Robust and Fast Training via Per-Sample Clipping
Pith reviewed 2026-05-08 17:46 UTC · model grok-4.3
The pith
Per-sample gradient clipping in SGD achieves optimal convergence rates for non-convex problems under heavy-tailed noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replacing the usual averaged gradient with a per-sample clipped version, the resulting PS-Clip-SGD algorithm attains optimal in-expectation convergence rates for non-convex stochastic optimization under heavy-tailed gradient noise and yields high-probability convergence guarantees that match those rates up to polylogarithmic factors in the failure probability.
What carries the argument
Per-sample clipped gradient estimator, which clips each sample's gradient individually before aggregation to control the influence of heavy-tailed outliers.
If this is right
- Optimal in-expectation convergence rates are obtained for non-convex problems under the stated heavy-tailed noise model.
- High-probability convergence bounds hold that differ from the expectation bounds by only polylog factors in the failure probability.
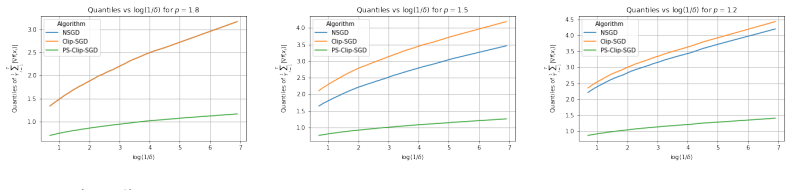
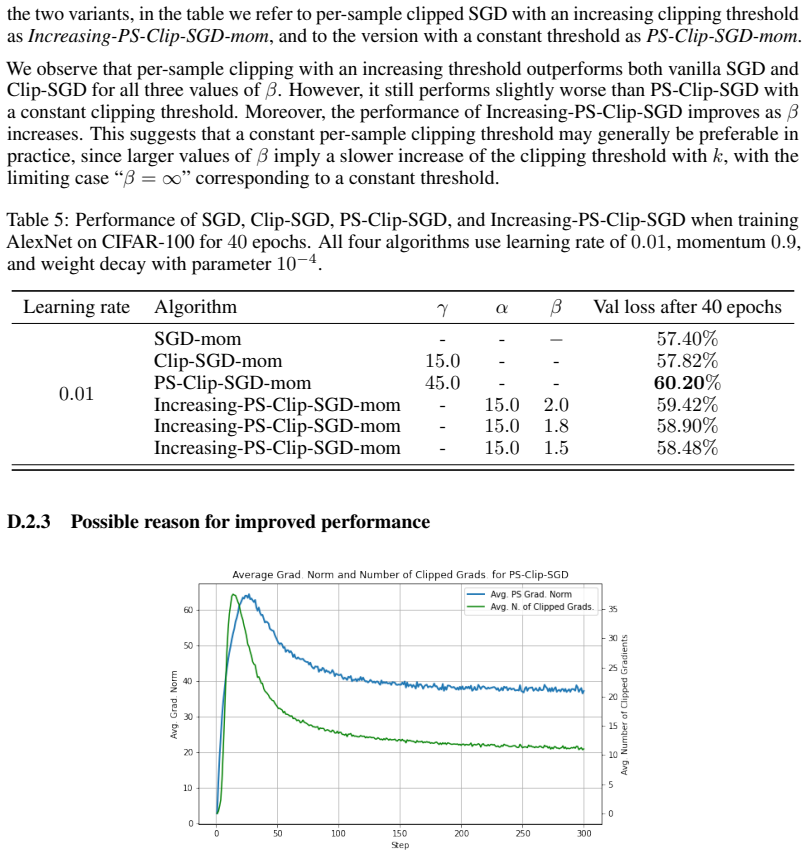
- Empirical training of AlexNet on CIFAR-100 improves over both momentum SGD and batch-level clipping, even after accounting for per-sample overhead.
