Recognition: no theorem link
Mind the Way You Select Negative Texts: Pursuing the Distance Consistency in OOD Detection with VLMs
Pith reviewed 2026-05-15 16:49 UTC · model grok-4.3
The pith
Enforcing inter-modal distance consistency when selecting negative texts improves OOD detection performance with vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
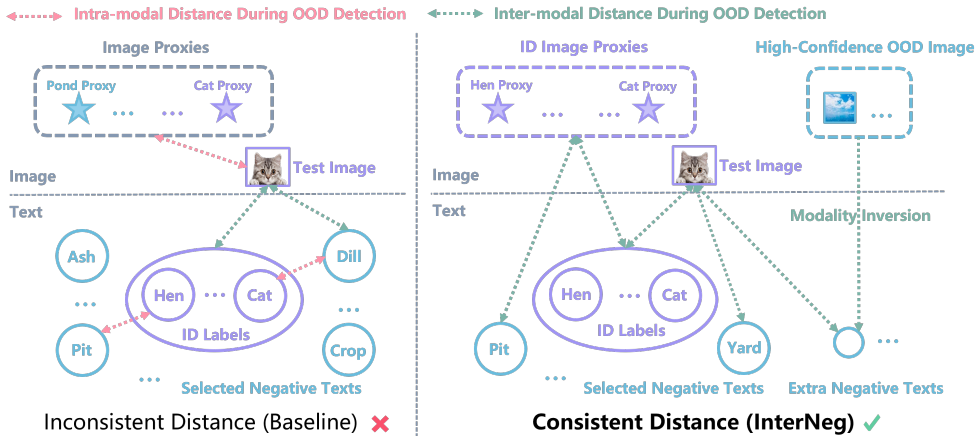
InterNeg systematically enforces inter-modal distance consistency for negative text handling in VLMs for OOD detection, using an inter-modal selection criterion from the textual view and dynamic inversion of high-confidence OOD images into negative text embeddings from the visual view, which yields superior detection performance.
What carries the argument
The InterNeg framework, which applies an inter-modal criterion to select negative texts and generates extra negative text embeddings by inverting high-confidence OOD images to maintain distance consistency.
If this is right
- Reduces false-positive rate by 3.47 percent on the large-scale ImageNet OOD benchmark
- Raises AUROC by 5.50 percent on near-OOD detection tasks
- Provides a unified textual-visual approach that avoids mixing intra- and inter-modal distances
- Demonstrates gains across multiple existing VLM-based OOD baselines
Where Pith is reading between the lines
- The consistency principle could be tested on other multi-modal architectures beyond CLIP-style models to check broader applicability
- The image-to-text inversion step might be adapted to generate negatives for additional downstream tasks such as open-vocabulary classification
- Combining the inter-modal selection rule with existing score functions could produce further incremental improvements without retraining
Load-bearing premise
That using intra-modal distances in current OOD methods creates an inherent inconsistency with VLMs' inter-modal optimization and that switching to consistent inter-modal distances will directly improve detection results.
What would settle it
A side-by-side test on the same benchmarks where an otherwise identical method replaces the inter-modal negative-text steps with intra-modal equivalents and measures whether the reported gains in FPR95 and AUROC disappear.
Figures



read the original abstract
Out-of-distribution (OOD) detection seeks to identify samples from unknown classes, a critical capability for deploying machine learning models in open-world scenarios. Recent research has demonstrated that Vision-Language Models (VLMs) can effectively leverage their multi-modal representations for OOD detection. However, current methods often incorporate intra-modal distance during OOD detection, such as comparing negative texts with ID labels or comparing test images with image proxies. This design paradigm creates an inherent inconsistency against the inter-modal distance that CLIP-like VLMs are optimized for, potentially leading to suboptimal performance. To address this limitation, we propose InterNeg, a simple yet effective framework that systematically utilizes consistent inter-modal distance enhancement from textual and visual perspectives. From the textual perspective, we devise an inter-modal criterion for selecting negative texts. From the visual perspective, we dynamically identify high-confidence OOD images and invert them into the textual space, generating extra negative text embeddings guided by inter-modal distance. Extensive experiments across multiple benchmarks demonstrate the superiority of our approach. Notably, our InterNeg achieves state-of-the-art performance compared to existing works, with a 3.47% reduction in FPR95 on the large-scale ImageNet benchmark and a 5.50% improvement in AUROC on the challenging Near-OOD benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that OOD detection methods using VLMs suffer from an inherent inconsistency by relying on intra-modal distances (e.g., negative texts vs. ID labels or test images vs. image proxies), which conflicts with the inter-modal distance optimization in CLIP-like models. It proposes InterNeg, a framework that enforces inter-modal consistency via an inter-modal criterion for negative text selection from the textual perspective and dynamic inversion of high-confidence OOD images into the textual space from the visual perspective. Experiments report state-of-the-art results, including a 3.47% FPR95 reduction on the large-scale ImageNet benchmark and a 5.50% AUROC improvement on the Near-OOD benchmark.
