Recognition: 1 theorem link
· Lean TheoremGroup of Skills: Group-Structured Skill Retrieval for Agent Skill Libraries
Pith reviewed 2026-05-11 01:03 UTC · model grok-4.3
The pith
Group-structured skill retrieval provides agents with compact role-labeled execution contexts built from skill graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GoSkills builds anchor-centered skill groups from a typed skill graph, expands support groups through a group graph, bottlenecks the selected group plan into a bounded set of atomic skill payloads, and renders a fixed execution contract with Start, Support, Check, and Avoid fields, without changing the downstream agent, skill payloads, or execution environment.
What carries the argument
Anchor-centered skill groups expanded via a group graph into fixed role-labeled execution contracts.
If this is right
- Preserves visible-requirement coverage under a small skill budget.
- Improves over flat skill-access baselines.
- Often improves reward and agent-only runtime relative to structural retrieval references.
Where Pith is reading between the lines
- This structured context could make it easier for agents to handle multi-step tasks by clarifying entry points and failure modes.
- The graph-based grouping might allow skill libraries to grow larger without overwhelming the agent with too many options.
- Applying similar grouping to other retrieval problems like tool use or planning could generalize the benefits.
Load-bearing premise
Typed skill graphs and associated group graphs can be constructed such that anchor-centered groups reliably produce role-labeled contexts beneficial to the agent without requiring changes to the agent, payloads, or environment.
What would settle it
A test case where the skill graph is absent or poorly constructed, checking whether GoSkills performance falls to the level of flat baselines on the same tasks.
Figures



read the original abstract
Skill-augmented agents increasingly rely on large reusable skill libraries, but retrieving relevant skills is not the same as presenting usable context. Existing methods typically return atomic skills or dependency-aware bundles whose internal roles remain implicit, leaving the agent to infer the execution entry point, support skills, visible requirements, and failure-avoidance guidance. We introduce Group of Skills (GoSkills), an inference-time group-structured retrieval method that changes the agent-facing retrieval object from a flat skill list to a compact, role-labeled execution context. GoSkills builds anchor-centered skill groups from a typed skill graph, expands support groups through a group graph, bottlenecks the selected group plan into a bounded set of atomic skill payloads, and renders a fixed execution contract with Start, Support, Check, and Avoid fields, without changing the downstream agent, skill payloads, or execution environment. Experiments on SkillsBench and ALFWorld show that GoSkills preserves visible-requirement coverage under a small skill budget, improves over flat skill-access baselines, and often improves reward and agent-only runtime relative to structural retrieval references.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Group of Skills (GoSkills), an inference-time group-structured skill retrieval method that builds anchor-centered skill groups from a typed skill graph, expands support groups through a group graph, bottlenecks the selected groups into a bounded set of atomic skill payloads, and renders a fixed execution contract with explicit Start, Support, Check, and Avoid role fields. The central claim is that this changes the agent-facing retrieval object from a flat list to a compact role-labeled context, preserving visible-requirement coverage under small skill budgets while improving over flat baselines and often improving reward and agent-only runtime relative to structural retrieval references on SkillsBench and ALFWorld, without any changes to the downstream agent, skill payloads, or execution environment.
Significance. If the experimental outcomes hold, the contribution is significant for skill-augmented agents because it supplies structured, role-explicit context rather than leaving role inference to the agent. The inference-time, drop-in character is a practical strength that maintains full compatibility with existing agents and environments. The emphasis on preserving coverage while reducing context size directly targets a real usability bottleneck in large skill libraries.
major comments (1)
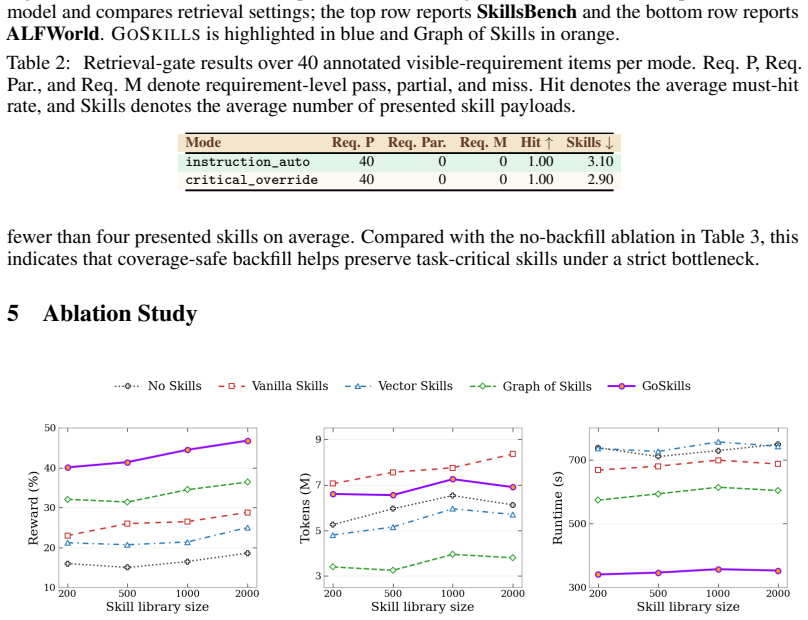
- [Abstract and §4] Abstract and §4 (Experiments): The performance claims of improved reward, runtime, and coverage preservation are presented only qualitatively (e.g., “improves over”, “often improves”) with no numerical values, error bars, ablation results, or statistical tests. No details are given on how the typed skill graph or group graph is constructed, how anchor groups are chosen, or how the bottleneck to atomic payloads is performed. These omissions are load-bearing because the central empirical claim cannot be verified or reproduced from the text.
