The Augmentation Trap: AI Productivity and the Cost of Cognitive Offloading
Pith reviewed 2026-05-22 10:01 UTC · model grok-4.3
The pith
Even rational decision-makers adopt AI tools that erode skills, leaving workers less productive in the long run.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
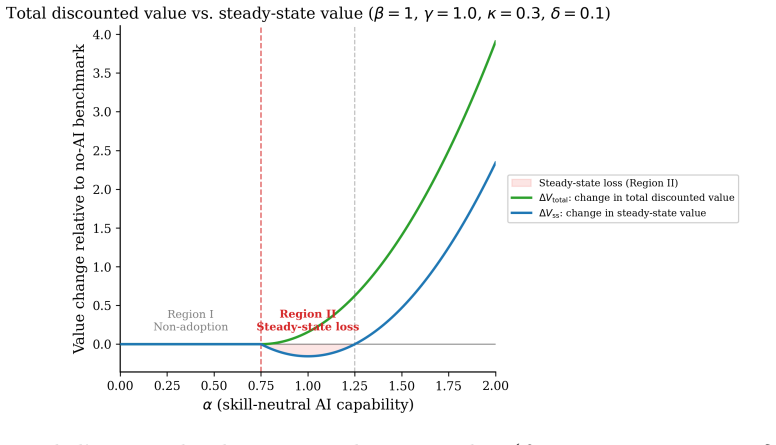
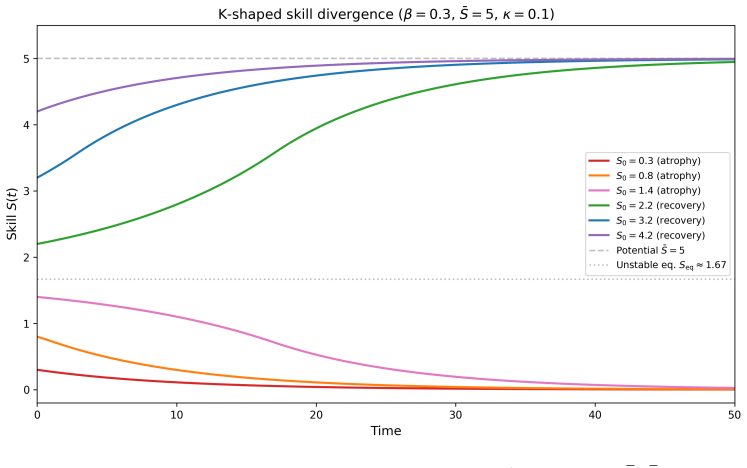
In a dynamic model of AI usage intensity, the decomposition of productivity effects into an expertise-independent channel and an expertise-scaling channel shows that optimal adoption produces steady-state loss even when erosion is fully anticipated, turns into an augmentation trap under short-termist incentives or external skill value, and allows permanent skill divergence when the tool relies less on existing expertise.
What carries the argument
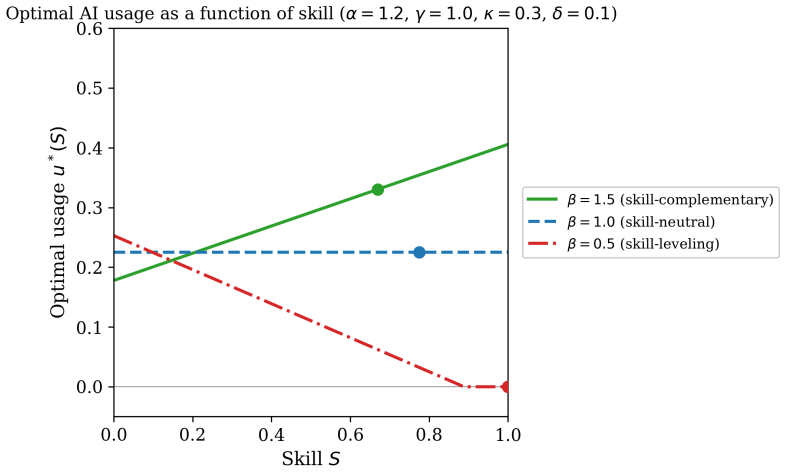
The dynamic choice model of AI usage intensity over time with a two-channel productivity decomposition separating expertise-independent and expertise-dependent effects.
If this is right
- Even full anticipation of skill erosion leads to rational AI adoption and steady-state productivity loss for the worker.