Significance. If the gains hold under full verification, the work is significant for OOD detection because it directly targets a training-objective mismatch in VLMs, offering a lightweight, conceptually clean enhancement that could improve reliability in open-world deployment. The concrete benchmark improvements and focus on inter-modal alignment provide a clear path for follow-up work in multi-modal robustness.
major comments (2)
- [§3] §3 (Method): The inter-modal criterion for negative text selection is presented at a high level without the explicit formulation or pseudocode; because this criterion is load-bearing for the central consistency claim, its precise definition (including any hyperparameters) must be provided to allow reproduction and to confirm it is independent of the reported performance metrics.
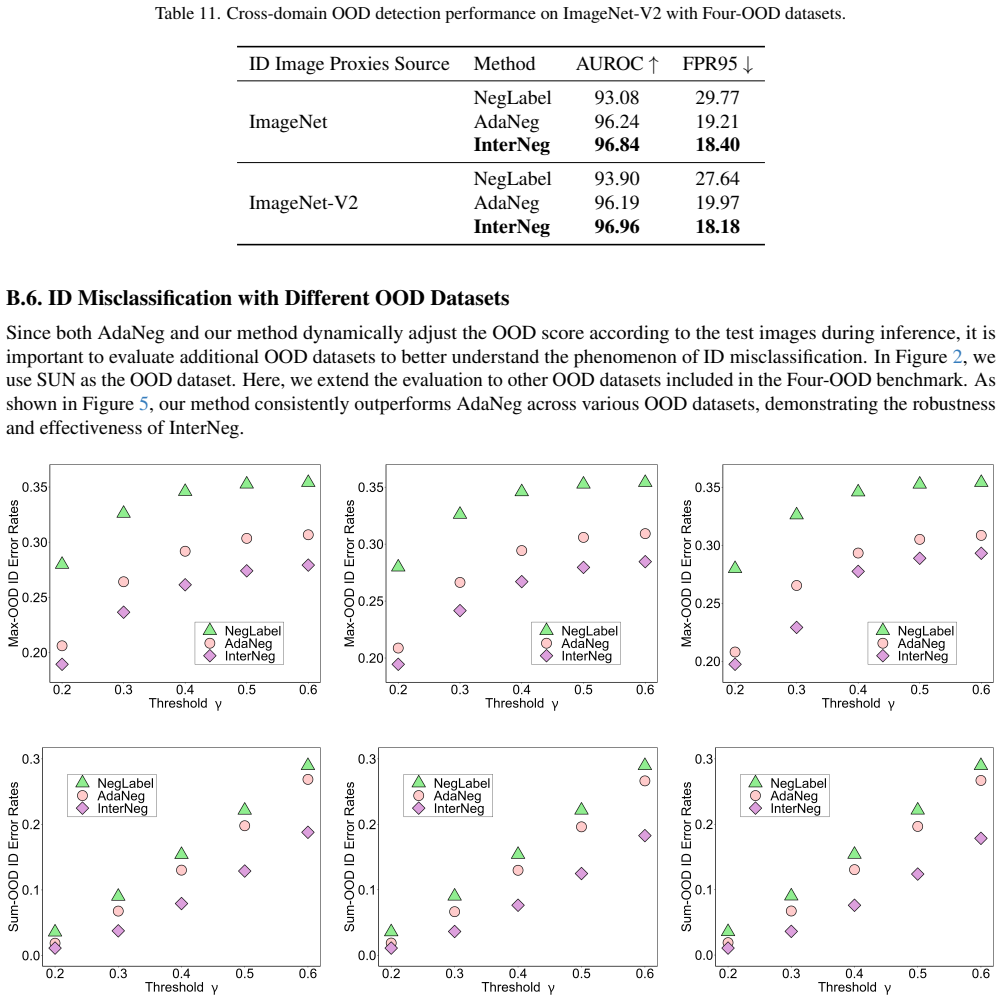
- [§4.2] §4.2 (Experiments): The dynamic OOD-image inversion step relies on a confidence threshold whose selection procedure is not detailed; given that this threshold appears as a free parameter in the method, an ablation showing sensitivity (or lack thereof) across a range of values is required to substantiate that the reported 3.47% and 5.50% gains are robust rather than tuned to the test sets.
minor comments (2)
- [Abstract / §1] The abstract and introduction use “intra-modal distance” and “inter-modal distance” without a short clarifying definition or reference to the CLIP loss; adding one sentence would improve accessibility for readers outside the immediate subfield.
