Palette: A Modular, Controllable, and Efficient Framework for On-demand Authorized Safety Alignment Relaxation in LLMs
Pith reviewed 2026-06-30 15:59 UTC · model grok-4.3
The pith
Palette identifies a refusal direction in LLMs and internalizes domain-specific relaxations through lightweight adaptation and parameter merging.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
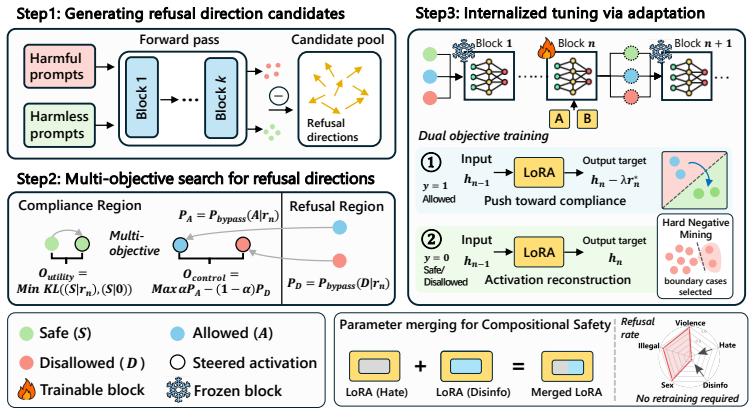
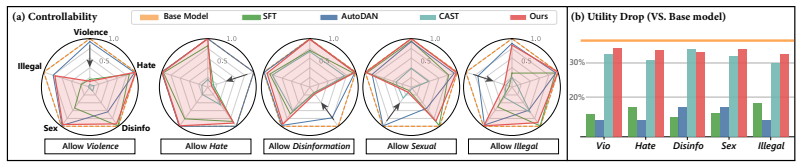
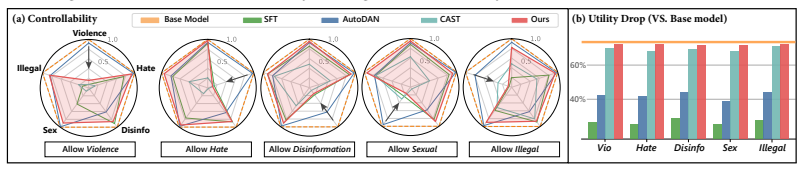
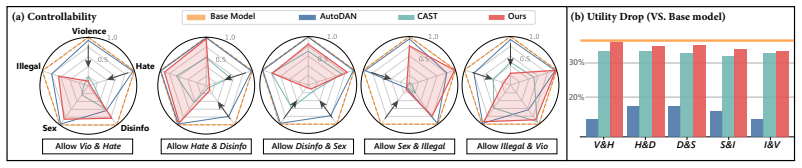
Palette shows that a refusal direction located by multi-objective search can be internalized into an LLM or VLM via lightweight adaptation and then composed across domains by parameter merging, producing precise on-demand safety relaxation for authorized target domains while leaving general safety and utility unchanged.
What carries the argument
Refusal direction identified by multi-objective search, internalized by lightweight adaptation, and composed by parameter merging.
If this is right
- Domain-specific safety controls can be learned once and then activated or deactivated on demand without retraining the base model.
- The same modular controls work across multiple model scales and both pure language and vision-language models.
- General capabilities and performance on non-target safety tasks remain intact after adaptation and merging.
- Foundation models can be configured for diverse professional requirements through composition rather than separate training runs.
Where Pith is reading between the lines
- The merging technique could be tested on alignment properties other than safety, such as output style or domain knowledge boundaries.
- If merging scales cleanly, organizations might maintain one base model and swap small control sets instead of hosting many specialized instances.
- Real-world deployment would need checks for whether merged controls remain stable when users combine them in unexpected ways.
Load-bearing premise
A direction found by search can be added to the model through adaptation and merging without creating interference or unintended safety loss in non-target domains.
What would settle it
Merging two or more domain-specific adaptations produces measurable refusal leakage or accuracy drop on a held-out general safety benchmark that was not observed before merging.
