Recognition: unknown
The ATOM Report: Measuring the Open Language Model Ecosystem
Pith reviewed 2026-05-10 17:29 UTC · model grok-4.3
The pith
Chinese open language models overtook U.S. models in summer 2025 and have since widened the gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
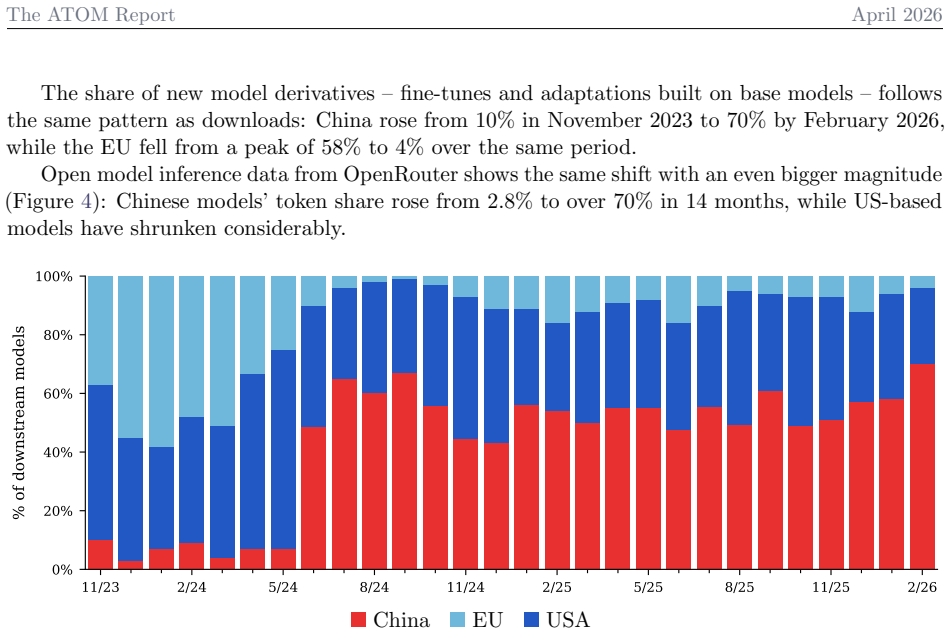
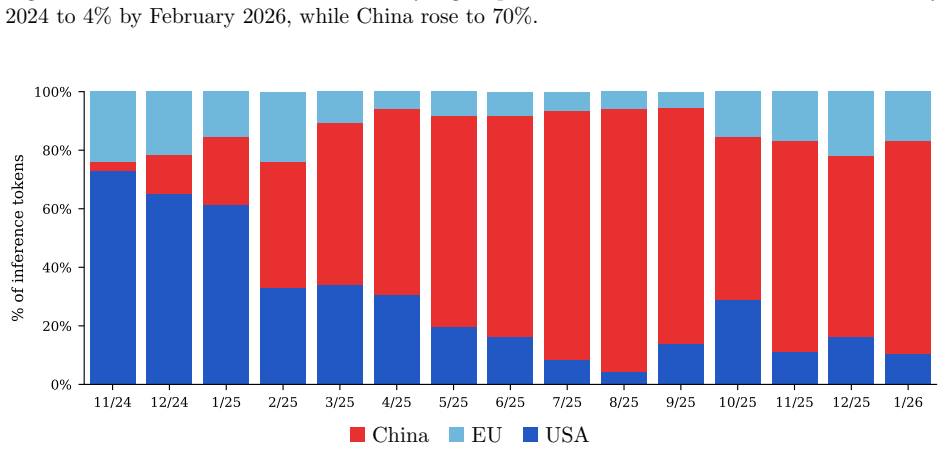
Combining Hugging Face downloads, model derivatives, inference market share, and performance metrics shows that Chinese open language models overtook their U.S. counterparts in the summer of 2025 and have subsequently increased their lead over Western models.
What carries the argument
Multi-indicator adoption snapshot that aggregates download counts, derivative creation, inference usage, and benchmark scores across the set of approximately 1,500 mainline open models.
If this is right
- Leadership in open model development has shifted toward Chinese organizations.
- Researchers and startups will increasingly build on Chinese-origin foundations.
- Policy discussions must incorporate this change when addressing technology competition and access.
- The open ecosystem is no longer centered on a single national source of models.
Where Pith is reading between the lines
- Continued growth in Chinese model usage could make future AI research and applications more dependent on non-Western infrastructure.
- The same multi-metric tracking approach could be applied to other model categories such as vision or multimodal systems to detect similar geographic shifts.
