Energy-Efficient On-Device RAG on a Mobile NPU: System Design and Benchmark on Snapdragon X Elite
Pith reviewed 2026-06-27 13:45 UTC · model grok-4.3
The pith
The NPU on Snapdragon X Elite runs a full RAG pipeline with 4x lower energy and latency than CPU while matching answer quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
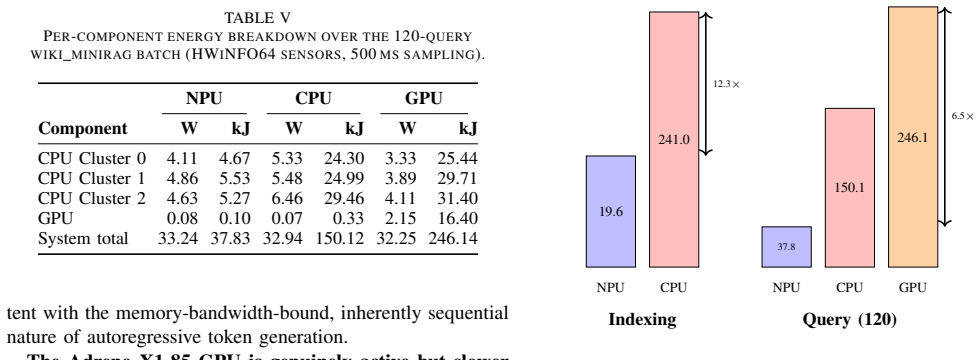
The central claim is that the first complete RAG pipeline running embedding, reranking, and generation entirely on the Hexagon NPU of the Snapdragon X Elite delivers 9.1x higher embedding throughput and 12.3x lower system energy on indexing workloads, plus 18.1x faster LLM prefilling, 4.0x lower end-to-end query latency, and 4.0x lower system energy on a 120-query benchmark, with no measurable quality regression relative to CPU or GPU baselines.
What carries the argument
The end-to-end RAG pipeline executing all three neural stages on the Qualcomm Hexagon NPU, with direct system-level profiling of throughput, latency, and energy against CPU and Adreno GPU baselines.
If this is right
- NPU acceleration makes on-device RAG viable for indexing and repeated query workloads without quality loss.
- The same workload on the integrated GPU is slower and uses substantially more energy than the NPU path.
- The approach is expected to generalize to other mobile NPUs once their software stacks reach comparable maturity.
- Answer quality remains within evaluator noise across all three backends for the tested Wikipedia-passage queries.
Where Pith is reading between the lines
- Wider adoption could shift RAG workloads away from cloud servers toward local devices, lowering both latency and data-transfer costs.
- The reported energy ratios provide a concrete target for hardware and compiler teams working on comparable NPUs.
- Extending the benchmark to longer contexts or domain-specific corpora would test whether the energy advantage persists at scale.
Load-bearing premise
The NPU software stack can execute embedding, reranking, and LLM generation end-to-end without hidden CPU fallback that would change the measured energy and latency figures.
What would settle it
A run of the same benchmark in which NPU execution shows measurable CPU fallback or produces answer scores more than one point lower than the CPU baseline on the 1-10 LLM-as-judge rubric.