Figures

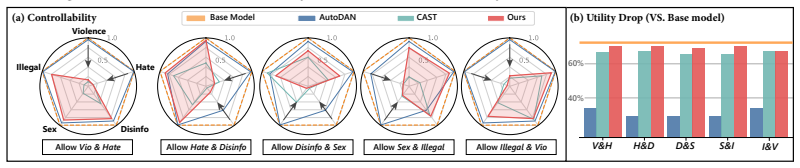

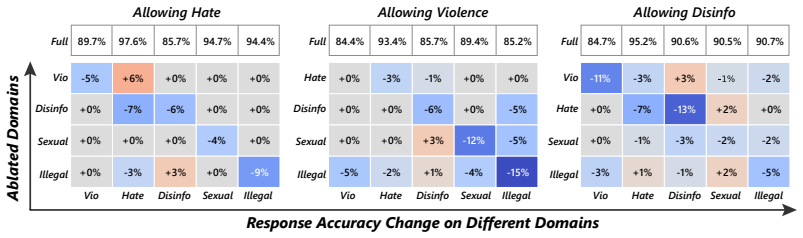
read the original abstract
Current safety alignment of foundation models largely follows a \emph{one-size-fits-all} paradigm, applying the same refusal policy across users and contexts. As a result, models may refuse requests that are unsafe for general users but legitimate for authorized professionals, limiting helpfulness in specialized professional settings. Existing approaches either require costly realignment or rely on inference-time steering that suffers from imprecise control and added latency. To this end, we propose \textsc{Palette}, a modular, controllable, and efficient framework that selectively relaxes refusal behavior on authorized target domains while preserving standard safety elsewhere. Our method identifies a refusal direction via multi-objective search and internalizes it into the model through lightweight adaptation. \textsc{Palette} further supports modular composition: it learns domain-specific safety controls independently and composes them through parameter merging, enabling on-demand multi-domain authorization without retraining. Experiments across four safety benchmarks, multiple model variants, and both LLMs and VLMs show that \textsc{Palette} delivers precise safety control without sacrificing general utility, offering a practical path toward foundation models that adapt to diverse professional needs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Palette, a modular framework for selectively relaxing safety refusals in LLMs and VLMs on authorized target domains. It identifies a refusal direction through multi-objective search, internalizes it via lightweight adaptation, and enables on-demand multi-domain control through independent learning followed by parameter merging. Experiments across four safety benchmarks, multiple model variants, LLMs, and VLMs are claimed to demonstrate precise control without loss of general utility or unintended interference in non-target domains.
Significance. If the experimental claims hold, the work provides a practical, efficient alternative to full realignment or inference-time steering for context-specific safety policies. The modular composition aspect could enable scalable customization for professional use cases while preserving baseline safety, addressing a clear limitation of current one-size-fits-all alignment approaches. The paper ships experimental validation across multiple benchmarks and model types, which strengthens the assessment if the methods and results are reproducible.
minor comments (3)
- [Abstract] The abstract asserts results across four benchmarks and multiple models but the provided text supplies no quantitative tables, baselines, or error bars; ensure §4 or §5 includes these with explicit comparison to steering and realignment baselines.
- [§3] Clarify the precise definition and search objective for the 'refusal direction' (mentioned as an invented entity in the axiom ledger); add a short methods subsection or equation in §3 to make the multi-objective search reproducible.
- [Experiments] The modular merging step is central to the on-demand claim; add a short ablation in the experiments section showing interference metrics when composing more than two domains.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the practical significance of Palette for modular safety customization, and the recommendation of minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical method relying on multi-objective search to identify a refusal direction, followed by lightweight adaptation and parameter merging for modular composition. No equations, derivations, or self-citations appear in the provided text that reduce any claimed outcome to a fitted input or prior result by construction. Central claims rest on experimental validation across benchmarks and models rather than mathematical self-definition or imported uniqueness theorems. This is self-contained against external benchmarks, consistent with the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Refusal behavior in LLMs corresponds to an isolatable direction in internal representations that can be selectively modified without side effects.
invented entities (1)
-
refusal direction
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Online Skill Learning for Web Agents via State-Grounded Dynamic Retrieval
SGDR enables stepwise skill reuse in web agents via sliding-window extraction, dual text-code representations, and state-grounded retrieval, delivering roughly 10% relative gains over baselines on WebArena.
