EHRBench: An Automated and Reliable EHR-based Benchmark for Clinical Decision Making with LLMs
Pith reviewed 2026-06-29 06:38 UTC · model grok-4.3
The pith
EHRBench builds nearly 1 million EHR-grounded QA items via an automated LLM-KB pipeline to evaluate LLMs on diagnosis, treatment, and prognosis tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
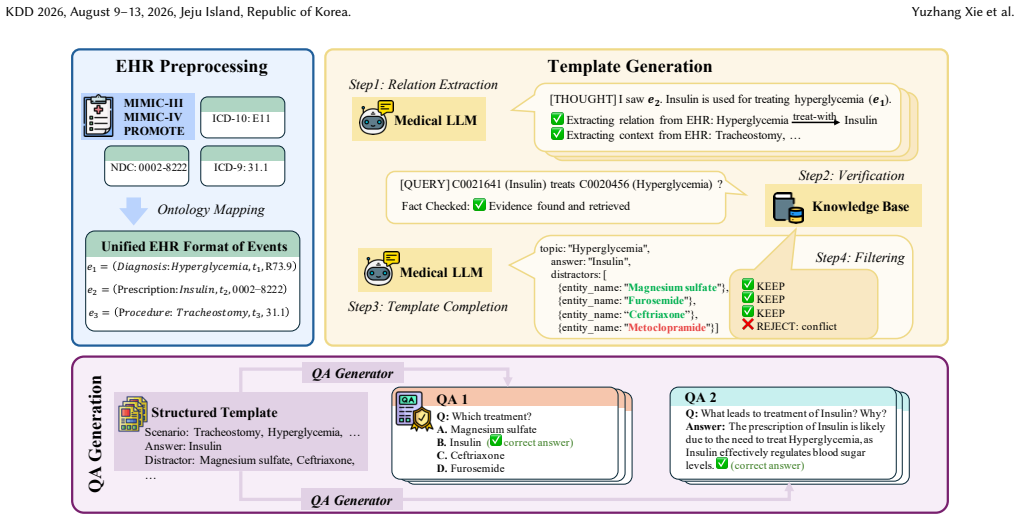
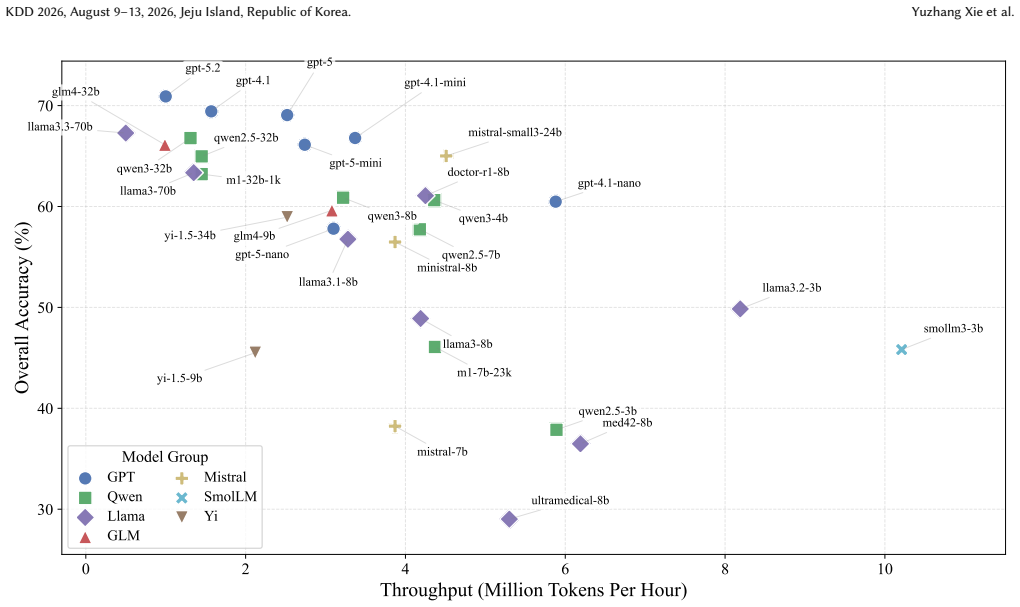
EHRBench is constructed through an EHR-LLM-KB interaction pipeline. A specialized LLM converts encounter-level EHR trajectories into structured templates and deterministically instantiates them into QA items. Systematic KB-based verification and enrichment filters hallucinated or ambiguous relations. This yields 960067 QA items spanning diagnosis, treatment, and prognosis. Benchmarking more than 30 LLMs produces consistent capability trends across settings.