- [§4] Table captions and axis labels in the benchmark results should explicitly state the number of runs or seeds used to compute the reported means and standard deviations.
Simulated Author's Rebuttal
Thank you for the detailed review and the recommendation for minor revision. We appreciate the recognition of the significance of our work on inter-modal consistency in OOD detection with VLMs. Below, we address each major comment point by point.
read point-by-point responses
-
Referee: [§3] §3 (Method): The inter-modal criterion for negative text selection is presented at a high level without the explicit formulation or pseudocode; because this criterion is load-bearing for the central consistency claim, its precise definition (including any hyperparameters) must be provided to allow reproduction and to confirm it is independent of the reported performance metrics.
Authors: We agree with the referee that the precise formulation of the inter-modal criterion is essential for reproducibility and to substantiate the consistency claim. In the revised manuscript, we will provide the explicit mathematical definition of the inter-modal distance criterion used for negative text selection. Specifically, we will include the formula that selects negative texts by maximizing the alignment between inter-modal distances and the CLIP optimization objective, along with the pseudocode for the selection algorithm. All hyperparameters, such as the number of negative texts or any scaling factors, will be clearly specified. This addition will confirm that the criterion is independent of the performance metrics and fully reproducible. revision: yes
-
Referee: [§4.2] §4.2 (Experiments): The dynamic OOD-image inversion step relies on a confidence threshold whose selection procedure is not detailed; given that this threshold appears as a free parameter in the method, an ablation showing sensitivity (or lack thereof) across a range of values is required to substantiate that the reported 3.47% and 5.50% gains are robust rather than tuned to the test sets.
Authors: We thank the referee for pointing this out. In the revised version, we will detail the procedure for selecting the confidence threshold, which is determined based on the validation set to ensure it generalizes. Additionally, we will include a comprehensive ablation study varying the threshold across a range of values (e.g., from 0.6 to 0.95) and report the corresponding OOD detection performance on the benchmarks. This will demonstrate that the reported improvements, including the 3.47% FPR95 reduction and 5.50% AUROC gain, are robust and not overly sensitive to the specific threshold choice. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces InterNeg with explicit new components—an inter-modal negative text selection criterion and dynamic image-to-text inversion for extra negatives—that are defined independently of the reported performance metrics. No equations, predictions, or derivations reduce the claimed FPR95/AUROC gains to quantities fitted from the same data or to self-referential definitions. The motivation (inconsistency between intra-modal distances and CLIP's inter-modal training) is stated directly without load-bearing self-citations or imported uniqueness theorems. The central claim rests on experimental results across benchmarks rather than any tautological reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- confidence threshold for OOD image selection
axioms (1)
- domain assumption CLIP-like VLMs are optimized primarily for inter-modal (image-text) distances rather than intra-modal distances.
Forward citations
Cited by 1 Pith paper
-
TINS: Test-time ID-prototype-separated Negative Semantics Learning for OOD Detection
TINS improves OOD detection by learning negative semantics at test time with ID-prototype separation, cutting average FPR95 from 14.04% to 6.72% on the Four-OOD benchmark with ImageNet-1K.
