Recognition: 2 theorem links
· Lean TheoremRethinking LoRA for Privacy-Preserving Federated Learning in Large Models
Pith reviewed 2026-05-15 20:05 UTC · model grok-4.3
The pith
LA-LoRA decouples gradient interactions in LoRA through local alternating updates to preserve performance under differential privacy in federated learning of large models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LA-LoRA strengthens convergence guarantees by performing alternating local updates on the pair of low-rank matrices, thereby decoupling their gradient interactions, aligning update directions across clients, and reducing the impact of compounded differential-privacy noise on the sharpness of the aggregated global model, which in turn yields state-of-the-art accuracy on both Swin Transformer and RoBERTa under strict privacy constraints.
What carries the argument
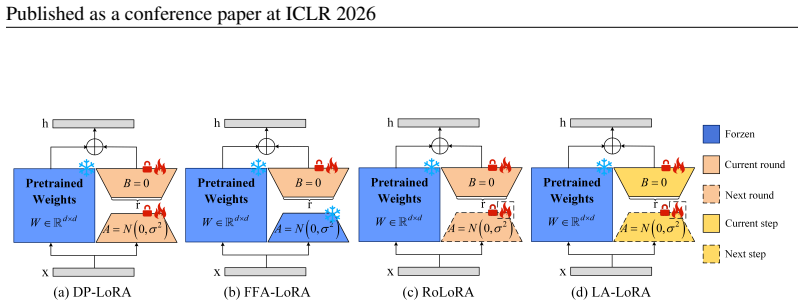
Local alternating LoRA (LA-LoRA) updates, which alternate optimization steps between the two asymmetric low-rank matrices on each client's private data before aggregation to break gradient coupling.
If this is right
- Convergence bounds hold under the added noise of differential privacy without requiring larger privacy budgets.
- The same alternating pattern delivers SOTA results on both large vision transformers and language models.
- Model sharpness after aggregation is measurably reduced, narrowing the gap to non-private federated fine-tuning.
- No additional communication rounds or client-to-server messages are introduced beyond standard LoRA.
Where Pith is reading between the lines
- If the alternating pattern generalizes, other parameter-efficient adapters could adopt similar local decoupling to improve robustness in noisy distributed training.
- The approach may allow practitioners to maintain tighter privacy budgets while still reaching usable accuracy on models larger than those tested here.
- A natural next test would be to measure whether the same local alternation reduces the variance of client updates when data heterogeneity is high.
- The method's emphasis on local computation suggests it could combine with existing adaptive clipping or noise scaling techniques for further gains.
Load-bearing premise
The three identified challenges of gradient coupling, compounded noise, and model sharpness are the dominant reasons LoRA loses performance in DPFL, and alternating local updates can fix them without creating new side effects or extra communication.
What would settle it
An experiment that isolates each of the three challenges in turn and shows that LA-LoRA's accuracy gains vanish once any single challenge is removed or neutralized by other means.