What carries the argument
The EHR-LLM-KB interaction pipeline that automates template generation from real EHR trajectories and applies knowledge-base verification to ensure reliability at scale.
If this is right
- LLMs can be tested at scale on practical clinical decision tasks that require substantive biomedical inference from real patient records.
- The three tasks together cover diagnosis, treatment selection, and prognosis prediction under incomplete evidence.
- Consistent performance trends across more than thirty models validate that the benchmark produces stable rankings.
- The automated pipeline removes the need for manual curation while maintaining claimed clinical reliability.
Where Pith is reading between the lines
- The same pipeline structure could be reused with updated knowledge bases to refresh the benchmark as medical guidelines evolve.
- Models that perform well on EHRBench might still require separate testing on live clinical workflows where patient context changes over time.
- The large item count makes it feasible to create task-specific subsets for targeted model improvement or error analysis.
Load-bearing premise
The knowledge-base verification step reliably catches and removes hallucinated or ambiguous clinical relations produced by the LLM template generator without needing manual review.
What would settle it
Independent expert review of a random sample of several hundred QA items revealing a substantial fraction that contain clinically incorrect, unverifiable, or ambiguous content.
Figures

read the original abstract
Clinical decision-making (CDM) is central to real-world clinical workflows, where clinicians infer diagnoses, select treatments, or anticipate future health outcomes under incomplete evidence. LLMs are increasingly used to support these decisions due to strong language capabilities, broad biomedical knowledge, and efficiency, yet the reliability of LLMs on real-world clinical decision tasks remains insufficiently understood. To evaluate CDM models, especially LLM-based models, an ideal and practical medical decision benchmark should be constructed via an automated yet reliable pipeline to ensure both scale and quality. Moreover, the grounding of a CDM benchmark in real patient EHRs can better support evaluation on practical CDM tasks that require substantive biomedical knowledge and clinical inference. To fill the gaps, we introduce EHRBench, an automated and reliable EHR-grounded benchmark for evaluating LLM-based clinical decision-making at scale. To ensure scalability and reliability, EHRBench is constructed through an EHR-LLM-KB(knowledge-base) interaction pipeline. For efficiency, we use a specialized LLM to automatically convert encounter-level EHR trajectories into structured templates and deterministically instantiate the templates into QA items. In parallel, we apply systematic KB-based verification and enrichment to filter hallucinated or ambiguous relations and to improve reliability. Using this pipeline, we construct nearly 1M (960,067) QA items spanning three core inference-required clinical decision tasks: diagnosis, treatment, and prognosis. We benchmark more than 30 representative LLMs on EHRBench and provide detailed analyses of performance and robustness. The results show consistent capability trends across settings, further validating the reliability of EHRBench and highlighting actionable gaps toward clinically reliable LLM systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EHRBench, a benchmark of 960,067 QA items spanning diagnosis, treatment, and prognosis tasks, constructed via an automated EHR-LLM-KB pipeline that converts EHR trajectories into templates, instantiates them deterministically, and applies KB verification/enrichment to filter hallucinations. It then benchmarks >30 LLMs on the resulting dataset and reports performance trends.
