Recognition: 2 theorem links
· Lean TheoremOmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models
Pith reviewed 2026-05-13 22:56 UTC · model grok-4.3
The pith
OmniVoice scales zero-shot text-to-speech to over 600 languages by directly generating acoustic tokens from text using a diffusion language model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OmniVoice is a massively multilingual zero-shot TTS model scaling to over 600 languages with a diffusion language model-style discrete non-autoregressive architecture that directly maps text to multi-codebook acoustic tokens, facilitated by full-codebook random masking and LLM initialization, achieving state-of-the-art performance on Chinese, English, and multilingual benchmarks from a 581k-hour open-source dataset.
What carries the argument
The diffusion language model-style discrete non-autoregressive architecture that directly converts text into multi-codebook acoustic tokens.
If this is right
- Simplifies TTS pipelines by removing the need for separate semantic and acoustic stages.
- Supports zero-shot synthesis for hundreds of languages with no language-specific fine-tuning.
- Delivers superior intelligibility through LLM pre-training initialization.
- Provides publicly available code and models for broad adoption in multilingual applications.
Where Pith is reading between the lines
- If the direct mapping works at this scale, similar diffusion approaches could simplify other sequence generation tasks like text-to-image or music.
- The open-source data curation may limit performance on dialects or languages with poor representation in public corpora.
- Future work could test whether this model maintains quality when generating speech in code-switched or accented contexts not explicitly in the training data.
Load-bearing premise
The curated 581k-hour open-source dataset contains enough high-quality, diverse data to train a model that generalizes intelligibly and naturally to over 600 languages.
What would settle it
Evaluation on a held-out set of 50 low-resource languages showing that word error rates or mean opinion scores fall below those of language-specific baselines or other multilingual models.
Figures



read the original abstract
We present OmniVoice, a massively multilingual zero-shot text-to-speech (TTS) model that scales to over 600 languages. At its core is a novel diffusion language model-style discrete non-autoregressive (NAR) architecture. Unlike conventional discrete NAR models that suffer from performance bottlenecks in complex two-stage (text-to-semantic-to-acoustic) pipelines, OmniVoice directly maps text to multi-codebook acoustic tokens. This simplified approach is facilitated by two key technical innovations: (1) a full-codebook random masking strategy for efficient training, and (2) initialization from a pre-trained LLM to ensure superior intelligibility. By leveraging a 581k-hour multilingual dataset curated entirely from open-source data, OmniVoice achieves the broadest language coverage to date and delivers state-of-the-art performance across Chinese, English, and diverse multilingual benchmarks. Our code and pre-trained models are publicly available at https://github.com/k2-fsa/OmniVoice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OmniVoice, a zero-shot TTS model for over 600 languages based on a diffusion language model-style discrete non-autoregressive architecture. It directly maps text to multi-codebook acoustic tokens using full-codebook random masking and initialization from a pre-trained LLM, trained on a 581k-hour multilingual dataset curated from open-source sources, and claims state-of-the-art performance on Chinese, English, and diverse multilingual benchmarks, with code and models released publicly.
Significance. If the performance claims hold with proper quantitative validation, this would represent a substantial advance in omnilingual TTS by simplifying the conventional two-stage pipeline and scaling language coverage far beyond existing systems. The public release of code and pre-trained models is a clear strength that supports reproducibility and community follow-up work.