Figures









read the original abstract
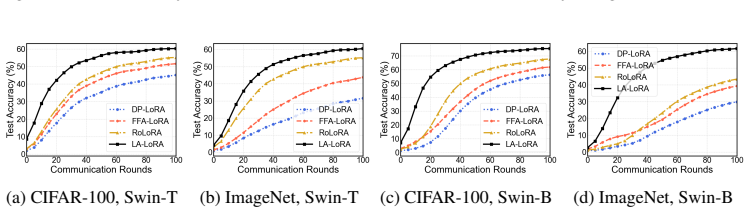
Fine-tuning large vision models (LVMs) and large language models (LLMs) under differentially private federated learning (DPFL) is hindered by a fundamental privacy-utility trade-off. Low-Rank Adaptation (LoRA), a promising parameter-efficient fine-tuning (PEFT) method, reduces computational and communication costs by introducing two trainable low-rank matrices while freezing pre-trained weights. However, directly applying LoRA in DPFL settings leads to performance degradation, especially in LVMs. Our analysis reveals three previously underexplored challenges: (1) gradient coupling caused by the simultaneous update of two asymmetric low-rank matrices, (2) compounded noise amplification under differential privacy, and (3) sharpness of the global aggregated model in the parameter space. To address these issues, we propose LA-LoRA (\textbf{L}ocal \textbf{A}lternating \textbf{LoRA}), a novel approach that decouples gradient interactions and aligns update directions across clients to enhance robustness under stringent privacy constraints. Theoretically, LA-LoRA strengthens convergence guarantees in noisy federated environments. Extensive experiments demonstrate that LA-LoRA achieves state-of-the-art (SOTA) performance on Swin Transformer and RoBERTa models, showcasing robustness to DP noise and broad applicability across both LVMs and LLMs. For example, when fine-tuning the Swin-B model on the Tiny-ImageNet dataset under a strict privacy budget ($\epsilon = 1$), LA-LoRA outperforms the best baseline, RoLoRA, by 16.83\% in test accuracy. Code is provided in \repolink.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LA-LoRA, a local alternating LoRA variant for differentially private federated learning (DPFL) of large vision and language models. It identifies three challenges with standard LoRA under DPFL—gradient coupling from simultaneous updates of the two low-rank matrices, compounded noise amplification, and increased sharpness of the aggregated model—and claims that decoupling the matrices via local alternating updates mitigates them, strengthens convergence guarantees in noisy settings, and yields SOTA empirical results (e.g., +16.83% test accuracy over RoLoRA on Swin-B/Tiny-ImageNet at ε=1) without extra communication cost.
Significance. If the reported gains are shown to arise from the proposed mechanism rather than differences in total communication rounds or update frequency, and if the theoretical strengthening is made explicit, the work would meaningfully improve the privacy-utility trade-off for parameter-efficient fine-tuning of large models in federated DP settings, with applicability to both LVMs and LLMs.
major comments (2)
- [Experiments] Experiments section (results on Swin-B/Tiny-ImageNet at ε=1): the 16.83% accuracy gain over RoLoRA is reported without error bars, number of runs, or explicit statement that the total number of global communication rounds is identical to all baselines; because LA-LoRA performs alternating local updates on the two LoRA matrices, the protocol must confirm that effective update frequency and total steps remain matched, otherwise the central empirical claim is confounded.
- [Theoretical Analysis] Theoretical section: the abstract states that LA-LoRA 'strengthens convergence guarantees in noisy federated environments,' yet no theorem, proof sketch, or modified convergence bound is referenced; the claim that alternating updates improve the rate relative to standard LoRA under DP noise is load-bearing for the paper's theoretical contribution and requires explicit derivation or key assumptions.
minor comments (1)
- [Abstract] Abstract: the repository link is given only as 'repolink'; replace with a concrete URL or placeholder that will be expanded in the camera-ready version.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address the two major points below and will incorporate revisions to strengthen both the experimental reporting and the theoretical presentation.
read point-by-point responses
-
Referee: [Experiments] Experiments section (results on Swin-B/Tiny-ImageNet at ε=1): the 16.83% accuracy gain over RoLoRA is reported without error bars, number of runs, or explicit statement that the total number of global communication rounds is identical to all baselines; because LA-LoRA performs alternating local updates on the two LoRA matrices, the protocol must confirm that effective update frequency and total steps remain matched, otherwise the central empirical claim is confounded.
Authors: We agree that these details are necessary for reproducibility and to rule out confounding factors. In the revised manuscript we will: (i) report mean and standard deviation over 5 independent runs with different random seeds for all methods on the Swin-B/Tiny-ImageNet experiment at ε=1; (ii) explicitly state that the total number of global communication rounds is identical across baselines and LA-LoRA; and (iii) add a protocol description clarifying that the alternation between the two LoRA matrices occurs entirely locally within each client’s local epochs and does not increase the number of communication rounds or effective update frequency. Each global round still consists of one model upload and one download per client. revision: yes
-
Referee: [Theoretical Analysis] Theoretical section: the abstract states that LA-LoRA 'strengthens convergence guarantees in noisy federated environments,' yet no theorem, proof sketch, or modified convergence bound is referenced; the claim that alternating updates improve the rate relative to standard LoRA under DP noise is load-bearing for the paper's theoretical contribution and requires explicit derivation or key assumptions.
