Cornerstones or Stumbling Blocks? Deciphering the Rock Tokens in On-Policy Distillation
Pith reviewed 2026-05-12 02:28 UTC · model grok-4.3
The pith
High-loss Rock Tokens in on-policy distillation resist training yet add almost nothing to reasoning performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
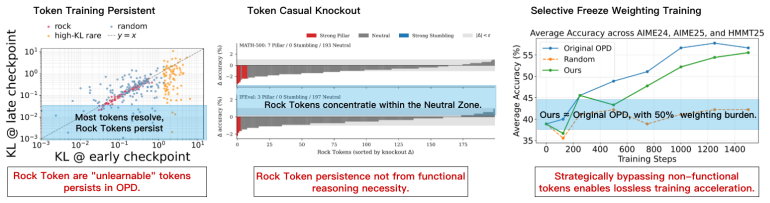
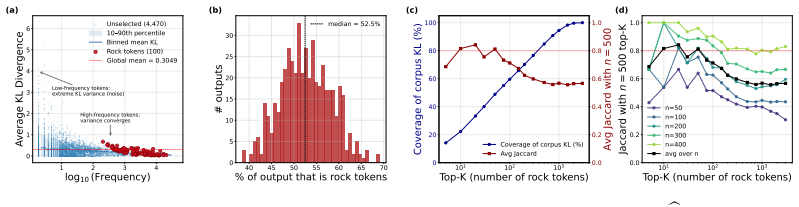
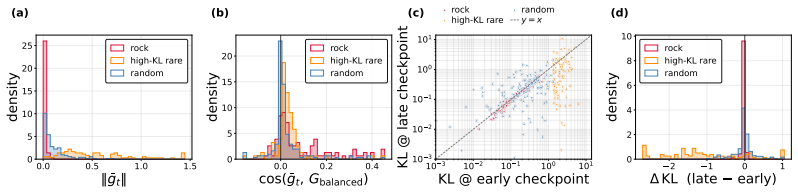
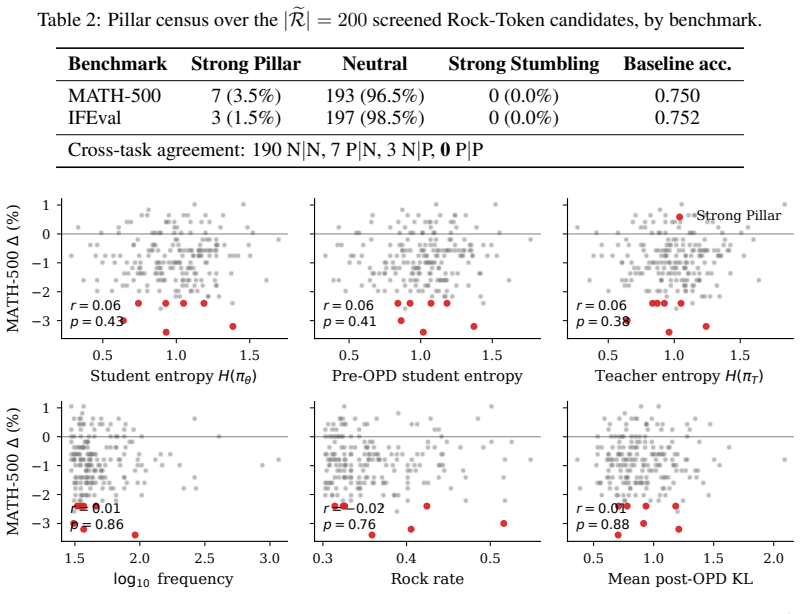
Even after on-policy distillation reaches apparent saturation, a substantial subset of tokens continues to exhibit persistently high loss. These Rock Tokens can account for up to 18% of the tokens in generated outputs. They provide a disproportionately large share of total gradient norms yet remain stagnant throughout training and resist teacher-driven corrections. Through causal intervention, these tokens are shown to provide negligible functional contribution to the model's actual reasoning performance, indicating that optimization bandwidth is spent on structural and discourse residuals that the student cannot or need not internalize.
What carries the argument
Rock Tokens: the persistently high-loss tokens under the per-token KL objective that resist correction while showing negligible downstream effect on reasoning.
Load-bearing premise
The tests that change or remove these high-loss tokens accurately capture whether they affect the model's final reasoning outputs.
What would settle it
Performing the causal intervention on Rock Tokens and observing clear changes in the model's reasoning accuracy or outputs would show the contribution is not negligible.
Figures


read the original abstract
While recent work in Reinforcement Learning with Verifiable Rewards (RLVR) has shown that a small subset of critical tokens disproportionately drives reasoning gains, an analogous token-level understanding of On-Policy Distillation (OPD) remains largely unexplored. In this work, we investigate high-loss tokens, a token type that--as the most direct signal of student-teacher mismatch under OPD's per-token KL objective--should progressively diminish as training converges according to existing studies; however, our empirical analysis shows otherwise. Even after OPD training reaches apparent saturation, a substantial subset of tokens continues to exhibit persistently high loss; these tokens, which we term Rock Tokens, can account for up to 18\% of the tokens in generated outputs. Our investigation reveals two startling paradoxes. First, despite their high occurrence frequency providing a disproportionately large share of total gradient norms, Rock Tokens themselves remain stagnant throughout training, resisting teacher-driven corrections. Second, through causal intervention, we find that these tokens provide negligible functional contribution to the model's actual reasoning performance. These findings suggest that a vast amount of optimization bandwidth is spent on structural and discourse residuals that the student model cannot or need not internalize. By deconstructing these dynamics, we demonstrate that strategically bypassing these ``stumbling blocks'' can significantly streamline the alignment process, challenging the necessity of uniform token weighting and offering a more efficient paradigm for large-scale model distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates persistently high-loss tokens in on-policy distillation (OPD) for language models, termed 'Rock Tokens.' These tokens persist after apparent training saturation, comprise up to 18% of generated outputs, and account for a disproportionate share of gradient norms while resisting teacher corrections. Through causal interventions, the authors claim these tokens contribute negligibly to reasoning performance, suggesting that strategically bypassing them can streamline distillation by challenging uniform token weighting.
