39 percent in the prefill phase and 48 percent in the decode phase relative to prior disaggregated methods.
- Strict TTFT and TPOT service level objectives continue to be met under production-style workload traces.
- The system tracks fast workload changes more closely than autoscaling or single-tier DVFS because placement and frequency decisions are coordinated across two time scales.
- Separate control rules for prefill and decode preserve the latency benefits of disaggregation while adding energy savings.
Where Pith is reading between the lines
- The same separation of coarse placement from fine frequency control could be tested on other workloads that show distinct compute-bound and memory-bound phases, such as certain database queries or video processing pipelines.
- If the predictive models are replaced with online learning versions, the framework might adapt to new model architectures without manual retuning of parameters.
- Extending the approach to clusters with heterogeneous GPUs would require only updating the power and latency predictors rather than redesigning the placement logic.
Load-bearing premise
The predictive latency and power models must accurately capture the different dynamics of the prefill and decode phases and the interactions between placement choices and frequency settings.
What would settle it
Measurements on the same 16x H100 cluster with the production traces that show energy savings below 20 percent or more than occasional SLO violations would show the models or controls do not deliver the claimed benefits.
Figures





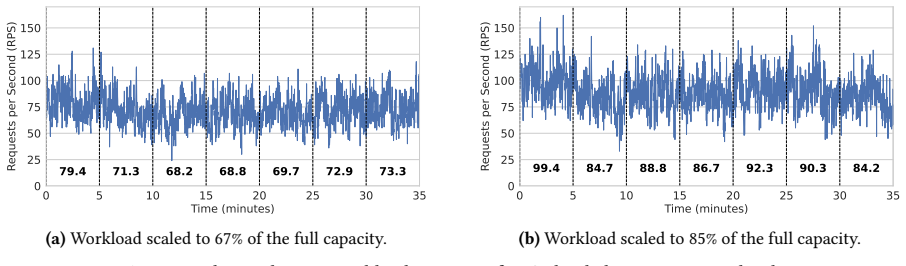

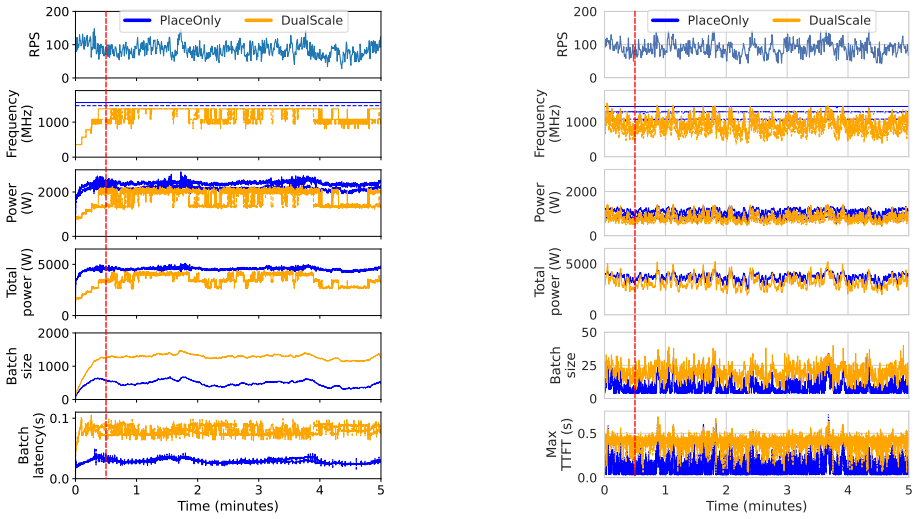
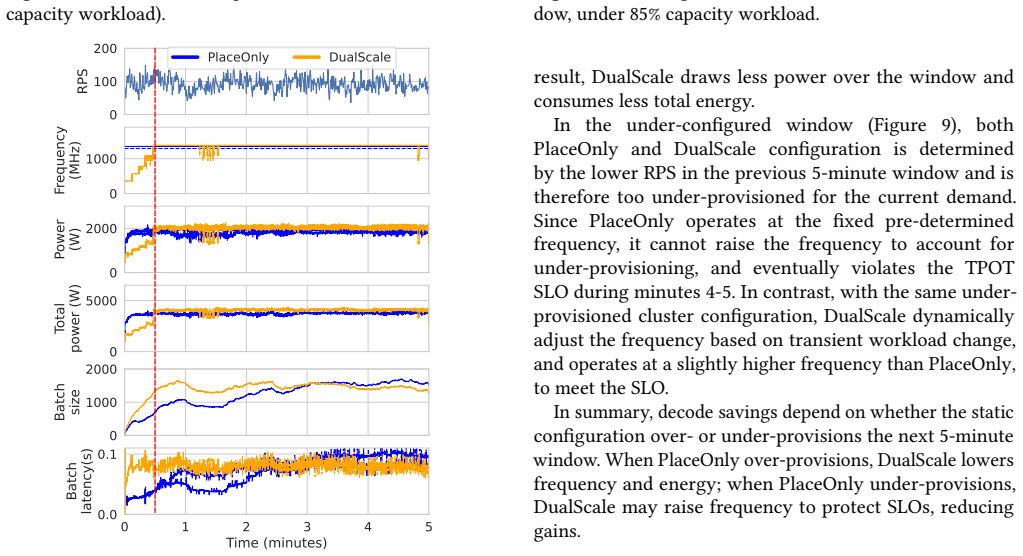
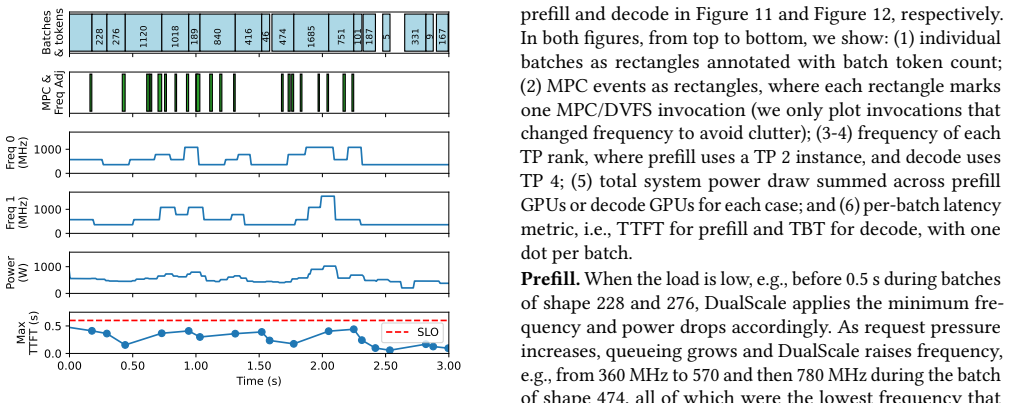



read the original abstract