Reference graph
Works this paper leans on
-
[1]
Id-like prompt learning for few- shot out-of-distribution detection
Yichen Bai, Zongbo Han, Bing Cao, Xiaoheng Jiang, Qinghua Hu, and Changqing Zhang. Id-like prompt learning for few- shot out-of-distribution detection. InConference on Computer Vision and Pattern Recognition, pages 17480–17489, 2024. 1, 3, 6
work page 2024
-
[2]
Zero-shot composed image retrieval with textual inversion
Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Alberto Del Bimbo. Zero-shot composed image retrieval with textual inversion. InInternational Conference on Computer Vision, pages 15292–15301, 2023. 6
work page 2023
-
[3]
In or out? fixing imagenet out-of-distribution detection eval- uation
Julian Bitterwolf, Maximilian M¨uller, and Matthias Hein. In or out? fixing imagenet out-of-distribution detection eval- uation. InInternational Conference on Machine Learning, pages 2471–2506, 2023. 2, 6
work page 2023
-
[4]
Rishi Bommasani, Drew A. Hudson, Ehsan Adeli, Russ B. Altman, Simran Arora, Sydney von Arx, Michael S. Bernstein, Jeannette Bohg, Antoine Bosselut, and Emma Brunskill et al. On the opportunities and risks of foundation models.CoRR,
-
[5]
Envisioning outlier exposure by large language models for out-of-distribution detection
Chentao Cao, Zhun Zhong, Zhanke Zhou, Yang Liu, Tongliang Liu, and Bo Han. Envisioning outlier exposure by large language models for out-of-distribution detection. In International Conference on Machine Learning, 2024. 3, 6
work page 2024
-
[6]
Conju- gated semantic pool improves OOD detection with pre-trained vision-language models
Mengyuan Chen, Junyu Gao, and Changsheng Xu. Conju- gated semantic pool improves OOD detection with pre-trained vision-language models. InAnnual Conference on Neural Information Processing Systems, pages 82560–82593, 2024. 1, 3, 4, 6
work page 2024
-
[7]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InConference on Computer Vision and Pattern Recog- nition, pages 3606–3613, 2014. 2, 3, 6
work page 2014
-
[8]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InConference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 6
work page 2009
-
[9]
Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web].IEEE signal processing magazine, 29(6):141–142, 2012. 3
work page 2012
-
[10]
Extremely simple activation shaping for out- of-distribution detection
Andrija Djurisic, Nebojsa Bozanic, Arjun Ashok, and Rosanne Liu. Extremely simple activation shaping for out- of-distribution detection. InInternational Conference on Learning Representations, pages 1–22, 2023. 7
work page 2023
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representa- tions, pages 1–22, ...
work page 2021
-
[12]
SIREN: shaping representations for detecting out-of- distribution objects
Xuefeng Du, Gabriel Gozum, Yifei Ming, and Yixuan Li. SIREN: shaping representations for detecting out-of- distribution objects. InAnnual Conference on Neural Infor- mation Processing Systems, pages 20434–20449, 2022. 3
work page 2022
-
[13]
VOS: learning what you don’t know by virtual outlier synthesis
Xuefeng Du, Zhaoning Wang, Mu Cai, and Yixuan Li. VOS: learning what you don’t know by virtual outlier synthesis. In International Conference on Learning Representations, pages 1–21, 2022. 6, 2
work page 2022
-
[14]
Zero-shot out-of-distribution detection based on the pre-trained model CLIP
Sepideh Esmaeilpour, Bing Liu, Eric Robertson, and Lei Shu. Zero-shot out-of-distribution detection based on the pre-trained model CLIP. InAAAI Conference on Artificial Intelligence, pages 6568–6576, 2022. 1, 3, 6
work page 2022
-
[15]
Christiane Fellbaum.WordNet: An Electronic Lexical Database. Bradford Books, 1998. 3, 5
work page 1998
-
[16]
Clipscope: Enhancing zero-shot ood detection with bayesian scoring
Hao Fu, Naman Patel, Prashanth Krishnamurthy, and Farshad khorrami. Clipscope: Enhancing zero-shot ood detection with bayesian scoring. InWinter Conference on Applications of Computer Vision, pages 5346–5355, 2025. 1, 3, 4, 6
work page 2025
-
[17]
Aucseg: Auc-oriented pixel-level long-tail semantic segmen- tation
Boyu Han, Qianqian Xu, Zhiyong Yang, Shilong Bao, Peisong Wen, Yangbangyan Jiang, and Qingming Huang. Aucseg: Auc-oriented pixel-level long-tail semantic segmen- tation. InAnnual Conference on Neural Information Process- ing Systems, pages 126863–126907, 2024. 7
work page 2024
-
[18]
