How Non-Linguistic Is the Indus Sign System? A Synthetic-Baseline Scorecard
Pith reviewed 2026-05-10 04:18 UTC · model grok-4.3
The pith
The Indus sign system occupies an intermediate statistical position unmatched by either heraldic or administrative non-linguistic baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
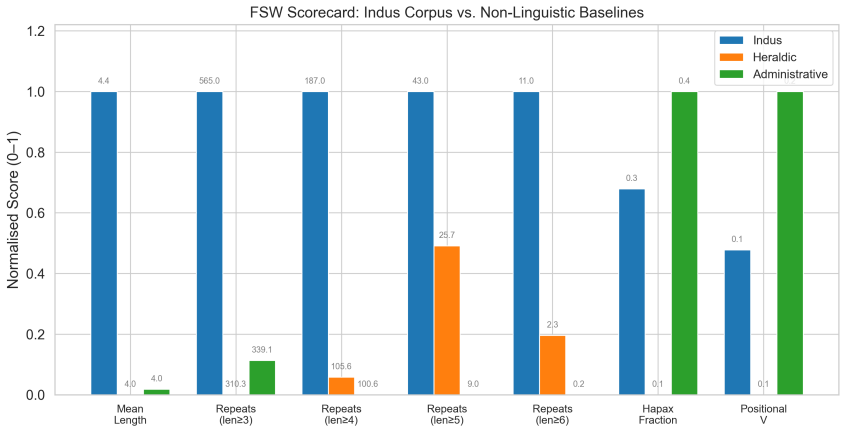
The Indus corpus does not match either synthetic baseline cleanly and occupies an intermediate position relative to the heraldic and administrative families across the four metrics; neither generator family can reproduce all four properties simultaneously, and no attested real-world non-linguistic system matches the complete statistical profile either.
What carries the argument
A multi-metric discrimination framework that generates synthetic non-linguistic baselines calibrated with Zipfian frequencies, positional constraints, and bigram dependencies from attested corpora, then scores both the Indus inscriptions and the baselines on brevity, formulaic repetition, hapax rate, and positional rigidity.
If this is right
- Non-linguistic models must be more complex than pure emblem or coding systems to account for all four Indus properties at once.
- Single-metric arguments about brevity or repetition alone are insufficient to settle the linguistic status of the Indus signs.
- The replicated Zipf slope and entropy values remain stable under the new multi-metric test.
- Any future non-linguistic explanation must be checked against the full set of four metrics rather than selected subsets.
Where Pith is reading between the lines
- The intermediate profile raises the possibility that the Indus system combines features from multiple generative mechanisms not captured by the current baselines.
- Applying the same scorecard to other short, formulaic ancient scripts could test whether they fall into similar intermediate zones.
- If additional metrics such as sign co-occurrence entropy or directionality constraints were added, the distance between Indus data and non-linguistic baselines might increase or shrink in measurable ways.
Load-bearing premise
That the two synthetic generator families together with the seven real non-linguistic corpora cover the space of possible non-linguistic sign systems and that the four chosen metrics are jointly sufficient to detect linguistic structure.
What would settle it
Discovery of any real or newly engineered non-linguistic sign system that simultaneously reproduces the Indus values for text brevity, formulaic repetition, hapax rate, and positional rigidity would falsify the intermediate-position claim.