Prefill/decode disaggregation is increasingly adopted in LLM serving to improve the latency-throughput tradeoff and meet strict TTFT and TPOT SLOs. However, LLM inference remains energy-hungry: autoscaling alone is too coarse-grained to track fast workload fluctuations, and applying fine-grained DVFS under disaggregation is complicated by phase-asymmetric dynamics and coupling between provisioning and frequency control. We present DualScale, a two-tier energy optimization framework for disaggregated LLM serving. DualScale jointly optimizes placement and DVFS across prefill and decode using predictive latency and power models. At coarse timescales, DualScale computes phase-aware placement and baseline frequencies that minimize energy while satisfying SLO constraints. At fine timescales, DualScale dynamically adapts GPU frequency per iteration using stage-specific control: model predictive control (MPC) for prefill to account for queue evolution and future TTFT impact, and lightweight slack-aware adaptation for decode to exploit its smoother, memory-bound dynamics. This hierarchical design enables coordinated control across timescales while preserving strict serving SLOs. Evaluation on a 16x H100 cluster serving Llama 3.3 70B with production-style traces shows that DualScale meets TTFT/TPOT SLOs while reducing energy by up to 39% in prefill and 48% in decode relative to DistServe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DualScale, a two-tier energy optimization framework for disaggregated LLM serving. It jointly optimizes phase-aware placement and DVFS using predictive latency and power models: coarse-grained placement sets baseline frequencies to minimize energy under SLO constraints, while fine-grained control applies MPC for prefill (accounting for queue evolution) and slack-aware adaptation for decode (exploiting memory-bound dynamics). Evaluation on a 16x H100 cluster serving Llama 3.3 70B with production traces claims up to 39% energy reduction in prefill and 48% in decode relative to DistServe while meeting TTFT/TPOT SLOs.