Figures

read the original abstract
Retrieval-Augmented Generation (RAG) pipelines are compute-intensive, combining embedding, retrieval, reranking, and large language model (LLM) generation. Running them entirely on-device benefits privacy, latency, and offline use, but the energy cost of CPU inference is a major barrier. We present what is, to our knowledge, the first end-to-end RAG pipeline that runs all neural stages -- embedding, reranking, and LLM generation -- on the Qualcomm Hexagon NPU of the Snapdragon X Elite. Profiling on a Dell XPS 13 laptop, we compare NPU-accelerated RAG against CPU and OpenCL/Adreno GPU baselines on indexing and query workloads. On indexing, the NPU achieves 9.1x higher embedding throughput and 12.3x less system energy. On a 120-query Wikipedia-passage benchmark, it delivers 18.1x faster LLM prefilling, 4.0x lower end-to-end query latency, and 4.0x less system energy than the CPU baseline; the same workload on the integrated GPU is 1.7x slower than CPU and uses 6.5x more energy than the NPU. A GPT-4.1 LLM-as-judge evaluation finds NPU answer quality on par with CPU and GPU within evaluator noise (mean 9.32 vs. 8.95 vs. 9.03 on a 1-10 rubric), with 86.7% of queries scoring identically across all three backends. On the Snapdragon X Elite / Hexagon class of laptop SoC, the NPU thus enables practical, energy-efficient on-device RAG without quality regression -- a sustainable path toward green edge intelligence that we expect to generalize to comparable mobile NPUs (Apple Neural Engine, Intel NPU, MediaTek APU) as their software stacks mature.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents what it claims is the first end-to-end RAG pipeline (embedding, reranking, and LLM generation) running entirely on the Qualcomm Hexagon NPU of the Snapdragon X Elite SoC. It reports concrete benchmarks on a Dell XPS 13 laptop against CPU and OpenCL/Adreno GPU baselines, including 9.1x higher embedding throughput and 12.3x lower energy on indexing, plus 18.1x faster LLM prefilling, 4.0x lower end-to-end latency, and 4.0x lower energy on a 120-query Wikipedia benchmark, with answer quality statistically indistinguishable across backends per GPT-4.1 judging.
Significance. If the NPU-only execution and measurement methodology are verified, the work would be a meaningful empirical contribution to on-device AI systems by showing practical energy and latency benefits for full RAG pipelines on a laptop-class NPU without quality loss. The real-hardware profiling and cross-backend quality evaluation are strengths that could inform hardware-software co-design for edge intelligence.
major comments (2)
- [Abstract and §4] Abstract and §4 (results): The headline claims of 18.1x faster prefilling and 4.0x lower end-to-end energy rest on the assumption that embedding, reranking, and LLM generation execute exclusively on the Hexagon NPU with no CPU fallback. No utilization counters, power-isolation traces, or framework logs are referenced to confirm 100% NPU utilization, which directly undermines the validity of the system-energy deltas versus the CPU baseline.
- [§3 and §4] §3 (implementation) and §4: The manuscript supplies no dataset statistics (e.g., passage lengths, index size), error bars on the reported speedups/energy figures, or exclusion criteria for the 120-query benchmark, making it impossible to assess whether the 4.0x gains are robust or sensitive to workload characteristics.
minor comments (2)
- [Abstract] Abstract: 'GPT-4.1' appears to be a non-standard model name; clarify whether this refers to GPT-4o, GPT-4-turbo, or another variant.
- [Abstract] The generalization statement to Apple Neural Engine, Intel NPU, and MediaTek APU would benefit from a brief discussion of architectural similarities/differences that support the expectation of transfer.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive suggestions. We address the major comments below and will incorporate revisions to strengthen the manuscript's clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (results): The headline claims of 18.1x faster prefilling and 4.0x lower end-to-end energy rest on the assumption that embedding, reranking, and LLM generation execute exclusively on the Hexagon NPU with no CPU fallback. No utilization counters, power-isolation traces, or framework logs are referenced to confirm 100% NPU utilization, which directly undermines the validity of the system-energy deltas versus the CPU baseline.
Authors: The implementation uses the Qualcomm Neural Processing SDK (QNN), which compiles models specifically for the Hexagon NPU and routes all supported operations to it without CPU fallback for the embedding, reranking, and generation stages. While we did not include explicit utilization logs in the original submission, the energy and latency benefits are measured at the system level on the NPU path versus pure CPU execution. To address the concern, we will revise §3 to include details on the dispatch mechanism and reference to profiling tools confirming NPU utilization. This does not change the core claims but improves verifiability. revision: yes
-
Referee: [§3 and §4] §3 (implementation) and §4: The manuscript supplies no dataset statistics (e.g., passage lengths, index size), error bars on the reported speedups/energy figures, or exclusion criteria for the 120-query benchmark, making it impossible to assess whether the 4.0x gains are robust or sensitive to workload characteristics.