major comments (2)
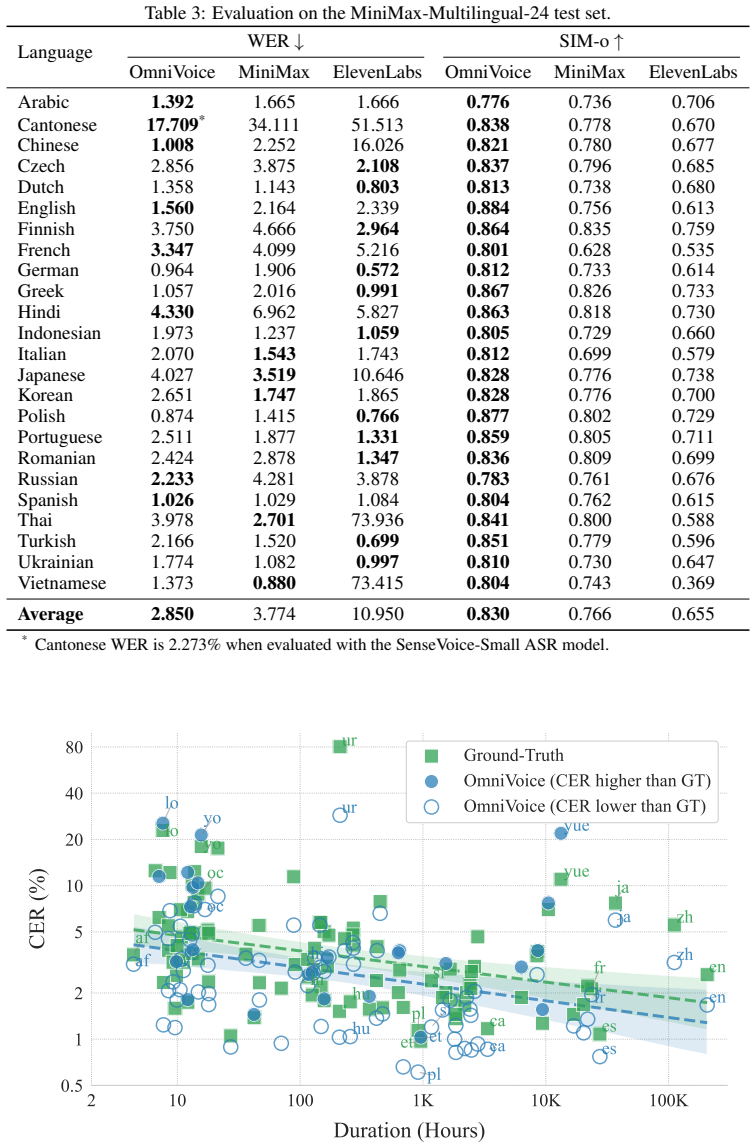
- [Abstract] Abstract: The central claims of SOTA performance across benchmarks and broadest language coverage to date are asserted without any quantitative metrics, baselines, error analysis, or dataset statistics, which is load-bearing for evaluating the generalization claim.
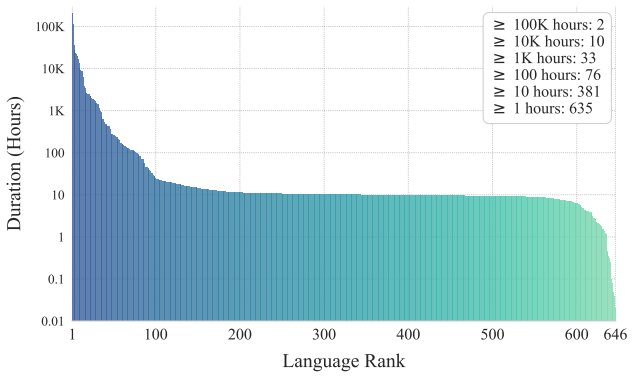
- [§2] §2 (Dataset description): No per-language hour breakdowns or coverage statistics are provided for the 581k-hour open-source corpus, which directly undermines assessment of zero-shot intelligibility and naturalness on the low-resource languages among the claimed 600+.
minor comments (2)
- [§3.1] §3.1: The notation for multi-codebook acoustic tokens and the full-codebook masking strategy could be introduced with an explicit equation or diagram for clarity.
- [Abstract] The abstract mentions 'diverse multilingual benchmarks' without naming them; this should be expanded in the experiments section for precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract and dataset section require strengthening with quantitative support and coverage details to better substantiate the claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of SOTA performance across benchmarks and broadest language coverage to date are asserted without any quantitative metrics, baselines, error analysis, or dataset statistics, which is load-bearing for evaluating the generalization claim.
Authors: We agree that the abstract should include concrete quantitative evidence. In the revised version, we will add key metrics such as WER reductions, MOS scores, and direct comparisons to prior multilingual TTS baselines on the English, Chinese, and diverse multilingual test sets. These numbers, drawn from the experimental results in the body, will directly support the SOTA and generalization claims without altering the core narrative. revision: yes
-
Referee: [§2] §2 (Dataset description): No per-language hour breakdowns or coverage statistics are provided for the 581k-hour open-source corpus, which directly undermines assessment of zero-shot intelligibility and naturalness on the low-resource languages among the claimed 600+.
