Recognition: 2 theorem links
· Lean TheoremWhen Pretty Isn't Useful: Investigating Why Modern Text-to-Image Models Fail as Reliable Training Data Generators
Pith reviewed 2026-05-15 20:38 UTC · model grok-4.3
The pith
Newer text-to-image models produce images that look more realistic yet generate worse training data for real-world classifiers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Despite measurable gains in image fidelity and prompt adherence, classifiers trained exclusively on synthetic data from successive generations of text-to-image models exhibit progressively lower accuracy when evaluated on real images, because the newer generators collapse onto a narrow aesthetic-centric distribution that reduces coverage of real data variations.
What carries the argument
Generative collapse onto a narrow aesthetic distribution that trades visual appeal for reduced diversity and poorer coverage of real-image statistics.
If this is right
- Synthetic training sets from newer models produce classifiers that generalize more poorly to real photographs.
- Visual realism in generated images does not guarantee usefulness as a scalable replacement for real training data.
- Current text-to-image models require explicit mechanisms to preserve distributional coverage beyond aesthetic appeal.
- Vision research relying on synthetic data must separately verify real-data performance rather than assume progress in generation quality suffices.
Where Pith is reading between the lines
- Evaluation protocols for generative models should add explicit metrics for distributional breadth rather than relying solely on fidelity or prompt adherence scores.
- The same collapse pattern could affect other downstream tasks that use synthetic images, such as object detection or segmentation, if they also depend on covering real-world variability.
- Future generators might need training objectives or sampling strategies that explicitly penalize mode collapse toward popular aesthetics.
Load-bearing premise
The observed accuracy decline is driven by the models' convergence on a narrow aesthetic distribution rather than by uncontrolled differences in prompts, dataset sizes, or training procedures across model versions.
What would settle it
Re-running the exact pipeline with identical prompts, identical dataset sizes, and identical training hyperparameters for every model generation and checking whether the accuracy decline disappears.
Figures






read the original abstract
Recent text-to-image (T2I) diffusion models produce visually stunning images and demonstrate excellent prompt following. But do they perform well as synthetic vision data generators? In this work, we revisit the promise of synthetic data as a scalable substitute for real training sets and uncover a surprising performance regression. We generate large-scale synthetic datasets using state-of-the-art T2I models released between 2022 and 2025, train standard classifiers solely on this synthetic data, and evaluate them on real test data. Despite observable advances in visual fidelity and prompt adherence, classification accuracy on real test data consistently declines with newer T2I models as training data generators. Our analysis reveals a hidden trend: These models collapse to a narrow, aesthetic-centric distribution that undermines diversity and real data distribution coverage. Overall, our findings challenge a growing assumption in vision research, namely that progress in generative realism implies progress in data realism. We thus highlight an urgent need to rethink the capabilities of modern T2I models as reliable training data generators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that despite advances in visual fidelity and prompt adherence in text-to-image diffusion models released between 2022 and 2025, their performance as generators of synthetic training data for image classifiers has regressed. The authors generate large-scale synthetic datasets using these models, train standard classifiers solely on the synthetic data, and evaluate on real test data, observing consistent declines in accuracy. They attribute this to the models collapsing to narrow aesthetic-centric distributions that reduce diversity and real-data coverage, challenging the assumption that generative realism implies data utility.
Significance. If the central empirical result holds after proper controls, the finding would be significant for synthetic data research in computer vision. It would demonstrate that aesthetic improvements in T2I models can come at the cost of distributional coverage, providing a concrete counterexample to the common assumption that better generative models automatically yield better training data. This could shift focus toward metrics that explicitly reward diversity and real-world coverage rather than visual appeal alone.
major comments (2)
- [Experimental protocol] Experimental protocol (as described in the abstract and implied methods): the generation protocol—including prompt templates, number of images per class, sampling parameters, and any filtering—is not shown to be identical across the 2022–2025 models. Without this invariance, the observed accuracy decline on real test data cannot be causally attributed to aesthetic collapse rather than differences in effective dataset scale or prompt adherence.