Authors: We agree this information is important for assessing robustness. In the revised version, we will expand §3 and §4 to include: average and distribution of passage lengths in the index, total index size in passages and tokens, standard deviations or error bars for all reported metrics based on repeated measurements, and the query selection process (random sample from Wikipedia with no special exclusions). These additions will allow better evaluation of the results' sensitivity to workload. revision: yes
Circularity Check
No circularity: pure empirical benchmark with direct hardware measurements
full rationale
The paper is a systems benchmark reporting measured throughput, energy, latency, and quality metrics for an on-device RAG pipeline running on Snapdragon X Elite Hexagon NPU versus CPU and GPU baselines. No mathematical derivations, equations, fitted parameters presented as predictions, or self-citations bearing the load of central claims appear in the provided text. All results are direct empirical comparisons on the same hardware with external quality evaluation via GPT-4.1, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On-device language models: A comprehensive review,
J. Xuet al., “On-device language models: A comprehensive review,” arXiv preprint arXiv:2409.00088, 2024
arXiv 2024
-
[2]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K¨uttler, M. Lewis, W.-t. Yih, T. Rockt¨aschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 9459–9474
2020
-
[3]
Snapdragon X elite platform,
Qualcomm Technologies, Inc., “Snapdragon X elite platform,” https://www.qualcomm.com/products/mobile/snapdragon/ pcs-and-tablets/snapdragon-x-elite, 2024
2024
-
[4]
Fast on-device LLM inference with NPUs,
D. Xu, H. Zhang, L. Yang, R. Liu, G. Huang, M. Xu, and X. Liu, “Fast on-device LLM inference with NPUs,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’25), Volume 1. ACM, 2025, pp. 445–462
2025
-
[5]
Toward sustainable on-device intelligence: A survey on energy-efficient RAG systems with small language models,
Z. Cheng, L. Lai, Y . Liu, and Y . Sun, “Toward sustainable on-device intelligence: A survey on energy-efficient RAG systems with small language models,”Available at SSRN 6698538, 2026
2026
-
[6]
EmbeddingGemma: Powerful and lightweight text repre- sentations,
J. Leeet al., “EmbeddingGemma: Powerful and lightweight text repre- sentations,”arXiv preprint arXiv:2509.20354, 2025
Pith/arXiv arXiv 2025
-
[7]
jina-reranker-v2-base-multilingual,
N. Sturuaet al., “jina-reranker-v2-base-multilingual,” https: //huggingface.co/jinaai/jina-reranker-v2-base-multilingual, 2024, jina AI
2024
-
[8]
A. Yanget al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[9]
Qualcomm AI runtime (QAIRT) SDK,
Qualcomm Technologies, Inc., “Qualcomm AI runtime (QAIRT) SDK,” https://www.qualcomm.com/developer/software/ qualcomm-ai-runtime-sdk, 2024
2024
-
[10]
Green AI,
R. Schwartz, J. Dodge, N. A. Smith, and O. Etzioni, “Green AI,” Communications of the ACM, vol. 63, no. 12, pp. 54–63, 2020
2020
-
[11]
llama.cpp: Inference of Meta’s LLaMA model in pure C/C++,
G. Gerganovet al., “llama.cpp: Inference of Meta’s LLaMA model in pure C/C++,” https://github.com/ggerganov/llama.cpp, 2024
2024
-
[12]
MLC-LLM: Machine learning compilation for large language models,
MLC AI, “MLC-LLM: Machine learning compilation for large language models,” https://llm.mlc.ai/, 2024
2024
-
[13]
ExecuTorch: End-to-end solution for enabling on-device inference,
Meta Platforms, Inc., “ExecuTorch: End-to-end solution for enabling on-device inference,” https://github.com/pytorch/executorch, 2024
2024
-
[14]
DRP: Distilled reasoning pruning with skill-aware step decomposition for efficient large reasoning models,