- Applying clipping during gradient accumulation steps improves performance at almost zero extra cost, contrary to the usual practice of clipping only after accumulation.
Where Pith is reading between the lines
- The method may allow larger batch sizes in practice without sacrificing stability when tails are heavy.
- It suggests that the timing of clipping relative to accumulation steps deserves systematic study across optimizers.
- If the per-sample clipping cost can be amortized, the approach could extend naturally to other first-order methods that suffer from outlier gradients.
Load-bearing premise
The noise in the observed gradients must follow a heavy-tailed distribution possessing finite moments of a prescribed order.
What would settle it
On a synthetic non-convex problem whose gradient noise is independently verified to be light-tailed, PS-Clip-SGD would fail to match the claimed optimal rates and would perform no better than unclipped SGD.
Figures
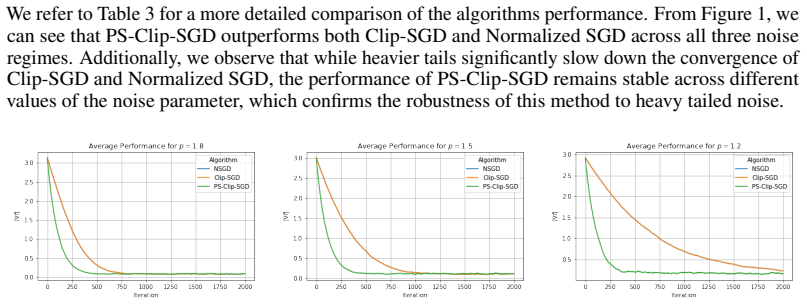
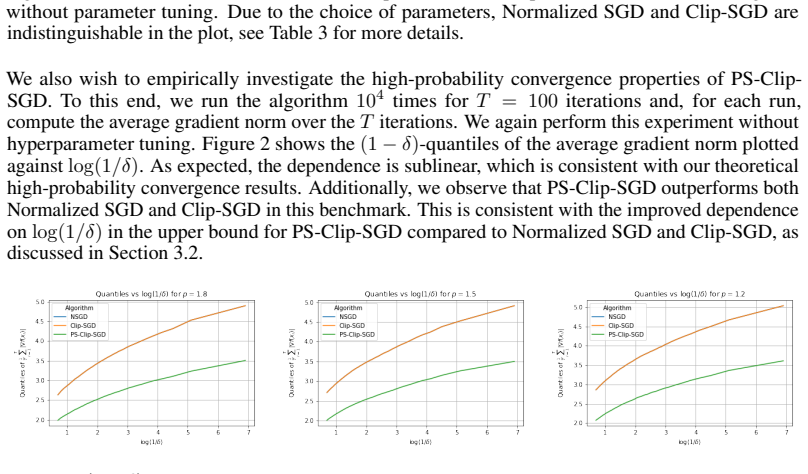
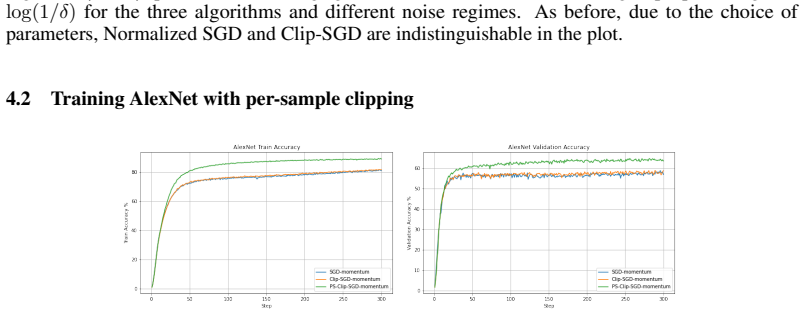
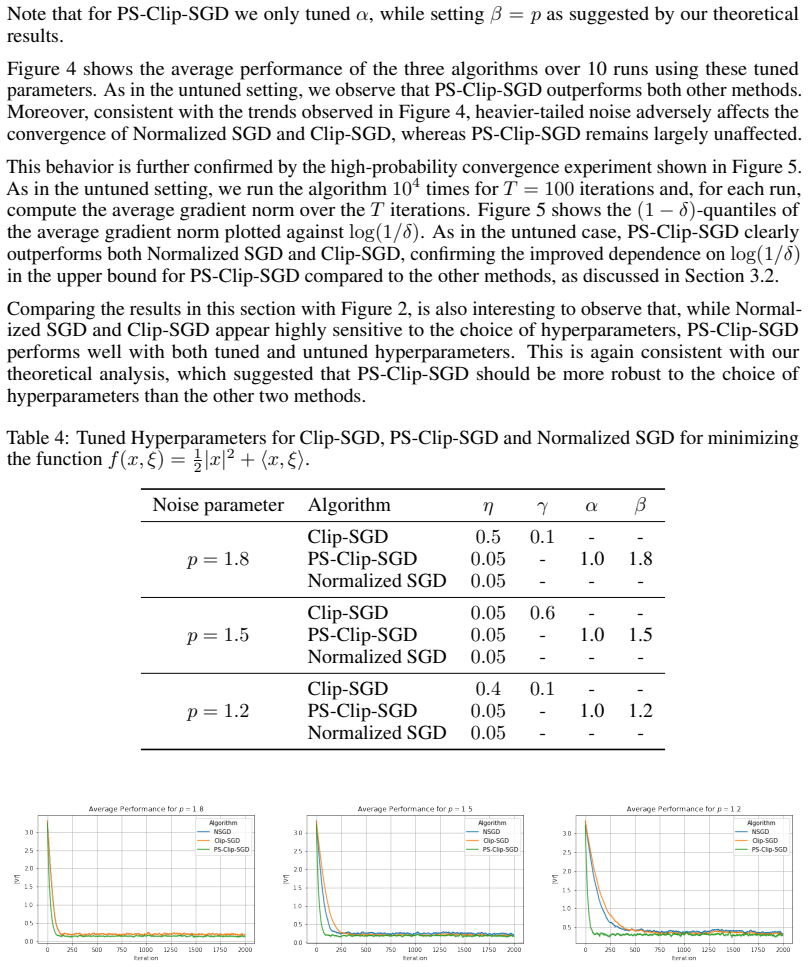
read the original abstract
We propose a robust gradient estimator based on per-sample gradient clipping and analyze its properties both theoretically and empirically. We show that the resulting method, per-sample clipped SGD (PS-Clip-SGD), achieves optimal in-expectation convergence rates for non-convex optimization problems under heavy-tailed gradient noise. Moreover, we establish high-probability convergence guarantees that match the in-expectation rates up to polylogarithmic factors in the failure probability. We complement our theoretical results with multiple numerical experiments. In particular, we demonstrate that PS-Clip-SGD outperforms both vanilla SGD with momentum and standard gradient clipping when training AlexNet on the CIFAR-100 dataset, even after accounting for the additional computational time caused by per-sample clipping. We also empirically show that, in the presence of gradient accumulation, applying clipping at the mini-batch level can improve training performance while incurring virtually no additional computational cost. This finding is particularly interesting, as it contradicts the common practice of applying clipping only after all accumulation steps have been completed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes per-sample clipped SGD (PS-Clip-SGD) as a robust gradient estimator. It claims that this method achieves optimal in-expectation convergence rates for non-convex optimization under heavy-tailed gradient noise, along with high-probability convergence guarantees that match the in-expectation rates up to polylogarithmic factors in the failure probability. These theoretical results are supported by experiments demonstrating that PS-Clip-SGD outperforms vanilla SGD with momentum and standard gradient clipping when training AlexNet on CIFAR-100 (accounting for extra compute), and that mini-batch-level clipping during gradient accumulation can improve performance at negligible cost, contrary to common practice.
