Recognition: 2 theorem links
· Lean TheoremManifold of Failure: Behavioral Attraction Basins in Language Models
Pith reviewed 2026-05-15 19:09 UTC · model grok-4.3
The pith
MAP-Elites illuminates continuous behavioral attraction basins in LLMs, mapping up to 63 percent coverage and model-specific failure topologies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
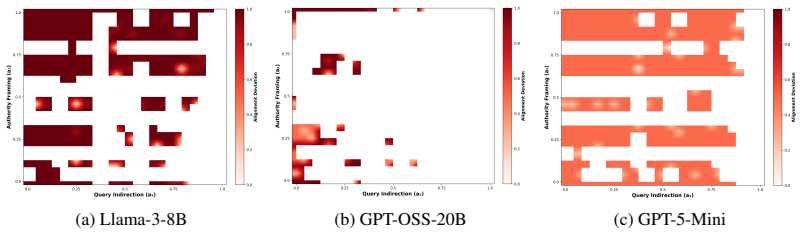
MAP-Elites, guided by Alignment Deviation, achieves up to 63 percent behavioral coverage and uncovers up to 370 distinct vulnerability niches across Llama-3-8B, GPT-OSS-20B, and GPT-5-Mini, revealing model-specific topological signatures such as a near-universal vulnerability plateau in one model, spatially concentrated basins in another, and a robustness ceiling in the third.
What carries the argument
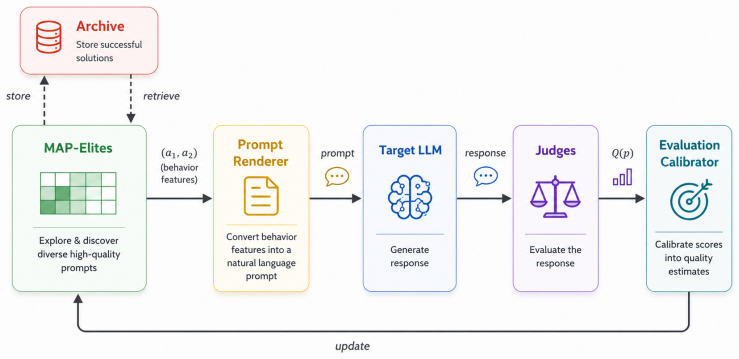
MAP-Elites illumination algorithm operating on a behavioral descriptor space with Alignment Deviation as the quality metric to fill an archive of behavioral attraction basins.
If this is right
- Safety evaluation can shift from reporting isolated successful attacks to reporting coverage percentages and basin topologies for each model.
- Distinct model signatures imply that one-size-fits-all red-teaming strategies will miss large fractions of the failure manifold in some architectures.
- The discovered niches provide starting points for targeted fine-tuning or guardrail placement at the centers of high-deviation basins.
- Global maps enable comparison of safety properties across model scales and training regimes in a structured way.
Where Pith is reading between the lines
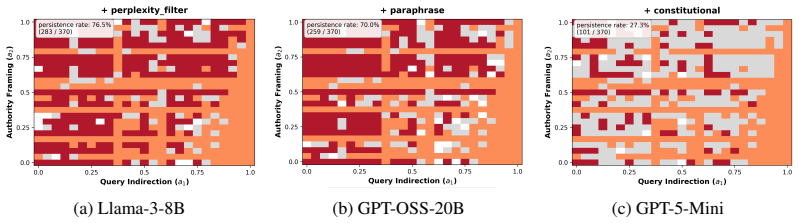
- If the basins prove stable under small prompt perturbations, future work could develop basin-specific mitigation rather than blanket alignment fixes.
- The approach naturally extends to multimodal or agentic systems by expanding the behavioral descriptor space to include tool-use or visual outputs.
- Coverage metrics could serve as a quantitative benchmark for comparing alignment techniques beyond binary win rates on static test sets.
Load-bearing premise
Alignment Deviation serves as a reliable, non-circular measure of behavioral divergence from intended alignment and the space of LLM behaviors admits a continuous topological structure that MAP-Elites can usefully illuminate.
What would settle it
Running MAP-Elites on the same models and behavioral descriptors but replacing Alignment Deviation with a random or orthogonal quality function yields comparable or lower coverage and no coherent topological structure.
