An Efficient and Privacy-Preserving Architecture for Cross-Institutional Collaborative RAG
Pith reviewed 2026-06-29 21:50 UTC · model grok-4.3
The pith
A scrambled attention protocol lets institutions run federated RAG together without exposing private data or retraining models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
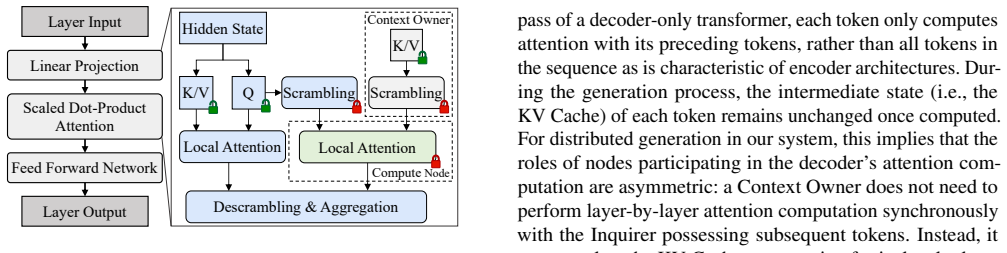
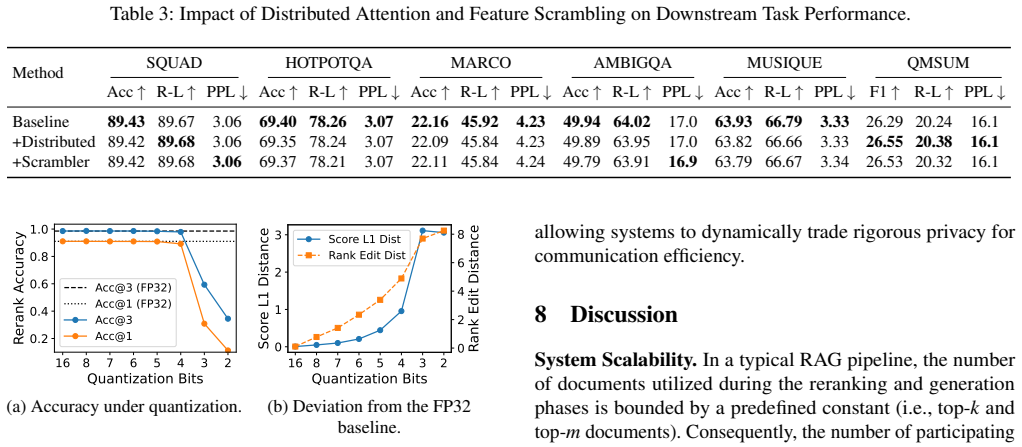
The Scrambled Distributed Attention protocol uses numerically stable feature scrambling and token permutation to dynamically delegate attention computations across nodes, thereby decoupling execution from data localization without exposing plaintext and while resisting intermediate state inversion attacks.
What carries the argument
Scrambled Distributed Attention protocol: it scrambles and permutes token features so that cross-node attention can occur without plaintext exposure or data movement.
If this is right
- Model utility remains within 0.1 percent of the non-private baseline.
- End-to-end latency falls by up to 62 times relative to existing secure baselines.
- Practical throughput for human-scale reading is maintained across institutions.
- No model retraining or specialized hardware is required.
Where Pith is reading between the lines
- The same scrambling approach might apply to other transformer layers that require cross-device communication.
- Performance in real multi-institution networks with variable network latency remains to be measured.
- The method could be combined with differential privacy techniques for stronger guarantees.
Load-bearing premise
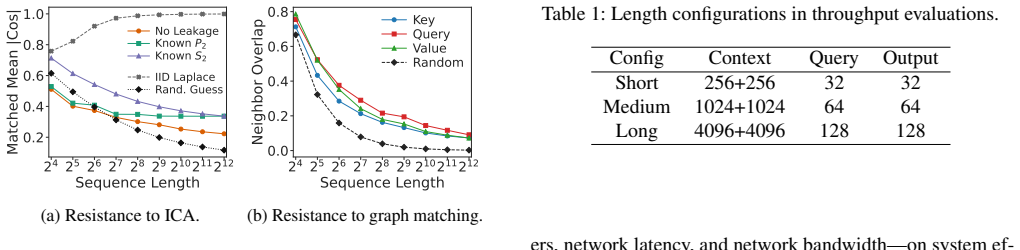
Numerically stable feature scrambling combined with token permutation prevents reconstruction of original tokens from any intermediate states passed between institutions.