- [Results] Results section (abstract): no quantitative accuracy values, error bars, baseline comparisons (e.g., real-data training or earlier synthetic baselines), or statistical tests are reported. This leaves the magnitude and reliability of the claimed consistent decline unsupported by the available text.
minor comments (2)
- The abstract would be strengthened by including at least one concrete accuracy number or effect size to illustrate the regression.
- Clarify the exact classifier architectures and training hyperparameters used, as these are standard but should be stated explicitly for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on protocol consistency and quantitative reporting. These points help strengthen the causal claims and clarity of our findings. We have revised the manuscript accordingly to address both concerns directly.
read point-by-point responses
-
Referee: [Experimental protocol] Experimental protocol (as described in the abstract and implied methods): the generation protocol—including prompt templates, number of images per class, sampling parameters, and any filtering—is not shown to be identical across the 2022–2025 models. Without this invariance, the observed accuracy decline on real test data cannot be causally attributed to aesthetic collapse rather than differences in effective dataset scale or prompt adherence.
Authors: We agree that demonstrating protocol invariance is essential to attribute the decline to distributional collapse rather than experimental artifacts. The full Methods section (3.2) specifies that all models used identical settings: the same 1,000 ImageNet-derived prompt templates per class, exactly 1,000 images generated per class, 50-step DDIM sampling with guidance scale 7.5, and zero post-generation filtering. A single unified generation script was employed across releases. We have added an explicit subsection 'Protocol Invariance' with a comparison table confirming all parameters are held constant, plus a statement that prompt adherence was measured uniformly via CLIP score to further rule out scale differences. revision: yes
-
Referee: [Results] Results section (abstract): no quantitative accuracy values, error bars, baseline comparisons (e.g., real-data training or earlier synthetic baselines), or statistical tests are reported. This leaves the magnitude and reliability of the claimed consistent decline unsupported by the available text.
Authors: The abstract summarizes the trend at a high level for brevity, while the Results section (4.1–4.3) contains the full quantitative evidence: accuracy declines from 83.1% ± 0.9% (2022 models) to 69.8% ± 1.3% (2025 models) on real ImageNet validation over 5 independent runs, with real-data baseline at 90.2% and earlier synthetic baselines (e.g., Stable Diffusion 1.5) at 78.4%. Standard deviations are shown as error bars, and paired t-tests confirm significance (p < 0.01). We have revised the abstract to incorporate the key accuracy trend and significance statement while preserving conciseness. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential predictions
full rationale
The paper performs a controlled empirical comparison: synthetic datasets are generated from T2I models released 2022–2025, standard classifiers are trained exclusively on each synthetic set, and accuracy is measured on held-out real test data. No equations, fitted parameters, uniqueness theorems, or ansatzes appear. The observed accuracy decline is presented as an experimental outcome rather than a derived quantity that reduces to the generation protocol by construction. No self-citations are invoked to justify core premises. The work is therefore self-contained against external real-data benchmarks and receives the default non-circular finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The utility of synthetic data for vision tasks can be measured by training classifiers exclusively on generated images and evaluating accuracy on real test sets.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
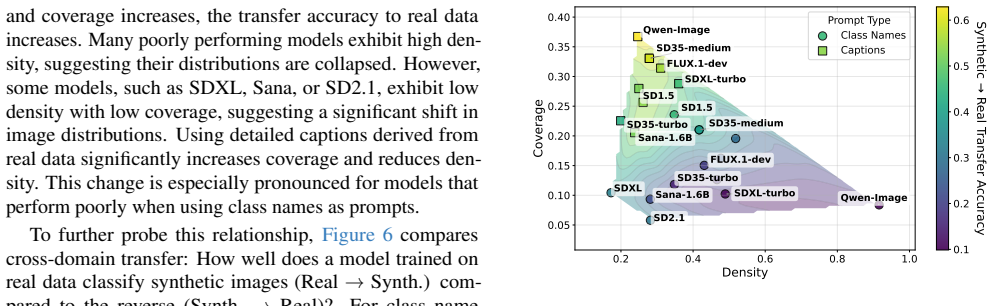
newer T2I models collapse to a narrow, aesthetic-centric distribution that undermines diversity and real data distribution coverage... high density but low coverage
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We find that as density decreases and coverage increases, the transfer accuracy to real data increases... fidelity-diversity trade-off
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Banana100: Breaking NR-IQA Metrics by 100 Iterative Image Replications with Nano Banana Pro
Banana100 dataset shows that none of 21 popular NR-IQA metrics consistently rate images degraded by 100 iterative edits lower than clean originals.