Significance. If the reliability of the KB filtering step holds, EHRBench would offer a valuable large-scale, EHR-grounded resource for evaluating LLMs on clinically relevant inference tasks, filling a gap in scalable CDM benchmarks. The scale and multi-task coverage are strengths, but the absence of validation data for the core reliability mechanism substantially reduces the immediate utility of the contribution.
major comments (1)
- [Abstract and Section 3 (pipeline)] Abstract and pipeline description (Section 3): The central claim that 'systematic KB-based verification and enrichment' successfully filters hallucinated or ambiguous relations to produce clinically reliable QA items without manual review is unsupported by any quantitative evidence. No error-rate measurements, precision/recall of the KB step, clinician-rated samples of pre- and post-filter items, or comparison to a human gold standard are reported. This directly undermines the 'reliable' qualifier in the title and abstract, as undetected errors from the LLM template generator can propagate into the final ~1M items.
minor comments (2)
- [Section 3] The manuscript should clarify the exact criteria and implementation details of the KB verification rules (e.g., which relations are checked and how enrichment is performed) to allow reproducibility.
- [Results section] Figure or table presenting the benchmark statistics (e.g., breakdown by task and source) would benefit from explicit error bars or confidence intervals if any sampling was involved in construction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the scale and scope of EHRBench. We address the central concern regarding validation of the KB filtering step below.
read point-by-point responses
-
Referee: Abstract and pipeline description (Section 3): The central claim that 'systematic KB-based verification and enrichment' successfully filters hallucinated or ambiguous relations to produce clinically reliable QA items without manual review is unsupported by any quantitative evidence. No error-rate measurements, precision/recall of the KB step, clinician-rated samples of pre- and post-filter items, or comparison to a human gold standard are reported. This directly undermines the 'reliable' qualifier in the title and abstract, as undetected errors from the LLM template generator can propagate into the final ~1M items.
Authors: We agree that the manuscript does not report direct quantitative validation (e.g., precision/recall, clinician ratings, or pre/post-filter error rates) for the KB verification step, and that this weakens the strength of the reliability claim. The current argument rests on the pipeline design (deterministic instantiation plus KB grounding), but lacks empirical measurement of its filtering efficacy. In the revised manuscript we will add a dedicated evaluation subsection in Section 3 that reports: (i) the fraction of items filtered by the KB step, (ii) clinician review of a 500-item random sample of pre- and post-filter QA pairs with inter-rater agreement and error-rate reduction statistics, and (iii) a comparison against a small human-annotated gold set. These additions will either substantiate or appropriately qualify the 'reliable' descriptor. revision: yes
Circularity Check
No circularity: benchmark pipeline uses external EHR data and independent KB without self-referential reduction.
full rationale
The paper constructs EHRBench via an EHR-LLM-KB pipeline that converts external patient trajectories into templates and applies KB verification for filtering. No equations, fitted parameters, or predictions are defined in terms of the output QA items themselves. The reliability claim rests on the pipeline's design rather than any self-citation chain or ansatz that reduces the result to its inputs by construction. The construction draws from independent sources (EHR records and KB), making the derivation self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The EHR-LLM-KB interaction pipeline produces reliable QA items without significant hallucination or ambiguity after verification.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, et al . 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Lisa Adams, Felix Busch, Tianyu Han, Jean-Baptiste Excoffier, Matthieu Ortala, Alexander Löser, Hugo JWL Aerts, Jakob Nikolas Kather, Daniel Truhn, and Keno Bressem. 2025. Longhealth: A question answering benchmark with long clinical documents.Journal of Healthcare Informatics Research(2025), 1–17
