When Corrective Hints Hurt: Prompt Design in Reasoner-Guided Repair of LLM Overcaution on Entailed Negations under OWL~2~DL
Pith reviewed 2026-05-08 07:55 UTC · model grok-4.3
The pith
Providing an open-world hint with reasoner verdicts reduces LLM repair accuracy on OWL 2 DL entailed negations compared to verdicts alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
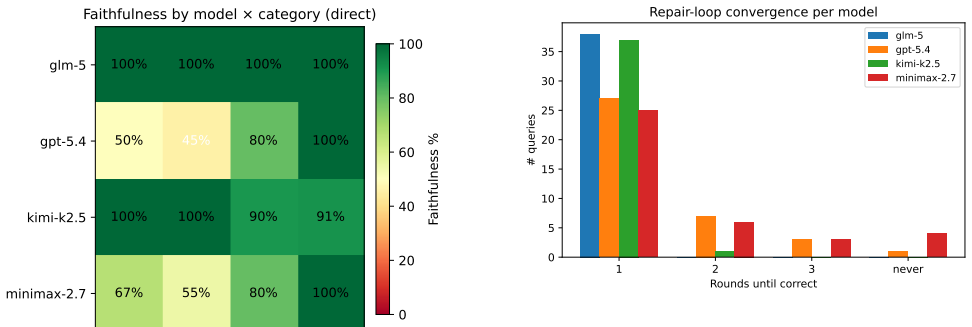
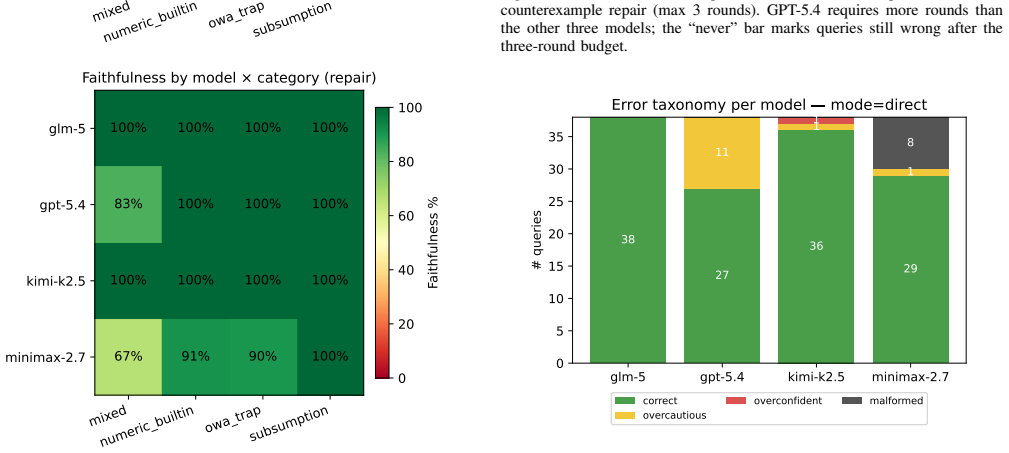
GPT-5.4 exhibits overcaution by returning unknown when the reasoner entails no under FunctionalProperty or disjointness closures. On 180 procedurally generated and audited queries, the verdict-only interaction mode reaches 97.8% direct faithfulness while the verdict-with-hint mode reaches only 67.2%, underperforming even generic retries at 81.7%. The same pattern accounts for all errors on 18 held-out queries in insurance and clinical domains, leading to the conclusion that prompt framing matters more than corrective content in reasoner-guided repair.
What carries the argument
The reasoner-verdict repair prompts, distinguished by the presence or absence of an open-world-assumption hint, used to correct LLM responses on OWL 2 DL compliance queries.
If this is right
- Single-shot prompting yields low direct faithfulness on these negation queries.
- Generic you-are-wrong retries substantially improve performance over single-shot.
- Combining the reasoner verdict with an OWA hint results in lower accuracy than the verdict alone.
- The performance advantage of verdict-only persists across held-out queries in different domains.