minor comments (2)
- [§3] The role labels (Start, Support, Check, Avoid) are introduced in the abstract and method description but would benefit from an explicit formal definition or running example early in §3 to clarify how each field is populated from the group expansion.
- Figure captions and axis labels in the experimental graphs should explicitly state the skill budget, the exact baselines, and the metric definitions (e.g., what constitutes “visible-requirement coverage”) to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the presentation of results and methodological details. We address the major comment point by point below and will incorporate the suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The performance claims of improved reward, runtime, and coverage preservation are presented only qualitatively (e.g., “improves over”, “often improves”) with no numerical values, error bars, ablation results, or statistical tests. No details are given on how the typed skill graph or group graph is constructed, how anchor groups are chosen, or how the bottleneck to atomic payloads is performed. These omissions are load-bearing because the central empirical claim cannot be verified or reproduced from the text.
Authors: We agree that the current presentation of experimental outcomes relies on qualitative phrasing and that additional quantitative detail and methodological exposition are required for full verifiability and reproducibility. In the revision we will replace the qualitative statements in the abstract with concrete numerical comparisons (e.g., mean reward deltas, runtime reductions, and coverage percentages) drawn from the SkillsBench and ALFWorld runs already performed. Section 4 will be expanded to include tables reporting exact values together with standard deviations across repeated trials, ablation results on key design choices, and the results of statistical significance tests where appropriate. For the construction details, we will add a new subsection (or substantially enlarge §3) that specifies: (i) the procedure for building the typed skill graph from skill metadata, (ii) the anchor-selection criterion and its implementation, (iii) the group-graph expansion algorithm, and (iv) the exact bottleneck routine that maps selected groups to a bounded atomic payload while populating the Start/Support/Check/Avoid roles. Pseudocode, parameter settings, and a worked example will be supplied so that the pipeline can be re-implemented from the text alone. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents GoSkills as an inference-time construction that builds anchor-centered groups from a typed skill graph, expands via a group graph, bottlenecks to atomic payloads, and renders a fixed role-labeled contract (Start/Support/Check/Avoid). No equations, fitted parameters, or predictions are defined in the provided text. The central procedure is described procedurally and independently of the downstream agent, skill payloads, or environment. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. Experimental claims on SkillsBench and ALFWorld are presented as external empirical outcomes rather than reductions to the method's own inputs by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GOSKILLS builds anchor-centered skill groups from a typed skill graph, expands support groups through a group graph, bottlenecks the selected group plan into a bounded set of atomic skill payloads, and renders a fixed execution contract with START, SUPPORT, CHECK, and AVOID fields
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Toolformer: Language Models Can Teach Themselves to Use Tools , url =
Schick, Timo and Dwivedi-Yu, Jane and Dessi, Roberto and Raileanu, Roberta and Lomeli, Maria and Hambro, Eric and Zettlemoyer, Luke and Cancedda, Nicola and Scialom, Thomas , booktitle =. Toolformer: Language Models Can Teach Themselves to Use Tools , url =
-
[2]
Augmented language models: a survey
Augmented language models: a survey , author=. arXiv preprint arXiv:2302.07842 , year=
-
[3]
Patil, Tianjun Zhang, Xin Wang, and Joseph E
Patil, Shishir G. and Zhang, Tianjun and Wang, Xin and Gonzalez, Joseph E. , booktitle =. Gorilla: Large Language Model Connected with Massive APIs , url =. doi:10.52202/079017-4020 , editor =
-
[4]
Yujia Qin and Shihao Liang and Yining Ye and Kunlun Zhu and Lan Yan and Yaxi Lu and Yankai Lin and Xin Cong and Xiangru Tang and Bill Qian and Sihan Zhao and Lauren Hong and Runchu Tian and Ruobing Xie and Jie Zhou and Mark Gerstein and dahai li and Zhiyuan Liu and Maosong Sun , booktitle=. Tool. 2024 , url=
2024
-
[5]
Retrieval Models Aren ' t Tool-Savvy: Benchmarking Tool Retrieval for Large Language Models