2025
-
[3]
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, et al. 2025. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Rahul K Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero-Candela, Foivos Tsimpourlas, et al . 2025. Healthbench: Evaluat- ing large language models towards improved human health.arXiv preprint arXiv:2505.08775(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Yaara Artsi, Vera Sorin, Eli Konen, Benjamin S Glicksberg, Girish Nadkarni, and Eyal Klang. 2024. Large language models for generating medical examinations: systematic review.BMC medical education24, 1 (2024), 354
2024
-
[6]
Seongsu Bae, Daeun Kyung, Jaehee Ryu, Eunbyeol Cho, Gyubok Lee, Sunjun Kweon, et al. 2023. Ehrxqa: A multi-modal question answering dataset for elec- tronic health records with chest x-ray images.Advances in Neural Information Processing Systems36 (2023), 3867–3880
2023
-
[7]
Elie Bakouch, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, Lewis Tunstall, Carlos Miguel Patino, et al. 2025. SmolLM3: smol, multilingual, long-context reasoner.Hugging Face Blog(2025)
2025
- [8]
-
[9]
Balu Bhasuran, Qiao Jin, Yuzhang Xie, Carl Yang, Karim Hanna, Jennifer Costa, Cindy Shavor, Wenshan Han, Zhiyong Lu, and Zhe He. 2025. Preliminary anal- ysis of the impact of lab results on large language model generated differential diagnoses.npj Digital Medicine8, 1 (2025), 166
2025
-
[10]
Olivier Bodenreider. 2004. The unified medical language system (UMLS): in- tegrating biomedical terminology.Nucleic acids research32, suppl_1 (2004), D267–D270
2004
-
[11]
Joeran S Bosma, Koen Dercksen, Luc Builtjes, Romain André, Christian Roest, Stefan J Fransen, Constant R Noordman, Mar Navarro-Padilla, Judith Lefkes, Natália Alves, et al. 2025. The DRAGON benchmark for clinical NLP.npj Digital Medicine8, 1 (2025), 289
2025
-
[12]
Kathi Canese and Sarah Weis. 2013. PubMed: the bibliographic database.The NCBI handbook2, 1 (2013), 2013
2013
-
[13]
Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, and Benyou Wang. 2024. Huatuogpt-o1, towards medical complex reasoning with llms.arXiv preprint arXiv:2412.18925(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
- [15]
-
[16]
Hejie Cui, Alyssa Unell, Bowen Chen, Jason Alan Fries, Emily Alsentzer, Sanmi Koyejo, and Nigam H Shah. 2025. Timer: Temporal instruction modeling and evaluation for longitudinal clinical records.npj Digital Medicine8, 1 (2025), 577
2025
-
[17]
Amin Dada, Osman Koraş, Marie Bauer, Amanda Butler, Kaleb Smith, Jens Kleesiek, and Julian Friedrich. 2025. Medisumqa: Patient-oriented question- answer generation from discharge letters. InProceedings of the Second Workshop on Patient-Oriented Language Processing (CL4Health). 124–136
2025
- [18]
- [19]
-
[20]
Felix J Dorfner, Amin Dada, Felix Busch, Marcus R Makowski, Tianyu Han, Daniel Truhn, et al. 2025. Evaluating the effectiveness of biomedical fine-tuning for large language models on clinical tasks.Journal of the American Medical Informatics Association32, 6 (2025), 1015–1024
2025
-
[21]
Yongqi Fan, Hongli Sun, Kui Xue, Xiaofan Zhang, Shaoting Zhang, and Tong Ruan. 2025. Medodyssey: A medical domain benchmark for long context evalu- ation up to 200k tokens. InFindings of the Association for Computational Lin- guistics: NAACL 2025. 32–56
2025
-
[22]
Zhihao Fan, Lai Wei, Jialong Tang, Wei Chen, Wang Siyuan, Zhongyu Wei, and Fei Huang. 2025. Ai hospital: Benchmarking large language models in a multi-agent medical interaction simulator. InProceedings of the 31st International Conference on Computational Linguistics. 10183–10213
2025
-
[23]
Scott L Fleming, Alejandro Lozano, William J Haberkorn, Jenelle A Jindal, Ed- uardo Reis, Rahul Thapa, Louis Blankemeier, Julian Z Genkins, Ethan Steinberg, Ashwin Nayak, et al . 2024. Medalign: A clinician-generated dataset for in- struction following with electronic medical records. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 3...