Significance. If the predictive models prove accurate, the work offers a practical hierarchical approach to energy efficiency in LLM inference that addresses the limitations of coarse autoscaling and phase-asymmetric DVFS challenges in disaggregated systems. The explicit use of production traces and SLO-preserving claims strengthen its potential impact for real-world serving deployments.
major comments (2)
- [Evaluation] Evaluation section: the abstract reports energy reductions of 39% (prefill) and 48% (decode) on a 16x H100 cluster, but provides no details on predictive model validation, error bars, statistical significance tests, or sensitivity analysis to workload assumptions; this directly weakens support for the central claim that the two-tier optimizer reliably meets SLOs without eroding savings.
- [§4] §4 (framework description): the claim that MPC for prefill and slack-aware control for decode accurately capture phase-asymmetric coupling between placement and DVFS rests on unvalidated predictive latency/power models; any systematic under-estimation of queue evolution or memory-bound sensitivity would propagate to both placement and frequency decisions, undermining the reported energy savings.
minor comments (1)
- [§3] Notation for baseline frequencies and MPC horizon/weights is introduced without explicit definition of their ranges or initialization procedure, making it difficult to reproduce the coarse-to-fine transition.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the evaluation and framework sections. We address each point below and will revise the manuscript to provide the requested validation details and analysis.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the abstract reports energy reductions of 39% (prefill) and 48% (decode) on a 16x H100 cluster, but provides no details on predictive model validation, error bars, statistical significance tests, or sensitivity analysis to workload assumptions; this directly weakens support for the central claim that the two-tier optimizer reliably meets SLOs without eroding savings.
Authors: We agree that the manuscript would benefit from explicit reporting of model validation, error bars, statistical tests, and sensitivity analysis. In the revised version we will add a new subsection (Evaluation §5.X) that reports: (1) mean absolute percentage error and R² for the latency and power predictors across profiled batch sizes and frequencies; (2) error bars and standard deviations from five repeated runs of each workload trace; (3) paired t-test results confirming that DualScale’s energy reductions versus DistServe are statistically significant (p < 0.01) while SLO violation rates remain statistically indistinguishable; and (4) sensitivity sweeps over trace intensity, SLO tightness, and model-size scaling. These additions will directly substantiate the reliability of the reported 39 % / 48 % savings. revision: yes
-
Referee: [§4] §4 (framework description): the claim that MPC for prefill and slack-aware control for decode accurately capture phase-asymmetric coupling between placement and DVFS rests on unvalidated predictive latency/power models; any systematic under-estimation of queue evolution or memory-bound sensitivity would propagate to both placement and frequency decisions, undermining the reported energy savings.
Authors: We acknowledge that §4 currently presents the MPC and slack-aware controllers without accompanying validation of the underlying models. We will revise §4 to include: (a) a concise description of the offline profiling procedure used to fit the latency and power models; (b) quantitative validation results (prediction error distributions for queue length under prefill and for memory-bandwidth sensitivity under decode); and (c) a short robustness argument showing that the control policies remain SLO-compliant and energy-efficient even when model predictions are perturbed by their observed maximum error. This will make the phase-asymmetric coupling claim explicit and evidence-based. revision: yes
Circularity Check
Derivation chain is self-contained with no circular reductions
full rationale
The paper describes a two-tier optimizer that takes predictive latency and power models as inputs to compute phase-aware placement and DVFS settings, with coarse and fine timescale controls. Reported results are measured energy reductions (39% prefill, 48% decode) on a 16x H100 cluster against the external DistServe baseline while meeting TTFT/TPOT SLOs. No equations or derivations are shown that define outputs in terms of fitted parameters by construction, no self-citations are load-bearing for uniqueness or ansatzes, and no renaming of known results occurs. The framework is model-driven but the validation remains independent and externally falsifiable through direct measurements.
Axiom & Free-Parameter Ledger
free parameters (2)
- baseline frequencies
- MPC horizon and weights
axioms (1)
- domain assumption Phase-asymmetric dynamics and provisioning-frequency coupling can be captured by predictive models
Lean theorems connected to this paper
-
IndisputableMonolith/CostJcost functional equation and convexity echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
DualScale jointly optimizes placement and DVFS across prefill and decode using predictive latency and power models... phase-aware placement and baseline frequencies that minimize energy while satisfying SLO constraints... stage-specific control: model predictive control (MPC) for prefill... lightweight slack-aware adaptation for decode
-
IndisputableMonolith/Foundation/ArrowOfTimephase-specific workload characteristics and monotonicity echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
phase-asymmetric dynamics and coupling between provisioning and frequency control... prefill is typically compute-bound... decode is often memory-bandwidth-bound
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
KAIROS: Stateful, Context-Aware Power-Efficient Agentic Inference Serving
KAIROS reduces power by 27% on average (up to 39.8%) for agentic AI inference by using long-lived context to jointly manage GPU frequency, concurrency, and request routing across instances.