Authors: We acknowledge the value of per-language statistics for assessing low-resource performance. While exhaustive breakdowns for every language in the open-source curation are not fully available due to source variability, we will add a table in Section 2 summarizing hours for the top 50 languages by volume, overall language family coverage, and notes on low-resource inclusion. Zero-shot results on the multilingual benchmarks already provide empirical validation for intelligibility across the claimed range. revision: partial
Circularity Check
No circularity detected; claims rest on external dataset and empirical evaluation
full rationale
The paper describes an empirical TTS architecture (diffusion LM-style NAR model mapping text directly to multi-codebook acoustic tokens via full-codebook masking and LLM initialization) trained on a 581k-hour open-source corpus. No equations, derivations, or self-referential predictions appear in the provided text. Performance claims are presented as outcomes of training and benchmarking rather than quantities fitted to the target metrics and then renamed. No load-bearing self-citations or uniqueness theorems imported from prior author work are invoked to force the central result. The derivation chain is therefore self-contained against external data and benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearOmniVoice employs a discrete masked diffusion objective with a bidirectional Transformer backbone. OmniVoice directly maps text to multi-codebook acoustic tokens... full-codebook random masking strategy... initialization from a pre-trained LLM
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe apply a language-level data resampling strategy... ri = max(1, round((Dmax/Di)^(1−β))) with β=0.8
Forward citations
Cited by 3 Pith papers
-
Kinetic-Optimal Scheduling with Moment Correction for Metric-Induced Discrete Flow Matching in Zero-Shot Text-to-Speech
GibbsTTS combines a training-free kinetic-optimal scheduler with finite-step moment correction in MI-DFM to deliver top naturalness and strong speaker similarity in zero-shot TTS.
-
Praxy Voice: Voice-Prompt Recovery + BUPS for Commercial-Class Indic TTS from a Frozen Non-Indic Base at Zero Commercial-Training-Data Cost
A combination of phoneme romanization, targeted LoRA adaptation, and voice-prompt recovery enables commercial-class Indic TTS from a non-Indic base without acoustic retraining or commercial data.
-
One Voice, Many Tongues: Cross-Lingual Voice Cloning for Scientific Speech
A system based on OmniVoice with multi-model ensemble distillation for fine-tuning shows consistent gains in intelligibility metrics while keeping speaker similarity for cross-lingual scientific speech.
Reference graph
Works this paper leans on
-
[1]
Sanyuan Chen, Chengyi Wang, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Neural codec language models are zero-shot text to speech synthesizers.IEEE Transactions on Audio, Speech and Language Processing, 2025
work page 2025
-
[2]
Kaito Baba, Wataru Nakata, Yuki Saito, and Hiroshi Saruwatari
Philip Anastassiou, Jiawei Chen, Jitong Chen, Yuanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, et al. Seed-tts: A family of high-quality versatile speech generation models.arXiv preprint arXiv:2406.02430, 2024
-
[3]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, et al. Cosyvoice 2: Scalable streaming speech synthesis with large language models.arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Hao-Han Guo, Yao Hu, Kun Liu, Fei-Yu Shen, Xu Tang, Yi-Chen Wu, Feng-Long Xie, Kun Xie, and Kai-Tuo Xu. Fireredtts: A foundation text-to-speech framework for industry-level generative speech applications.arXiv preprint arXiv:2409.03283, 2024
-
[5]
Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, and Jingchen Shu. Indextts2: A breakthrough in emotionally expressive and duration-controlled auto-regressive zero-shot text-to-speech.arXiv preprint arXiv:2506.21619, 2025