Shi, Zhengliang and Wang, Yuhan and Yan, Lingyong and Ren, Pengjie and Wang, Shuaiqiang and Yin, Dawei and Ren, Zhaochun. Retrieval Models Aren ' t Tool-Savvy: Benchmarking Tool Retrieval for Large Language Models. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1258
-
[6]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
SkillsBench: Benchmarking how well agent skills work across diverse tasks , author=. arXiv preprint arXiv:2602.12670 , year=
work page internal anchor Pith review arXiv
-
[7]
SkillNet: Create, evaluate, and connect AI skills,
Skillnet: Create, evaluate, and connect ai skills , author=. arXiv preprint arXiv:2603.04448 , year=
-
[8]
Organizing, orchestrating, and benchmarking agent skills at ecosystem scale, 2026
Organizing, Orchestrating, and Benchmarking Agent Skills at Ecosystem Scale , author=. arXiv preprint arXiv:2603.02176 , year=
-
[9]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
From local to global: A graph rag approach to query-focused summarization , author=. arXiv preprint arXiv:2404.16130 , year=
work page internal anchor Pith review arXiv
-
[10]
Bernal Jimenez Gutierrez and Yiheng Shu and Yu Gu and Michihiro Yasunaga and Yu Su , booktitle=. Hippo. 2024 , url=
2024
-
[11]
European Conference on Computer Vision , pages=
Controlllm: Augment language models with tools by searching on graphs , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[12]
ToolNet: Connecting large language models with massive tools via tool graph,
Toolnet: Connecting large language models with massive tools via tool graph , author=. arXiv preprint arXiv:2403.00839 , year=
-
[13]
Graph of Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Graph of Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills , author=. arXiv preprint arXiv:2604.05333 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
GraSP: Graph-Structured Skill Compositions for LLM Agents
GraSP: Graph-Structured Skill Compositions for LLM Agents , author=. arXiv preprint arXiv:2604.17870 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
The Eleventh International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. The Eleventh International Conference on Learning Representations , year=
-
[16]
Yuchen Zhuang and Yue Yu and Kuan Wang and Haotian Sun and Chao Zhang , booktitle=. Tool. 2023 , url=
2023
-
[17]
2021 , url=
Mohit Shridhar and Xingdi Yuan and Marc-Alexandre Cote and Yonatan Bisk and Adam Trischler and Matthew Hausknecht , booktitle=. 2021 , url=
2021
-
[18]
Introducing Claude Sonnet 4.5 , year =
-
[19]
2026 , month = mar, day =
2026
-
[20]
2026 , howpublished =
2026
-
[21]
2026 , month = feb, day =
2026
-
[22]
2026 , month = jan, day =
2026
-
[23]
2025 , month = nov, day =
Pichai, Sundar and Hassabis, Demis and Kavukcuoglu, Koray , title =. 2025 , month = nov, day =
2025
-
[24]
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
SoK: Agentic Skills--Beyond Tool Use in LLM Agents , author=. arXiv preprint arXiv:2602.20867 , year=
work page internal anchor Pith review arXiv
-
[25]
2026 , eprint=
SkillX: Automatically Constructing Skill Knowledge Bases for Agents , author=. 2026 , eprint=
2026
-
[26]
2025 , eprint=
LEGOMem: Modular Procedural Memory for Multi-agent LLM Systems for Workflow Automation , author=. 2025 , eprint=
2025
-
[27]
Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages=
Towards completeness-oriented tool retrieval for large language models , author=. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages=
-
[28]
Measuring Coding Challenge Competence With APPS , url =
Hendrycks, Dan and Basart, Steven and Kadavath, Saurav and Mazeika, Mantas and Arora, Akul and Guo, Ethan and Burns, Collin and Puranik, Samir and He, Horace and Song, Dawn and Steinhardt, Jacob , booktitle =. Measuring Coding Challenge Competence With APPS , url =
-
[29]
Acon: Optimizing context compression for long-horizon llm agents , author=. arXiv preprint arXiv:2510.00615 , year=
-
[30]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Grammar-constrained decoding for structured NLP tasks without finetuning , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[31]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Api-bank: A comprehensive benchmark for tool-augmented llms , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[32]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
RepoShapley: Shapley-Enhanced Context Filtering for Repository-Level Code Completion
RepoShapley: Shapley-Enhanced Context Filtering for Repository-Level Code Completion , author=. arXiv preprint arXiv:2601.03378 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents , author=. arXiv preprint arXiv:2602.02474 , year=
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.