What would settle it
An experiment in which an attacker recovers original input tokens or KV cache contents from the scrambled delegated states would disprove the privacy claim.
Figures




read the original abstract
Retrieval-Augmented Generation (RAG) empowers LLMs with external knowledge, making cross-institutional domain-specific knowledge base integration a highly promising deployment paradigm. Despite this potential, strict privacy regulations create severe "data silos" that obstruct such collaboration. Building federated RAG systems requires distributed inference, but the Transformer's self-attention mechanism fundamentally conflicts with this by mandating cross-node access to distributed Key-Value caches. To address this challenge, we present FedRAG, a high-throughput, privacy-preserving federated RAG framework. At its core is a novel Scrambled Distributed Attention protocol that utilizes numerically stable feature scrambling and token permutation. By dynamically delegating scrambled computations to collaborating nodes, our system successfully decouples attention execution from data localization without exposing plaintext. Crucially, our approach requires no specialized hardware or model retraining, circumventing the prohibitive latency and communication overheads of cryptographic solutions while robustly defending against intermediate state inversion attacks. Extensive evaluations demonstrate our framework preserves negligible (<0.1\%) model utility degradation and achieves up to a 62$\times$ latency reduction over existing secure baselines, sustaining practical, human-reading throughput for cross-institutional knowledge synergy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FedRAG, a federated RAG framework for cross-institutional collaboration under privacy constraints. Its core contribution is the Scrambled Distributed Attention protocol, which applies numerically stable feature scrambling and token permutation to delegate computations across nodes. This is claimed to decouple attention from data localization without exposing plaintext, require no specialized hardware or retraining, defend against intermediate state inversion attacks, and deliver <0.1% utility degradation with up to 62× latency reduction versus secure baselines.
Significance. If the privacy guarantees and performance claims hold, the work would address a practical barrier to collaborative RAG by avoiding the overhead of cryptographic primitives while sustaining usable throughput. The absence of model retraining or specialized hardware is a notable strength relative to many secure-inference baselines.
major comments (1)
- [Abstract / §3] Abstract and §3 (Scrambled Distributed Attention protocol): the central privacy claim—that numerically stable feature scrambling plus token permutation 'robustly defends against intermediate state inversion attacks' without exposing plaintext—is asserted without a formal security model, game-based definition, reduction to a hard problem, or any attack experiments (e.g., reconstruction or gradient-inversion attempts on scrambled KV caches). This is load-bearing for the entire privacy premise and the subsequent utility/latency results.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the privacy analysis of FedRAG. We address the major comment below and commit to revisions that strengthen the presentation without altering the core technical claims or results.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Scrambled Distributed Attention protocol): the central privacy claim—that numerically stable feature scrambling plus token permutation 'robustly defends against intermediate state inversion attacks' without exposing plaintext—is asserted without a formal security model, game-based definition, reduction to a hard problem, or any attack experiments (e.g., reconstruction or gradient-inversion attempts on scrambled KV caches). This is load-bearing for the entire privacy premise and the subsequent utility/latency results.
Authors: We agree that the manuscript would be strengthened by a more explicit treatment of the privacy argument. The current version motivates the defense through the protocol design: feature scrambling is constructed to be numerically stable (preserving the exact attention computation) while rendering intermediate states non-invertible without the secret parameters, and token permutation breaks positional correspondence. These choices are intended to prevent plaintext exposure and thwart inversion without requiring cryptographic primitives. We acknowledge the absence of a formal game-based model or reduction in the submitted version. In revision we will expand §3 with an informal security argument detailing why the combination of scrambling and permutation renders reconstruction computationally impractical under standard assumptions on the adversary's knowledge, and we will add targeted experiments in the evaluation section that attempt reconstruction and gradient-inversion attacks on the scrambled KV caches. These additions will be empirical and explanatory rather than a full cryptographic proof, consistent with the paper's focus on practical systems performance. revision: yes
Circularity Check
No circularity detected; claims rest on empirical evaluation rather than self-referential definitions
full rationale
The provided abstract and context contain no equations, fitted parameters, or derivation steps that reduce performance or security claims to their own inputs by construction. The Scrambled Distributed Attention protocol is introduced as a novel mechanism whose privacy and utility properties are asserted via description and external evaluation, without self-definitional loops, renamed known results, or load-bearing self-citations that collapse the argument. Absence of mathematical derivations in the visible text precludes any of the enumerated circularity patterns. This is the expected outcome for a systems paper whose central contributions are architectural and empirical.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Transformer's self-attention mechanism fundamentally conflicts with distributed inference by mandating cross-node access to distributed Key-Value caches.