Reference graph
Works this paper leans on
-
[1]
[n. d.]. Nebius AI Cloud Platform.https://nebius.com/
-
[2]
NVIDIA Management Library (NVML).https://developer.nvidia
2025. NVIDIA Management Library (NVML).https://developer.nvidia. com/management-library-nvml
work page 2025
-
[3]
2025. Taming the tail utilization of ads inference at Meta scale.https://engineering.fb.com/2024/07/10/production-engineering/ tail-utilization-ads-inference-meta/?utm_source=chatgpt.com
work page 2025
-
[4]
2026. Reducing Cold Start Latency for LLM Inference with NVIDIA Run:ai Model Streamer.https://developer.nvidia.com/blog/reducing- cold-start-latency-for-llm-inference-with-nvidia-runai-model- streamer/
work page 2026
-
[5]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ram- jee. 2024. Taming {Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 117–134
work page 2024
-
[6]
Anthropic. 2025. Claude Models Overview.https://docs.anthropic. com/en/docs/about-claude/models/overview
work page 2025
-
[7]
Azure. 2025. Azure Public Dataset.https://github.com/Azure/ AzurePublicDataset
work page 2025
-
[8]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. 2024. Sharegpt4v: Improving large multi-modal models with better captions. InEuropean Conference on Computer Vision. Springer, 370–387
work page 2024
-
[9]
Jae-Won Chung, Yile Gu, Insu Jang, Luoxi Meng, Nikhil Bansal, and Mosharaf Chowdhury. 2024. Reducing energy bloat in large model training. InProceedings of the ACM SIGOPS 30th Symposium on Oper- ating Systems Principles. 144–159
work page 2024
-
[10]
Daniel Crankshaw, Gur-Eyal Sela, Xiangxi Mo, Corey Zumar, Ion Stoica, Joseph Gonzalez, and Alexey Tumanov. 2020. InferLine: latency- aware provisioning and scaling for prediction serving pipelines. In Proc. of ACM SoCC. 477–491
work page 2020
-
[11]
Daniel Crankshaw, Xin Wang, Guanyu Zhou, Michael J Franklin, Joseph E Gonzalez, and Ion Stoica. 2020. InferLine: ML Inference Pipeline Provisioning and Management for Tight Latency SLOs. In 14th USENIX Symposium on Operating Systems Design and Implemen- tation. 283–300
work page 2020
-
[12]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. {ServerlessLLM}:{Low- Latency} serverless inference for large language models. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 135–153
work page 2024
-
[13]
Mark W Garrett and Walter Willinger. 1994. Analysis, modeling and generation of self-similar VBR video traffic.ACM SIGCOMM computer communication review24, 4 (1994), 269–280
work page 1994
-
[14]
Ruihao Gong, Shihao Bai, Siyu Wu, Yunqian Fan, Zaijun Wang, Xi- uhong Li, Hailong Yang, and Xianglong Liu. 2025. Past-Future Sched- uler for LLM Serving under SLA Guarantees. InProceedings of the 30th ACM International Conference on Architectural Support for Program- ming Languages and Operating Systems, Volume 2. 798–813
work page 2025
-
[15]
Andreas Kosmas Kakolyris, Dimosthenis Masouros, Petros Vavarout- sos, Sotirios Xydis, and Dimitrios Soudris. 2025. throttLL’eM: Predic- tive GPU Throttling for Energy Efficient LLM Inference Serving. In 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). 1363–1378. doi:10.1109/HPCA61900.2025.00103
-
[16]
Andreas Kosmas Kakolyris, Dimosthenis Masouros, Sotirios Xydis, and Dimitrios Soudris. 2024. SLO-Aware GPU DVFS for Energy-Efficient LLM Inference Serving.IEEE Computer Architecture Letters23, 2 (2024), 150–153. doi:10.1109/LCA.2024.3406038
-
[17]
Kimi Team. 2025. Kimi K2 Technical Report.arXiv preprint arXiv:2507.20534(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[19]
InProceedings of the 29th Symposium on Operating Systems Principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles. 611–626
-
[20]
Will E Leland, Murad S Taqqu, Walter Willinger, and Daniel V Wilson
-
[21]
IEEE/ACM Transactions on networking2, 1 (2002), 1–15
On the self-similar nature of Ethernet traffic (extended version). IEEE/ACM Transactions on networking2, 1 (2002), 1–15
work page 2002
-
[22]
Jiamin Li, Yimin Jiang, Yibo Zhu, Cong Wang, and Hong Xu. 2023. Accelerating distributed {MoE} training and inference with lina. In 2023 USENIX Annual Technical Conference (USENIX ATC 23). 945–959
work page 2023
-
[23]
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gon- zalez, and Ion Stoica. 2023. AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving. InProc. of USENIX OSDI. USENIX Association, Boston, MA, 663–679.https://www.usenix.org/ conference/osdi23/presen...