-
[6]
Ditar: Diffusion transformer autoregressive mod- eling for speech generation
Dongya Jia, Zhuo Chen, Jiawei Chen, Chenpeng Du, Jian Wu, Jian Cong, Xiaobin Zhuang, Chumin Li, Zhen Wei, Yuping Wang, et al. Ditar: Diffusion transformer autoregressive mod- eling for speech generation. InInternational Conference on Machine Learning, pages 27255– 27270. PMLR, 2025
work page 2025
-
[7]
Xinsheng Wang, Mingqi Jiang, Ziyang Ma, Ziyu Zhang, Songxiang Liu, Linqin Li, Zheng Liang, Qixi Zheng, Rui Wang, Xiaoqin Feng, et al. Spark-tts: An efficient llm-based text-to- speech model with single-stream decoupled speech tokens.arXiv preprint arXiv:2503.01710, 2025
-
[8]
Zhen Ye, Xinfa Zhu, Chi-Min Chan, Xinsheng Wang, Xu Tan, Jiahe Lei, Yi Peng, Haohe Liu, Yizhu Jin, Zheqi Dai, et al. Llasa: Scaling train-time and inference-time compute for llama-based speech synthesis.arXiv preprint arXiv:2502.04128, 2025
-
[9]
Yakun Song, Xiaobin Zhuang, Jiawei Chen, Zhikang Niu, Guanrou Yang, Chenpeng Du, Dongya Jia, Zhuo Chen, Yuping Wang, Yuxuan Wang, et al. Distar: Diffusion over a scalable token autoregressive representation for speech generation.arXiv preprint arXiv:2510.12210, 2025
-
[10]
Yixuan Zhou, Guoyang Zeng, Xin Liu, Xiang Li, Renjie Yu, Ziyang Wang, Runchuan Ye, Weiyue Sun, Jiancheng Gui, Kehan Li, et al. V oxcpm: Tokenizer-free tts for context-aware speech generation and true-to-life voice cloning.arXiv preprint arXiv:2509.24650, 2025
-
[11]
Glm-tts technical report.arXiv preprint arXiv:2512.14291, 2025
Jiayan Cui, Zhihan Yang, Naihan Li, Jiankun Tian, Xingyu Ma, Yi Zhang, Guangyu Chen, Runxuan Yang, Yuqing Cheng, Yizhi Zhou, et al. Glm-tts technical report.arXiv preprint arXiv:2512.14291, 2025
-
[12]
Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, et al. V oicebox: Text-guided mul- tilingual universal speech generation at scale.Advances in neural information processing sys- tems, 36:14005–14034, 2023
work page 2023
-
[13]
E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts
Sefik Emre Eskimez, Xiaofei Wang, Manthan Thakker, Canrun Li, Chung-Hsien Tsai, Zhen Xiao, Hemin Yang, Zirun Zhu, Min Tang, Xu Tan, et al. E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts. In2024 IEEE Spoken Language Technology Workshop (SLT), pages 682–689. IEEE, 2024
work page 2024
-
[14]
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, Jian Zhao, Kai Yu, and Xie Chen. F5-tts: A fairytaler that fakes fluent and faithful speech with flow matching.arXiv preprint arXiv:2410.06885, 2024. 12
-
[15]
Pseudo-autoregressive neural codec language models for efficient zero-shot text-to-speech synthesis
Yifan Yang, Shujie Liu, Jinyu Li, Yuxuan Hu, Haibin Wu, Hui Wang, Jianwei Yu, Lingwei Meng, Haiyang Sun, Yanqing Liu, et al. Pseudo-autoregressive neural codec language models for efficient zero-shot text-to-speech synthesis. InProceedings of the 33rd ACM International Conference on Multimedia, pages 9316–9325, 2025
work page 2025
-
[16]
Han Zhu, Wei Kang, Zengwei Yao, Liyong Guo, Fangjun Kuang, Zhaoqing Li, Weiji Zhuang, Long Lin, and Daniel Povey. Zipvoice: Fast and high-quality zero-shot text-to-speech with flow matching.arXiv preprint arXiv:2506.13053, 2025
-
[17]
ZipVoice-Dialog: Non-Autoregressive Spoken Dialogue Generation with Flow Matching
Han Zhu, Wei Kang, Liyong Guo, Zengwei Yao, Fangjun Kuang, Weiji Zhuang, Zhaoqing Li, Zhifeng Han, Dong Zhang, Xin Zhang, et al. Zipvoice-dialog: Non-autoregressive spoken dialogue generation with flow matching.arXiv preprint arXiv:2507.09318, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Ziyue Jiang, Yi Ren, Ruiqi Li, Shengpeng Ji, Boyang Zhang, Zhenhui Ye, Chen Zhang, Bai Jionghao, Xiaoda Yang, Jialong Zuo, et al. Megatts 3: Sparse alignment enhanced latent diffusion transformer for zero-shot speech synthesis.arXiv preprint arXiv:2502.18924, 2025
-
[19]
MaskGCT: Zero-shot text-to- speech with masked generative codec transformer