Boyu Han, Qianqian Xu, Shilong Bao, Zhiyong Yang, Kangli Zi, and Qingming Huang. Lightfair: Towards an efficient alternative for fair t2i diffusion via debiasing pre-trained text encoders. InAnnual Conference on Neural Information Pro- cessing Systems, 2025. 3
work page 2025
-
[19]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InConference on Computer Vision and Pattern Recognition, pages 770–778,
-
[20]
A baseline for detect- ing misclassified and out-of-distribution examples in neural networks
Dan Hendrycks and Kevin Gimpel. A baseline for detect- ing misclassified and out-of-distribution examples in neural networks. InInternational Conference on Learning Repre- sentations, pages 1–12, 2017. 3, 6, 7, 2
work page 2017
-
[21]
Dan Hendrycks, Mantas Mazeika, and Thomas G. Dietterich. Deep anomaly detection with outlier exposure. InInterna- tional Conference on Learning Representations, pages 1–18,
-
[22]
Using self-supervised learning can improve model robustness and uncertainty
Dan Hendrycks, Mantas Mazeika, Saurav Kadavath, and Dawn Song. Using self-supervised learning can improve model robustness and uncertainty. InAnnual Conference on Neural Information Processing Systems, pages 15637–15648,
-
[23]
Pixmix: Dreamlike pictures comprehensively improve safety measures
Dan Hendrycks, Andy Zou, Mantas Mazeika, Leonard Tang, Bo Li, Dawn Song, and Jacob Steinhardt. Pixmix: Dreamlike pictures comprehensively improve safety measures. InCon- ference on Computer Vision and Pattern Recognition, pages 16762–16771, 2022. 3
work page 2022
-
[24]
Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alexander Shepard, Hartwig Adam, Pietro Perona, and Serge J. Belongie. The inaturalist species classification and detection dataset. InConference on Computer Vision and Pattern Recognition, page 8769–8778, 2018. 2, 6
work page 2018
-
[25]
Reconboost: Boosting can achieve modal- ity reconcilement
Cong Hua, Qianqian Xu, Shilong Bao, Zhiyong Yang, and Qingming Huang. Reconboost: Boosting can achieve modal- ity reconcilement. InInternational Conference on Machine Learning, pages 19573–19597, 2024. 1
work page 2024
-
[26]
Openworldauc: Towards unified evaluation and optimization for open-world prompt tuning
Cong Hua, Qianqian Xu, Zhiyong Yang, Zitai Wang, Shilong Bao, and Qingming Huang. Openworldauc: Towards unified evaluation and optimization for open-world prompt tuning. InInternational Conference on Machine Learning, pages 24975–25020, 2025. 3
work page 2025
-
[27]
MOS: towards scaling out-of- distribution detection for large semantic space
Rui Huang and Yixuan Li. MOS: towards scaling out-of- distribution detection for large semantic space. InConference on Computer Vision and Pattern Recognition, pages 8710– 8719, 2021. 2, 3, 6
work page 2021
-
[28]
On the importance of gradients for detecting distributional shifts in the wild
Rui Huang, Andrew Geng, and Yixuan Li. On the importance of gradients for detecting distributional shifts in the wild. In Annual Conference on Neural Information Processing Sys- tems, pages 677–689, 2021. 6
work page 2021
-
[29]
Negative label guided OOD detec- tion with pretrained vision-language models
Xue Jiang, Feng Liu, Zhen Fang, Hong Chen, Tongliang Liu, Feng Zheng, and Bo Han. Negative label guided OOD detec- tion with pretrained vision-language models. InInternational Conference on Learning Representations, pages 1–29, 2024. 1, 2, 3, 4, 6, 7
work page 2024
-
[30]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. 2009. 3
work page 2009
-
[31]
Ya Le and Xuan S. Yang. Tiny imagenet visual recognition challenge. 2015. 3
work page 2015
-
[32]
A simple unified framework for detecting out-of-distribution samples and adversarial attacks
Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. InAnnual Conference on Neural Information Processing Systems, pages 7167–7177,
-
[33]
Rethinking out-of-distribution (OOD) detection: Masked image modeling is all you need
Jingyao Li, Pengguang Chen, Zexin He, Shaozuo Yu, Shu Liu, and Jiaya Jia. Rethinking out-of-distribution (OOD) detection: Masked image modeling is all you need. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 11578–11589, 2023. 1, 3
work page 2023
-
[34]
Focal-sam: Focal sharpness-aware minimization for long-tailed classifi- cation
Sicong Li, Qianqian Xu, Zhiyong Yang, Zitai Wang, Linchao Zhang, Xiaochun Cao, and Qingming Huang. Focal-sam: Focal sharpness-aware minimization for long-tailed classifi- cation. InInternational Conference on Machine Learning, pages 36624–36651, 2025. 7
work page 2025
-
[35]
Learning transferable negative prompts for out-of- distribution detection