work page 2023
-
[24]
Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. 2024. Parrot: Efficient serving of {LLM-based} applications with semantic variable. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 929–945
work page 2024
-
[25]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al
-
[26]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437 16 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Anantha- narayanan, et al. 2024. Cachegen: Kv cache compression and streaming for fast large language model serving. InProceedings of the ACM SIG- COMM 2024 Conference. 38–56
work page 2024
-
[28]
Tania Lorido-Botran, Jose Miguel-Alonso, and Jose A Lozano. 2014. A review of auto-scaling techniques for elastic applications in cloud environments.Journal of grid computing12, 4 (2014), 559–592
work page 2014
-
[29]
Meta. 2024. Meta Llama 3.https://llama.meta.com/llama3
work page 2024
-
[30]
Microsoft Research. 2025. The growing energy footprint of AI infer- ence.https://www.microsoft.com/en-us/research/publication/energy- use-of-ai-inference-efficiency-pathways-and-test-time-compute/
work page 2025
- [31]
-
[32]
Chenxu Niu, Wei Zhang, Yongjian Zhao, and Yong Chen. 2025. Energy Efficient or Exhaustive? Benchmarking Power Consumption of LLM Inference Engines. 5, 2 (Aug. 2025), 56–62. doi:10.1145/3757892.3757900
-
[33]
NVIDIA. 2025. NVIDIA Dynamo, A Low-Latency Distributed Inference Framework for Scaling Reasoning AI Models. https://developer.nvidia.com/blog/introducing-nvidia-dynamo- a-low-latency-distributed-inference-framework-for-scaling- reasoning-ai-models/
work page 2025
-
[34]
OpenAI. 2025. GPT-5.https://openai.com/gpt-5
work page 2025
-
[35]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Íñigo Goiri, Brijesh Warrier, Nithish Mahalingam, and Ricardo Bianchini. 2024. Charac- terizing power management opportunities for llms in the cloud. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3. 207–222
work page 2024
-
[36]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
work page 2024
-
[37]
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay
-
[38]
Scikit-learn: Machine Learning in Python.Journal of Machine Learning Research12 (2011), 2825–2830
work page 2011
-
[39]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
-
[40]
DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC)
-
[41]
Yixin Song, Zeyu Mi, Haotong Xie, and Haibo Chen. 2024. Powerinfer: Fast large language model serving with a consumer-grade gpu. In Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles. 590–606
work page 2024
- [42]
-
[43]
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. 2025. Dynamollm: Designing llm inference clusters for per- formance and energy efficiency. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 1348–1362
work page 2025
-
[44]
vLLM Project. 2025. Disaggregated Prefill V1.https://docs.vllm.ai/en/ latest/features/disagg_prefill.html
work page 2025
-
[45]
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. 2024. Loongserve: Efficiently serving long-context large language models with elastic sequence parallelism. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles. 640–654
work page 2024
-
[46]
Jie You, Jae-Won Chung, and Mosharaf Chowdhury. 2023. Zeus: Un- derstanding and optimizing {GPU } energy consumption of {DNN} training. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). 119–139
work page 2023
-
[47]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A distributed serving system for {Transformer-Based} generative models. InProc. of USENIX OSDI. 521–538
work page 2022
-
[48]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. InProc. of USENIX OSDI(2024). 193–210. Appendix A Placement Configurations Table 2 lists the full Tier 1 placement plans used in the time-varying produ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.