Recognition: unknown
HiveMind: OS-Inspired Scheduling for Concurrent LLM Agent Workloads
Pith reviewed 2026-05-10 06:08 UTC · model grok-4.3
The pith
An HTTP proxy applies operating system scheduling to let multiple LLM agents share rate-limited APIs without crashing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
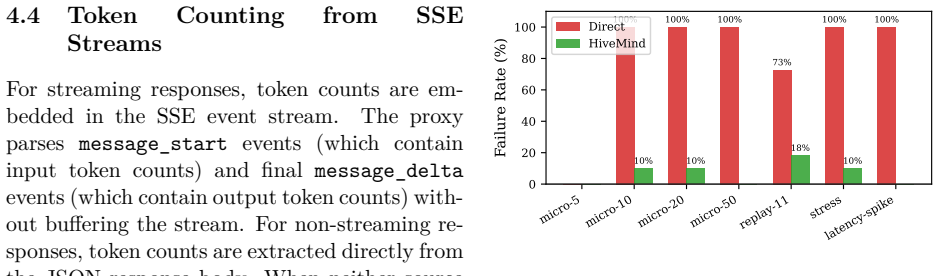
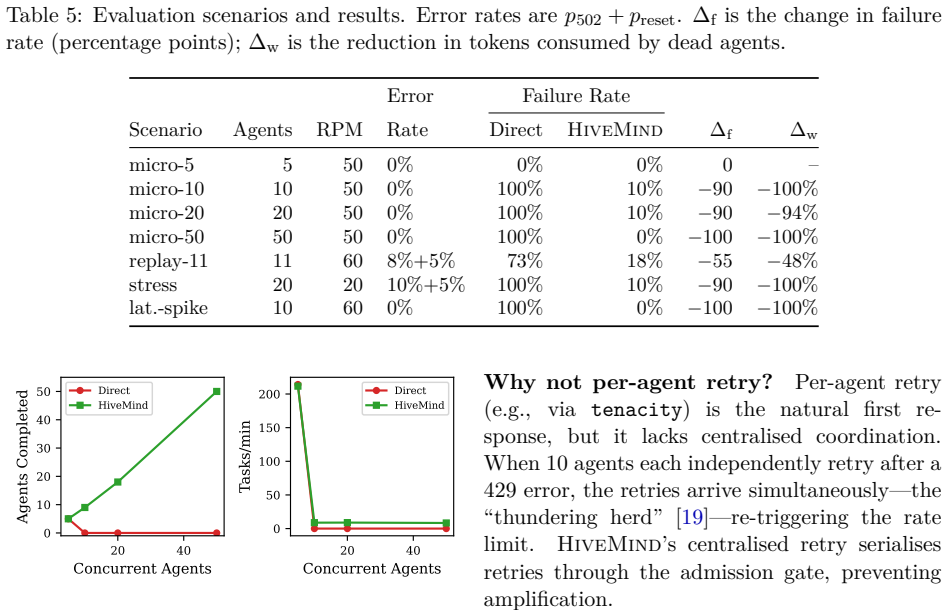
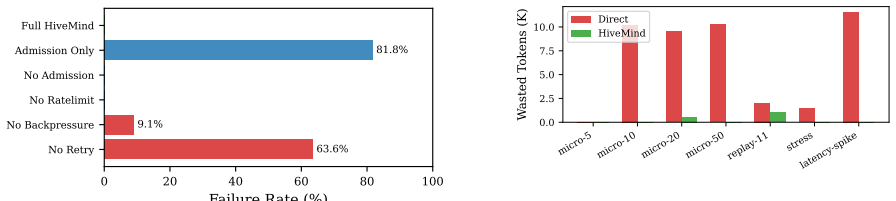
HIVEMIND is a transparent HTTP proxy that coordinates concurrent LLM agents by applying five operating-system scheduling primitives to shared API endpoints. The primitives are admission control, rate-limit tracking, AIMD backpressure with circuit breaking, token budget management, and priority queuing. In seven scenarios the proxy reduces failure rates from 72-100 percent to 0-18 percent and eliminates 48-100 percent of wasted compute while requiring zero changes to existing agent code and adding under three milliseconds of overhead per request.