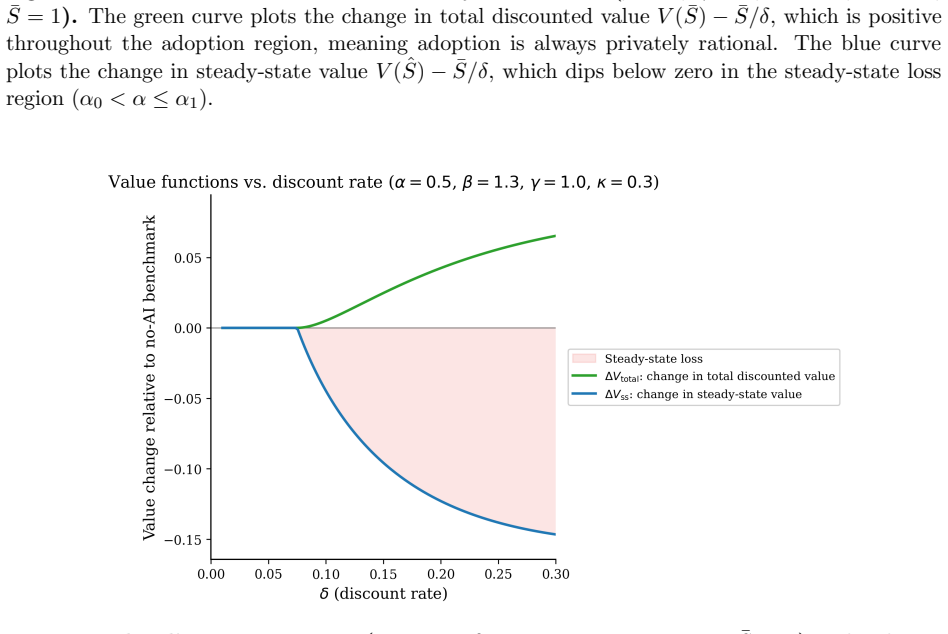
- Short-termist managers or external value of skill convert the loss into an augmentation trap leaving the worker worse off than no adoption.
- Lower dependence of AI on worker expertise causes experienced workers to reach full potential while less experienced ones deskill to zero.
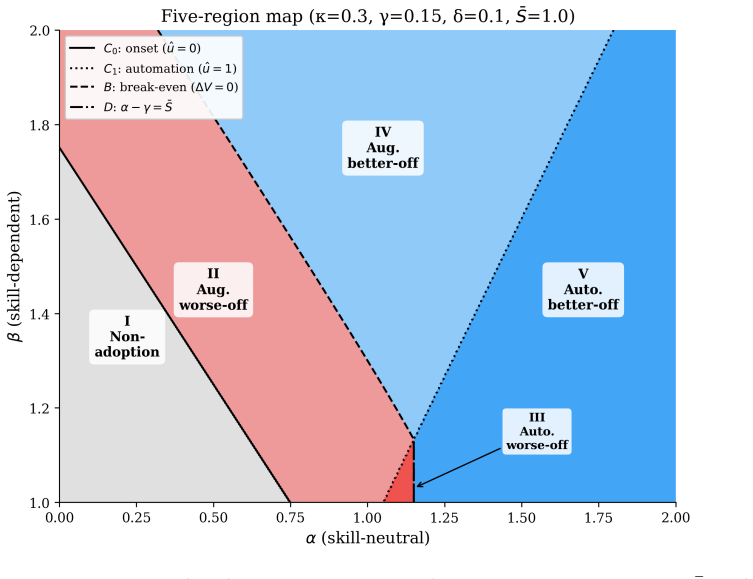
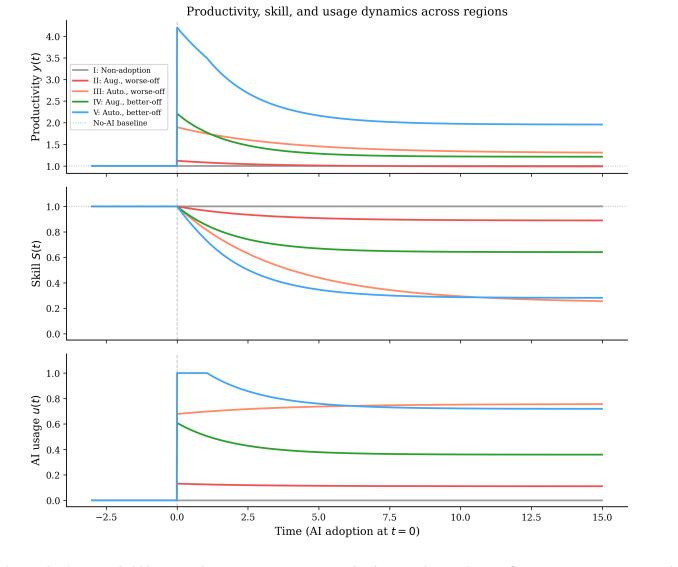
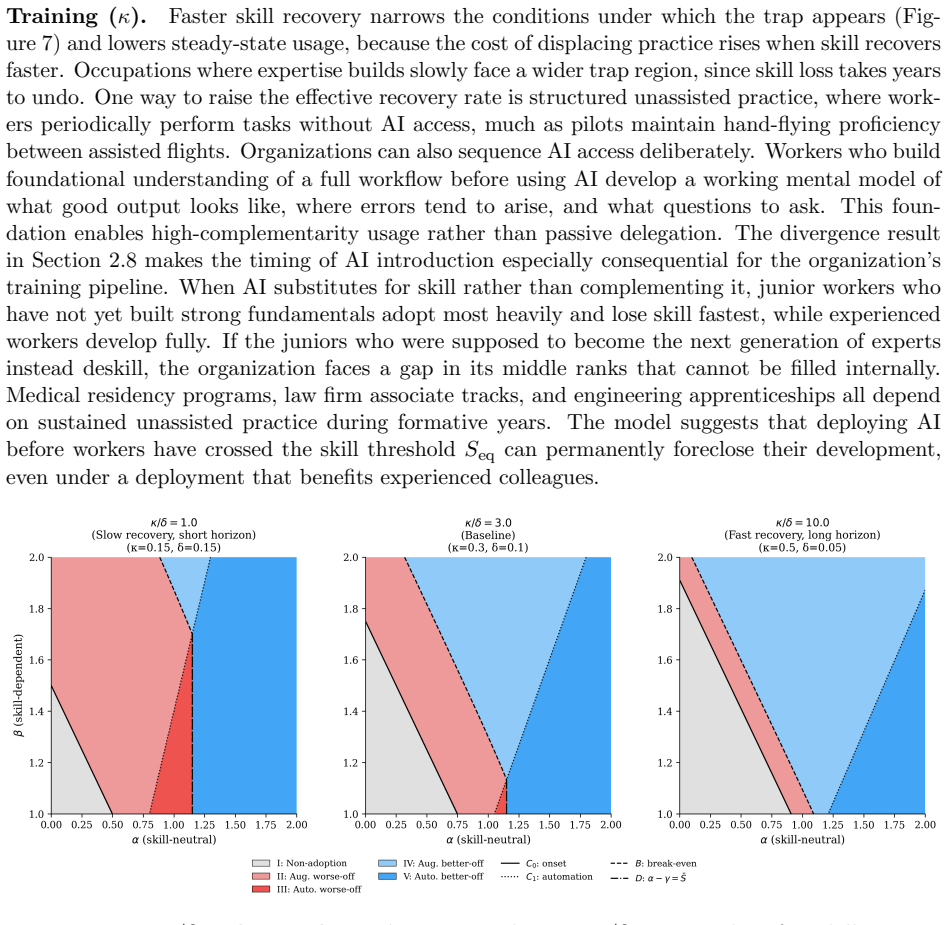
- The five regimes from the productivity decomposition separate beneficial from harmful AI deployments and highlight trap vulnerability.
Where Pith is reading between the lines
- Long-term contracts or skill-maintenance requirements could counteract the trap by aligning incentives with sustained expertise.
- Industries with heavy AI use may see widening gaps between high- and low-experience workers over time.
- Empirical tests could track specific skill metrics like problem-solving speed without AI assistance before and after rollout.
Load-bearing premise
Sustained AI use erodes worker expertise over time in a manner that can be separated from the immediate productivity gains and that this erosion dominates the long-run costs.
What would settle it
Track a cohort of workers' productivity on tasks without AI access over several years after introducing sustained AI assistance in their main work; if long-run productivity without the tool falls below the pre-AI baseline, the steady-state loss claim holds.
Figures
read the original abstract
Experimental evidence suggests that AI tools raise worker productivity, but also that sustained use can erode the expertise on which those gains depend. To explore the consequences of this tradeoff, we develop a dynamic model in which a decision-maker chooses AI usage intensity for a worker over time, trading immediate productivity against the erosion of worker skill. We