Authors: We acknowledge that the current manuscript presents an informal analysis of how alternating updates reduce gradient coupling and noise amplification (Section 4) but does not contain a formal theorem or proof sketch. In the revision we will add a dedicated subsection that states a convergence theorem under standard assumptions (L-smoothness, bounded gradients, and Gaussian DP noise), derives the modified convergence bound showing a reduced noise-dependent term for LA-LoRA relative to simultaneous LoRA updates, and includes a proof sketch. This will make the theoretical strengthening explicit while preserving the paper’s overall length. revision: yes
Circularity Check
No circularity: derivation and claims remain self-contained
full rationale
The paper identifies three challenges (gradient coupling, noise amplification, model sharpness) and proposes LA-LoRA with local alternating updates to decouple matrices. No equations, convergence claims, or performance results reduce by construction to fitted parameters, self-citations, or renamed inputs. Theoretical strengthening of guarantees is stated without load-bearing reduction to prior self-work, and reported accuracy gains (e.g., +16.83% on Swin-B) are presented as direct experimental outcomes rather than predictions forced by the method definition itself. The derivation chain is independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Differential privacy noise is added independently to each client's gradient update before aggregation.
- standard math Federated clients perform local updates on frozen pre-trained weights plus the two LoRA matrices.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2 (Closed-form projected gradients)... Theorem 4 (Convergence rate)... rank r-RIP
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LA-LoRA alternately updates noisy A and B within each local round
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Adaptive Selection of LoRA Components in Privacy-Preserving Federated Learning
AS-LoRA adaptively chooses which LoRA factor to update per layer and round using a curvature-aware second-order score, eliminating reconstruction error floors and improving performance in DP federated learning.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Image matching filtering and refinement by planes and beyond.arXiv preprint arXiv:2411.09484,
Fabio Bellavia, Zhenjun Zhao, Luca Morelli, and Fabio Remondino. Image matching filtering and refinement by planes and beyond.arXiv preprint arXiv:2411.09484,
-
[3]
Jieming Bian, Lei Wang, Letian Zhang, and Jie Xu. Fedalt: Federated fine-tuning through adaptive local training with rest-of-world lora.arXiv preprint arXiv:2503.11880, 2025a. Jieming Bian, Lei Wang, Letian Zhang, and Jie Xu. Lora-fair: Federated lora fine-tuning with aggre- gation and initialization refinement. InProceedings of the IEEE/CVF International...
-
[4]
Shuangyi Chen, Yue Ju, Hardik Dalal, Zhongwen Zhu, and Ashish Khisti. Robust federated finetun- ing of foundation models via alternating minimization of lora.arXiv preprint arXiv:2409.02346,
-
[5]
Heterogeneous lora for fed- erated fine-tuning of on-device foundation models
Yae Jee Cho, Luyang Liu, Zheng Xu, Aldi Fahrezi, and Gauri Joshi. Heterogeneous lora for fed- erated fine-tuning of on-device foundation models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 12903–12913,
work page 2024
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
Multi-level logit distillation
doi: 10.1109/CVPR52729.2023.01907. 13 Published as a conference paper at ICLR 2026 Chen Feng, Georgios Tzimiropoulos, and Ioannis Patras. SSR: An Efficient and Robust Framework for Learning with Unknown Label Noise. In33rd British Machine Vision Conference (BMVC), 11
-
[8]
Chen Feng, Georgios Tzimiropoulos, and Ioannis Patras
URLhttps://bmvc2022.mpi-inf.mpg.de/372/. Chen Feng, Georgios Tzimiropoulos, and Ioannis Patras. CLIPCleaner: Cleaning Noisy Labels with CLIP. InThe 32nd ACM International Conference on Multimedia (ACM MM), 10 2024a. doi: 10.1145/3664647.3680664. Chen Feng, Georgios Tzimiropoulos, and Ioannis Patras. NoiseBox: Towards More Efficient and Effective Learning ...