Reference graph
Works this paper leans on
-
[1]
Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625– 5644, 2024
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625– 5644, 2024
2024
-
[2]
Jiaxi Li, Yucheng Shi, Jin Lu, and Ninghao Liu. Mits: Enhanced tree search reasoning for llms via pointwise mutual information.arXiv preprint arXiv:2510.03632, 2025
-
[3]
Qitao Tan, Jun Liu, Zheng Zhan, Caiwei Ding, Yanzhi Wang, Xiaolong Ma, Jaewoo Lee, Jin Lu, and Geng Yuan. Harmony in divergence: Towards fast, accurate, and memory-efficient zeroth-order llm fine-tuning.arXiv preprint arXiv:2502.03304, 2025
-
[4]
Wenqi Liu, Xuemeng Song, Jiaxi Li, Yinwei Wei, Na Zheng, Jianhua Yin, and Liqiang Nie. Mit- igating hallucination through theory-consistent symmetric multimodal preference optimization. arXiv preprint arXiv:2506.11712, 2025
-
[5]
Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to! arXiv preprint arXiv:2310.03693, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Xianjun Yang, Xiao Wang, Qi Zhang, Linda Petzold, William Yang Wang, Xun Zhao, and Dahua Lin. Shadow alignment: The ease of subverting safely-aligned language models.arXiv preprint arXiv:2310.02949, 2023
-
[7]
Shenghui Li, Edith C-H Ngai, Fanghua Ye, and Thiemo V oigt. Peft-as-an-attack! jail- breaking language models during federated parameter-efficient fine-tuning.arXiv preprint arXiv:2411.19335, 2024
-
[8]
Rui Ye, Jingyi Chai, Xiangrui Liu, Yaodong Yang, Yanfeng Wang, and Siheng Chen. Emerging safety attack and defense in federated instruction tuning of large language models.arXiv preprint arXiv:2406.10630, 2024
-
[9]
Qitao Tan, Xiaoying Song, Ningxi Cheng, Ninghao Liu, Xiaoming Zhai, Lingzi Hong, Yanzhi Wang, Zhen Xiang, and Geng Yuan. Q-realign: Piggybacking realignment on quantization for safe and efficient llm deployment.arXiv preprint arXiv:2601.08089, 2026
-
[10]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[11]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
2025
-
[13]
Jingyu Zhang, Ahmed Elgohary, Ahmed Magooda, Daniel Khashabi, and Benjamin Van Durme. Controllable safety alignment: Inference-time adaptation to diverse safety requirements.arXiv preprint arXiv:2410.08968, 2024
-
[14]
Refuse whenever you feel unsafe: Improving safety in llms via decoupled refusal training
Youliang Yuan, Wenxiang Jiao, Wenxuan Wang, Jen-tse Huang, Jiahao Xu, Tian Liang, Pinjia He, and Zhaopeng Tu. Refuse whenever you feel unsafe: Improving safety in llms via decoupled refusal training. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3149–3167, 2025
2025
-
[15]
Controllable preference optimization: Toward controllable multi-objective alignment
Yiju Guo, Ganqu Cui, Lifan Yuan, Ning Ding, Zexu Sun, Bowen Sun, Huimin Chen, Ruobing Xie, Jie Zhou, Yankai Lin, et al. Controllable preference optimization: Toward controllable multi-objective alignment. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1437–1454, 2024. 10
2024
-
[16]
Bruce W Lee, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Erik Miehling, Pierre Dognin, Manish Nagireddy, and Amit Dhurandhar. Programming refusal with conditional activation steering.arXiv preprint arXiv:2409.05907, 2024
-
[17]
Beyond prompt engineering: Robust behavior control in llms via steering target atoms
Mengru Wang, Ziwen Xu, Shengyu Mao, Shumin Deng, Zhaopeng Tu, Huajun Chen, and Ningyu Zhang. Beyond prompt engineering: Robust behavior control in llms via steering target atoms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23381–23399, 2025
2025
-
[18]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Steering Llama 2 via Contrastive Activation Addition
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083, 2024
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083, 2024
2024
-
[21]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
A strongreject for empty jailbreaks.Advances in Neural Information Processing Systems, 37:125416–125440, 2024