Yuancheng Wang, Haoyue Zhan, Liwei Liu, Ruihong Zeng, Haotian Guo, Jiachen Zheng, Qiang Zhang, Xueyao Zhang, Shunsi Zhang, and Zhizheng Wu. MaskGCT: Zero-shot text-to- speech with masked generative codec transformer. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[20]
Yifan Yang, Bing Han, Hui Wang, Long Zhou, Wei Wang, Mingyu Cui, Xu Tan, and Xie Chen. Measuring prosody diversity in zero-shot tts: A new metric, benchmark, and exploration.arXiv preprint arXiv:2509.19928, 2025
-
[21]
Single-stage tts with masked audio token modeling and semantic knowledge distillation
Gerard I Gállego, Roy Fejgin, Chunghsin Yeh, Xiaoyu Liu, and Gautam Bhattacharya. Single-stage tts with masked audio token modeling and semantic knowledge distillation. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 1–5. IEEE, 2025
work page 2025
-
[22]
Subham Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
work page 2024
-
[23]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[24]
Large language diffusion models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, JUN ZHOU, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[25]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Ling- peng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Soundstorm: Efficient parallel audio generation.arXiv preprint arXiv:2305.09636, 2023
Zalán Borsos, Matt Sharifi, Damien Vincent, Eugene Kharitonov, Neil Zeghidour, and Marco Tagliasacchi. Soundstorm: Efficient parallel audio generation.arXiv preprint arXiv:2305.09636, 2023
-
[27]
Leying Zhang, Wangyou Zhang, Zhengyang Chen, and Yanmin Qian. Advanced zero-shot text-to-speech for background removal and preservation with controllable masked speech pre- diction. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
work page 2025
-
[28]
Xiaofei Wang, Sefik Emre Eskimez, Manthan Thakker, Hemin Yang, Zirun Zhu, Min Tang, Yufei Xia, Jinzhu Li, Sheng Zhao, Jinyu Li, et al. An investigation of noise robustness for flow-matching-based zero-shot tts.arXiv preprint arXiv:2406.05699, 2024
-
[29]
V oicesculptor: Your voice, designed by you
Jingbin Hu, Huakang Chen, Linhan Ma, Dake Guo, Qirui Zhan, Wenhao Li, Haoyu Zhang, Kangxiang Xia, Ziyu Zhang, Wenjie Tian, et al. V oicesculptor: Your voice, designed by you. arXiv preprint arXiv:2601.10629, 2026. 13
-
[30]
Huan Liao, Qinke Ni, Yuancheng Wang, Yiheng Lu, Haoyue Zhan, Pengyuan Xie, Qiang Zhang, and Zhizheng Wu. Nvspeech: An integrated and scalable pipeline for human-like speech modeling with paralinguistic vocalizations.arXiv preprint arXiv:2508.04195, 2025
-
[31]
Wei Deng, Siyi Zhou, Jingchen Shu, Jinchao Wang, and Lu Wang. Indextts: An industrial-level controllable and efficient zero-shot text-to-speech system.arXiv preprint arXiv:2502.05512, 2025
-
[32]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Chongjia Ni, Xian Shi, et al. Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training.arXiv preprint arXiv:2505.17589, 2025
-
[34]
Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conver- sion for everyone
Edresson Casanova, Julian Weber, Christopher D Shulby, Arnaldo Candido Junior, Eren Gölge, and Moacir A Ponti. Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conver- sion for everyone. InInternational conference on machine learning, pages 2709–2720. PMLR, 2022
work page 2022
-
[35]
Xtts: a massively multilingual zero-shot text-to-speech model
Edresson Casanova, Kelly Davis, Eren Gölge, Görkem Göknar, Iulian Gulea, Logan Hart, Aya Aljafari, Joshua Meyer, Reuben Morais, Samuel Olayemi, et al. Xtts: a massively multilingual zero-shot text-to-speech model. InProc. Interspeech 2024, pages 4978–4982, 2024
work page 2024
-
[36]
V oicecraft-x: Unifying multilingual, voice-cloning speech synthesis and speech editing
Zhisheng Zheng, Puyuan Peng, Anuj Diwan, Cong Phuoc Huynh, Xiaohang Sun, Zhu Liu, Vimal Bhat, and David Harwath. V oicecraft-x: Unifying multilingual, voice-cloning speech synthesis and speech editing. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2737–2756, 2025