Tianqi Li, Guansong Pang, Xiao Bai, Wenjun Miao, and Jin Zheng. Learning transferable negative prompts for out-of- distribution detection. InConference on Computer Vision and Pattern Recognition, pages 17584–17594, 2024. 1, 3, 6
work page 2024
-
[36]
Shiyu Liang, Yixuan Li, and R. Srikant. Enhancing the re- liability of out-of-distribution image detection in neural net- works. InInternational Conference on Learning Representa- tions, pages 1–15, 2018. 1, 3, 6
work page 2018
-
[37]
Weitang Liu, Xiaoyun Wang, John D. Owens, and Yixuan Li. Energy-based out-of-distribution detection. InAnnual Conference on Neural Information Processing Systems, pages 21464–21475, 2020. 1, 3, 6, 2
work page 2020
-
[38]
GEN: pushing the limits of softmax-based out-of-distribution detec- tion
Xixi Liu, Yaroslava Lochman, and Christopher Zach. GEN: pushing the limits of softmax-based out-of-distribution detec- tion. InConference on Computer Vision and Pattern Recogni- tion, pages 23946–23955, 2023. 7, 2
work page 2023
-
[39]
Forming auxiliary high-confident instance-level loss to promote learning from label proportions
Tianhao Ma, Han Chen, Juncheng Hu, Yungang Zhu, and Ximing Li. Forming auxiliary high-confident instance-level loss to promote learning from label proportions. InConfer- ence on Computer Vision and Pattern Recognition, pages 20592–20601, 2025. 1
work page 2025
-
[40]
Learning from label proportions via proportional value classification
Tianhao Ma, Wei Wang, Ximing Li, Gang Niu, and Masashi Sugiyama. Learning from label proportions via proportional value classification. InInternational Conference on Learning Representations, pages 1–26, 2026. 1
work page 2026
-
[41]
Delving into out-of-distribution detection with vision-language representations
Yifei Ming, Ziyang Cai, Jiuxiang Gu, Yiyou Sun, Wei Li, and Yixuan Li. Delving into out-of-distribution detection with vision-language representations. InAnnual Conference on Neural Information Processing Systems, pages 35087–35102,
- [42]
-
[43]
Locoop: Few-shot out-of-distribution detection via prompt learning
Atsuyuki Miyai, Qing Yu, Go Irie, and Kiyoharu Aizawa. Locoop: Few-shot out-of-distribution detection via prompt learning. InAnnual Conference on Neural Information Pro- cessing Systems, pages 76298–76310, 2023. 1, 3, 6, 7
work page 2023
-
[44]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y . Ng. Reading digits in natural images with unsupervised feature learning. InNIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011. 3
work page 2011
-
[45]
Deep neural networks are easily fooled: High confidence predic- tions for unrecognizable images
Anh Mai Nguyen, Jason Yosinski, and Jeff Clune. Deep neural networks are easily fooled: High confidence predic- tions for unrecognizable images. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 427–436,
-
[46]
Out-of-distribution detection with negative prompts
Jun Nie, Yonggang Zhang, Zhen Fang, Tongliang Liu, Bo Han, and Xinmei Tian. Out-of-distribution detection with negative prompts. InInternational Conference on Learning Representations, pages 1–20, 2024. 1, 3, 6
work page 2024
-
[47]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, pages 8748–8763, 2021. 1, 2, 3, 6
work page 2021
-
[48]
Liu, Emily Fertig, Jasper Snoek, Ryan Poplin, Mark A
Jie Ren, Peter J. Liu, Emily Fertig, Jasper Snoek, Ryan Poplin, Mark A. DePristo, Joshua V . Dillon, and Balaji Lakshmi- narayanan. Likelihood ratios for out-of-distribution detection. InAnnual Conference on Neural Information Processing Sys- tems, pages 14680–14691, 2019. 3 10
work page 2019
-
[49]
Liu, Abhijit Guha Roy, Shreyas Padhy, and Balaji Lakshminarayanan
Jie Ren, Stanislav Fort, Jeremiah Z. Liu, Abhijit Guha Roy, Shreyas Padhy, and Balaji Lakshminarayanan. A simple fix to mahalanobis distance for improving near-ood detection. CoRR, abs/2106.09022, 2021. 7
-
[50]
Mohammadreza Salehi, Hossein Mirzaei, Dan Hendrycks, Yixuan Li, Mohammad Hossein Rohban, and Mohammad Sabokrou. A unified survey on anomaly, novelty, open-set, and out of-distribution detection: Solutions and future chal- lenges.Trans. Mach. Learn. Res., 2022. 1
work page 2022
-
[51]
React: Out-of- distribution detection with rectified activations
Yiyou Sun, Chuan Guo, and Yixuan Li. React: Out-of- distribution detection with rectified activations. InAnnual Conference on Neural Information Processing Systems, pages 144–157, 2021. 3, 7
work page 2021
-
[52]
Out- of-distribution detection with deep nearest neighbors