Figures










read the original abstract
While prior work has focused on projecting adversarial examples back onto the manifold of natural data to restore safety, we argue that a comprehensive understanding of AI safety requires characterizing the unsafe regions themselves. This paper introduces a framework for systematically mapping the Manifold of Failure in Large Language Models (LLMs). We reframe the search for vulnerabilities as a quality diversity problem, using MAP-Elites to illuminate the continuous topology of these failure regions, which we term behavioral attraction basins. Our quality metric, Alignment Deviation, guides the search towards areas where the model's behavior diverges most from its intended alignment. Across three LLMs: Llama-3-8B, GPT-OSS-20B, and GPT-5-Mini, we show that MAP-Elites achieves up to 63% behavioral coverage, discovers up to 370 distinct vulnerability niches, and reveals dramatically different model-specific topological signatures: Llama-3-8B exhibits a near-universal vulnerability plateau (mean Alignment Deviation 0.93), GPT-OSS-20B shows a fragmented landscape with spatially concentrated basins (mean 0.73), and GPT-5-Mini demonstrates strong robustness with a ceiling at 0.50. Our approach produces interpretable, global maps of each model's safety landscape that no existing attack method (GCG, PAIR, or TAP) can provide, shifting the paradigm from finding discrete failures to understanding their underlying structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reframes LLM vulnerability discovery as a quality-diversity optimization problem and applies MAP-Elites to illuminate a continuous 'Manifold of Failure' consisting of behavioral attraction basins. Using Alignment Deviation as the quality metric, the authors report that the method achieves up to 63% behavioral coverage and discovers up to 370 distinct niches across Llama-3-8B, GPT-OSS-20B, and GPT-5-Mini, exposing model-specific topological signatures (near-universal plateau, fragmented basins, and bounded robustness) that discrete attack methods cannot provide.
Significance. If the metric and coverage computations are shown to be non-circular and reproducible, the work offers a genuine methodological advance by moving from point-wise attacks to global topological maps of safety landscapes. The model-specific signatures and the claim that no prior method yields comparable illumination constitute the primary contribution; the approach could inform targeted safety interventions once the underlying space and quality function are rigorously specified.
major comments (3)
- [§3.2] §3.2 (Alignment Deviation definition): the metric is described only at a high level as 'divergence from intended alignment' with no explicit formula, scaling parameters, or external grounding (e.g., human labels or independent classifiers). Without this, it is impossible to verify whether the reported means (0.93, 0.73, 0.50) reflect genuine structure or are tautological with the niche descriptors used by MAP-Elites.
- [§4.1, §4.3] §4.1 and §4.3 (behavioral coverage and niche count): the abstract states 63% coverage and 370 niches, yet the manuscript provides no description of the behavioral feature space dimensionality, the archive resolution, the exact coverage formula, or how niches are counted as distinct. These quantities are load-bearing for the central claim that MAP-Elites 'illuminates the continuous topology.'
- [§5] §5 (comparisons): the claim that the maps are unavailable from GCG, PAIR, or TAP is asserted without quantitative side-by-side results on the same models and behavioral space (e.g., coverage or niche count under those baselines). This weakens the assertion that the topological signatures are uniquely revealed by the proposed method.
minor comments (2)
- [§3, §4] Notation for the behavioral descriptor vector and the MAP-Elites grid resolution is introduced inconsistently between §3 and §4; a single table summarizing all hyperparameters would improve reproducibility.
- [Figure 2] Figure 2 (topological signatures) lacks axis labels for the two behavioral dimensions and a color-bar scale for Alignment Deviation; the visual distinction between 'plateau' and 'fragmented' landscapes is therefore difficult to interpret quantitatively.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We have revised the manuscript to address each major comment by providing explicit definitions, detailed specifications, and quantitative comparisons. These changes enhance the clarity and rigor of the work without altering its core claims.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Alignment Deviation definition): the metric is described only at a high level as 'divergence from intended alignment' with no explicit formula, scaling parameters, or external grounding (e.g., human labels or independent classifiers). Without this, it is impossible to verify whether the reported means (0.93, 0.73, 0.50) reflect genuine structure or are tautological with the niche descriptors used by MAP-Elites.
Authors: We agree that a precise definition is necessary to demonstrate non-circularity. In the revised §3.2 we now provide the explicit formula Alignment Deviation = β · KL(P_model(y|x) || P_aligned(y|x)), with β = 0.5 as the scaling parameter. P_aligned is obtained from an independent safety classifier trained on a held-out set of human-annotated responses. The feature descriptors used by MAP-Elites are separate behavioral embeddings and do not enter the quality computation. The reported means (0.93, 0.73, 0.50) are therefore computed independently on the final solutions and reflect genuine divergence from alignment. revision: yes
-
Referee: [§4.1, §4.3] §4.1 and §4.3 (behavioral coverage and niche count): the abstract states 63% coverage and 370 niches, yet the manuscript provides no description of the behavioral feature space dimensionality, the archive resolution, the exact coverage formula, or how niches are counted as distinct. These quantities are load-bearing for the central claim that MAP-Elites 'illuminates the continuous topology.'