work page 2025
-
[37]
Yushen Chen, Junzhe Liu, Yujie Tu, Zhikang Niu, Yuzhe Liang, Kai Yu, Chunyu Qiang, Chen Zhang, and Xie Chen. Habibi: Laying the open-source foundation of unified-dialectal arabic speech synthesis.arXiv preprint arXiv:2601.13802, 2026
-
[38]
Zhiyuan Zhao, Lijian Lin, Ye Zhu, Kai Xie, Yunfei Liu, and Yu Li. Lemas: Large a 150k-hour large-scale extensible multilingual audio suite with generative speech models.arXiv preprint arXiv:2601.04233, 2026
-
[39]
Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, et al. Scaling speech technology to 1,000+ languages.Journal of Machine Learning Research, 25(97):1–52, 2024
work page 2024
-
[40]
Chatterbox-TTS.https://github.com/resemble-ai/chatterbox, 2025
Resemble AI. Chatterbox-TTS.https://github.com/resemble-ai/chatterbox, 2025. GitHub repository
work page 2025
-
[41]
Shijia Liao, Yuxuan Wang, Tianyu Li, Yifan Cheng, Ruoyi Zhang, Rongzhi Zhou, and Yi- jin Xing. Fish-speech: Leveraging large language models for advanced multilingual text-to- speech synthesis.arXiv preprint arXiv:2411.01156, 2024
-
[42]
Qwen3-tts technical report.arXiv preprint arXiv:2601.15621, 2026
Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, et al. Qwen3-tts technical report.arXiv preprint arXiv:2601.15621, 2026
-
[43]
Indextts 2.5 technical report.arXiv preprint arXiv:2601.03888, 2026
Yunpei Li, Xun Zhou, Jinchao Wang, Lu Wang, Yong Wu, Siyi Zhou, Yiquan Zhou, and Jingchen Shu. Indextts 2.5 technical report.arXiv preprint arXiv:2601.03888, 2026
-
[44]
Wataru Nakata, Yuki Saito, Yota Ueda, and Hiroshi Saruwatari. Sidon: Fast and robust open-source multilingual speech restoration for large-scale dataset cleansing.arXiv preprint arXiv:2509.17052, 2025
-
[45]
Runchuan Ye, Yixuan Zhou, Renjie Yu, Zijian Lin, Kehan Li, Xiang Li, Xin Liu, Guoyang Zeng, and Zhiyong Wu. A scalable pipeline for enabling non-verbal speech generation and understanding.arXiv preprint arXiv:2508.05385, 2025. 14
-
[46]
Haorui He, Zengqiang Shang, Chaoren Wang, Xuyuan Li, Yicheng Gu, Hua Hua, Liwei Liu, Chen Yang, Jiaqi Li, Peiyang Shi, et al. Emilia: A large-scale, extensive, multilingual, and diverse dataset for speech generation.IEEE Transactions on Audio, Speech and Language Processing, 2025
work page 2025
-
[47]
Boson AI. Higgs Audio V2: Redefining Expressiveness in Audio Generation.https:// github.com/boson-ai/higgs-audio, 2025. GitHub repository. Release blog available at https://www.boson.ai/blog/higgs-audio-v2
work page 2025
-
[48]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021
work page 2021
-
[50]
Aleksandr Meister, Matvei Novikov, Nikolay Karpov, Evelina Bakhturina, Vitaly Lavrukhin, and Boris Ginsburg. Librispeech-pc: Benchmark for evaluation of punctuation and capitaliza- tion capabilities of end-to-end asr models. In2023 IEEE automatic speech recognition and understanding workshop (ASRU), pages 1–7. IEEE, 2023
work page 2023
-
[51]
15 Xin Zhang, Dong Zhang, Shimin Li, Yaqian Zhou, and Xipeng Qiu
Bowen Zhang, Congchao Guo, Geng Yang, Hang Yu, Haozhe Zhang, Heidi Lei, Jialong Mai, Junjie Yan, Kaiyue Yang, Mingqi Yang, et al. Minimax-speech: Intrinsic zero-shot text-to- speech with a learnable speaker encoder.arXiv preprint arXiv:2505.07916, 2025
-
[52]
Fleurs: Few-shot learning evaluation of universal representations of speech
Alexis Conneau, Min Ma, Simran Khanuja, Yu Zhang, Vera Axelrod, Siddharth Dalmia, Jason Riesa, Clara Rivera, and Ankur Bapna. Fleurs: Few-shot learning evaluation of universal representations of speech. In2022 IEEE Spoken Language Technology Workshop (SLT), pages 798–805. IEEE, 2023
work page 2023
-
[53]
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. Wavlm: Large-scale self-supervised pre- training for full stack speech processing.IEEE Journal of Selected Topics in Signal Processing, 16(6):1505–1518, 2022