Significance. If the causal interventions are shown to isolate token contributions without confounding effects, the work would provide a valuable empirical lens on token-level dynamics in OPD, highlighting optimization inefficiencies and motivating targeted weighting schemes for more efficient large-scale distillation. The manuscript is credited for its observational analysis of training saturation and the application of causal interventions to probe functional contributions.
major comments (1)
- Abstract: the central claim that causal interventions demonstrate negligible functional contribution of Rock Tokens to reasoning performance is load-bearing for the proposal to bypass them. However, in autoregressive generation, masking or altering specific tokens necessarily alters the conditioning context for all subsequent tokens. A null effect on final outputs could therefore reflect compensatory adjustments by later tokens rather than true lack of causal weight from the Rock Tokens. Without explicit controls for sequence position, length, or matched comparisons to non-Rock high-loss tokens, the intervention does not cleanly isolate the claimed negligible contribution.
minor comments (2)
- Abstract and methods: details on dataset sizes, exact intervention methods (e.g., masking vs. replacement), statistical controls, and the operational definition of 'saturation' are missing, hindering verification of the empirical observations and gradient dominance claims.
- The paper should include a dedicated section contrasting the OPD findings with prior token-level analyses in RLVR to clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies a substantive methodological consideration in our causal analysis. We address the concern directly below and describe the revisions we will make.
read point-by-point responses
-
Referee: Abstract: the central claim that causal interventions demonstrate negligible functional contribution of Rock Tokens to reasoning performance is load-bearing for the proposal to bypass them. However, in autoregressive generation, masking or altering specific tokens necessarily alters the conditioning context for all subsequent tokens. A null effect on final outputs could therefore reflect compensatory adjustments by later tokens rather than true lack of causal weight from the Rock Tokens. Without explicit controls for sequence position, length, or matched comparisons to non-Rock high-loss tokens, the intervention does not cleanly isolate the claimed negligible contribution.
Authors: We agree that autoregressive dependencies represent a potential confounder and that stronger isolation of token-level effects requires additional controls. Our original interventions replaced Rock Tokens with the teacher's token at the same position while continuing generation, yielding no measurable change in final reasoning accuracy. To address the referee's point, the revised manuscript will add: (i) position-stratified results (early/mid/late sequence interventions), (ii) length-matched sequence cohorts, and (iii) parallel interventions on non-Rock high-loss tokens at matched positions and loss magnitudes. These controls will be reported alongside the original findings to demonstrate that compensatory effects do not explain the null result for Rock Tokens specifically. revision: partial
Circularity Check
No significant circularity: purely observational and interventional analysis
full rationale
The paper reports empirical measurements of token losses during on-policy distillation, identifies persistently high-loss 'Rock Tokens' via direct observation, and assesses their functional contribution through causal interventions on generated sequences. No equations, closed-form derivations, or parameter-fitting steps are present that would reduce any reported quantity (e.g., gradient norms, loss values, or performance deltas) to a fitted input defined by the same data. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The central claims rest on external experimental benchmarks rather than self-referential reductions, satisfying the criteria for a self-contained observational study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-loss tokens are the most direct signal of student-teacher mismatch under the per-token KL objective
invented entities (1)
-
Rock Tokens
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Even after OPD training reaches apparent saturation, a substantial subset of tokens continues to exhibit persistently high loss; these tokens, which we term Rock Tokens... through causal intervention, we find that these tokens provide negligible functional contribution to the model's actual reasoning performance.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the initial Rock Score as R(v) = ℓ̄v · Freq(v)... context-consistent rock rate CCR(v) = |R(v)| / Freq(v).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
When Safe Skills Collide: Measuring Compositional Risk in Agent Skill Ecosystems
About 18.2% of structurally flagged skill pairs represent genuine compositional safety risks in agent skill registries, with exploitation gated by host model behavior.
-
Bridging Reasoning Trajectories in On-Policy Distillation via Near-Future Guidance
TOPD augments on-policy distillation by using near-future trajectory signals to suppress non-divergent high-loss tokens and distribute guidance, raising average accuracy from 47.8% to 52.2% on reasoning benchmarks.
-
A Formula-Driven Survey and Research Agenda for On-Policy Distillation
A survey creates a taxonomy for on-policy distillation in LLMs that separates temporal credit assignment from vocabulary-level probability routing.
-
RankVR: Low-Rank Structure Perception and Value Recalibration for Robust Composed Image Retrieval
RankVR introduces GSCP and ASVC modules to improve CIR robustness by decoupling clean samples via low-rank structure and dynamically scoring triplet value in noisy datasets.
-
IMAGINE: Adaptive Schema-Imagery Enhanced Composition for Composed Video Retrieval
IMAGINE uses adaptive schema-imagery via dynamic multimodal prototypes to incorporate implicit semantics into composed video retrieval, claiming SOTA results on CVR and CIR benchmarks.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.