Alexandra Souly, Qingyuan Lu, Dillon Bowen, Tu Trinh, Elvis Hsieh, Sana Pandey, Pieter Abbeel, Justin Svegliato, Scott Emmons, Olivia Watkins, et al. A strongreject for empty jailbreaks.Advances in Neural Information Processing Systems, 37:125416–125440, 2024
2024
-
[23]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Chi Zhang, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety alignment of llm via a human-preference dataset.arXiv preprint arXiv:2307.04657, 2023
-
[25]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J Pappas, Florian Tramer, et al. Jailbreakbench: An open robustness benchmark for jailbreaking large language models. Advances in Neural Information Processing Systems, 37:55005–55029, 2024
2024
-
[26]
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, et al. The wmdp benchmark: Measuring and reducing malicious use with unlearning.arXiv preprint arXiv:2403.03218, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Mm-safetybench: A benchmark for safety evaluation of multimodal large language models
Xin Liu, Yichen Zhu, Jindong Gu, Yunshi Lan, Chao Yang, and Yu Qiao. Mm-safetybench: A benchmark for safety evaluation of multimodal large language models. InEuropean Conference on Computer Vision, pages 386–403. Springer, 2024
2024
-
[28]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models.arXiv preprint arXiv:2310.04451, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[34]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
2024
-
[36]
Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
2024
-
[37]
Bill Yuchen Lin, Abhilasha Ravichander, Ximing Lu, Nouha Dziri, Melanie Sclar, Khyathi Chandu, Chandra Bhagavatula, and Yejin Choi. The unlocking spell on base llms: Rethinking alignment via in-context learning.arXiv preprint arXiv:2312.01552, 2023
-
[38]
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work? InProceedings of the 2022 conference on empirical methods in natural language processing, pages 11048–11064, 2022
2022
-
[39]
Roleplay-doh: Enabling domain-experts to create llm-simulated patients via eliciting and adhering to principles
Ryan Louie, Ananjan Nandi, William Fang, Cheng Chang, Emma Brunskill, and Diyi Yang. Roleplay-doh: Enabling domain-experts to create llm-simulated patients via eliciting and adhering to principles. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10570–10603, 2024
2024
-
[40]
From distributional to overton pluralism: Investi- gating large language model alignment
Thom Lake, Eunsol Choi, and Greg Durrett. From distributional to overton pluralism: Investi- gating large language model alignment. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6794–6814, 2025
2025
-
[41]
Pace: Parsimonious concept engineering for large language models
Jinqi Luo, Tianjiao Ding, Kwan H Chan, Darshan Thaker, Aditya Chattopadhyay, Chris Callison- Burch, and René Vidal. Pace: Parsimonious concept engineering for large language models. Advances in Neural Information Processing Systems, 37:99347–99381, 2024
2024
-
[42]
The art of saying no: Contextual noncompliance in language models.Advances in Neural Information Processing Systems, 37:49706–49748, 2024
Faeze Brahman, Sachin Kumar, Vidhisha Balachandran, Pradeep Dasigi, Valentina Pyatkin, Abhilasha Ravichander, Sarah Wiegreffe, Nouha Dziri, Khyathi Chandu, Jack Hessel, et al. The art of saying no: Contextual noncompliance in language models.Advances in Neural Information Processing Systems, 37:49706–49748, 2024
2024
-
[43]
Fine-grained human feedback gives better rewards for language model training.Advances in Neural Information Processing Systems, 36:59008–59033, 2023
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A Smith, Mari Ostendorf, and Hannaneh Hajishirzi. Fine-grained human feedback gives better rewards for language model training.Advances in Neural Information Processing Systems, 36:59008–59033, 2023
2023
-
[44]
Beyond one-preference-fits-all alignment: Multi-objective direct preference optimization