work page 2022
-
[54]
Brecht Desplanques, Jenthe Thienpondt, and Kris Demuynck. Ecapa-tdnn: Emphasized chan- nel attention, propagation and aggregation in tdnn based speaker verification. InProc. Inter- speech 2020, pages 3830–3834, 2020
work page 2020
-
[55]
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdi- nov, and Abdelrahman Mohamed. Hubert: Self-supervised speech representation learning by masked prediction of hidden units.IEEE/ACM transactions on audio, speech, and language processing, 29:3451–3460, 2021
work page 2021
-
[56]
Zhifu Gao, ShiLiang Zhang, Ian McLoughlin, and Zhijie Yan. Paraformer: Fast and accu- rate parallel transformer for non-autoregressive end-to-end speech recognition. InProc. Inter- speech 2022, pages 2063–2067, 2022
work page 2022
-
[57]
ASR Omnilingual, Gil Keren, Artyom Kozhevnikov, Yen Meng, Christophe Ropers, Matthew Setzler, Skyler Wang, Ife Adebara, Michael Auli, Can Balioglu, et al. Omnilingual asr: Open- source multilingual speech recognition for 1600+ languages.arXiv preprint arXiv:2511.09690, 2025
-
[58]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational con- ference on machine learning, pages 28492–28518. PMLR, 2023
work page 2023
-
[59]
Utmos: Utokyo-sarulab system for voicemos challenge 2022.Interspeech 2022, 2022
Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hi- roshi Saruwatari. Utmos: Utokyo-sarulab system for voicemos challenge 2022.Interspeech 2022, 2022
work page 2022
-
[60]
Keyu An, Qian Chen, Chong Deng, Zhihao Du, Changfeng Gao, Zhifu Gao, Yue Gu, Ting He, Hangrui Hu, Kai Hu, et al. Funaudiollm: V oice understanding and generation foundation models for natural interaction between humans and llms.arXiv preprint arXiv:2407.04051, 2024. 15
-
[61]
Libritts: A corpus derived from librispeech for text-to-speech
Heiga Zen, Viet Dang, Rob Clark, Yu Zhang, Ron J Weiss, Ye Jia, Zhifeng Chen, and Yonghui Wu. Libritts: A corpus derived from librispeech for text-to-speech. InProc. Interspeech 2019, pages 1526–1530, 2019
work page 2019
-
[62]
Common voice: A massively-multilingual speech corpus
Rosana Ardila, Megan Branson, Kelly Davis, Michael Kohler, Josh Meyer, Michael Henretty, Reuben Morais, Lindsay Saunders, Francis Tyers, and Gregor Weber. Common voice: A massively-multilingual speech corpus. InProceedings of the Twelfth Language Resources and Evaluation Conference, pages 4218–4222, 2020
work page 2020
-
[63]
Yifan Yang, Zheshu Song, Jianheng Zhuo, Mingyu Cui, Jinpeng Li, Bo Yang, Yexing Du, Ziyang Ma, Xunying Liu, Ziyuan Wang, et al. Gigaspeech 2: An evolving, large-scale and multi-domain asr corpus for low-resource languages with automated crawling, transcription and refinement. InProceedings of the 63rd Annual Meeting of the Association for Computa- tional ...
work page 2025
-
[64]
Nithin Rao Koluguri, Monica Sekoyan, George Zelenfroynd, Sasha Meister, Shuoyang Ding, Sofia Kostandian, He Huang, Nikolay Karpov, Jagadeesh Balam, Vitaly Lavrukhin, et al. Gra- nary: Speech recognition and translation dataset in 25 european languages.arXiv preprint arXiv:2505.13404, 2025
-
[65]
Eurospeech: A multilingual speech corpus.arXiv preprint arXiv:2510.00514, 2025
Samuel Pfisterer, Florian Grötschla, Luca A Lanzendörfer, Florian Yan, and Roger Watten- hofer. Eurospeech: A multilingual speech corpus.arXiv preprint arXiv:2510.00514, 2025
-
[66]
Ashwin Sankar, Srija Anand, Praveen Varadhan, Sherry Thomas, Mehak Singal, Shridhar Ku- mar, Deovrat Mehendale, Aditi Krishana, Giri Raju, and Mitesh Khapra. Indicvoices-r: Un- locking a massive multilingual multi-speaker speech corpus for scaling indian tts.Advances in Neural Information Processing Systems, 37:68161–68182, 2024
work page 2024
-
[67]
Towards building text-to-speech systems for the next billion users
Gokul Karthik Kumar, SV Praveen, Pratyush Kumar, Mitesh M Khapra, and Karthik Nandaku- mar. Towards building text-to-speech systems for the next billion users. InIcassp 2023-2023 ieee international conference on acoustics, speech and signal processing (icassp), pages 1–5. IEEE, 2023