- These adoption figures may influence decisions on international standards or collaboration rules for open AI tools.
Load-bearing premise
The chosen combination of download counts, derivative activity, inference share, and performance scores accurately reflects real-world adoption and influence without systematic bias.
What would settle it
Independent usage data from sources outside Hugging Face and the listed metrics showing that U.S. models retained majority adoption or influence after summer 2025 would undermine the overtake claim.
Figures















read the original abstract
We present a comprehensive adoption snapshot of the leading open language models and who is building them, focusing on the ~1.5K mainline open models from the likes of Alibaba's Qwen, DeepSeek, Meta's Llama, that are the foundation of an ecosystem crucial to researchers, entrepreneurs, and policy advisors. We document a clear trend where Chinese models overtook their counterparts built in the U.S. in the summer of 2025 and subsequently widened the gap over their western counterparts. We study a mix of Hugging Face downloads and model derivatives, inference market share, performance metrics and more to make a comprehensive picture of the ecosystem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a comprehensive adoption snapshot of the leading open language model ecosystem, focusing on the ~1.5K mainline open models from developers including Alibaba's Qwen, DeepSeek, and Meta's Llama. It documents a clear trend in which Chinese models overtook their U.S. counterparts in summer 2025 and subsequently widened the gap, derived from a composite of Hugging Face downloads, model derivatives, inference market share, performance metrics, and related indicators.
Significance. If the reported temporal overtake and gap-widening hold after methodological clarification, the work supplies timely empirical data on shifting global open-model influence with direct relevance to AI policy, research prioritization, and ecosystem monitoring. The multi-indicator approach is a positive feature for a measurement study, though its value hinges on transparent handling of sampling and regional biases.
major comments (3)
- [Abstract] Abstract: The central claim of Chinese models overtaking U.S. models in summer 2025 is presented without any description of data-cleaning rules, inclusion criteria for the ~1.5K model sample, or adjustments for selection bias; these omissions make the trend unverifiable from the provided information.
- [Abstract] Abstract (inference market share component): No details are given on how inference market share was measured or whether the metric incorporates usage outside Hugging Face (e.g., ModelScope, Chinese cloud platforms, or local deployments); without such cross-validation the overtake timing and subsequent widening are sensitive to platform-specific sampling bias.
- [Abstract] Abstract (composite metrics): The paper states that a 'mix' of downloads, derivatives, inference share, and performance metrics yields the comprehensive picture, yet provides no information on weighting, aggregation rules, or robustness checks; this is load-bearing for interpreting the claimed gap-widening.
minor comments (2)
- [Abstract] Abstract: The qualifier 'and more' is imprecise; enumerate the full set of indicators used to construct the ecosystem picture.
- [Throughout] Terminology: 'Western counterparts' and 'U.S. models' appear to be used interchangeably; adopt consistent geographic labeling throughout.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We agree that greater transparency is needed in the abstract regarding methodology and have revised the manuscript accordingly to strengthen verifiability while preserving the high-level summary. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of Chinese models overtaking U.S. models in summer 2025 is presented without any description of data-cleaning rules, inclusion criteria for the ~1.5K model sample, or adjustments for selection bias; these omissions make the trend unverifiable from the provided information.
Authors: The full manuscript details the sample construction in Section 2 (Data Sources and Scope), including explicit inclusion criteria focused on mainline models from leading developers (Qwen, DeepSeek, Llama and similar), exclusion of minor fine-tunes and duplicates, and basic data-cleaning steps such as removing inactive repositories. Potential selection biases (e.g., toward English-language metadata on Hugging Face) are discussed in the limitations subsection. To address the abstract-level concern, we have added a concise clause referencing the ~1.5K mainline model sample and directing readers to the methods for full criteria and cleaning rules. revision: yes
-
Referee: [Abstract] Abstract (inference market share component): No details are given on how inference market share was measured or whether the metric incorporates usage outside Hugging Face (e.g., ModelScope, Chinese cloud platforms, or local deployments); without such cross-validation the overtake timing and subsequent widening are sensitive to platform-specific sampling bias.