Figures
read the original abstract
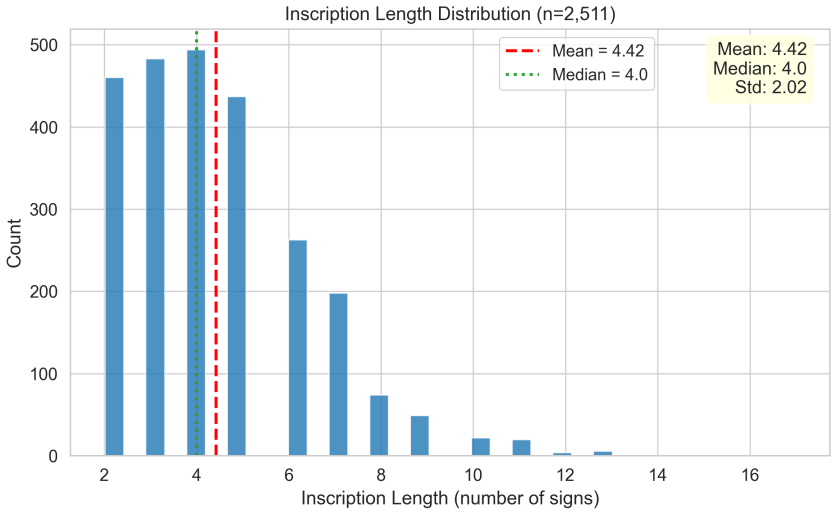
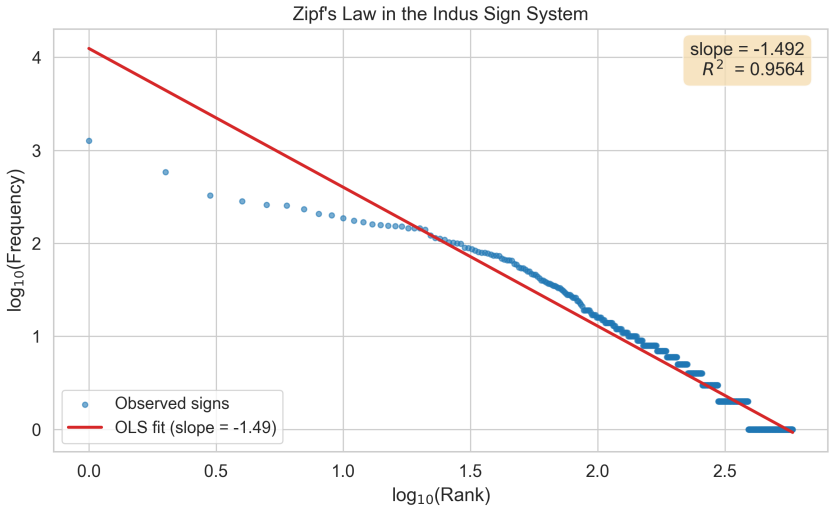
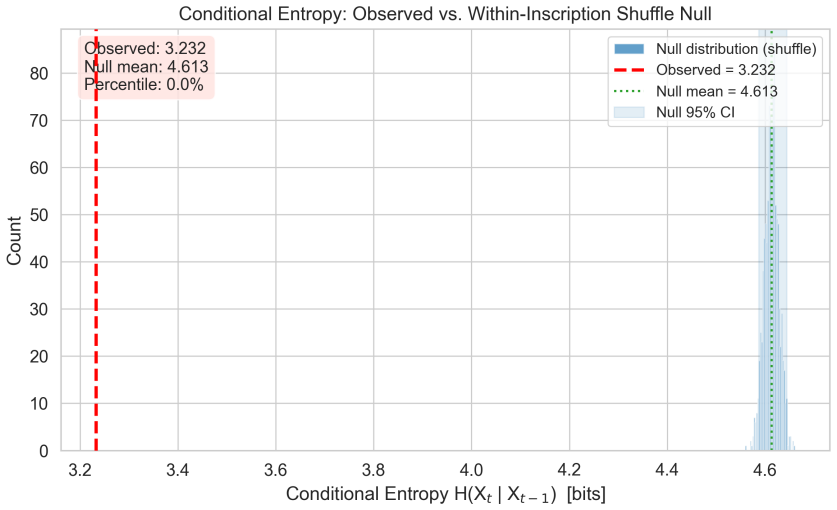
Whether the Indus Valley sign system (c. 2600-1900 BCE) encodes spoken language has been debated for decades. This paper introduces a multi-metric discrimination framework that tests the observed Indus corpus against two kinds of computer-generated non-linguistic baseline -- one mimicking a heraldic emblem system, the other an administrative coding system -- each calibrated with Zipfian frequency distributions, positional constraints, and bigram dependencies derived from six attested non-linguistic corpora. The scorecard evaluates four properties central to the Farmer-Sproat-Witzel (2004) critique: text brevity, repeated formulaic phrases, hapax legomenon rate, and positional rigidity. Applying this framework to 1,916 deduplicated inscriptions (584 unique signs, 11,110 tokens) from the ICIT/Yajnadevam digitization, we find that the Indus corpus does not match either baseline cleanly. Across the four metrics examined, the Indus corpus occupies an intermediate position relative to the two baseline families, matching neither cleanly. Neither a heraldic nor an administrative generator can reproduce all four properties at once. We also compare against seven real-world non-linguistic corpora including Sproat's (2014) datasets, finding that no attested non-linguistic system reproduces the full Indus statistical profile either. We replicate key prior results including a Zipf slope of -1.49 and conditional entropy of 3.23 bits. All code and data are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multi-metric discrimination framework that compares the statistical profile of the Indus Valley sign system (1,916 deduplicated inscriptions, 584 signs, 11,110 tokens) against two families of synthetic non-linguistic baselines (heraldic emblem and administrative coding systems) calibrated on Zipfian frequencies, positional constraints, and bigram dependencies from six attested corpora, plus seven real non-linguistic corpora. It evaluates four properties (brevity, formulaic repetition, hapax rate, positional rigidity) and reports that the Indus corpus occupies an intermediate position, matching neither baseline family nor any attested non-linguistic system on all metrics simultaneously. The work also replicates prior quantitative results (Zipf slope of -1.49 and conditional entropy of 3.23 bits) and releases all code and data publicly.