Significance. If the stated convergence results hold, the work provides a theoretically grounded clipping strategy with optimal rates under heavy-tailed noise assumptions that are relevant to deep learning. The matching high-probability bounds and the empirical observation on accumulation-stage clipping are practical strengths. The paper supplies conditional optimality claims and reproducible-style experiments as supporting elements.
major comments (1)
- [Theoretical analysis] The central optimality claim in the abstract rests on the gradient noise satisfying explicit heavy-tailed moment bounds. The manuscript should include a dedicated subsection (likely in the theoretical analysis) that states the precise moment conditions (e.g., which p-moments are finite) and shows how they yield the claimed optimal rate; without this explicit linkage the applicability to the reported AlexNet/CIFAR-100 runs remains conditional rather than verified.
minor comments (2)
- [Abstract] The abstract states that multiple numerical experiments were performed, yet only the AlexNet/CIFAR-100 run is described in detail; a one-sentence summary of the other experiments would improve completeness.
- [Experiments] In the experimental section, the comparison to baselines should explicitly state whether hyper-parameters for vanilla SGD and standard clipping were re-tuned on the same compute budget as PS-Clip-SGD; the current description leaves open the possibility that the reported gains partly reflect unequal tuning effort.
Simulated Author's Rebuttal
We thank the referee for the careful review and the minor revision recommendation. We address the single major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Theoretical analysis] The central optimality claim in the abstract rests on the gradient noise satisfying explicit heavy-tailed moment bounds. The manuscript should include a dedicated subsection (likely in the theoretical analysis) that states the precise moment conditions (e.g., which p-moments are finite) and shows how they yield the claimed optimal rate; without this explicit linkage the applicability to the reported AlexNet/CIFAR-100 runs remains conditional rather than verified.
Authors: We agree that a dedicated subsection would improve clarity and make the optimality claims self-contained. In the revised manuscript we will insert a new subsection (tentatively titled 'Moment Assumptions and Derivation of Optimal Rates') immediately after the problem setup in the theoretical analysis section. This subsection will (i) state the precise assumption that the stochastic gradient noise satisfies E[||noise||^p] ≤ σ^p for some p ∈ (1,2] and all samples, (ii) recall the standard heavy-tailed convergence result that yields the optimal in-expectation rate O(T^{-(p-1)/(2p-1)}) (or the specific rate proved in our theorems), and (iii) explicitly connect these conditions to the high-probability bounds. We will also add a short paragraph discussing why the CIFAR-100 experiments are consistent with the assumed regime. These additions require only a few paragraphs and do not alter any proofs or experiments. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes per-sample clipped SGD (PS-Clip-SGD) and claims optimal in-expectation and high-probability convergence rates for non-convex problems under heavy-tailed gradient noise with moment bounds. These rates are derived from standard external optimization theory (e.g., typical SGD analyses adapted to clipping and tail assumptions) rather than reducing to self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations within the paper. The abstract and context indicate the results are conditional on the stated noise model, with experiments as separate empirical validation. No self-definitional steps, ansatzes smuggled via citation, or renaming of known results as new derivations are present. The central claims remain independent of the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gradient noise is heavy-tailed with bounded moments sufficient for the clipping analysis
- standard math The objective is L-smooth and bounded below
Lean theorems connected to this paper
-
IndisputableMonolith.Cost (J(x)=½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
g(x_t,ξ_t)=min(1, γ_t/|∇f(x_t,ξ_t)|)∇f(x_t,ξ_t)... clipping factors γ_k^(t):=min(1, αk^{1/β}/|∇f(x_t,ξ_t^{(k)})|)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Is Variational Monte Carlo Robust? Sharp Moment Thresholds and Heavy-tailed Stochastic Optimization
VMC local energy and gradient estimators are generically heavy-tailed for common ansatze due to nodal sets, but a new clipped variant converges in the low-moment regime.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.