Zhanhui Zhou, Jie Liu, Jing Shao, Xiangyu Yue, Chao Yang, Wanli Ouyang, and Yu Qiao. Beyond one-preference-fits-all alignment: Multi-objective direct preference optimization. In Findings of the Association for Computational Linguistics: ACL 2024, pages 10586–10613, 2024. 12
2024
-
[45]
Self-improvement towards pareto optimality: Mitigating preference conflicts in multi-objective alignment
Moxin Li, Yuantao Zhang, Wenjie Wang, Wentao Shi, Zhuo Liu, Fuli Feng, and Tat-Seng Chua. Self-improvement towards pareto optimality: Mitigating preference conflicts in multi-objective alignment. InFindings of the Association for Computational Linguistics: ACL 2025, pages 11010–11031, 2025
2025
-
[46]
Gradient- adaptive policy optimization: Towards multi-objective alignment of large language models
Chengao Li, Hanyu Zhang, Yunkun Xu, Hongyan Xue, Xiang Ao, and Qing He. Gradient- adaptive policy optimization: Towards multi-objective alignment of large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11214–11232, 2025
2025
-
[47]
Rewarded soups: towards pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards.Advances in Neural Information Processing Systems, 36:71095–71134, 2023
Alexandre Rame, Guillaume Couairon, Corentin Dancette, Jean-Baptiste Gaya, Mustafa Shukor, Laure Soulier, and Matthieu Cord. Rewarded soups: towards pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards.Advances in Neural Information Processing Systems, 36:71095–71134, 2023
2023
-
[48]
Joel Jang, Seungone Kim, Bill Yuchen Lin, Yizhong Wang, Jack Hessel, Luke Zettlemoyer, Hannaneh Hajishirzi, Yejin Choi, and Prithviraj Ammanabrolu. Personalized soups: Per- sonalized large language model alignment via post-hoc parameter merging.arXiv preprint arXiv:2310.11564, 2023
-
[49]
Warm: On the benefits of weight averaged reward models.arXiv preprint arXiv:2401.12187, 2024
Alexandre Ramé, Nino Vieillard, Léonard Hussenot, Robert Dadashi, Geoffrey Cideron, Olivier Bachem, and Johan Ferret. Warm: On the benefits of weight averaged reward models.arXiv preprint arXiv:2401.12187, 2024
-
[50]
Representation surgery for multi-task model merging.arXiv preprint arXiv:2402.02705, 2024
Enneng Yang, Li Shen, Zhenyi Wang, Guibing Guo, Xiaojun Chen, Xingwei Wang, and Dacheng Tao. Representation surgery for multi-task model merging.arXiv preprint arXiv:2402.02705, 2024
-
[51]
arXiv preprint arXiv:2405.20947 , year=
Justin Cui, Wei-Lin Chiang, Ion Stoica, and Cho-Jui Hsieh. Or-bench: An over-refusal benchmark for large language models.arXiv preprint arXiv:2405.20947, 2024
-
[52]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. Xstest: A test suite for identifying exaggerated safety behaviours in large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers),...
2024
-
[53]
TrustLLM: Trustworthiness in Large Language Models
Yue Huang, Lichao Sun, Haoran Wang, Siyuan Wu, Qihui Zhang, Yuan Li, Chujie Gao, Yixin Huang, Wenhan Lyu, Yixuan Zhang, et al. Trustllm: Trustworthiness in large language models. arXiv preprint arXiv:2401.05561, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Mitigating exaggerated safety in large language models.arXiv preprint arXiv:2405.05418, 2024
Ruchira Ray and Ruchi Bhalani. Mitigating exaggerated safety in large language models.arXiv preprint arXiv:2405.05418, 2024
-
[55]
Mahavir Dabas, Si Chen, Charles Fleming, Ming Jin, and Ruoxi Jia. Just enough shifts: Mitigating over-refusal in aligned language models with targeted representation fine-tuning. arXiv preprint arXiv:2507.04250, 2025
-
[56]
Junbo Zhang, Ran Chen, Qianli Zhou, Xinyang Deng, and Wen Jiang. Understanding and mitigating over-refusal for large language models via safety representation.arXiv preprint arXiv:2511.19009, 2025
-
[57]
Xinpeng Wang, Chengzhi Hu, Paul Röttger, and Barbara Plank. Surgical, cheap, and flexi- ble: Mitigating false refusal in language models via single vector ablation.arXiv preprint arXiv:2410.03415, 2024
-
[58]
The hidden dimensions of llm alignment: A multi-dimensional safety analysis.arXiv e-prints, pages arXiv–2502, 2025
Wenbo Pan, Zhichao Liu, Qiguang Chen, Xiangyang Zhou, Haining Yu, and Xiaohua Jia. The hidden dimensions of llm alignment: A multi-dimensional safety analysis.arXiv e-prints, pages arXiv–2502, 2025