Authors: Inference share is derived from Hugging Face's public inference endpoint usage statistics and download volume as the primary observable proxy for open-model adoption. We acknowledge that this metric does not incorporate usage on ModelScope, Chinese cloud providers, or fully local deployments, which could understate Chinese model activity. We have expanded the limitations section to explicitly note this platform-specific bias and have added a robustness note that the overtake trend appears consistently across the other non-inference indicators (downloads, derivatives, benchmarks). Full cross-validation with non-public platform data is not possible with publicly available sources. revision: partial
-
Referee: [Abstract] Abstract (composite metrics): The paper states that a 'mix' of downloads, derivatives, inference share, and performance metrics yields the comprehensive picture, yet provides no information on weighting, aggregation rules, or robustness checks; this is load-bearing for interpreting the claimed gap-widening.
Authors: The composite view is a qualitative convergence of independent indicators rather than a single weighted index; each metric is reported separately in the results section, and the gap-widening claim rests on the alignment of trends across them. We have revised the abstract and added an explicit paragraph in Section 4 describing this narrative-synthesis approach, along with per-indicator robustness plots that confirm the overtake timing holds when any single metric is removed. No formal weighting scheme is used, which we now state clearly to avoid implying quantitative precision. revision: yes
Circularity Check
No circularity: empirical measurement report with no derivation chain
full rationale
The paper is a data-driven measurement report that aggregates Hugging Face downloads, model derivatives, inference market share, and performance metrics to document adoption trends. It contains no equations, fitted parameters presented as predictions, self-definitional constructs, or load-bearing self-citations that reduce claims to inputs by construction. The central observation (Chinese models overtaking US models in summer 2025) is an empirical snapshot, not a derived result that loops back to its own definitions or prior author work. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
DeGenTWeb: A First Look at LLM-dominant Websites
DeGenTWeb shows LLM-dominant websites are common and increasing in Common Crawl and Bing search results, but accurate detection is getting harder with newer models.
Reference graph
Works this paper leans on
-
[1]
The data provenance initiative: A large scale audit of dataset licensing & attribution in AI
LMSYS Org blog post, published August 29, 2024. Shayne Longpre et al. The data provenance initiative: A large scale audit of dataset licensing & attribution in AI.arXiv preprint arXiv:2310.16787, 2023. URL https://arxiv.org/abs/2310. 16787. Shayne Longpre et al. Consent in crisis: The rapid decline of the AI data commons.arXiv preprint arXiv:2407.14933, 2...
-
[2]
Qwen2.5-Coder-0.5B-Instruct (13.5M)
Qwen3-0.6B (72.8M) 6. Qwen2.5-Coder-0.5B-Instruct (13.5M)
-
[3]
Qwen2-0.5B (10.7M)
Qwen2.5-0.5B-Instruct (32.3M) 7. Qwen2-0.5B (10.7M)
-
[4]
SmolLM2-135M (10.5M)
Florence-2-large (19.4M) 8. SmolLM2-135M (10.5M)
-
[5]
Florence-2-base (8.8M)
t5gemma-b-b-prefixlm (17.5M) 9. Florence-2-base (8.8M)
-
[6]
llava-onevision-qwen2-0.5b-ov-hf (8.4M) 1-5B
Qwen2.5-0.5B (17.1M) 10. llava-onevision-qwen2-0.5b-ov-hf (8.4M) 1-5B
-
[7]
Llama-3.2-3B-Instruct (37M)