decompose the tool's productivity effect into two channels, one independent of worker expertise and one that scales with it. The model produces three main results. First, a decision-maker who fully anticipates skill erosion still rationally adopts AI when front-loaded gains outweigh long-run skill costs, lowering long-run productivity. The decomposition sorts deployments into five regimes by their long-run effect, separating beneficial from harmful adoption. Second, the tradeoff introduces the potential for misaligned incentives. When the decision-maker does not bear the long-run skill cost, AI use can leave the worker worse off than with no AI, the outcome we call the augmentation trap. Third, when AI productivity depends little on worker expertise, the model can generate permanent divergence, with high-skill workers realizing their potential and low-skill workers deskilling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a dynamic model in which a decision-maker chooses AI usage intensity over time for a worker, trading immediate productivity gains against long-run erosion of expertise. Productivity is decomposed into an expertise-independent channel and an expertise-dependent channel that scales with skill. The model yields three results: (1) fully rational adoption can produce steady-state productivity below the pre-adoption level when front-loaded gains outweigh discounted skill costs; (2) short-termist managerial incentives or external skill value convert this into an 'augmentation trap' that leaves the worker strictly worse off; and (3) when AI productivity depends less on expertise, small incentive differences can drive permanent skill divergence, with experienced workers retaining full potential while others deskill to zero. Deployments are classified into five regimes that distinguish beneficial from harmful adoption.