- Reasoner-guided wrappers require explicit ablation of prompt variants to determine optimal configurations.
Where Pith is reading between the lines
- Minimalist prompt designs that avoid additional assumptions may be preferable when correcting LLMs on closed-world style logical queries.
- Similar overcaution patterns could appear in other description logic or ontology tasks if not tested with variant prompts.
- Developers of LLM-based ontology tools should test multiple repair strategies rather than assuming more information always helps.
- The findings suggest testing whether the hint introduces conflicting assumptions that reinforce the model's caution.
Load-bearing premise
The 180 procedurally generated queries along with the 18 held-out ones represent the full reproducible error pattern of the model on OWL 2 DL compliance tasks.
What would settle it
Running the same four-mode comparison on a new collection of reasoner-audited queries from a different domain and finding that the verdict-with-hint mode achieves accuracy comparable to or higher than verdict-only would falsify the observation that the hint hurts performance.
Figures
read the original abstract
We report a reproducible error pattern in GPT-5.4 on OWL~2~DL compliance queries: the model frequently answers ``unknown'' when the reasoner-entailed answer is ``no'' under \emph{FunctionalProperty} closure or class \emph{disjointness}. Using 180 reasoner-audited queries from a procedural expansion of the observed pattern plus 18 hand-authored held-out queries in two unrelated domains (insurance and clinical), we compare four interaction modes under matched query budget: single-shot, three rounds of generic ``you-are-wrong'' retry, three rounds of reasoner-verdict repair with an open-world-assumption (OWA) hint, and the same repair without the hint. Direct faithfulness is 43.9\,\% (Wilson 95\,\% CI $[36.8,51.2]$); generic retry reaches 81.7\,\% ($[75.4,86.6]$); the verdict-with-hint variant is \emph{worse} at 67.2\,\% ($[60.1,73.7]$); the verdict-only variant reaches 97.8\,\% ($[94.4,99.1]$). All pairwise comparisons remain significant under McNemar's exact test with Bonferroni correction ($\alpha = 0.01$; all $p < 10^{-5}$). The same fingerprint accounts for 4/4 errors on the held-out queries. Our interpretation is bounded: prompt framing can matter more than corrective content, and reasoner-guided wrappers should be ablated explicitly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a reproducible error pattern in GPT-5.4 on OWL 2 DL compliance queries, where the model outputs 'unknown' instead of the reasoner-entailed 'no' under FunctionalProperty closure or class disjointness. Using 180 reasoner-audited queries generated by procedural expansion of this observed pattern plus 18 hand-authored held-out queries in insurance and clinical domains, the authors compare four interaction modes under matched query budget: single-shot (43.9% accuracy), generic 'you-are-wrong' retry (81.7%), reasoner-verdict repair with open-world-assumption hint (67.2%), and verdict-only repair (97.8%). All pairwise differences are significant by McNemar's exact test with Bonferroni correction (α=0.01, all p<10^{-5}). The same error fingerprint explains all 4 errors on the held-out set. The authors conclude that prompt framing can matter more than corrective content and that reasoner-guided wrappers require explicit ablation.
Significance. If the central empirical comparison holds under less biased sampling, the work provides a concrete, statistically supported demonstration that certain corrective hints can degrade LLM performance on knowledge-representation tasks even when paired with accurate reasoner verdicts. The use of Wilson confidence intervals, McNemar tests with multiple-comparison correction, and a small held-out set in unrelated domains adds rigor to the accuracy claims. The finding that verdict-only repair substantially outperforms both generic retry and hinted repair offers a falsifiable, actionable observation for hybrid LLM-reasoner systems and underscores the value of systematic ablation in prompt engineering for OWL 2 DL compliance.
major comments (2)
- [Query construction (procedural expansion)] Query construction section (procedural expansion of the observed pattern): The 180 queries are generated by procedural expansion seeded from cases where GPT-5.4 outputs 'unknown' rather than the reasoner-entailed 'no'. This deliberately enriches the test distribution for the target failure mode, as described in the abstract. The headline result that the verdict-with-hint variant is worse (67.2%) than verdict-only (97.8%) may therefore reflect an artifact of the query phrasing or negation structure rather than a general property of prompt framing versus corrective content. A broader, independently sampled set of OWL 2 DL queries would be required to support the general claim.