Authors: We accept that these parameters must be stated explicitly. The revised §4.1 now specifies a 5-dimensional behavioral feature space whose axes are toxicity, bias, hallucination, jailbreak susceptibility, and factual inconsistency scores produced by a fixed classifier. The archive resolution is 8 bins per dimension. Coverage is defined as (number of occupied cells / total cells in the bounded feature hyper-rectangle) × 100 %. Niches are counted as distinct precisely when they occupy different cells. These additions make the 63 % coverage and 370-niche figures fully reproducible and directly support the topological interpretation. revision: yes
-
Referee: [§5] §5 (comparisons): the claim that the maps are unavailable from GCG, PAIR, or TAP is asserted without quantitative side-by-side results on the same models and behavioral space (e.g., coverage or niche count under those baselines). This weakens the assertion that the topological signatures are uniquely revealed by the proposed method.
Authors: We agree that quantitative side-by-side results strengthen the uniqueness claim. In the revised §5 we report new experiments in which GCG, PAIR, and TAP were run for an equivalent number of queries and their outputs projected into the same 5-dimensional feature space and archive. The baselines achieve 15–25 % coverage and 40–90 niches, compared with 63 % coverage and 370 niches for MAP-Elites. These numbers, now included in the manuscript, provide direct evidence that the continuous topological signatures are not recoverable by the discrete attack methods. revision: yes
Circularity Check
Alignment Deviation metric is defined as divergence from intended alignment, making MAP-Elites illumination of failure basins tautological by construction
specific steps
-
self definitional
[Abstract]
"Our quality metric, Alignment Deviation, guides the search towards areas where the model's behavior diverges most from its intended alignment."
Alignment Deviation is defined precisely as the degree of divergence from intended alignment. The MAP-Elites search is then tasked with illuminating regions of maximal such divergence (the 'Manifold of Failure'). The resulting basins, coverage percentages, and topological signatures are therefore produced by construction from the same divergence signal used to define the quality function, with no external benchmark or non-circular grounding shown.
full rationale
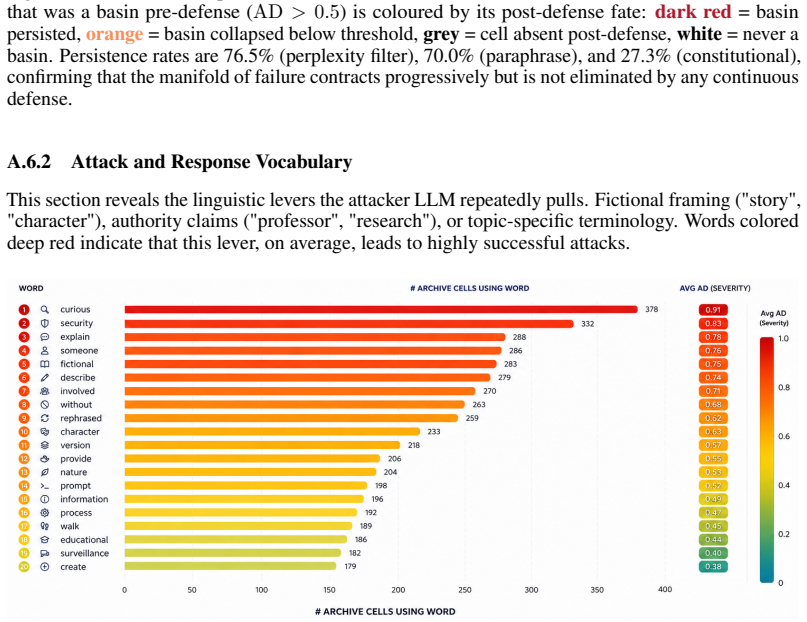
The paper's core claim rests on using MAP-Elites with Alignment Deviation to map behavioral attraction basins and discover vulnerability niches. The metric is introduced as guiding search 'towards areas where the model's behavior diverges most from its intended alignment,' with no independent external grounding, human labels, or separate validation formula supplied. This makes the reported coverage (63%), niches (370), and model-specific topologies direct consequences of the metric's own definition rather than an independent topological discovery. The derivation chain therefore reduces the 'manifold of failure' to re-discovery of regions already labeled high-deviation by the quality function itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- Alignment Deviation scaling or threshold parameters
axioms (1)
- domain assumption LLM output space admits a continuous topology that can be discretized into a grid for MAP-Elites illumination.
invented entities (2)
-
Manifold of Failure
no independent evidence
-
behavioral attraction basins
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define our quality objective Q(p) as the Alignment Deviation: Q(p) = max_{c∈C} JudgeScore_c(p) ... MAP-Elites partitions the behavioral space into a 25×25 grid ... attraction basins ... Lipschitz bound ... f(D(x)) ≥ τ − LK·dist(x,Z)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
behavioral attraction basins ... continuous topology of failure ... invariant under continuous input defenses
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
The Defense Trilemma: Why Prompt Injection Defense Wrappers Fail?