Significance. If the skill-erosion premise and two-channel decomposition hold in practice, the framework supplies a useful analytical tool for distinguishing productive AI augmentation from deskilling traps and for classifying deployments by vulnerability. The explicit separation of channels and the derivation of regime boundaries constitute a clear theoretical contribution. However, the quantitative predictions rest entirely on the chosen functional forms and parameter values for erosion and productivity; without calibration, validation data, or robustness checks against alternative specifications, the results remain illustrative rather than predictive.
major comments (2)
- [Model and Results] The steady-state loss result (first main claim) and the augmentation trap (second claim) are generated directly from the model's chosen functional forms for the skill transition equation and the productivity decomposition P = f(independent) + g(expertise) * h(usage). The manuscript should demonstrate that these outcomes survive alternative specifications, such as multiplicative erosion, threshold-based decay, or recovery with non-use, which can produce interior steady states without net loss.
- [Abstract and Model Setup] The abstract and model description provide no empirical calibration, validation data, or robustness checks against real productivity or skill trajectories. Because soundness rests on whether the separable erosion premise matches observed settings, the paper should either supply external benchmarks or explicitly bound the domain of applicability.
minor comments (1)
- Notation for the two productivity channels and the five regimes would benefit from a summary table or diagram to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the scope and robustness of our theoretical framework. We have revised the manuscript to address the concerns about alternative specifications and domain of applicability. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Model and Results] The steady-state loss result (first main claim) and the augmentation trap (second claim) are generated directly from the model's chosen functional forms for the skill transition equation and the productivity decomposition P = f(independent) + g(expertise) * h(usage). The manuscript should demonstrate that these outcomes survive alternative specifications, such as multiplicative erosion, threshold-based decay, or recovery with non-use, which can produce interior steady states without net loss.
Authors: We agree that robustness to functional forms strengthens the contribution. In the revised version we have added Appendix C, which re-derives the steady-state and trap results under multiplicative erosion (decay proportional to current skill), threshold-based decay (erosion only above a usage intensity), and partial recovery during non-use periods. The core qualitative outcomes—steady-state productivity below the pre-adoption level and the augmentation trap under short-term incentives—persist across these specifications, although the exact parameter thresholds shift. We retain the original additive forms in the main text for analytical transparency while noting the conditions under which interior steady states without net loss can arise. revision: yes
-
Referee: [Abstract and Model Setup] The abstract and model description provide no empirical calibration, validation data, or robustness checks against real productivity or skill trajectories. Because soundness rests on whether the separable erosion premise matches observed settings, the paper should either supply external benchmarks or explicitly bound the domain of applicability.
Authors: This is a purely theoretical model paper; we cannot supply new empirical calibration or validation data without conducting a separate empirical study, which lies outside the current scope. We have, however, revised the abstract and Section 2 to explicitly bound the domain: the framework applies to settings in which AI use can produce cognitive offloading and skill erosion through reduced deliberate practice, consistent with existing empirical findings on AI productivity and expertise maintenance (now cited). We also state that quantitative predictions are illustrative and direct readers to the new robustness appendix for sensitivity to functional forms. revision: partial
- Supplying empirical calibration, validation data, or robustness checks against real productivity or skill trajectories, as the manuscript is a theoretical contribution without new data collection.
Circularity Check
Model derives results from explicit assumptions on erosion dynamics without reduction to inputs by construction.
full rationale
The paper presents a dynamic optimization model that decomposes productivity into independent and expertise-dependent channels and specifies a skill transition process. The three main results, including rational adoption producing steady-state loss, follow directly from solving the model under the stated functional forms and objective. No quoted equations show an output being redefined as its own input, no parameters are fitted to data then relabeled as predictions, and no load-bearing claims rest on self-citations. The derivation remains self-contained within the model's internal logic and stated premises, which is the standard structure for theoretical economic models.
Axiom & Free-Parameter Ledger
free parameters (2)
- erosion rate parameter
- expertise-scaling weight
axioms (2)
- domain assumption Worker expertise erodes monotonically with cumulative AI usage intensity.
- standard math Manager chooses usage intensity to maximize a discounted sum of productivity net of skill costs.
Forward citations
Cited by 1 Pith paper
-
Exploratory Responsiveness and Adaptive Rigidity under AI-Assisted Optimization
A dynamical framework is proposed where AI assistance substitutes for or amplifies exploratory search on rugged landscapes depending on the level of adaptive responsiveness.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.