work page 2023
-
[68]
Rasa: Building expressive speech synthesis systems for indian languages in low-resource settings
Praveen Srinivasa Varadhan, Ashwin Sankar, Giri Raju, and Mitesh M Khapra. Rasa: Building expressive speech synthesis systems for indian languages in low-resource settings. InProc. Interspeech 2024, pages 1830–1834, 2024
work page 2024
-
[69]
Zero-shot text-to-speech for vietnamese
Thi Vu, Linh The Nguyen, and Dat Quoc Nguyen. Zero-shot text-to-speech for vietnamese. In Proceedings of ACL, 2025
work page 2025
-
[70]
Cml-tts: A multilingual dataset for speech synthesis in low-resource lan- guages
Frederico S Oliveira, Edresson Casanova, Arnaldo Candido Junior, Anderson S Soares, and Ar- lindo R Galvão Filho. Cml-tts: A multilingual dataset for speech synthesis in low-resource lan- guages. InInternational Conference on Text, Speech, and Dialogue, pages 188–199. Springer, 2023
work page 2023
-
[71]
Longhao Li, Zhao Guo, Hongjie Chen, Yuhang Dai, Ziyu Zhang, Hongfei Xue, Tianlun Zuo, Chengyou Wang, Shuiyuan Wang, Jie Li, et al. Wenetspeech-yue: A large-scale cantonese speech corpus with multi-dimensional annotation.arXiv preprint arXiv:2509.03959, 2025
-
[72]
Yuhang Dai, Ziyu Zhang, Shuai Wang, Longhao Li, Zhao Guo, Tianlun Zuo, Shuiyuan Wang, Hongfei Xue, Chengyou Wang, Qing Wang, et al. Wenetspeech-chuan: A large- scale sichuanese corpus with rich annotation for dialectal speech processing.arXiv preprint arXiv:2509.18004, 2025
-
[73]
Kespeech: An open source speech dataset of mandarin and its eight subdialects
Zhiyuan Tang, Dong Wang, Yanguang Xu, Jianwei Sun, Xiaoning Lei, Shuaijiang Zhao, Cheng Wen, Xingjun Tan, Chuandong Xie, Shuran Zhou, et al. Kespeech: An open source speech dataset of mandarin and its eight subdialects. InThirty-fifth conference on neural information processing systems datasets and benchmarks track (Round 2), 2021
work page 2021
-
[74]
Xian Shi, Fan Yu, Yizhou Lu, Yuhao Liang, Qiangze Feng, Daliang Wang, Yanmin Qian, and Lei Xie. The accented english speech recognition challenge 2020: open datasets, tracks, base- lines, results and methods. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6918–6922. IEEE, 2021. 16
work page 2020
-
[75]
Jeong-Uk Bang, Seung Yun, Seung-Hi Kim, Mu-Yeol Choi, Min-Kyu Lee, Yeo-Jeong Kim, Dong-Hyun Kim, Jun Park, Young-Jik Lee, and Sang-Hun Kim. Ksponspeech: Korean spon- taneous speech corpus for automatic speech recognition.Applied Sciences, 10(19):6936, 2020
work page 2020
-
[76]
Reazonspeech: A free and massive corpus for japanese asr, 2016
YYDMS Fujimoto. Reazonspeech: A free and massive corpus for japanese asr, 2016
work page 2016
-
[77]
Cancan Li, Fei Su, Juan Liu, Hui Bu, Yulong Wan, Hongbin Suo, and Ming Li. Aishell6- whisper: A chinese mandarin audio-visual whisper speech dataset with speech recognition baselines.arXiv preprint arXiv:2509.23833, 2025
-
[78]
Scaling rich style-prompted text-to-speech datasets
Anuj Diwan, Zhisheng Zheng, David Harwath, and Eunsol Choi. Scaling rich style-prompted text-to-speech datasets. InProceedings of the 2025 Conference on Empirical Methods in Nat- ural Language Processing, pages 3639–3659, 2025
work page 2025
-
[79]
Seniortalk: A chinese conversation dataset with rich annotations for super-aged seniors, 2025
Yang Chen, Hui Wang, Shiyao Wang, Junyang Chen, Jiabei He, Jiaming Zhou, Xi Yang, Yequan Wang, Yonghua Lin, and Yong Qin. Seniortalk: A chinese conversation dataset with rich annotations for super-aged seniors, 2025
work page 2025
-
[80]
Jiaming Zhou, Shiyao Wang, Shiwan Zhao, Jiabei He, Haoqin Sun, Hui Wang, Cheng Liu, Aobo Kong, Yujie Guo, and Yong Qin. Childmandarin: A comprehensive mandarin speech dataset for young children aged 3-5.arXiv preprint arXiv:2409.18584, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.