- [Experimental setup] Experimental setup (prompt variants): The manuscript does not provide the exact prompt texts used for the four modes (single-shot, generic retry, verdict-with-hint, verdict-only). Because the central interpretation is that framing matters more than content, and because the with-hint variant underperforms, readers cannot assess whether the performance drop is due to the OWA hint itself or to subtle differences in wording, length, or structure. Releasing the full prompts is necessary for reproducibility and for confirming that the comparison isolates the intended variable.
minor comments (2)
- [Held-out evaluation] The held-out set contains only 18 queries with 4 errors; while the 4/4 match is consistent, the small size limits the strength of the generalization statement. Expanding or better characterizing this set would be useful.
- The paper would benefit from public release of the full query set, reasoner audits, and prompt templates to enable independent verification of the procedural expansion method.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on query construction and experimental reproducibility. We address each major point below with clarifications on our design choices and commitments to revisions.
read point-by-point responses
-
Referee: [Query construction (procedural expansion)] Query construction section (procedural expansion of the observed pattern): The 180 queries are generated by procedural expansion seeded from cases where GPT-5.4 outputs 'unknown' rather than the reasoner-entailed 'no'. This deliberately enriches the test distribution for the target failure mode, as described in the abstract. The headline result that the verdict-with-hint variant is worse (67.2%) than verdict-only (97.8%) may therefore reflect an artifact of the query phrasing or negation structure rather than a general property of prompt framing versus corrective content. A broader, independently sampled set of OWL 2 DL queries would be required to support the general claim.
Authors: The procedural expansion was chosen to generate a sufficiently large, reasoner-audited set that isolates the specific reproducible error pattern (overcautious 'unknown' on entailed 'no' under FunctionalProperty or disjointness) with enough statistical power for McNemar's tests. The manuscript already bounds its claims to this pattern, as evidenced by the held-out set of 18 queries from unrelated insurance and clinical domains where the identical error fingerprint accounts for all failures. This design demonstrates that, for this class of OWL 2 DL compliance queries, the OWA hint degrades performance relative to verdict-only repair. We agree a broader independently sampled corpus would support wider generalization and will add explicit language in the revised discussion and limitations sections stating the scope of the findings and the rationale for targeted sampling. revision: partial
-
Referee: [Experimental setup] Experimental setup (prompt variants): The manuscript does not provide the exact prompt texts used for the four modes (single-shot, generic retry, verdict-with-hint, verdict-only). Because the central interpretation is that framing matters more than content, and because the with-hint variant underperforms, readers cannot assess whether the performance drop is due to the OWA hint itself or to subtle differences in wording, length, or structure. Releasing the full prompts is necessary for reproducibility and for confirming that the comparison isolates the intended variable.
Authors: We agree that the exact prompt texts are required for full reproducibility and to allow independent verification that the performance gap arises from the OWA hint rather than incidental differences in prompt length or phrasing. The revised manuscript will include the complete prompt templates for all four modes in a new appendix. revision: yes
Circularity Check
No circularity: direct empirical measurements on audited queries
full rationale
The paper reports measured accuracies for four prompt interaction modes on 180 procedurally generated plus 18 held-out queries that were reasoner-audited for OWL 2 DL entailments. No equations, fitted parameters, derivations, or predictions appear in the provided text; the reported percentages (e.g., 97.8% for verdict-only) are direct empirical counts, not quantities obtained by substituting inputs into a self-referential formula. Query generation is described as expansion from an observed error pattern, but this construction does not reduce any central claim to its own inputs by definition, nor does it rely on self-citations for load-bearing premises. The work is therefore self-contained as an experimental comparison.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The OWL 2 DL reasoner provides accurate entailment verdicts used both to audit queries and to supply corrective feedback
Forward citations
Cited by 1 Pith paper
-
Energy-Efficient On-Device RAG on a Mobile NPU: System Design and Benchmark on Snapdragon X Elite
First end-to-end RAG on mobile NPU delivers 18.1x faster prefilling, 4x lower latency and energy than CPU on Snapdragon X Elite with equivalent quality.