Yiyou Sun, Yifei Ming, Xiaojin Zhu, and Yixuan Li. Out- of-distribution detection with deep nearest neighbors. In International Conference on Machine Learning, pages 20827– 20840, 2022. 3, 6
work page 2022
-
[53]
Argue: Attribute-guided prompt tuning for vision-language models
Xinyu Tian, Shu Zou, Zhaoyuan Yang, and Jing Zhang. Argue: Attribute-guided prompt tuning for vision-language models. InConference on Computer Vision and Pattern Recognition, pages 28578–28587, 2023. 6
work page 2023
-
[54]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkor- eit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAnnual Conference on Neural Information Processing Systems, pages 5998–6008,
-
[55]
Open-set recognition: A good closed-set classifier is all you need
Sagar Vaze, Kai Han, Andrea Vedaldi, and Andrew Zisser- man. Open-set recognition: A good closed-set classifier is all you need. InInternational Conference on Learning Represen- tations, pages 1–27, 2022. 2, 6
work page 2022
-
[56]
Vim: Out-of-distribution with virtual-logit matching
Haoqi Wang, Zhizhong Li, Litong Feng, and Wayne Zhang. Vim: Out-of-distribution with virtual-logit matching. InCon- ference on Computer Vision and Pattern Recognition, pages 4911–4920, 2022. 3, 6, 2
work page 2022
-
[57]
CLIPN for zero-shot OOD detection: Teaching CLIP to say no
Hualiang Wang, Yi Li, Huifeng Yao, and Xiaomeng Li. CLIPN for zero-shot OOD detection: Teaching CLIP to say no. InInternational Conference on Computer Vision, pages 1802–1812, 2023. 3, 6
work page 2023
-
[58]
Rethinking consistent multi-label classifi- cation under inexact supervision
Wei Wang, Tianhao Ma, Ming-Kun Xie, Gang Niu, and Masashi Sugiyama. Rethinking consistent multi-label classifi- cation under inexact supervision. InInternational Conference on Learning Representations, pages 1–26, 2026. 1
work page 2026
-
[59]
Yimu Wang, Evelien Riddell, Adrian Chow, Sean Sedwards, and Krzysztof Czarnecki. Mitigating the modality gap: Few- shot out-of-distribution detection with multi-modal prototypes and image bias estimation.CoRR, abs/2502.00662, 2025. 1, 3, 6
-
[60]
Openauc: towards auc-oriented open-set recognition
Zitai Wang, Qianqian Xu, Zhiyong Yang, Yuan He, Xiaochun Cao, and Qingming Huang. Openauc: towards auc-oriented open-set recognition. InAnnual Conference on Neural In- formation Processing Systems, pages 25033–25045, 2022. 1
work page 2022
-
[61]
A unified generalization analysis of re-weighting and logit-adjustment for imbalanced learn- ing
Zitai Wang, Qianqian Xu, Zhiyong Yang, Yuan He, Xiaochun Cao, and Qingming Huang. A unified generalization analysis of re-weighting and logit-adjustment for imbalanced learn- ing. InAnnual Conference on Neural Information Processing Systems, pages 48417–48430, 2023. 7
work page 2023
-
[62]
A unified perspective for loss-oriented imbalanced learning via localiza- tion.IEEE Trans
Zitai Wang, Qianqian Xu, Zhiyong Yang, Zhikang Xu, Lin- chao Zhang, Xiaochun Cao, and Qingming Huang. A unified perspective for loss-oriented imbalanced learning via localiza- tion.IEEE Trans. Pattern Anal. Mach. Intell., 48(1):639–656,
-
[63]
Ehinger, Aude Oliva, and Antonio Torralba
Jianxiong Xiao, James Hays, Krista A. Ehinger, Aude Oliva, and Antonio Torralba. SUN database: Large-scale scene recognition from abbey to zoo. InConference on Computer Vision and Pattern Recognition, pages 3485–3492, 2010. 6
work page 2010
-
[64]
Likelihood re- gret: An out-of-distribution detection score for variational auto-encoder
Zhisheng Xiao, Qing Yan, and Yali Amit. Likelihood re- gret: An out-of-distribution detection score for variational auto-encoder. InAnnual Conference on Neural Information Processing Systems, pages 20685–20696, 2020. 3
work page 2020
-
[65]
Scal- ing for training time and post-hoc out-of-distribution detec- tion enhancement
Kai Xu, Rongyu Chen, Gianni Franchi, and Angela Yao. Scal- ing for training time and post-hoc out-of-distribution detec- tion enhancement. InInternational Conference on Learning Representations, pages 1–14, 2024. 7, 2
work page 2024
-
[66]
Openood: Benchmarking generalized out-of-distribution detection
Jingkang Yang, Pengyun Wang, Dejian Zou, Zitang Zhou, Kunyuan Ding, Wenxuan Peng, Haoqi Wang, Guangyao Chen, Bo Li, Yiyou Sun, Xuefeng Du, Kaiyang Zhou, Wayne Zhang, Dan Hendrycks, Yixuan Li, and Ziwei Liu. Openood: Benchmarking generalized out-of-distribution detection. In Annual Conference on Neural Information Processing Sys- tems, pages 32598–32611, 2...