What carries the argument
The HIVEMIND transparent HTTP proxy that enforces five OS-inspired scheduling primitives on requests to rate-limited LLM APIs.
If this is right
- Concurrent LLM agents can run at higher parallelism on shared APIs without each agent implementing its own coordination logic.
- Most failed requests and the compute spent on them are eliminated when the five primitives operate together.
- The proxy works for Anthropic, OpenAI, and local models through auto-detected profiles and requires no code changes.
- Transparent retry is the single most important primitive, but the full set outperforms any subset.
- Real deployments see negligible added latency and can therefore adopt the approach immediately.
Where Pith is reading between the lines
- The same proxy pattern could manage other contended resources such as local GPU queues for open-weight models.
- Developers may now attempt larger multi-agent systems that were previously abandoned because of unpredictable API collisions.
- The low-overhead design suggests the approach can be inserted into standard agent orchestration tools without redesign.
Load-bearing premise
The seven evaluation scenarios with five to fifty agents capture the contention patterns that appear in diverse real-world LLM agent workloads and API behaviors.
What would settle it
A new workload of thirty concurrent agents on an API with different rate-limit dynamics that still produces failure rates above twenty percent when HIVEMIND is inserted would show the primitives do not generalize.
Figures


read the original abstract
When multiple LLM coding agents share a rate-limited API endpoint, they exhibit resource contention patterns analogous to unscheduled OS processes competing for CPU, memory, and I/O. In a motivating incident, 3 of 11 parallel agents died from connection resets and HTTP 502 errors - a 27% failure rate - despite the API having sufficient aggregate capacity to serve all 11 sequentially. We present HIVEMIND, a transparent HTTP proxy that applies five OS-inspired scheduling primitives - admission control, rate-limit tracking, AIMD backpressure with circuit breaking, token budget management, and priority queuing - to eliminate the failure modes caused by uncoordinated parallel execution. The proxy requires zero modifications to existing agent code and supports Anthropic, OpenAI, and local model APIs via auto-detected provider profiles. Our evaluation across seven scenarios (5-50 concurrent agents) shows that uncoordinated agents fail at 72-100% rates under contention, while HIVEMIND reduces failures to 0-18% and eliminates 48-100% of wasted compute. An ablation study reveals that transparent retry - not admission control - is the single most critical primitive, but the primitives are most effective in combination. Real-world validation against Ollama confirms that HIVEMIND adds under 3ms of proxy overhead per request. The system is open-source under the MIT license.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HiveMind, a transparent HTTP proxy implementing five OS-inspired scheduling primitives (admission control, rate-limit tracking, AIMD backpressure with circuit breaking, token budget management, and priority queuing) to mitigate resource contention when multiple LLM coding agents share rate-limited APIs from providers such as Anthropic, OpenAI, and Ollama. It reports a motivating incident with 27% failure rate among 11 agents and claims that across seven scenarios (5-50 concurrent agents), uncoordinated execution yields 72-100% failure rates while HiveMind reduces failures to 0-18%, eliminates 48-100% of wasted compute, adds under 3 ms overhead, and benefits most from the combined primitives per an ablation study. The system requires zero agent code changes and is released open-source under MIT.
Significance. If the evaluation holds and generalizes, this would be a practically significant systems contribution for concurrent LLM agent deployments, demonstrating a lightweight, provider-agnostic proxy that applies established OS scheduling ideas to reduce failures and wasted compute without modifying agent code. The low measured overhead, open-source release, and ablation identifying the value of combined primitives are strengths that could influence production tooling for multi-agent workflows.
major comments (3)
- [Evaluation] Evaluation section: the central empirical claims (uncoordinated failure rates of 72-100% vs. HIVEMIND 0-18%, plus 48-100% wasted compute elimination) depend on the seven scenarios faithfully modeling real rate-limited API contention, but the manuscript provides no details on how contention was generated (exact rate limits, error injection, request size distributions, or whether agents were modified to trigger specific failure modes). This is load-bearing for assessing whether the measured improvements transfer beyond the synthetic setups to production Anthropic/OpenAI/Ollama behaviors.
- [Abstract] Abstract and motivating incident: the single incident (3/11 agents failing) is cited to motivate the work, but with such a small sample it cannot robustly anchor the generalization claims made for the seven scenarios spanning 5-50 agents; the manuscript should quantify variability across runs or provide statistical significance for the failure reductions.