2024
-
[24]
Team Glm, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, et al
-
[25]
Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [26]
-
[27]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Ab- hishek Kadian, Ahmad Al-Dahle, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [28]
-
[29]
Keqi Han, Songlin Zhao, Yao Su, Xiang Li, Yixuan Yuan, Lifang He, and Carl Yang. 2026. Towards a Virtual Neuroscientist: Autonomous Neuroimaging Analysis via Multi-Agent Collaboration.arXiv preprint arXiv:2605.09366(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Tessa Han, Aounon Kumar, Chirag Agarwal, and Himabindu Lakkaraju. 2024. Medsafetybench: Evaluating and improving the medical safety of large language models.Advances in Neural Information Processing Systems37 (2024), 33423– 33454
2024
-
[31]
Vinyas Harish, Felipe Morgado, Ariel D Stern, and Sunit Das. 2021. Artificial intelligence and clinical decision making: the new nature of medical uncertainty. Academic Medicine96, 1 (2021), 31–36
2021
-
[32]
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, and Ping Luo. 2024. Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22170–22183
2024
-
[33]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, et al. 2025. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems43, 2 (2025), 1–55
2025
- [34]
-
[35]
Liesbeth Hunik, Asma Chaabouni, Twan van Laarhoven, Tim C Olde Hartman, Ralph TH Leijenaar, Jochen WL Cals, Annemarie A Uijen, and Henk J Schers
-
[36]
Diagnostic Prediction Models for Primary Care, Based on AI and Electronic Health Records: Systematic Review.JMIR Medical Informatics13, 1 (2025), e62862
2025
-
[37]
Mingyi Jia, Junwen Duan, Yan Song, and Jianxin Wang. 2025. medikal: Inte- grating knowledge graphs as assistants of llms for enhanced clinical diagnosis on emrs. InProceedings of the 31st International Conference on Computational Linguistics. 9278–9298
2025
-
[38]
AQ Jiang, A Sablayrolles, A Mensch, C Bamford, DS Chaplot, D de Las Casas, et al. 2023. Mistral 7B. arXiv 2023.arXiv preprint arXiv:2310.06825(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences11, 14 (2021), 6421
2021
-
[40]
Alistair EW Johnson, Lucas Bulgarelli, Lu Shen, Alvin Gayles, Ayad Shammout, Steven Horng, Tom J Pollard, Sicheng Hao, Benjamin Moody, Brian Gow, et al
-
[41]
MIMIC-IV, a freely accessible electronic health record dataset.Scientific data10, 1 (2023), 1
2023
-
[42]
Alistair EW Johnson, Tom J Pollard, Lu Shen, Li-wei H Lehman, Mengling Feng, Mohammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G Mark. 2016. MIMIC-III, a freely accessible critical care database. Scientific data3, 1 (2016), 1–9
2016
-
[43]
Shreya Johri, Jaehwan Jeong, Benjamin A Tran, Daniel I Schlessinger, Shannon Wongvibulsin, Zhuo Ran Cai, Roxana Daneshjou, and Pranav Rajpurkar. 2024. CRAFT-MD: A conversational evaluation framework for comprehensive assess- ment of clinical LLMs. InAAAI 2024 Spring Symposium on Clinical Foundation Models
2024
-
[44]
Nikhil Khandekar, Qiao Jin, Guangzhi Xiong, Soren Dunn, Serina Applebaum, Zain Anwar, Maame Sarfo-Gyamfi, Conrad Safranek, Abid Anwar, Andrew Zhang, et al. 2024. Medcalc-bench: Evaluating large language models for medical calculations.Advances in Neural Information Processing Systems37 (2024), 84730– 84745
2024
-
[45]
Halil Kilicoglu, Dongwook Shin, Marcelo Fiszman, Graciela Rosemblat, and Thomas C Rindflesch. 2012. SemMedDB: a PubMed-scale repository of biomedi- cal semantic predications.Bioinformatics28, 23 (2012), 3158–3160