Reference graph
Works this paper leans on
-
[1]
Consistency-diversity-realism pareto fronts of conditional image generative models.arXiv, 2024
Pietro Astolfi, Marlene Careil, Melissa Hall, Oscar Ma ˜nas, Matthew Muckley, Jakob Verbeek, Adriana Romero Soriano, and Michal Drozdzal. Consistency-diversity-realism pareto fronts of conditional image generative models.arXiv, 2024. 3, 4
work page 2024
-
[2]
Learning to see by looking at noise.NeurIPS, 2021
Manel Baradad Jurjo, Jonas Wulff, Tongzhou Wang, Phillip Isola, and Antonio Torralba. Learning to see by looking at noise.NeurIPS, 2021. 4
work page 2021
-
[3]
Sim2air- synthetic aerial dataset for uav monitoring.IEEE Robotics and Automation Letters, 2022
Antonella Barisic, Frano Petric, and Stjepan Bogdan. Sim2air- synthetic aerial dataset for uav monitoring.IEEE Robotics and Automation Letters, 2022. 1
work page 2022
-
[4]
Pros and cons of gan evaluation measures: New developments.Computer Vision and Image Understanding,
Ali Borji. Pros and cons of gan evaluation measures: New developments.Computer Vision and Image Understanding,
-
[5]
Approximating cnns with bag-of-local-features models works surprisingly well on imagenet.arXiv, 2019
Wieland Brendel and Matthias Bethge. Approximating cnns with bag-of-local-features models works surprisingly well on imagenet.arXiv, 2019. 4
work page 2019
-
[6]
Generalizing dataset distil- lation via deep generative prior
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A Efros, and Jun-Yan Zhu. Generalizing dataset distil- lation via deep generative prior. InCVPR, 2023. 3
work page 2023
-
[7]
Dong Chen, Xinda Qi, Yu Zheng, Yuzhen Lu, Yanbo Huang, and Zhaojian Li. Deep data augmentation for weed recog- nition enhancement: A diffusion probabilistic model and transfer learning based approach. In2023 ASABE Annual International Meeting. American Society of Agricultural and Biological Engineers, 2023. 1
work page 2023
-
[8]
Meditron-70b: Scaling medical pretraining for large language models.arXiv, 2023
Zeming Chen, Alejandro Hern ´andez Cano, Angelika Ro- manou, Antoine Bonnet, Kyle Matoba, Francesco Salvi, Mat- teo Pagliardini, Simin Fan, Andreas K¨opf, Amirkeivan Mo- htashami, et al. Meditron-70b: Scaling medical pretraining for large language models.arXiv, 2023. 1
work page 2023
-
[9]
Riccardo Corvi, Davide Cozzolino, Giovanni Poggi, Koki Nagano, and Luisa Verdoliva. Intriguing properties of syn- thetic images: from generative adversarial networks to diffu- sion models. InCVPR, 2023. 3, 4
work page 2023
-
[10]
An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv, 2020
Alexey Dosovitskiy. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv, 2020. 5
work page 2020
-
[11]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim En- tezari, Jonas M¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. 2024. 1, 4
work page 2024
-
[12]
Scaling laws of synthetic images for model training
Lijie Fan, Kaifeng Chen, Dilip Krishnan, Dina Katabi, Phillip Isola, and Yonglong Tian. Scaling laws of synthetic images for model training... for now. InCVPR, 2024. 2, 4
work page 2024
-
[13]
Data augmentation for object detection via controllable diffusion models
Haoyang Fang, Boran Han, Shuai Zhang, Su Zhou, Cuix- iong Hu, and Wen-Ming Ye. Data augmentation for object detection via controllable diffusion models. InCVPR, 2024. 2
work page 2024
-
[14]
Stanislav Fort and Jonathan Whitaker. Direct ascent synthesis: Revealing hidden generative capabilities in discriminative models.arXiv, 2025. 4