invented entities (1)
-
Scrambled Distributed Attention protocol
no independent evidence
Forward citations
Cited by 1 Pith paper
-
When Latent Agents Lie: KV-Cache Integrity in Multi-Agent LLM Collaboration
KV-cache sharing boosts multi-agent QA performance but enables undetectable tampering; HMAC manifests binding agent, session, and payload reliably detect changes.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt- oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Self-rag: Learning to retrieve, gen- erate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, gen- erate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[3]
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, An- drew McNamara, Bhaskar Mitra, Tri Nguyen, et al. Ms marco: A human generated machine reading comprehen- sion dataset.arXiv preprint arXiv:1611.09268, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
Improving language mod- els by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language mod- els by retrieving from trillions of tokens. InInterna- tional conference on machine learning, pages 2206–
-
[5]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216, 4(5), 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Homomorphic encryption for arithmetic of ap- proximate numbers
Jung Hee Cheon, Andrey Kim, Miran Kim, and Yongsoo Song. Homomorphic encryption for arithmetic of ap- proximate numbers. InInternational conference on the theory and application of cryptology and information security, pages 409–437. Springer, 2017
2017
-
[8]
Thirty years of graph matching in pattern recognition.International journal of pattern recognition and artificial intelligence, 18(03):265–298, 2004
Donatello Conte, Pasquale Foggia, Carlo Sansone, and Mario Vento. Thirty years of graph matching in pattern recognition.International journal of pattern recognition and artificial intelligence, 18(03):265–298, 2004. 13
2004
-
[9]
Improved achiev- ability and converse bounds for erdos-rényi graph match- ing.ACM SIGMETRICS performance evaluation review, 44(1):63–72, 2016
Daniel Cullina and Negar Kiyavash. Improved achiev- ability and converse bounds for erdos-rényi graph match- ing.ACM SIGMETRICS performance evaluation review, 44(1):63–72, 2016
2016
-
[10]
Flashattention: Fast and memory- efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344– 16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory- efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344– 16359, 2022
2022
-
[11]
Depth gives a false sense of privacy:{LLM} internal states inversion
Tian Dong, Yan Meng, Shaofeng Li, Guoxing Chen, Zhen Liu, and Haojin Zhu. Depth gives a false sense of privacy:{LLM} internal states inversion. In34th USENIX Security Symposium (USENIX Security 25), pages 1629–1648, 2025
2025
-
[12]
Puma: Secure in- ference of llama-7b in five minutes.Security and Safety, 4:2025014, 2025
Ye Dong, Wen-jie Lu, Yancheng Zheng, Haoqi Wu, Derun Zhao, Jin Tan, Zhicong Huang, Cheng Hong, Tao Wei, Wen-Guang Chen, et al. Puma: Secure in- ference of llama-7b in five minutes.Security and Safety, 4:2025014, 2025
2025
-
[13]
Dp-forward: Fine- tuning and inference on language models with differen- tial privacy in forward pass
Minxin Du, Xiang Yue, Sherman SM Chow, Tianhao Wang, Chenyu Huang, and Huan Sun. Dp-forward: Fine- tuning and inference on language models with differen- tial privacy in forward pass. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communi- cations Security, pages 2665–2679, 2023
2023
-
[14]
Unsplit: Data-oblivious model inversion, model stealing, and label inference attacks against split learning
Ege Erdo˘gan, Alptekin Küpçü, and A Ercüment Çiçek. Unsplit: Data-oblivious model inversion, model stealing, and label inference attacks against split learning. In Proceedings of the 21st Workshop on Privacy in the Electronic Society, pages 115–124, 2022
2022
-
[15]
How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 55–65, 2019
2019
-
[16]
Simcse: Simple contrastive learning of sentence embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. Simcse: Simple contrastive learning of sentence embeddings. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 6894– 6910, 2021
2021
-
[17]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Retrieval augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. InInternational conference on ma- chine learning, pages 3929–3938. PMLR, 2020
2020
-
[20]
Iron: Private infer- ence on transformers.Advances in neural information processing systems, 35:15718–15731, 2022
Meng Hao, Hongwei Li, Hanxiao Chen, Pengzhi Xing, Guowen Xu, and Tianwei Zhang. Iron: Private infer- ence on transformers.Advances in neural information processing systems, 35:15718–15731, 2022
2022
-
[21]
Independent component analysis: algorithms and applications.Neural networks, 13(4-5):411–430, 2000