- [Evaluation] Ablation study: the claim that transparent retry is the single most critical primitive (yet most effective in combination) is presented without reporting the per-primitive failure rates or wasted compute numbers from the ablation; this makes it impossible to verify the relative contributions and whether the combination effect is additive or synergistic.
minor comments (2)
- [Abstract] The abstract states support for 'local model APIs via auto-detected provider profiles' but does not specify which local servers (beyond the Ollama overhead measurement) or how profile detection works; a brief description would improve clarity.
- [Evaluation] The paper should include a table summarizing the seven scenarios (agent count, workload type, API provider, measured failure rates with and without HIVEMIND) to make the quantitative results easier to parse.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important areas for improving the clarity, reproducibility, and rigor of the evaluation. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central empirical claims (uncoordinated failure rates of 72-100% vs. HIVEMIND 0-18%, plus 48-100% wasted compute elimination) depend on the seven scenarios faithfully modeling real rate-limited API contention, but the manuscript provides no details on how contention was generated (exact rate limits, error injection, request size distributions, or whether agents were modified to trigger specific failure modes). This is load-bearing for assessing whether the measured improvements transfer beyond the synthetic setups to production Anthropic/OpenAI/Ollama behaviors.
Authors: We agree that the current manuscript lacks sufficient detail on the experimental setup, which limits assessment of how faithfully the scenarios model production contention. In the revised version, we will expand the Evaluation section with a new subsection describing the exact rate-limit configurations applied for each provider profile, the request size and token distributions used to generate workloads, the process for inducing contention (including how API responses such as rate-limit errors were handled), and explicit confirmation that no modifications were made to any agent code. These additions will be based on the test harness used for the reported results and will directly address transferability concerns. revision: yes
-
Referee: [Abstract] Abstract and motivating incident: the single incident (3/11 agents failing) is cited to motivate the work, but with such a small sample it cannot robustly anchor the generalization claims made for the seven scenarios spanning 5-50 agents; the manuscript should quantify variability across runs or provide statistical significance for the failure reductions.
Authors: The single motivating incident is presented strictly as an anecdotal observation that prompted the work, not as statistical evidence supporting the main claims. The primary results and generalization rest on the seven controlled scenarios. We will revise the abstract, introduction, and Evaluation section to explicitly distinguish the incident from the empirical evaluation and will add measures of variability (such as standard deviation or min/max ranges across repeated runs) for the reported failure rates and wasted-compute figures to provide the requested statistical context. revision: partial
-
Referee: [Evaluation] Ablation study: the claim that transparent retry is the single most critical primitive (yet most effective in combination) is presented without reporting the per-primitive failure rates or wasted compute numbers from the ablation; this makes it impossible to verify the relative contributions and whether the combination effect is additive or synergistic.
Authors: We acknowledge that the ablation results are summarized at a high level without the underlying per-primitive metrics, making independent verification difficult. In the revision, we will add a detailed table (or expanded figure) in the Evaluation section that reports failure rates and wasted-compute percentages for each primitive in isolation as well as for all relevant combinations. This will allow readers to assess the relative contribution of transparent retry and to evaluate whether the combined effect is additive or synergistic. revision: yes
Circularity Check
No circularity: empirical systems paper with no derivation chain
full rationale
The paper is a purely empirical systems contribution describing an HTTP proxy implementing five scheduling primitives, evaluated via seven scenarios and one motivating incident. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text. Claims rest on direct experimental measurements of failure rates and wasted compute rather than any reduction to prior results or definitions by construction. The work is self-contained with independent empirical content.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Safe Bilevel Delegation (SBD): A Formal Framework for Runtime Delegation Safety in Multi-Agent Systems
SBD is a bilevel optimization framework that learns context-dependent safety weights for runtime task delegation in hierarchical multi-agent systems, with continuous authority transfer alpha and theoretical guarantees...