-
[9]
Pengxin Guo, Shuang Zeng, Yanran Wang, Huijie Fan, Feifei Wang, and Liangqiong Qu. Selec- tive aggregation for low-rank adaptation in federated learning.arXiv preprint arXiv:2410.01463,
-
[10]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Bert: Pre-training of deep bidirectional transformers for language understanding
14 Published as a conference paper at ICLR 2026 Jacob Devlin Ming-Wei Chang Kenton, Lee Kristina Toutanova, et al. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of naacL-HLT, volume
work page 2026
-
[12]
The Power of Scale for Parameter-Efficient Prompt Tuning
Accessed: 2025-08-05. Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning.arXiv preprint arXiv:2104.08691,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation.arXiv preprint arXiv:2101.00190,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Junkang Liu, Yuanyuan Liu, Fanhua Shang, Hongying Liu, Jin Liu, and Wei Feng. Improving gen- eralization in federated learning with highly heterogeneous data via momentum-based stochastic controlled weight averaging. InForty-second International Conference on Machine Learning, 2024a. Junkang Liu, Fanhua Shang, Yuanyuan Liu, Hongying Liu, Yuangang Li, and ...
-
[15]
Swin transformer: Hierarchical vision transformer using shifted windows
15 Published as a conference paper at ICLR 2026 Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 10012–10022,
work page 2026
-
[16]
Zhiyu Liu, Zhi Han, Yandong Tang, Hai Zhang, Shaojie Tang, and Yao Wang. Efficient over- parameterized matrix sensing from noisy measurements via alternating preconditioned gradient descent.arXiv preprint arXiv:2502.00463, 2025f. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep ...
-
[17]
doi: 10.1109/TNNLS.2024. 3417452. Ilya Mironov. R ´enyi differential privacy. InProc. IEEE computer security foundations symposium (CSF), pp. 263–275,
-
[18]
Kaichen Ouyang, Zong Ke, Shengwei Fu, Lingjie Liu, Puning Zhao, and Dayu Hu. Learn from global correlations: Enhancing evolutionary algorithm via spectral gnn.arXiv preprint arXiv:2412.17629,
-
[19]
In Forty-second International Conference on Machine Learning
Jiaxing Qi, Zhongzhi Luan, Shaohan Huang, Carol Fung, Hailong Yang, and Depei Qian. Fdlora: Personalized federated learning of large language model via dual lora tuning.arXiv preprint arXiv:2406.07925,
-
[21]
Text-driven prompt generation for vision-language models in federated learning
Chen Qiu, Xingyu Li, Chaithanya Kumar Mummadi, Madan Ravi Ganesh, Zhenzhen Li, Lu Peng, and Wan-Yi Lin. Text-driven prompt generation for vision-language models in federated learning. arXiv preprint arXiv:2310.06123,
-
[22]
Ugur Guney, Yann Dauphin, and L ´eon Bottou
16 Published as a conference paper at ICLR 2026 Levent Sagun, Utku Evci, V . Ugur Guney, Yann Dauphin, and L ´eon Bottou. Empirical analysis of the hessian of over-parametrized neural networks. InInternational Conference on Learning Representations (ICLR),
work page 2026
-
[23]
Jiyun Shin, Jinhyun Ahn, Honggu Kang, and Joonhyuk Kang. Fedsplitx: Federated split learning for computationally-constrained heterogeneous clients.arXiv preprint arXiv:2310.14579,
-
[24]
FoundationPose: Unified 6D Pose Estimation and Track- ing of Novel Objects
Youbang Sun, Zitao Li, Yaliang Li, and Bolin Ding. Improving lora in privacy-preserving federated learning.arXiv preprint arXiv:2403.12313, 2024a. Zhonglin Sun, Chen Feng, Ioannis Patras, and Georgios Tzimiropoulos. LAFS: Landmark-based Facial Self-supervised Learning for Face Recognition. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and ...