Y . Jiang, D. Li, and F. Ferraro, “DRP: Distilled reasoning pruning with skill-aware step decomposition for efficient large reasoning models,”
-
[15]
Available: https://arxiv.org/abs/2505.13975
[Online]. Available: https://arxiv.org/abs/2505.13975
-
[16]
Find your optimal teacher: Personalized data synthesis via router-guided multi-teacher distillation,
H. Zhang, S. Yang, X. Liang, C. Shang, Y . Jiang, C. Tao, J. Xiong, H. K.-H. So, R. Xie, A. X. Chang, and N. Wong, “Find your optimal teacher: Personalized data synthesis via router-guided multi-teacher distillation,” 2026. [Online]. Available: https://arxiv.org/abs/2510.10925
Pith/arXiv arXiv 2026
-
[17]
Learning how to use tools, not just when: Pattern-aware tool-integrated reasoning,
N. Xu, Y . Jiang, S. R. Dipta, and H. Zhang, “Learning how to use tools, not just when: Pattern-aware tool-integrated reasoning,” 2026. [Online]. Available: https://arxiv.org/abs/2509.23292
arXiv 2026
-
[18]
Task-specific efficiency analysis: When small language models outperform large language models,
J. Cao, Y . Ma, X. Li, Q. Ren, and X. Chen, “Task-specific efficiency analysis: When small language models outperform large language models,” 2026. [Online]. Available: https://arxiv.org/abs/2603.21389
arXiv 2026
-
[19]
Small language model agents enable efficient and high-quality knowledge mining,
S. Zhang, S. Lin, X. Wei, Y . Chen, P. Qian, S. Wang, and H. Xu, “Small language model agents enable efficient and high-quality knowledge mining,” 2026. [Online]. Available: https://arxiv.org/abs/2510.01427
Pith/arXiv arXiv 2026
-
[20]
Synergized data efficiency and compression (SEC) optimization for large language models,
X. Li, Y . Ma, Y . Huang, X. Wang, Y . Lin, and C. Zhang, “Synergized data efficiency and compression (SEC) optimization for large language models,” in2024 4th International Conference on Electronic Information Engineering and Computer Science (EIECS). IEEE, 2024, pp. 586–591
2024
-
[21]
X. Li, J. Cao, M. Wang, Y . Wu, L. Yan, Y . Zhou, Z. Sha, and Y . Ma, “FAST: A synergistic framework of attention and state-space models for spatiotemporal traffic prediction,” 2026. [Online]. Available: https://arxiv.org/abs/2604.13453
Pith/arXiv arXiv 2026
-
[22]
CATCH: A modular cross-domain adaptive template with hook,
X. Li, Y . Lu, J. Cao, Y . Ma, Z. Li, and Y . Zhou, “CATCH: A modular cross-domain adaptive template with hook,” inInternational Symposium on Visual Computing. Springer, 2025, pp. 41–52
2025
-
[23]
Performance-efficiency trade-offs in human preference prediction: A comparative study of traditional machine learning and large language models,
Y . Zhang, Z. Xiang, and H. Xu, “Performance-efficiency trade-offs in human preference prediction: A comparative study of traditional machine learning and large language models,” inProceedings of the 31st IEEE Symposium on Computers and Communications (ISCC). IEEE, 2026
2026
-
[24]
LangChain: Building applications with LLMs through composability,
LangChain, Inc., “LangChain: Building applications with LLMs through composability,” https://github.com/langchain-ai/langchain, 2024
2024
-
[25]
LlamaIndex: A data framework for LLM applications,
LlamaIndex, “LlamaIndex: A data framework for LLM applications,” https://github.com/run-llama/llama index, 2024
2024
-
[26]
Retrieval-augmented generation for large language models: A survey,
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, and H. Wang, “Retrieval-augmented generation for large language models: A survey,”arXiv preprint arXiv:2312.10997, 2024
Pith/arXiv arXiv 2024
-
[27]
Does RAG know when retrieval is wrong? diagnosing context compliance under knowledge conflict,