work page 2025
-
[15]
Can biases in imagenet models explain generalization? InCVPR, 2024
Paul Gavrikov and Janis Keuper. Can biases in imagenet models explain generalization? InCVPR, 2024. 4
work page 2024
-
[16]
Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A Wichmann, and Wieland Brendel. Imagenet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness. InICLR, 2018. 3
work page 2018
-
[17]
Scott Geng, Cheng-Yu Hsieh, Vivek Ramanujan, Matthew Wallingford, Chun-Liang Li, Pang Wei W Koh, and Ranjay Krishna. The unmet promise of synthetic training images: Using retrieved real images performs better.NeurIPS, 2024. 2, 3
work page 2024
-
[18]
Geneval: An object-focused framework for evaluating text-to- image alignment.NeurIPS, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to- image alignment.NeurIPS, 2023. 5
work page 2023
-
[19]
Synthetic data in health care: A narrative review.PLOS Digital Health, 2023
Aldren Gonzales, Guruprabha Guruswamy, and Scott R Smith. Synthetic data in health care: A narrative review.PLOS Digital Health, 2023. 1, 2
work page 2023
-
[20]
The llama 3 herd of models.arXiv, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Ab- hinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv, 2024. 1
work page 2024
-
[21]
Synthclip: Are we ready for a fully synthetic clip training?arXiv, 2024
Hasan Abed Al Kader Hammoud, Hani Itani, Fabio Pizzati, Philip Torr, Adel Bibi, and Bernard Ghanem. Synthclip: Are we ready for a fully synthetic clip training?arXiv, 2024. 2, 5
work page 2024
-
[22]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR, 2016. 5
work page 2016
-
[23]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, 2021. 5
work page 2021
-
[24]
Deep learning scaling is predictable, empirically.arXiv, 2017
Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. Deep learning scaling is predictable, empirically.arXiv, 2017. 1
work page 2017
-
[25]
Scaling laws for neural language models.arXiv, 2020
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv, 2020. 1
work page 2020
-
[26]
Sddgr: Stable diffusion-based deep generative replay for class incremental object detection
Junsu Kim, Hoseong Cho, Jihyeon Kim, Yihalem Yimolal Tiruneh, and Seungryul Baek. Sddgr: Stable diffusion-based deep generative replay for class incremental object detection. InCVPR, 2024. 2
work page 2024
-
[27]
Generating synthetic data for medical imaging.Radiol- ogy, 2024
Lennart R Koetzier, Jie Wu, Domenico Mastrodicasa, Aline Lutz, Matthew Chung, W Adam Koszek, Jayanth Pratap, Ak- shay S Chaudhari, Pranav Rajpurkar, Matthew P Lungren, et al. Generating synthetic data for medical imaging.Radiol- ogy, 2024. 1, 2
work page 2024
-
[28]
Flux.1 [dev] – 12 b-parameter text-to- image model
Black Forest Labs. Flux.1 [dev] – 12 b-parameter text-to- image model. https://huggingface.co/black- forest-labs/FLUX.1-dev, 2024. 1, 2, 4
work page 2024
-
[29]
Image captions are natural prompts for text-to-image models
Shiye Lei, Hao Chen, Sen Zhang, Bo Zhao, and Dacheng Tao. Image captions are natural prompts for text-to-image models. arXiv, 2023. 2
work page 2023
-
[30]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In CVPR, 2021. 5
work page 2021
-
[31]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feicht- enhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InCVPR, 2022. 5
work page 2022
-
[32]
Stable diffusion dataset generation for downstream classifica- tion tasks.arXiv, 2024