Significance. If the results hold, this provides a replicable quantitative scorecard for assessing undeciphered scripts against calibrated non-linguistic proxies, adding empirical data to the linguistic-status debate. Strengths include the public code and data release, explicit replication of prior metrics, and anchoring of baselines in external attested corpora rather than ad-hoc invention.
major comments (2)
- [Synthetic baseline generation and calibration] The central claim that the Indus profile matches neither baseline family nor any attested non-linguistic corpus depends on the assumption that the two synthetic generator families (calibrated only on frequency, positional, and bigram statistics from six external corpora) adequately span the space of possible non-linguistic systems. The manuscript does not test or bound whether alternative structures (e.g., hierarchical codes or higher-order dependencies) could simultaneously match the observed values on all four metrics; this is load-bearing for interpreting the mismatch result.
- [Comparison against real-world non-linguistic corpora] The statement that 'no attested non-linguistic system reproduces the full Indus statistical profile' is based on seven specific corpora (including Sproat 2014 datasets). The selection criteria for these corpora and any sensitivity analysis to corpus choice are not detailed, leaving the generality of the 'no match' conclusion open to the risk that other unexamined systems could align.
minor comments (2)
- [Corpus description] The abstract and methods should explicitly cross-reference the exact sections or supplementary material that document the deduplication procedure, sign inventory construction, and any exclusion rules applied to the 1,916 inscriptions.
- [Metric definitions] Notation for the four metrics (brevity, formulaic repetition, hapax rate, positional rigidity) would benefit from a single consolidated table or equation block early in the paper to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments highlight important considerations regarding the scope of our synthetic baselines and the selection of real-world corpora. We address each major comment below and indicate where revisions will be made to improve clarity and transparency.
read point-by-point responses
-
Referee: [Synthetic baseline generation and calibration] The central claim that the Indus profile matches neither baseline family nor any attested non-linguistic corpus depends on the assumption that the two synthetic generator families (calibrated only on frequency, positional, and bigram statistics from six external corpora) adequately span the space of possible non-linguistic systems. The manuscript does not test or bound whether alternative structures (e.g., hierarchical codes or higher-order dependencies) could simultaneously match the observed values on all four metrics; this is load-bearing for interpreting the mismatch result.
Authors: We agree that the two generator families do not exhaustively span all possible non-linguistic structures. Our heraldic and administrative baselines were chosen specifically because they instantiate two distinct archetypes commonly discussed in the literature on the Indus script, with parameters derived from six attested corpora to ground them empirically rather than invent them ad hoc. The central empirical result remains that neither family reproduces the full set of four Indus metrics simultaneously, and the same holds for the seven real corpora examined. We will add a new paragraph in the Discussion section acknowledging that more complex mechanisms (hierarchical codes, higher-order dependencies) are untested and could in principle produce closer matches; we will also note that fully bounding the space of all conceivable non-linguistic systems lies beyond the scope of any single study. This revision clarifies interpretive limits without changing the reported comparisons or conclusions. revision: partial
-
Referee: [Comparison against real-world non-linguistic corpora] The statement that 'no attested non-linguistic system reproduces the full Indus statistical profile' is based on seven specific corpora (including Sproat 2014 datasets). The selection criteria for these corpora and any sensitivity analysis to corpus choice are not detailed, leaving the generality of the 'no match' conclusion open to the risk that other unexamined systems could align.