-
[25]
Chunlin Tian, Zhan Shi, Zhijiang Guo, Li Li, and Chengzhong Xu. Hydralora: An asymmetric lora architecture for efficient fine-tuning.arXiv preprint arXiv:2404.19245,
-
[26]
Glue: A multi-task benchmark and analysis platform for natural language understanding
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pp. 353–355,
work page 2018
-
[27]
Point4bit: Post training 4-bit quantization for point cloud 3d detection
Jianyu Wang, Yu Wang, Shengjie Zhao, and Sifan Zhou. Point4bit: Post training 4-bit quantization for point cloud 3d detection. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025a. Lei Wang, Jieming Bian, Letian Zhang, and Jie Xu. Adaptive lora experts allocation and selection for federated fine-tuning.arXiv preprint arXiv:...
-
[28]
Flora: Federated fine-tuning large language models with heterogeneous low-rank adaptations
Ziyao Wang, Zheyu Shen, Yexiao He, Guoheng Sun, Hongyi Wang, Lingjuan Lyu, and Ang Li. Flora: Federated fine-tuning large language models with heterogeneous low-rank adaptations. arXiv preprint arXiv:2409.05976,
-
[29]
Shuang Wu, Heng Liang, Yong Zhang, Yanlin Chen, and Ziyu Jia. A cross-modal densely guided knowledge distillation based on modality rebalancing strategy for enhanced unimodal emotion recognition. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2025, Montreal, Canada, August 16–22, 2025, pp. 4236–4244,
work page 2025
-
[30]
Zequn Xie. Conquer: Context-aware representation with query enhancement for text-based person search.arXiv preprint arXiv:2601.18625,
-
[31]
Chat-driven text generation and interaction for person retrieval
Zequn Xie, Chuxin Wang, Yeqiang Wang, Sihang Cai, Shulei Wang, and Tao Jin. Chat-driven text generation and interaction for person retrieval. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 5259–5270,
work page 2025
-
[32]
Zequn Xie, Xin Liu, Boyun Zhang, Yuxiao Lin, Sihang Cai, and Tao Jin. Hvd: Human vision-driven video representation learning for text-video retrieval.arXiv preprint arXiv:2601.16155, 2026a. Zequn Xie, Boyun Zhang, Yuxiao Lin, and Tao Jin. Delving deeper: Hierarchical visual perception for robust video-text retrieval.arXiv preprint arXiv:2601.12768, 2026b....
-
[33]
Emerg- ing safety attack and defense in federated instruction tuning of large language models
17 Published as a conference paper at ICLR 2026 Rui Ye, Jingyi Chai, Xiangrui Liu, Yaodong Yang, Yanfeng Wang, and Siheng Chen. Emerg- ing safety attack and defense in federated instruction tuning of large language models. In The Thirteenth International Conference on Learning Representations,
work page 2026
-
[34]
Sixing Yu, J Pablo Mu ˜noz, and Ali Jannesari
URLhttps: //openreview.net/forum?id=sYNWqQYJhz. Sixing Yu, J Pablo Mu ˜noz, and Ali Jannesari. Bridging the gap between foundation models and heterogeneous federated learning.arXiv preprint arXiv:2310.00247,
-
[35]
Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models.arXiv preprint arXiv:2106.10199,
-
[36]
Riemannian preconditioned lora for fine-tuning foundation mod- els.arXiv preprint arXiv:2402.02347,
Fangzhao Zhang and Mert Pilanci. Riemannian preconditioned lora for fine-tuning foundation mod- els.arXiv preprint arXiv:2402.02347,
-
[37]
Towards building the federatedgpt: Federated instruction tuning
Jianyi Zhang, Saeed Vahidian, Martin Kuo, Chunyuan Li, Ruiyi Zhang, Tong Yu, Guoyin Wang, and Yiran Chen. Towards building the federatedgpt: Federated instruction tuning. InICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6915–6919. IEEE, 2024a. Xinwei Zhang, Zhiqi Bu, Mingyi Hong, and Meisam Razaviy...