Y . Chen, P. Qian, S. Wang, S. Zhang, H. Xu, S. Lin, and X. Wei, “Does RAG know when retrieval is wrong? diagnosing context compliance under knowledge conflict,” 2026. [Online]. Available: https://arxiv.org/abs/2605.14473
Pith/arXiv arXiv 2026
-
[28]
Seeing through the conflict: Transparent knowledge conflict handling in retrieval-augmented generation,
H. Ye, S. Chen, Z. Zhong, C. Xiao, H. Zhang, Y . Wu, and F. Shen, “Seeing through the conflict: Transparent knowledge conflict handling in retrieval-augmented generation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 40, 2026, pp. 34 423–34 431
2026
-
[29]
Relevant is not warranted: Evidence-force calibration for cited RAG,
P. Qian, S. Wang, X. Wang, Y . Chen, W. Xu, Q. Yu, S. Lin, S. Zhang, J. You, and X. Wei, “Relevant is not warranted: Evidence-force calibration for cited RAG,” 2026. [Online]. Available: https://arxiv.org/abs/2605.28044
Pith/arXiv arXiv 2026
-
[30]
J. Liu, J. Yang, X. Li, W. Yan, Y . Wu, P. Liang, and M. Yuan, “Architecture matters more than scale: A comparative study of retrieval and memory augmentation for financial QA under SME compute constraints,” 2026. [Online]. Available: https://arxiv.org/abs/2604.17979
Pith/arXiv arXiv 2026
-
[31]
Y . Qi, Y . Qi, and T. Wagh, “Coverage-aware web crawling for domain- specific supplier discovery via a web–knowledge–web pipeline,” 2026. [Online]. Available: https://arxiv.org/abs/2602.24262
Pith/arXiv arXiv 2026
-
[32]
Y . Qi, X. Xu, and Y . Li, “When corrective hints hurt: Prompt design in reasoner-guided repair of LLM overcaution on entailed negations under OWL 2 DL,” 2026. [Online]. Available: https://arxiv.org/abs/2604.23398
Pith/arXiv arXiv 2026
-
[33]
Encoder: Entity mining and modification relation binding for composed image retrieval,
Z. Li, Z. Chen, H. Wen, Z. Fu, Y . Hu, and W. Guan, “Encoder: Entity mining and modification relation binding for composed image retrieval,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 5, 2025, pp. 5101–5109
2025
-
[34]
FineCIR: Explicit parsing of fine-grained modification semantics for composed image retrieval,
Z. Li, Z. Fu, Y . Hu, Z. Chen, H. Wen, and L. Nie, “FineCIR: Explicit parsing of fine-grained modification semantics for composed image retrieval,”arXiv preprint arXiv:2503.21309, 2025
arXiv 2025
-
[35]
Reinforcement learning for option hedging: Static implied-volatility fit versus shortfall-aware performance,
Z. Chen, M. Hu, J. Yi, and W. Sun, “Reinforcement learning for option hedging: Static implied-volatility fit versus shortfall-aware performance,” 2026
2026
-
[36]
FinSentLLM: Multi-LLM and structured semantic signals for enhanced financial sentiment forecasting,
Z. Zhang, R. Fu, Y . He, X. Shen, Y . Wang, X. Du, H. You, K. Jin, J. Shi, and S. Fong, “FinSentLLM: Multi-LLM and structured semantic signals for enhanced financial sentiment forecasting,” inICASSP 2026 – 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2026, pp. 17 682–17 686
2026
-
[37]
Enhancing counterfactual ex- planations with feasibility and diversity,
X. Qin, S. Li, Y . Cai, and L. Wang, “Enhancing counterfactual ex- planations with feasibility and diversity,” in2025 IEEE International Conference on Data Mining Workshops (ICDMW). IEEE, 2025, pp. 2310–2319
2025
-
[38]
Exploring the application boundaries of LLMs in mental health: A systematic scoping review,
J. Yang, T. Liu, Y . T. Luo, T. Niu, P. Pang, A. Xiang, and Q. Yang, “Exploring the application boundaries of LLMs in mental health: A systematic scoping review,”Frontiers in Psychology, vol. 16, p. 1715306, 2026
2026
-
[39]
Z. Cheng, L. Lai, Y . Liu, K. Cheng, and X. Qi, “Enhancing financial report question-answering: A retrieval-augmented generation system with reranking analysis,” 2026. [Online]. Available: https: //arxiv.org/abs/2603.16877