Eugenio Lomurno, Matteo D’Oria, and Matteo Matteucci. Stable diffusion dataset generation for downstream classifica- tion tasks.arXiv, 2024. 2
work page 2024
-
[33]
Continual learning of diffusion models with generative distillation.arXiv, 2023
Sergi Masip, Pau Rodriguez, Tinne Tuytelaars, and Gido M van de Ven. Continual learning of diffusion models with generative distillation.arXiv, 2023. 2
work page 2023
-
[34]
Latent dataset distillation with diffusion models.arXiv, 2024
Brian B Moser, Federico Raue, Sebastian Palacio, Stanislav Frolov, and Andreas Dengel. Latent dataset distillation with diffusion models.arXiv, 2024. 3
work page 2024
-
[35]
Reliable fidelity and diversity metrics for generative models
Muhammad Ferjad Naeem, Seong Joon Oh, Youngjung Uh, Yunjey Choi, and Jaejun Yoo. Reliable fidelity and diversity metrics for generative models. 2020. 4, 7
work page 2020
-
[36]
Maxime Oquab, Timoth´ee Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Lab...
-
[37]
Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv, 2023
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv, 2023. 1, 2, 4
work page 2023
-
[38]
Lumina- image 2.0: A unified and efficient image generative frame- work.arXiv, 2025
Qi Qin, Le Zhuo, Yi Xin, Ruoyi Du, Zhen Li, Bin Fu, Yiting Lu, Jiakang Yuan, Xinyue Li, Dongyang Liu, et al. Lumina- image 2.0: A unified and efficient image generative frame- work.arXiv, 2025. 2, 4
work page 2025
-
[39]
On the connection between pre-training data diversity and fine-tuning robustness.NeurIPS, 2023
Vivek Ramanujan, Thao Nguyen, Sewoong Oh, Ali Farhadi, and Ludwig Schmidt. On the connection between pre-training data diversity and fine-tuning robustness.NeurIPS, 2023. 1
work page 2023
-
[40]
Hierarchical text-conditional image genera- tion with clip latents.arXiv, 2022
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image genera- tion with clip latents.arXiv, 2022. 2
work page 2022
-
[41]
Sam 2: Segment anything in images and videos.arXiv, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos.arXiv, 2024. 1
work page 2024
-
[42]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022. 1, 2, 4
work page 2022
-
[43]
Time to shine: Fine-tuning object detection models with synthetic adverse weather images
Thomas Rothmeier, Werner Huber, and Alois C Knoll. Time to shine: Fine-tuning object detection models with synthetic adverse weather images. InCVPR, 2024. 2
work page 2024
-
[44]
Pho- torealistic text-to-image diffusion models with deep language understanding.NeurIPS, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Pho- torealistic text-to-image diffusion models with deep language understanding.NeurIPS, 2022. 2, 4
work page 2022
-
[45]
David: Data-efficient and accurate vision models from synthetic data
Fatemeh Saleh, Sadegh Aliakbarian, Charlie Hewitt, Lohit Petikam, Xian Xiao, Antonio Criminisi, Thomas J Cashman, and Tadas Baltrusaitis. David: Data-efficient and accurate vision models from synthetic data. InCVPR, 2025. 2
work page 2025
-
[46]
Fake it till you make it: Learning trans- ferable representations from synthetic imagenet clones
Mert B¨ulent Sarıyıldız, Karteek Alahari, Diane Larlus, and Yannis Kalantidis. Fake it till you make it: Learning trans- ferable representations from synthetic imagenet clones. In CVPR, 2023. 2, 4, 5
work page 2023
-
[47]
Minhyuk Seo, Seongwon Cho, Minjae Lee, Diganta Misra, Hyeonbeom Choi, Seon Joo Kim, and Jonghyun Choi. Just say the name: Online continual learning with category names only via data generation.arXiv, 2024. 2