Qwen2.5-1.5B-Instruct (150.6M) 6. Llama-3.2-3B-Instruct (37M)
-
[8]
gemma-3-1b-it (34.9M)
Qwen2.5-VL-3B-Instruct (70.7M) 7. gemma-3-1b-it (34.9M)
-
[9]
Qwen2-VL-2B-Instruct (30M)
Qwen2.5-3B-Instruct (70.1M) 8. Qwen2-VL-2B-Instruct (30M)
-
[10]
Qwen3-4B (29.7M)
Llama-3.2-1B-Instruct (55.7M) 9. Qwen3-4B (29.7M)
-
[11]
Qwen3-1.7B (29.2M) 7-9B
Llama-3.2-1B (49.2M) 10. Qwen3-1.7B (29.2M) 7-9B
-
[12]
Meta-Llama-3-8B-Instruct (38.9M)
Llama-3.1-8B-Instruct (133M) 6. Meta-Llama-3-8B-Instruct (38.9M)
-
[13]
Meta-Llama-3-8B (36.6M)
Qwen2.5-7B-Instruct (109M) 7. Meta-Llama-3-8B (36.6M)
-
[14]
Llama-2-7b-chat-hf (29.2M)
Mistral-7B-Instruct-v0.2 (53.5M) 8. Llama-2-7b-chat-hf (29.2M)
-
[15]
Llama-2-7b-hf (28.4M)
Qwen2.5-VL-7B-Instruct (51.2M) 9. Llama-2-7b-hf (28.4M)
-
[16]
falcon-7b-instruct (26.7M) 4Also see related, recurring work in this direction from Hugging Face directly (Ghosh et al., 2026)
Qwen3-8B (42.5M) 10. falcon-7b-instruct (26.7M) 4Also see related, recurring work in this direction from Hugging Face directly (Ghosh et al., 2026). atomproject.ai/report 20 / 23 The ATOM Report April 2026 10-50B
2026
-
[17]
Qwen2.5-32B-Instruct (18.5M)
gpt-oss-20b (54M) 6. Qwen2.5-32B-Instruct (18.5M)
-
[18]
Llama-3.2-11B-Vision-Instruct (17.6M)
Qwen2.5-14B-Instruct (33.3M) 7. Llama-3.2-11B-Vision-Instruct (17.6M)
-
[19]
Llama-2-13b-chat-hf (15.2M)
Qwen3-32B (24.6M) 8. Llama-2-13b-chat-hf (15.2M)
-
[20]
Qwen3-VL-30B-A3B-Instruct (13.2M)
DeepSeek-R1-Distill-Qwen-32B (23M) 9. Qwen3-VL-30B-A3B-Instruct (13.2M)
-
[21]
gemma-3-27b-it (12.3M) 50-100B
Mixtral-8x7B-Instruct-v0.1 (20M) 10. gemma-3-27b-it (12.3M) 50-100B
-
[22]
Qwen2.5-VL-72B-Instruct (5.7M)
Llama-3.1-70B-Instruct (20.2M) 6. Qwen2.5-VL-72B-Instruct (5.7M)
-
[23]
Qwen2.5-72B-Instruct (5.4M)
Qwen3-Next-80B-A3B-Instruct (14.6M) 7. Qwen2.5-72B-Instruct (5.4M)
-
[24]
Llama-2-70b-chat-hf (4.6M)
Llama-3.3-70B-Instruct (10.3M) 8. Llama-2-70b-chat-hf (4.6M)
-
[25]
DeepSeek-R1-Distill-Llama-70B (4.3M)
InternVL3-78B (6.2M) 9. DeepSeek-R1-Distill-Llama-70B (4.3M)
-
[26]
Meta-Llama-3-70B (3.2M) 100-250B
Meta-Llama-3-70B-Instruct (5.9M) 10. Meta-Llama-3-70B (3.2M) 100-250B
-
[27]
InternVL3 5-241B-A28B-Instruct (4.1M)
gpt-oss-120b (29.2M) 6. InternVL3 5-241B-A28B-Instruct (4.1M)
-
[28]
Qwen3-235B-A22B (3.4M)
Mixtral-8x22B-Instruct-v0.1 (6M) 7. Qwen3-235B-A22B (3.4M)
-
[29]
Qwen3-VL-235B-A22B-Thinking (3.3M)
Mistral-Large-Instruct-2407 (5M) 8. Qwen3-VL-235B-A22B-Thinking (3.3M)
-
[30]
Qwen3-235B-A22B-Instruct-2507-FP8 (2.7M)
Mistral-Large-Instruct-2411 (4.9M) 9. Qwen3-235B-A22B-Instruct-2507-FP8 (2.7M)
-
[31]
MiniMax-M2 (1.9M) 250B+
Mixtral-8x22B-v0.1 (4.8M) 10. MiniMax-M2 (1.9M) 250B+
-
[32]
GLM-5-FP8 (4.9M)
Llama-3.1-405B (20.3M) 6. GLM-5-FP8 (4.9M)
-
[33]
DeepSeek-V3-0324 (4M)
DeepSeek-R1 (16.7M) 7. DeepSeek-V3-0324 (4M)
-
[34]
Llama-3.1-405B-Instruct (3.4M)
DeepSeek-V3 (14.3M) 8. Llama-3.1-405B-Instruct (3.4M)
-
[35]
Qwen3.5-397B-A17B (2.1M)
DeepSeek-R1-0528 (5.9M) 9. Qwen3.5-397B-A17B (2.1M)
-
[36]
Kimi-K2-Instruct (1.8M) C Additional RAM Details The top-10 model download counts over time, used to compute the RAM scores, is shown in Figure 17
Kimi-K2.5 (5.4M) 10. Kimi-K2-Instruct (1.8M) C Additional RAM Details The top-10 model download counts over time, used to compute the RAM scores, is shown in Figure 17. This shows that among the top few models in each size category, the median of top-10 downloads over the first 180 days is remarkably similar across buckets. The smallest models have larger...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.