2025
-
[59]
Leheng Sheng, Changshuo Shen, Weixiang Zhao, Junfeng Fang, Xiaohao Liu, Zhenkai Liang, Xiang Wang, An Zhang, and Tat-Seng Chua. Alphasteer: Learning refusal steering with principled null-space constraint.arXiv preprint arXiv:2506.07022, 2025. 13
-
[60]
Mitigating content effects on reasoning in language models through fine-grained activation steering
Marco Valentino, Geonhee Kim, Dhairya Dalal, Zhixue Zhao, and André Freitas. Mitigating content effects on reasoning in language models through fine-grained activation steering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33314–33322, 2026
2026
-
[61]
Steering away from harm: An adaptive approach to defending vision language model against jailbreaks
Han Wang, Gang Wang, and Huan Zhang. Steering away from harm: An adaptive approach to defending vision language model against jailbreaks. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29947–29957, 2025
2025
-
[62]
Steering language model refusal with sparse autoencoders.arXiv preprint arXiv:2411.11296, 2024
Kyle O’Brien, David Majercak, Xavier Fernandes, Richard Edgar, Blake Bullwinkel, Jingya Chen, Harsha Nori, Dean Carignan, Eric Horvitz, and Forough Poursabzi-Sangdeh. Steering language model refusal with sparse autoencoders.arXiv preprint arXiv:2411.11296, 2024
-
[63]
Pappas, and Eric Wong
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. In2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 23–42, 2025
2025
-
[64]
Hypersteer: Activation steering at scale with hypernetworks.ArXiv, abs/2506.03292, 2025
Jiuding Sun, Sidharth Baskaran, Zhengxuan Wu, Michael Benjamin Sklar, Christopher Potts, and Atticus Geiger. Hypersteer: Activation steering at scale with hypernetworks.ArXiv, abs/2506.03292, 2025
-
[65]
Unlocking general long chain-of-thought reasoning capabilities of large language models via representation engineering
Xinyu Tang, Xiaolei Wang, Zhihao Lv, Yingqian Min, Wayne Xin Zhao, Binbin Hu, Ziqi Liu, and Zhiqiang Zhang. Unlocking general long chain-of-thought reasoning capabilities of large language models via representation engineering. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6832–684...
2025
-
[66]
Catastrophic Jailbreak of Open-source LLMs via Exploiting Generation
Yangsibo Huang, Samyak Gupta, Mengzhou Xia, Kai Li, and Danqi Chen. Catastrophic jailbreak of open-source llms via exploiting generation.ArXiv, abs/2310.06987, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
Harm- bench: A standardized evaluation framework for automated red teaming and robust refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. Harm- bench: A standardized evaluation framework for automated red teaming and robust refusal. In International Conference on Machine Learning, 2024
2024
-
[68]
Stanford alpaca: An instruction-following llama model, 2023
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Stanford alpaca: An instruction-following llama model, 2023
2023
-
[69]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Visual token sparsification for efficient vision-language model inference.arXiv preprint arXiv:2410.04417, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Mutual effort for efficiency: A similarity-based token pruning for vision transformers in self-supervised learning
Sheng Li, Qitao Tan, Yue Dai, Zhenglun Kong, Tianyu Wang, Jun Liu, Ao Li, Ninghao Liu, Yufei Ding, Xulong Tang, et al. Mutual effort for efficiency: A similarity-based token pruning for vision transformers in self-supervised learning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[71]
Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Chendi Li, Jinghua Yan, Yu Bai, Ponnuswamy Sadayappan, Xia Hu, et al. Topv: Compatible token pruning with inference time optimization for fast and low-memory multimodal vision language model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19803–19813, 2025. 14 A Relat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.