Reference graph
Works this paper leans on
-
[1]
Claude code: An agentic cod- ing tool
Anthropic, “Claude code: An agentic cod- ing tool.”https://docs.anthropic.com/ en/docs/claude-code, 2025. Accessed: 2026-04-15
2025
-
[2]
Codex CLI: Open-source cod- ing agent
OpenAI, “Codex CLI: Open-source cod- ing agent.”https://github.com/openai/ codex, 2025. Accessed: 2026-04-15
2025
-
[3]
Cursor: The AI code edi- tor
Anysphere Inc., “Cursor: The AI code edi- tor.”https://cursor.com, 2024. Accessed: 2026-04-15
2024
-
[4]
GitHub copilot
GitHub, “GitHub copilot.”https: //github.com/features/copilot, 2024. Accessed: 2026-04-15. 11
2024
-
[5]
Silberschatz, P
A. Silberschatz, P. B. Galvin, and G. Gagne,Operating System Concepts. Wiley, 10th ed., 2018
2018
-
[6]
System deadlocks,
E. G. Coffman, M. J. Elphick, and A. Shoshani, “System deadlocks,”ACM Computing Surveys, vol. 3, no. 2, pp. 67– 78, 1971
1971
-
[7]
LangChain
H. Chase, “LangChain.”https://github. com/langchain-ai/langchain, 2022. Ac- cessed: 2026-04-15
2022
-
[8]
Moura, “CrewAI.”https://github
J. Moura, “CrewAI.”https://github. com/joaomdmoura/crewAI, 2024. Accessed: 2026-04-15
2024
-
[9]
AutoGen: Enabling next- gen LLM applications via multi-agent con- versation,
Q. Wu, G. Bansal, J. Zhang, Y. Wu, B. Li, E.Zhu, L.Jiang, X.Zhang, S.Zhang, J.Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang, “AutoGen: Enabling next- gen LLM applications via multi-agent con- versation,” 2023
2023
-
[10]
Semantic kernel
Microsoft, “Semantic kernel.”https: //github.com/microsoft/semantic- kernel, 2023. Accessed: 2026-04-15
2023
-
[11]
Devin: The first AI soft- ware engineer
Cognition Labs, “Devin: The first AI soft- ware engineer.”https://devin.ai, 2024. Accessed: 2026-04-15
2024
-
[12]
SWE-bench: Can language models resolve real-world GitHub issues?,
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “SWE-bench: Can language models resolve real-world GitHub issues?,” 2024
2024
-
[13]
SWE-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Liber, S. Yao, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,” 2024
2024
-
[14]
A. S. Tanenbaum and H. Bos,Modern Op- erating Systems. Pearson, 4th ed., 2015
2015
-
[15]
Cooperating sequential processes,
E. W. Dijkstra, “Cooperating sequential processes,”Technical Report EWD-123, Technological University Eindhoven, 1965
1965
-
[16]
Congestion avoidance and control,
V. Jacobson, “Congestion avoidance and control,” inProceedings of ACM SIG- COMM, pp. 314–329, 1988
1988
-
[17]
Analysis of the increase and decrease algorithms for con- gestion avoidance in computer networks,
D.-M. Chiu and R. Jain, “Analysis of the increase and decrease algorithms for con- gestion avoidance in computer networks,” Computer Networks and ISDN Systems, vol. 17, no. 1, pp. 1–14, 1989
1989
-
[18]
M. T. Nygard,Release It! Design and De- ploy Production-Ready Software. Pragmatic Bookshelf, 2nd ed., 2018
2018
-
[19]
The tail at scale,
J. Dean and L. A. Barroso, “The tail at scale,” inCommunications of the ACM, vol. 56, pp. 74–80, 2013
2013
-
[20]
Ollama: Run large language mod- elslocally
Ollama, “Ollama: Run large language mod- elslocally.”https://ollama.com, 2024. Ac- cessed: 2026-04-15
2024
-
[21]
TCP congestion control,
M. Allman, V. Paxson, and E. Blan- ton, “TCP congestion control,”RFC 5681, IETF, 2009
2009
-
[22]
SEDA: An architecture for well- conditioned, scalable internet services,
M. Welsh, D. Culler, and E. Brewer, “SEDA: An architecture for well- conditioned, scalable internet services,” in Proceedings of the 18th ACM Symposium on Operating Systems Principles (SOSP), pp. 230–243, 2001
2001
-
[23]
Herlihy and N
M. Herlihy and N. Shavit,The Art of Mul- tiprocessor Programming. Morgan Kauf- mann, revised 1st ed., 2012. 12
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.