Authors: The seven corpora were selected as the principal publicly available non-linguistic datasets that have been used in prior quantitative work on the Indus debate, including the Sproat 2014 collection and related sources. In the revised manuscript we will add an explicit subsection in Methods describing the selection criteria (public availability, relevance to the linguistic-status literature, and structural variety) and will include a sensitivity table showing that the 'no full-profile match' result is robust across different subsets of the seven corpora. These additions will be incorporated in the next version. revision: yes
- We cannot exhaustively test or bound every conceivable non-linguistic structure, as the design space is open-ended.
Circularity Check
No circularity: empirical comparisons anchored externally
full rationale
The paper constructs two synthetic generator families by fitting Zipfian frequencies, positional constraints, and bigram dependencies to statistics drawn from six external attested non-linguistic corpora, then evaluates the Indus corpus (1,916 inscriptions) against these generators and seven real-world non-linguistic corpora on four metrics. No derivation step reduces by construction to the paper's own inputs; the central claim that the Indus profile matches neither baseline family nor any attested corpus rests on independent external benchmarks rather than self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The framework is self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four properties (text brevity, repeated formulaic phrases, hapax legomenon rate, positional rigidity) are the central properties for testing the Farmer-Sproat-Witzel critique of linguistic status.
Forward citations
Cited by 1 Pith paper
-
Odyssey: Constructing Verifiable Local Truth-Preserving Foundation Models
ODYSSEY is a sheaf-theoretic framework for building verifiable foundation models as compositions of foundries via left and right Kan extensions.
Reference graph
Works this paper leans on
-
[1]
Cuneiform Digital Library Initiative (CDLI).https://cdli.ucla.edu/
-
[2]
Farmer, S., Sproat, R., & Witzel, M. (2004). The collapse of the Indus-script thesis: The myth of a literate Harappan civilization.Electronic Journal of V edic Studies, 11(2), 19–57
work page 2004
-
[3]
Kumar, A., Subramanian, S., et al. (2021). Neural sequence models for the Indus script.arXiv preprint
work page 2021
-
[4]
(1977).The Indus Script: Texts, Concordance and Tables
Mahadevan, I. (1977).The Indus Script: Texts, Concordance and Tables. Memoirs of the Archaeo- logical Survey of India, No. 77
work page 1977
-
[5]
(1994).Deciphering the Indus Script
Parpola, A. (1994).Deciphering the Indus Script. Cambridge University Press
work page 1994
-
[6]
Rao, R. P. N., Yadav, N., Vahia, M. N., Joglekar, H., Adhikari, R., & Mahadevan, I. (2009). Entropic evidence for linguistic structure in the Indus script.Science, 324(5931), 1165
work page 2009
-
[7]
Sproat, R. (2010). Ancient symbols, computational linguistics, and the reviewing practices of the general science journals.Computational Linguistics, 36(3), 585–594. 12
work page 2010
-
[8]
Sproat, R. (2014). A statistical comparison of written language and nonlinguistic symbol systems. Language Resources and Evaluation, 48(4), 681–693
work page 2014
-
[9]
Vidale, M. (2007). The collapse melts down: A reply to Farmer, Sproat, and Witzel.East and West, 57(1–4), 333–366
work page 2007
-
[10]
Wells, B. K. (2015).An Epigraphic Approach to Indus Writing. Oxbow Books
work page 2015
-
[11]
Yadav, N., Joglekar, H., Rao, R. P. N., Vahia, M. N., Adhikari, R., & Mahadevan, I. (2010). Statis- tical analysis of the Indus script using n-grams.PLoS ONE, 5(3), e9506
work page 2010
-
[12]
N., Mahadevan, I., & Joglekar, H
Yadav, N., Vahia, M. N., Mahadevan, I., & Joglekar, H. (2008). Segmentation of Indus texts.Inter- national Journal of Dravidian Linguistics, 37(1), 39–52. 13
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.