Pith/arXiv arXiv 2026
-
[40]
Resolving the robustness-precision trade-off in financial RAG through hybrid document-routed retrieval,
Z. Cheng, L. Lai, and Y . Liu, “Resolving the robustness-precision trade-off in financial RAG through hybrid document-routed retrieval,”
-
[41]
Available: https://arxiv.org/abs/2603.26815
[Online]. Available: https://arxiv.org/abs/2603.26815
-
[42]
AutoNeural: Co-designing vision-language models for NPU inference,
W. Chen, L. Wu, Y . Hu, Z. Li, Z. Cheng, Y . Qian, L. Zhu, Z. Hu, L. Liang, Q. Tang, Z. Liu, and H. Yang, “AutoNeural: Co-designing vision-language models for NPU inference,” 2025. [Online]. Available: https://arxiv.org/abs/2512.02924
arXiv 2025
-
[43]
Energy and policy consid- erations for deep learning in NLP,
E. Strubell, A. Ganesh, and A. McCallum, “Energy and policy consid- erations for deep learning in NLP,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019, pp. 3645–3650
2019
-
[44]
Carbon emissions and large neural network training,
D. Patterson, J. Gonzalez, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, and J. Dean, “Carbon emissions and large neural network training,”arXiv preprint arXiv:2104.10350, 2021
Pith/arXiv arXiv 2021
-
[45]
Billion-scale similarity search with GPUs,
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with GPUs,”IEEE Transactions on Big Data, vol. 7, no. 3, pp. 535– 547, 2021
2021
-
[46]
Reciprocal rank fusion outperforms condorcet and individual rank learning methods,
G. V . Cormack, C. L. A. Clarke, and S. Buettcher, “Reciprocal rank fusion outperforms condorcet and individual rank learning methods,” inProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2009, pp. 758–759
2009
-
[47]
rag-mini-wikipedia: a small wikipedia- passage benchmark for retrieval-augmented generation,
RAG Datasets contributors, “rag-mini-wikipedia: a small wikipedia- passage benchmark for retrieval-augmented generation,” Hugging Face dataset, https://huggingface.co/datasets/rag-datasets/rag-mini-wikipedia, 2024
2024
-
[48]
FinDER: a financial-domain question-answering benchmark over SEC filings,
Linq AI Research, “FinDER: a financial-domain question-answering benchmark over SEC filings,” Hugging Face dataset, https://huggingface. co/datasets/Linq-AI-Research/FinDER, 2024
2024
-
[49]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena,” in Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023
2023
-
[50]
From generation to judgment: Oppor- tunities and challenges of LLM-as-a-Judge,
D. Li, B. Jiang, L. Huang, A. Beigi, C. Zhao, Z. Tan, A. Bhattacharjee, Y . Jiang, C. Chen, T. Wuet al., “From generation to judgment: Oppor- tunities and challenges of LLM-as-a-Judge,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 2757–2791
2025
-
[51]
Reflect-guard: Enhancing LLM safeguards against adversarial prompts via logical self-reflection,
L. Lin, J. You, Y . Li, L. Lin, Y . Wang, Z. Zhang, and M. Zheng, “Reflect-guard: Enhancing LLM safeguards against adversarial prompts via logical self-reflection,” 2026. [Online]. Available: https://arxiv.org/abs/2605.24834
Pith/arXiv arXiv 2026
-
[52]
Y . Wang, Y . Tang, Y . Qian, and C. Zhao, “VisualLeakBench: Auditing the fragility of large vision-language models against PII leakage and social engineering,” 2026. [Online]. Available: https://arxiv.org/abs/2603.13385
arXiv 2026
-
[53]
When safe skills collide: Measuring compositional risk in agent skill ecosystems,
S. Wang, P. Qian, Y . Chen, J. You, X. Wang, X. Jiang, L. Liu, H. Yu, and J. Xu, “When safe skills collide: Measuring compositional risk in agent skill ecosystems,” 2026. [Online]. Available: https://arxiv.org/abs/2606.00448
Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.