2012
-
[46]
Michelle Kang Kim, Carol Rouphael, John McMichael, Nicole Welch, and Srini- vasan Dasarathy. 2023. Challenges in and opportunities for electronic health record-based data analysis and interpretation.Gut and liver18, 2 (2023), 201
2023
-
[47]
Yunsoo Kim, Jinge Wu, Yusuf Abdulle, and Honghan Wu. 2024. MedExQA: Medical question answering benchmark with multiple explanations.arXiv EHRBench: An Automated and Reliable EHR-based Benchmark for Clinical Decision Making with LLMs KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. preprint arXiv:2406.06331(2024)
-
[48]
Rachel Knevel and Katherine P Liao. 2023. From real-world electronic health record data to real-world results using artificial intelligence.Annals of the Rheumatic Diseases82, 3 (2023), 306–311
2023
-
[49]
Yogesh Kumar, Apeksha Koul, Ruchi Singla, and Muhammad Fazal Ijaz. 2023. Artificial intelligence in disease diagnosis: a systematic literature review, syn- thesizing framework and future research agenda.Journal of ambient intelligence and humanized computing14, 7 (2023), 8459–8486
2023
-
[50]
Sunjun Kweon, Jiyoun Kim, Heeyoung Kwak, Dongchul Cha, Hangyul Yoon, Kwang Kim, Jeewon Yang, Seunghyun Won, and Edward Choi. 2024. Ehrnoteqa: An llm benchmark for real-world clinical practice using discharge summaries. Advances in Neural Information Processing Systems37 (2024), 124575–124611
2024
- [51]
-
[52]
Gyubok Lee, Hyeonji Hwang, Seongsu Bae, Yeonsu Kwon, Woncheol Shin, Seongjun Yang, Minjoon Seo, Jong-Yeup Kim, and Edward Choi. 2022. Ehrsql: A practical text-to-sql benchmark for electronic health records.Advances in Neural Information Processing Systems35 (2022), 15589–15601
2022
- [53]
-
[54]
Stella Li, Vidhisha Balachandran, Shangbin Feng, Jonathan Ilgen, Emma Pierson, Pang Wei W Koh, and Yulia Tsvetkov. 2024. Mediq: Question-asking llms and a benchmark for reliable interactive clinical reasoning.Advances in Neural Information Processing Systems37 (2024), 28858–28888
2024
- [55]
-
[56]
Alexander H Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, et al . 2026. Ministral 3.arXiv preprint arXiv:2601.08584(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [57]
- [58]
-
[59]
Jie Liu, Wenxuan Wang, Zizhan Ma, Guolin Huang, Yihang SU, Kao-Jung Chang, Wenting Chen, Haoliang Li, Linlin Shen, and Michael Lyu. 2024. Medchain: Bridging the gap between llm agents and clinical practice through interactive sequential benchmarking.arXiv preprint arXiv:2412.01605(2024)
-
[60]
Jie Liu, Wenxuan Wang, Su Yihang, Jingyuan Huang, Yudi Zhang, Cheng-Yi Li, Wenting Chen, Xiaohan Xing, Kao-Jung Chang, Linlin Shen, et al . 2025. Asclepius: A spectrum evaluation benchmark for medical multi-modal large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 24181–24201
2025
-
[61]
Ruoyu Liu, Kui Xue, Xiaofan Zhang, and Shaoting Zhang. 2025. Interactive evaluation for medical llms via task-oriented dialogue system. InProceedings of the 31st International Conference on Computational Linguistics. 4871–4896
2025
- [62]
-
[63]
Meng Lu, Yuzhang Xie, Zhenyu Bi, Shuxiang Cao, and Xuan Wang. 2025. CROSSAGENTIE: Cross-Type and Cross-Task Multi-Agent LLM Collaboration for Zero-Shot Information Extraction. InFindings of the Association for Compu- tational Linguistics: ACL 2025. 13953–13977
2025
-
[64]