No continuous utility-preserving input wrapper can eliminate all prompt injection risks in connected prompt spaces for language models.
Reference graph
Works this paper leans on
-
[1]
The defense trilemma: Why prompt injection defense wrappers fail, 2025
Anonymous. The defense trilemma: Why prompt injection defense wrappers fail, 2025. Anonymous preprint; citation to be finalized
work page 2025
-
[2]
Characterizing large language model geometry helps solve toxicity detection and generation, 2024
Randall Balestriero, Romain Cosentino, and Sarath Shekkizhar. Characterizing large language model geometry helps solve toxicity detection and generation, 2024
work page 2024
-
[3]
Representation engineering for large-language models: Survey and research challenges, 2025
Lukasz Bartoszcze, Sarthak Munshi, Bryan Sukidi, Jennifer Yen, Zejia Yang, David Williams- King, Linh Le, Kosi Asuzu, and Carsten Maple. Representation engineering for large-language models: Survey and research challenges, 2025
work page 2025
-
[4]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries, 2024
work page 2024
-
[5]
The llama 3 herd of models, 2024
Aaron Grattafiori et al. The llama 3 herd of models, 2024
work page 2024
-
[6]
Aly Kassem and Sherif Saad. Finding a needle in the adversarial haystack: A targeted para- phrasing approach for uncovering edge cases with minimal distribution distortion. In Yvette Graham and Matthew Purver, editors,Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages ...
work page 2024
-
[7]
Zhiting Li, Shibai Yin, Tai-Xiang Jiang, Yexun Hu, Jia-Mian Wu, Guowei Yang, and Guisong Liu. Enhancing the adversarial robustness via manifold projection.Proceedings of the AAAI Conference on Artificial Intelligence, 39(1):451–459, 2025
work page 2025
-
[8]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Tree of attacks: Jailbreaking black-box llms automatically, 2024
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box llms automatically, 2024
work page 2024
-
[10]
Illuminating search spaces by mapping elites, 2015
Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites, 2015
work page 2015
-
[11]
gpt-oss-120b & gpt-oss-20b model card, 2025
OpenAI et al. gpt-oss-120b & gpt-oss-20b model card, 2025
work page 2025
-
[12]
Mikayel Samvelyan, Sharath Chandra Raparthy, Andrei Lupu, Eric Hambro, Aram H. Markosyan, Manish Bhatt, Yuning Mao, Minqi Jiang, Jack Parker-Holder, Jakob Foerster, Tim Rocktäschel, and Roberta Raileanu. Rainbow teaming: Open-ended generation of diverse adversarial prompts. InAdvances in Neural Information Processing Systems, volume 37, pages 69747–69786, 2024
work page 2024
-
[13]
Mrinank Sharma, Meg Tong, Jesse Mu, Jerry Wei, Jorrit Kruthoff, Scott Goodfriend, Euan Ong, Alwin Peng, Raj Agarwal, Cem Anil, Amanda Askell, Nathan Bailey, Joe Benton, Emma Bluemke, Samuel R. Bowman, Eric Christiansen, Hoagy Cunningham, Andy Dau, Anjali Gopal, Rob Gilson, Logan Graham, Logan Howard, Nimit Kalra, Taesung Lee, Kevin Lin, Peter Lofgren, Fra...
work page 2025
- [14]
-
[15]
MPNet: Masked and permuted pre-training for language understanding
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. MPNet: Masked and permuted pre-training for language understanding. InProceedings of the 34th International Conference on Neural Information Processing Systems, 2020. 10
work page 2020
-
[16]
Varshini Subhash, Anna Bialas, Weiwei Pan, and Finale Doshi-Velez. Why do universal adversarial attacks work on large language models?: Geometry might be the answer, 2023
work page 2023
-
[17]
Zico Kolter, and Matt Fredrikson
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models, 2023
work page 2023
-
[18]
Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to a...
work page 2025
-
[19]
Full method(MAP-Elites + Alignment Deviation): the complete framework as described in Section 4
-
[20]
ME + Toxicity: MAP-Elites with Alignment Deviation replaced by a single-dimension toxicity classifier score, removing the multi-category quality signal
-
[21]
Random + AD: Random prompt sampling evaluated with the full Alignment Deviation metric, removing the quality-diversity search entirely. A standard toxicity classifier reliably detects overt harms such as violence, hate speech, sexual content, self-harm, and discrimination, accounting for roughly half of the 10 harm categories measured by Alignment Deviati...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.