work page 2024
-
[38]
The" PC1-PC2 3 0 3 3 0 3 PC3-PC4 1 0 1 4 0 4 PC5-PC6 10 0 10 4 0 4 T oken:
doi: 10.48550/arXiv. 2601.22579. URLhttps://arxiv.org/abs/2601.22579. Sifan Zhou. Comptrack: Information bottleneck-guided low-rank dynamic token compression for point cloud tracking. InThe Fortieth AAAI Conference on Artificial Intelligence,
work page internal anchor Pith review doi:10.48550/arxiv
-
[39]
URL https://openreview.net/forum?id=nXExYROmVe. Sifan Zhou, Zhi Tian, Xiangxiang Chu, Xinyu Zhang, Bo Zhang, Xiaobo Lu, Chengjian Feng, Zequn Jie, Patrick Yin Chiang, and Lin Ma. Fastpillars: A deployment-friendly pillar-based 3d detector. arXiv preprint arXiv:2302.02367,
-
[40]
LiDAR-PTQ: Post-training quantization for point cloud 3d object detection
Sifan Zhou, Liang Li, Xinyu Zhang, Bo Zhang, Shipeng Bai, Miao Sun, Ziyu Zhao, Xiaobo Lu, and Xiangxiang Chu. LiDAR-PTQ: Post-training quantization for point cloud 3d object detection. 2024a. Sifan Zhou, Zhihang Yuan, Dawei Yang, Ziyu Zhao, Xing Hu, Yuguang Shi, Xiaobo Lu, and Qiang Wu. Information entropy guided height-aware histogram for quantization-fr...
-
[41]
Method Time Cost (s) Memory Cost (MB) Test Accuracy (%) CIFAR-100 Tiny-ImageNet CIFAR-100 Tiny-ImageNet CIFAR-100 Tiny-ImageNet DP-LoRA 30.35 28.02 3524 3524 55.98 30.20 DP-LoRA(+filter) 30.72 28.51 3524 3524 67.95 48.09 FFA-LoRA 17.85 16.54 1762 1762 61.94 39.33 RoLoRA 16.64 16.32 1762 1762 67.88 43.85 LA-LoRA(-filter) 17.30 17.16 1762 1762 69.87 52.72 L...
work page 2026
-
[42]
“Grad. Cos. (late)” denotes the average cosine similarity between∇ ALand∇ BLover the last 10% of training steps. Federated DP-LoRA has lower test accuracy and gradient cosine than centralized DP-LoRA, while LA-LoRA(-filter) improves both settings. Setting Method Test Acc. (%)∆Acc Grad. Cos. (late)∆Cos Centralized DP-LoRA76.11 ±0.38 - 0.681 - LA-LoRA(-filt...
work page 2026
-
[43]
For privacy parameters, we setδ= 1e−5for SST-2 and QNLI, andδ= 1e−6for QQP and MNLI to account for their larger dataset sizes. The noise multipliers corresponding to privacy budgets ϵ∈ {3,2,1}are: •SST-2:σ∈ {0.36,0.53,1.0}, •QNLI:σ∈ {0.23,0.34,0.67}, •QQP:σ∈ {0.073,0.11,0.21}, •MNLI:σ∈ {0.067,0.10,0.195}. 23 Published as a conference paper at ICLR 2026 Gr...
work page 2026
-
[44]
Table 4 summarizes the corresponding final test accuracies
Figure 9, Figure 10, and Figure 11 present the convergence curves of LA-LoRA and three SOTA baselines (DP-LoRA, FFA-LoRA, RoLoRA) on SST-2, QNLI, QQP, and MNLI using RoBERTa- Base under different privacy budgets (ϵ∈ {1,2,3}). Table 4 summarizes the corresponding final test accuracies. Across all settings, LA-LoRA consistently achieves the highest accuracy...