Chaitanya Malaviya, Subin Lee, Sihao Chen, Elizabeth Sieber, Mark Yatskar, and Dan Roth. 2024. Expertqa: Expert-curated questions and attributed answers. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 3025–3045
2024
-
[65]
Izet Masic. 2022. Medical decision making-an overview.Acta Informatica Medica 30, 3 (2022), 230
2022
-
[66]
Nikita Mehandru, Niloufar Golchini, David Bamman, Travis Zack, Melanie F Molina, and Ahmed Alaa. 2025. ER-REASON: A Benchmark Dataset for LLM-Based Clinical Reasoning in the Emergency Room.arXiv preprint arXiv:2505.22919(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Benjamin Molinet, Santiago Marro, Elena Cabrio, and Serena Villata. 2024. Ex- planatory argumentation in natural language for correct and incorrect medical diagnoses.Journal of Biomedical Semantics15, 1 (2024), 8
2024
-
[68]
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, Kashun Shum, Randy Zhong, Juntong Song, and Tong Zhang. 2024. Ragtruth: A hallucination corpus for developing trustworthy retrieval-augmented language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 10862–10878
2024
- [69]
-
[70]
Kimberly J O’malley, Karon F Cook, Matt D Price, Kimberly Raiford Wildes, John F Hurdle, and Carol M Ashton. 2005. Measuring diagnoses: ICD code accuracy.Health services research40, 5p2 (2005), 1620–1639
2005
-
[71]
David Oniani, Xizhi Wu, Shyam Visweswaran, Sumit Kapoor, Shravan Koora- gayalu, Katelyn Polanska, and Yanshan Wang. 2024. Enhancing large language models for clinical decision support by incorporating clinical practice guidelines. In2024 IEEE 12th International Conference on Healthcare Informatics (ICHI). IEEE, 694–702
2024
-
[72]
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. 2022. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. InConference on health, inference, and learning. PMLR, 248–260
2022
-
[73]
Anusri Pampari, Preethi Raghavan, Jennifer Liang, and Jian Peng. 2018. emrqa: A large corpus for question answering on electronic medical records.arXiv preprint arXiv:1809.00732(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[74]
Maria Panagioti, Kanza Khan, Richard N Keers, Aseel Abuzour, Denham Phipps, Evangelos Kontopantelis, Peter Bower, Stephen Campbell, Razaan Haneef, An- thony J Avery, et al. 2019. Prevalence, severity, and nature of preventable patient harm across medical care settings: systematic review and meta-analysis.bmj 366 (2019)
2019
-
[75]
Junwoo Park, Youngwoo Cho, Haneol Lee, Jaegul Choo, and Edward Choi. 2021. Knowledge graph-based question answering with electronic health records. In Machine Learning for Healthcare Conference. PMLR, 36–53
2021
-
[76]
Own-point-of-view
Thierry Pelaccia, Jacques Tardif, Emmanuel Triby, and Bernard Charlin. 2017. A Novel Approach to Study Medical Decision Making in the Clinical Setting: The “Own-point-of-view” Perspective.Academic Emergency Medicine24, 7 (2017), 785–795
2017
-
[77]
Oriel Perets, Ofir Ben Shoham, Nir Grinberg, and Nadav Rappoport. 2025. CUP- Case: Clinically Uncommon Patient Cases and Diagnoses Dataset. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 28293–28301
2025
- [78]
-
[79]
Preethi Raghavan, Jennifer J Liang, Diwakar Mahajan, Rachita Chandra, and Peter Szolovits. 2021. emrkbqa: A clinical knowledge-base question answering dataset. Association for Computational Linguistics
2021
-
[80]
Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. 2024. AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments.arXiv preprint arXiv:2405.07960(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.