Towards a Virtual Neuroscientist: Autonomous Neuroimaging Analysis via Multi-Agent Collaboration
Pith reviewed 2026-05-19 17:07 UTC · model grok-4.3
The pith
Multi-agent system NIAgent autonomously builds and refines neuroimaging analysis workflows to outperform fixed pipelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NIAgent is a multi-agent system for autonomous end-to-end neuroimaging analysis that adopts a code-centric execution paradigm where specialist agents collaboratively synthesize and optimize executable programs over composable domain-specific primitives, paired with a hierarchical verification framework integrating cohort-level metric screening with agentic visual inspection to drive evidence-grounded workflow remediation.
What carries the argument
Code-centric execution paradigm in which specialist agents collaboratively synthesize and optimize executable programs over composable domain-specific primitives, enabling robust long-horizon workflow construction that adapts to runtime observations.
Load-bearing premise
The hierarchical verification framework integrating cohort-level metric screening with agentic visual inspection is sufficient to drive evidence-grounded workflow remediation without human intervention or additional safeguards.
What would settle it
Running NIAgent on a fresh neuroimaging dataset and finding that its generated workflows produce lower accuracy in predicting clinical outcomes than human-tuned baselines, or that they contain uncorrected errors that require manual fixes.
Figures










read the original abstract
Transforming neuroimaging data into clinically actionable biomarkers is a knowledge-intensive and labor-intensive process. Standardized workflows such as fMRIPrep have improved robustness and efficiency, but they are statically configured and cannot reason about downstream objectives, deliberate over alternative strategies, or close the loop between intermediate evidence and subsequent decisions in the way a human researcher would. This lack of closed-loop adaptation often leaves domain experts trapped in a cycle of manual trial-and-error to tune parameters and remediate pipeline failures, severely constraining the scalability of clinical biomarker development. To bridge this gap, we introduce NEXUS, an autonomous multi-agent framework that integrates neuroimaging workflow execution with scientific-objective understanding. Unlike conventional flat toolcalling agents, NEXUS adopts a code-centric execution paradigm where specialist agents collaboratively synthesize and optimize executable programs over composable domain-specific primitives. This design enables robust, long-horizon workflow construction that adapts dynamically to runtime observations. Furthermore, we propose a hierarchical verification framework for autonomous quality control, integrating cohort-level metric screening with agentic visual inspection to drive evidence-grounded workflow remediation. Experiments on ADHD-200 and ADNI demonstrate that NEXUS outperforms standard workflow-based baselines in predictive performance while exhibiting sophisticated agentic behaviors, including strategy exploration and adaptive refinement. The code is available at https://github.com/LearningKeqi/Virtual-Neuroscientist-NEXUS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NIAgent, a multi-agent system for autonomous end-to-end neuroimaging analysis. It uses a code-centric execution paradigm in which specialist agents collaboratively synthesize and optimize executable workflows over domain-specific primitives, enabling dynamic adaptation. A hierarchical verification framework integrates cohort-level metric screening with agentic visual inspection to support evidence-grounded remediation of pipeline failures. Experiments on the ADHD-200 and ADNI datasets are reported to show that NIAgent outperforms standard workflow-based baselines in predictive performance while exhibiting agentic behaviors such as strategy exploration and adaptive refinement.
Significance. If the performance gains can be rigorously attributed to the autonomous components through detailed ablations and validation of the verification framework, the work could meaningfully advance AI-driven automation of scientific workflows in neuroimaging by reducing reliance on manual trial-and-error for pipeline tuning and remediation.
major comments (2)
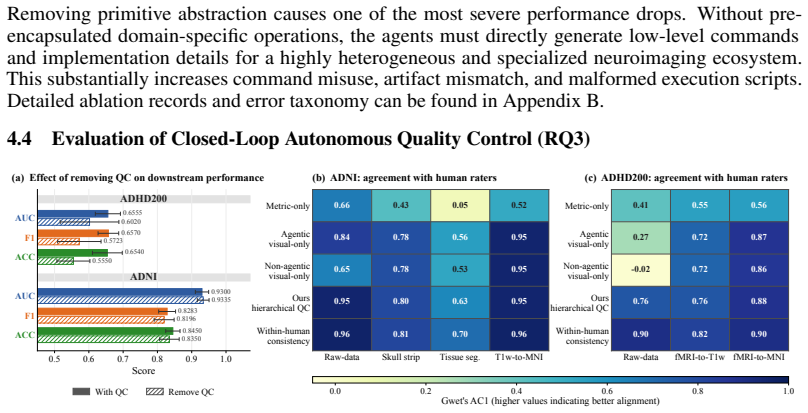
- [Results] Results section: The central claim that NIAgent outperforms workflow-based baselines on ADHD-200 and ADNI rests on reported predictive performance improvements, yet the manuscript provides no specific quantitative metrics, error bars, baseline configurations, or ablation studies isolating the contribution of multi-agent collaboration or the hierarchical verification framework. This absence directly weakens attribution of gains to the autonomy mechanisms.