work page 2026
-
[45]
Table 13 summarizes the performance of all baselines and LA-LoRA variants on GLUE tasks
Model Method SST-2 QNLI QQP MNLI Avg Llama-2-7B DP-LoRA91.56 88.22 85.56 86.86 88.05 FFA-LoRA92.53 89.23 85.56 86.98 88.58 RoLoRA92.12 89.34 85.98 87.21 88.66 LA-LoRA93.36 89.78 86.75 87.56 89.36 B.5 LANGUAGE MODEL RESULTS UNDER DATA HETEROGENEITYβ= 0.3 We report additional results of language tasks under Dirichletβ= 0.3. Table 13 summarizes the performan...
work page 2026
-
[46]
Method GLUE tasks (RoBERTa-Base) Image Classification (Swin-B) QQP MNLI CIFAR-100 Tiny-ImageNet DP-LoRA 84.56±0.83 80.98±0.44 56.52±0.51 30.64±0.30 DP-LoRA(+filter) 84.79±0.42 81.43±0.57 69.08±0.52 49.85±0.55 DP-LoRA(+Doppler) 84.82±0.49 81.04±0.57 66.12±0.71 48.53±0.57 LA-LoRA(-filter) 84.98±0.51 82.40±0.53 70.38±0.48 53.07±0.60 LA-LoRA 85.83±0.49 82.99±...
work page 2026
-
[47]
We report test accuracy (%) and the maximum Hessian eigenvalueλ max(H)on LoRA parameters. Method GLUE tasks (RoBERTa-Base) Image Classification (Swin-B) QQPλ max(H) CIFAR-100λ max(H) DP-LoRA 84.02 43.74 55.98 101.62 DP-LoRA(+filter) 85.63 41.36 (↓2.38) 67.95 80.33 (↓21.29) LA-LoRA(-filter) 85.95 40.82 (↓2.92) 69.87 64.77 (↓36.85) LA-LoRA 86.4140.22 (↓3.52...
work page 2026
-
[48]
All kernel choices provide a large gain over the DP-LoRA baseline (Table 3)
The performance of LA-LoRA remains stable across these configurations: the test accuracy varies within at most0.97%. All kernel choices provide a large gain over the DP-LoRA baseline (Table 3). Among the three variants, the 5-tap kernelG (5) s achieves the best overall trade-off between accuracy and efficiency, and thus is used as the default in all main ...
work page 2022
-
[49]
As discussed in Section 3, simultaneous updates ofAandBsuffer from gradient coupling (Eq
E.2 CLOSED-FORM PROJECTED GRADIENTS We present a projection-based view to explain why the proposed local alternating update improves optimization stability compared to standard LoRA. As discussed in Section 3, simultaneous updates ofAandBsuffer from gradient coupling (Eq. 3), amplified noise (Eq. 4), and sharper aggregated solutions. In contrast, LA-LoRA ...
work page 2026
-
[50]
and0≤η≤ 1 1+δr+ 1 P , then LA-LoRA without momentum solves the over- parameterized problem leads to Lc(Bk+1,A k+1)≤(1−η c)2Lc(Bk,A k),(42) and PX i Bi kAi k −X ⋆ 2 F ≤ 1 +δ r 1−δ r (1−η c)2t PX i Bi 0Ai 0 −X ⋆ 2 F ,(43) whereη c = 2P(1−δ r) η− η2(1+δr+ 1 P ) 2 . Proof. Lc(Bk+1,A k+1)≤ L c(Bk,A k+1)− η− η2(1 +δ r + 1 P ) 2 Pmax i ∇Bi k Lc(Bk,A k+1) 2 P ⋆ A...
work page 2026
-
[51]
FFA-LoRA: fixed row-space subspace.FFA-LoRA freezesAat some initializationA 0 and only updatesB. At iterationkwe can write Wk =W 0 +sB kA0, so Wk −W 0 ∈ S0 withS 0 ={∆W∈R m×n : row(∆W)⊆r(A 0)}. LetW ⋆ be a target (e.g., optimal) rank-rsolution. IfW ⋆ −W 0 /∈ S0, then by projection geometry inf k ∥Wk −W ⋆∥F ≥inf ∆W∈S 0 ∥∆W−(W ⋆ −W 0)∥F = dist(W ⋆ −W 0,S 0)...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.