work page 2022
-
[67]
Generalized out-of-distribution detection: A survey.Int
Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. Generalized out-of-distribution detection: A survey.Int. J. Comput. Vis., 132(12):5635–5662, 2024. 1, 3
work page 2024
-
[68]
Harnessing hierarchical label distribution variations in test agnostic long-tail recognition
Zhiyong Yang, Qianqian Xu, Zitai Wang, Sicong Li, Boyu Han, Shilong Bao, Xiaochun Cao, and Qingming Huang. Harnessing hierarchical label distribution variations in test agnostic long-tail recognition. InInternational Conference on Machine Learning, pages 56624–56664, 2024. 7
work page 2024
-
[69]
Zhiyong Yang, Qianqian Xu, Sicong Li, Zitai Wang, Xi- aochun Cao, and Qingming Huang. Dirmixe: Harnessing test agnostic long-tail recognition with hierarchical label vartia- tions.IEEE Trans. Pattern Anal. Mach. Intell., pages 1–18,
-
[70]
Local-prompt: Extensible local prompts for few-shot out- of-distribution detection
Fanhu Zeng, Zhen Cheng, Fei Zhu, and Xu-Yao Zhang. Local-prompt: Extensible local prompts for few-shot out- of-distribution detection. InInternational Conference on Learning Representations, pages 1–18, 2025. 6
work page 2025
-
[71]
Boxuan Zhang, Jianing Zhu, Zengmao Wang, Tongliang Liu, Bo Du, and Bo Han. What if the input is expanded in OOD detection? InAnnual Conference on Neural Information Processing Systems, pages 21289–21329, 2024. 6
work page 2024
-
[72]
Hai Zhang, Boyuan Zheng, Tianying Ji, JinHang Liu, Anqi Guo, Junqiao Zhao, and Lanqing Li. Scrutinize what we ignore: Reining in task representation shift of context-based offline meta reinforcement learning. InInternational Confer- ence on Learning Representations, pages 1–22, 2025. 1
work page 2025
-
[73]
Jingyang Zhang, Jingkang Yang, Pengyun Wang, Haoqi Wang, Yueqian Lin, Haoran Zhang, Yiyou Sun, Xuefeng Du, Kaiyang Zhou, Wayne Zhang, Yixuan Li, Ziwei Liu, Yiran Chen, and Hai Li. Openood v1.5: Enhanced benchmark for out-of-distribution detection.CoRR, abs/2306.09301, 2023. 2, 7, 6
-
[74]
Adaneg: Adaptive negative proxy guided OOD detection with vision-language models
Yabin Zhang and Lei Zhang. Adaneg: Adaptive negative proxy guided OOD detection with vision-language models. 11 InAnnual Conference on Neural Information Processing Sys- tems, pages 38744–38768, 2024. 1, 2, 3, 4, 6, 7
work page 2024
-
[75]
LAPT: label-driven automated prompt tuning for OOD detec- tion with vision-language models
Yabin Zhang, Wenjie Zhu, Chenhang He, and Lei Zhang. LAPT: label-driven automated prompt tuning for OOD detec- tion with vision-language models. InEuropean Conference on Computer Vision, pages 271–288, 2024. 6, 7
work page 2024
-
[76]
Two fists, one heart: Multi- objective optimization based strategy fusion for long-tailed learning
Zhe Zhao, Pengkun Wang, Haibin Wen, Wei Xu, Lai Song, Qingfu Zhang, and Yang Wang. Two fists, one heart: Multi- objective optimization based strategy fusion for long-tailed learning. InInternational Conference on Machine Learning, pages 61040–61071, 2024. 7
work page 2024
-
[77]
Places: A 10 million image database for scene recognition.IEEE Trans
Bolei Zhou, `Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition.IEEE Trans. Pattern Anal. Mach. Intell., 40(6):1452–1464, 2018. 3, 6
work page 2018
-
[78]
Shu Zou, Xinyu Tian, Qinyu Zhao, Zhaoyuan Yang, and Jing Zhang. Simlabel: Consistency-guided ood detection with pretrained vision-language models. InAustralasian Joint Conference on Artificial Intelligence, page 110–121, 2025. 6 12 Appendix Table of Contents A . Pseudo-code for Modality Inversion 2 B . Additional Results 2 B.1. Full results on the OpenOOD...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.