- [Methods] Hierarchical verification framework (described in the methods): The assertion that cohort-level metric screening combined with agentic visual inspection suffices for autonomous remediation without human intervention is load-bearing for the closed-loop adaptation claim, but the paper supplies no quantitative inspection error rates, edge-case artifact evaluations, or ablations demonstrating performance degradation when the visual-inspection stage is removed.
minor comments (2)
- [Experiments] Clarify the exact composition of the standard workflow-based baselines, including any parameter settings or preprocessing steps, to allow direct reproducibility of the comparisons.
- Ensure that descriptions of agentic behaviors (strategy exploration, adaptive refinement) are accompanied by concrete examples or logs from the runs rather than high-level assertions.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have revised the manuscript to provide the requested details and analyses.
read point-by-point responses
-
Referee: [Results] Results section: The central claim that NIAgent outperforms workflow-based baselines on ADHD-200 and ADNI rests on reported predictive performance improvements, yet the manuscript provides no specific quantitative metrics, error bars, baseline configurations, or ablation studies isolating the contribution of multi-agent collaboration or the hierarchical verification framework. This absence directly weakens attribution of gains to the autonomy mechanisms.
Authors: We appreciate this observation. The manuscript reports outperformance on the two datasets but does not include the specific numerical metrics, error bars, or baseline configurations in the main text. We agree that this limits attribution and have added a new table with exact performance values (including means and standard deviations), explicit baseline configurations, and ablation studies that isolate the contributions of multi-agent collaboration and the hierarchical verification framework in the revised Results section. revision: yes
-
Referee: [Methods] Hierarchical verification framework (described in the methods): The assertion that cohort-level metric screening combined with agentic visual inspection suffices for autonomous remediation without human intervention is load-bearing for the closed-loop adaptation claim, but the paper supplies no quantitative inspection error rates, edge-case artifact evaluations, or ablations demonstrating performance degradation when the visual-inspection stage is removed.
Authors: We agree that quantitative support for the verification framework is necessary to substantiate the closed-loop claim. The current manuscript describes the framework at a high level without error rates or ablations. We have added quantitative inspection error rates measured on held-out cases, evaluations on edge-case artifacts, and an ablation removing the visual-inspection stage (showing measurable performance drop) to the revised Methods and Results sections. revision: yes
Circularity Check
No circularity: empirical validation on external benchmarks
full rationale
The paper introduces NIAgent as a multi-agent system for autonomous neuroimaging workflows and supports its claims solely through experimental comparisons on the external ADHD-200 and ADNI datasets against standard baselines. No mathematical derivations, equations, fitted parameters, or self-referential definitions appear in the provided text. The hierarchical verification framework is presented as a design choice whose sufficiency is asserted via overall predictive performance rather than any reduction to inputs by construction. This is a standard empirical systems paper whose central results rest on observable outcomes independent of the method's internal definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Neuroimaging analysis workflows can be decomposed into composable domain-specific primitives that agents can synthesize into executable programs
- ad hoc to paper Agentic visual inspection combined with cohort-level metrics can provide sufficient evidence for autonomous remediation of pipeline failures
invented entities (1)
-
NIAgent multi-agent system
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
NIAgent adopts a code-centric execution paradigm where specialist agents collaboratively synthesize and optimize executable programs over composable domain-specific primitives... hierarchical verification framework integrating cohort-level metric screening with agentic visual inspection
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on ADHD-200 and ADNI demonstrate that NIAgent outperforms standard workflow-based baselines
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
EHRBench: An Automated and Reliable EHR-based Benchmark for Clinical Decision Making with LLMs
EHRBench uses an EHR-LLM-KB pipeline to automatically create 960,067 reliable QA items spanning diagnosis, treatment, and prognosis for large-scale LLM evaluation in clinical decision making.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.