Reference graph
Works this paper leans on
-
[1]
Evaluating large language models on DL-Lite reason- ing,
B. Wanget al., “Evaluating large language models on DL-Lite reason- ing,” inFindings of EMNLP, 2024
work page 2024
-
[2]
DL-ReasonSuite: a benchmark for description-logic reasoning in lan- guage models,
“DL-ReasonSuite: a benchmark for description-logic reasoning in lan- guage models,”Applied Sciences, vol. 16, no. 4, p. 1821, 2026
work page 2026
-
[3]
OntoURL: a large-scale benchmark for ontology question answering,
“OntoURL: a large-scale benchmark for ontology question answering,” arXiv:2505.11031, 2025
-
[4]
Large language models for OWL proofs,
Yanget al., “Large language models for OWL proofs,” 2026
work page 2026
-
[5]
Explanation-refiner: iterative LLM refinement under formal verifier feedback,
“Explanation-refiner: iterative LLM refinement under formal verifier feedback,” arXiv:2405.01379, 2024
-
[6]
B. Glimmet al., “HermiT: an OWL 2 reasoner,”Journal of Automated Reasoning, vol. 53, no. 3, pp. 245–269, 2014
work page 2014
-
[7]
Pellet: a practical OWL-DL reasoner,
E. Sirinet al., “Pellet: a practical OWL-DL reasoner,”Journal of Web Semantics, vol. 5, no. 2, pp. 51–53, 2007
work page 2007
-
[8]
Benchmarking large language models for image classification of marine mammals,
Y . Qi, S. Cai, Z. Zhao, J. Li, Y . Lin, and Z. Wang, “Benchmarking large language models for image classification of marine mammals,” in2024 IEEE Int. Conf. on Knowledge Graph (ICKG), 2024, pp. 258–265
work page 2024
-
[9]
Structured memory mechanisms for stable context representation in large language models,
Y . Xing, T. Yang, Y . Qi, M. Wei, Y . Cheng, and H. Xin, “Structured memory mechanisms for stable context representation in large language models,” inIEEE Int. Conf. on Artificial Intelligence and Digital Ethics (ICAIDE), 2025
work page 2025
-
[10]
Distilling semantic knowledge via multi-level alignment in TinyBERT-based language models,
T. Yang, Y . Cheng, Y . Qi, and M. Wei, “Distilling semantic knowledge via multi-level alignment in TinyBERT-based language models,”Journal of Computer Technology and Software, vol. 4, no. 5, 2025
work page 2025
-
[11]
Can LLMs simulate economic agents? Testing production theory with GPT-based firm behavior,
Y . Qi, H. Guo, and Y . Qi, “Can LLMs simulate economic agents? Testing production theory with GPT-based firm behavior,”Preprints, 2026
work page 2026
-
[12]
Y . Qi, Y . Qi, and T. Wagh, “Coverage-aware web crawling for domain- specific supplier discovery via a Web–Knowledge–Web pipeline,” arXiv:2602.24262, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Graph neural network- driven hierarchical mining for complex imbalanced data,
Y . Qi, Q. Lu, S. Dou, X. Sun, M. Li, and Y . Li, “Graph neural network- driven hierarchical mining for complex imbalanced data,” inInt. Symp. on Big Data and Applied Statistics (ISBDAS), 2025
work page 2025
-
[14]
Detecting high-potential SMEs with hetero- geneous graph neural networks,
Y . Qi, H. Guo, and Y . Qi, “Detecting high-potential SMEs with hetero- geneous graph neural networks,” arXiv:2602.19591, 2026
work page internal anchor Pith review arXiv 2026
-
[15]
Chain-of-thought prompting elicits reasoning in large lan- guage models,
J. Weiet al., “Chain-of-thought prompting elicits reasoning in large lan- guage models,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 24824–24837
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.