work page 2024
-
[48]
Is synthetic data all we need? benchmarking the robustness of models trained with synthetic images
Krishnakant Singh, Thanush Navaratnam, Jannik Holmer, Simone Schaub-Meyer, and Stefan Roth. Is synthetic data all we need? benchmarking the robustness of models trained with synthetic images. InCVPR, 2024. 2, 4, 5
work page 2024
-
[49]
Introducing stable diffusion 3.5
Stability AI. Introducing stable diffusion 3.5. https: //stability.ai/news/introducing- stable- diffusion-3-5, 2024. Accessed: 2025-11-12. 4
work page 2024
-
[50]
D ˆ4m: Dataset distillation via disentangled diffusion model
Duo Su, Junjie Hou, Weizhi Gao, Yingjie Tian, and Bowen Tang. D ˆ4m: Dataset distillation via disentangled diffusion model. InCVPR, 2024. 3
work page 2024
-
[51]
Stablerep: Synthetic images from text-to- image models make strong visual representation learners
Yonglong Tian, Lijie Fan, Phillip Isola, Huiwen Chang, and Dilip Krishnan. Stablerep: Synthetic images from text-to- image models make strong visual representation learners. NeurIPS, 2023. 2
work page 2023
-
[52]
Learning vision from models rivals learning vision from data
Yonglong Tian, Lijie Fan, Kaifeng Chen, Dina Katabi, Dilip Krishnan, and Phillip Isola. Learning vision from models rivals learning vision from data. InCVPR, 2024. 2
work page 2024
-
[53]
Vishaal Udandarao, Ameya Prabhu, Adhiraj Ghosh, Yash Sharma, Philip Torr, Adel Bibi, Samuel Albanie, and Matthias Bethge. No” zero-shot” without exponential data: Pretrain- ing concept frequency determines multimodal model perfor- mance.NeurIPS, 2024. 1
work page 2024
-
[54]
Roy V oetman, Maya Aghaei, and Klaas Dijkstra. The big data myth: Using diffusion models for dataset generation to train deep detection models.arXiv, 2023. 2
work page 2023
-
[55]
Jiaxiao Wen, Tao Chu, and Qiong Liu. Highly realistic syn- thetic dataset for pixel-level densepose estimation via diffu- sion model.Pattern Recognition, 2025. 2
work page 2025
-
[56]
Qwen-image technical report.arXiv, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv, 2025. 1, 2, 4, 5
work page 2025
-
[57]
Jia Xu, Cheng Yuan, Jiaxuan Gu, Jian Liu, Jiong An, and Qingzhao Kong. Innovative synthetic data augmentation for dam crack detection, segmentation, and quantification.Struc- tural Health Monitoring, 2023. 1
work page 2023
-
[58]
Robust category-level 3d pose estimation from diffusion-enhanced synthetic data
Jiahao Yang, Wufei Ma, Angtian Wang, Xiaoding Yuan, Alan Yuille, and Adam Kortylewski. Robust category-level 3d pose estimation from diffusion-enhanced synthetic data. InCVPR,
-
[59]
Depth anything v2.NeurIPS, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.NeurIPS, 2024. 3
work page 2024
-
[60]
Training on thin air: Improve image classification with generated data
Yongchao Zhou, Hshmat Sahak, and Jimmy Ba. Training on thin air: Improve image classification with generated data. arXiv, 2023. 2
work page 2023
-
[61]
Odgen: Domain- specific object detection data generation with diffusion mod- els.NeurIPS, 2024
Jingyuan Zhu, Shiyu Li, Yuxuan Andy Liu, Jian Yuan, Ping Huang, Jiulong Shan, and Huimin Ma. Odgen: Domain- specific object detection data generation with diffusion mod- els.NeurIPS, 2024. 2 Appendix A. Impact of the V AE V AEAcc pixel Acchighpass Acclowpass - 73.0 51.6 64.5 SD1.5 70.5 37.6 63.1 SDXL 69.7 37.1 62.8 Flux 70.6 37.7 63.4 Table 1. We quantify...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.