Aapo Hyvärinen and Erkki Oja. Independent component analysis: algorithms and applications.Neural networks, 13(4-5):411–430, 2000
2000
-
[22]
Leveraging pas- sage retrieval with generative models for open domain question answering
Gautier Izacard and Edouard Grave. Leveraging pas- sage retrieval with generative models for open domain question answering. InProceedings of the 16th con- ference of the european chapter of the association for computational linguistics: main volume, pages 874–880, 2021
2021
-
[23]
Quantization and training of neural networks for efficient integer-arithmetic-only inference
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2704– 2713, 2018
2018
-
[24]
Billion- scale similarity search with gpus.IEEE transactions on big data, 7(3):535–547, 2019
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion- scale similarity search with gpus.IEEE transactions on big data, 7(3):535–547, 2019
2019
-
[25]
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Generalization through memorization: Nearest neighbor language models. arXiv preprint arXiv:1911.00172, 2019
-
[26]
Crypten: Secure multi-party computation meets machine learning.Advances in Neural Information Pro- cessing Systems, 34:4961–4973, 2021
Brian Knott, Shobha Venkataraman, Awni Hannun, Shubho Sengupta, Mark Ibrahim, and Laurens van der Maaten. Crypten: Secure multi-party computation meets machine learning.Advances in Neural Information Pro- cessing Systems, 34:4961–4973, 2021
2021
-
[27]
PhD thesis, UC Berkeley, 2025
Woosuk Kwon.vLLM: An Efficient Inference Engine for Large Language Models. PhD thesis, UC Berkeley, 2025
2025
-
[28]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In International Conference on Machine Learning, pages 19274–19286. PMLR, 2023. 14
2023
-
[29]
Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[30]
Senyao Li, Haozhao Wang, Wenchao Xu, Rui Zhang, Song Guo, Jingling Yuan, Xian Zhong, Tianwei Zhang, and Ruixuan Li. Collaborative inference and learning between edge slms and cloud llms: A survey of algo- rithms, execution, and open challenges.arXiv preprint arXiv:2507.16731, 2025
-
[31]
Alexander H Liu, Kartik Khandelwal, Sandeep Subra- manian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexan- dre Gavaudan, et al. Ministral 3.arXiv preprint arXiv:2601.08584, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Ring Attention with Blockwise Transformers for Near-Infinite Context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring at- tention with blockwise transformers for near-infinite context.arXiv preprint arXiv:2310.01889, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Zhifan Luo, Shuo Shao, Su Zhang, Lijing Zhou, Yuke Hu, Chenxu Zhao, Zhihao Liu, and Zhan Qin. Shadow in the cache: Unveiling and mitigating pri- vacy risks of kv-cache in llm inference.arXiv preprint arXiv:2508.09442, 2025
-
[34]
Ambigqa: Answering ambiguous open-domain questions
Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. Ambigqa: Answering ambiguous open-domain questions. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 5783–5797, 2020
2020
-
[35]
Text embeddings reveal (al- most) as much as text
John Morris, V olodymyr Kuleshov, Vitaly Shmatikov, and Alexander M Rush. Text embeddings reveal (al- most) as much as text. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12448–12460, 2023
2023
-
[36]
Training language models to follow instructions with human feedback.Advances in neural information pro- cessing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information pro- cessing systems, 35:27730–27744, 2022
2022
-
[37]
Public-key cryptosystems based on com- posite degree residuosity classes
Pascal Paillier. Public-key cryptosystems based on com- posite degree residuosity classes. InInternational con- ference on the theory and applications of cryptographic techniques, pages 223–238. Springer, 1999
1999
-
[38]
Unifying large language mod- els and knowledge graphs: A roadmap.IEEE Transac- tions on Knowledge and Data Engineering, 36(7):3580– 3599, 2024
Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu. Unifying large language mod- els and knowledge graphs: A roadmap.IEEE Transac- tions on Knowledge and Data Engineering, 36(7):3580– 3599, 2024
2024
-
[39]
Bolt: Privacy-preserving, accu- rate and efficient inference for transformers
Qi Pang, Jinhao Zhu, Helen Möllering, Wenting Zheng, and Thomas Schneider. Bolt: Privacy-preserving, accu- rate and efficient inference for transformers. In2024 IEEE Symposium on Security and Privacy (SP), pages 4753–4771. IEEE, 2024
2024
-
[40]
Squad: 100,000+ questions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. InProceedings of the 2016 conference on empirical methods in natural language processing, pages 2383–2392, 2016
2016
-
[41]
Trusted execution environment: What it is, and what it is not
Mohamed Sabt, Mohammed Achemlal, and Abdelmad- jid Bouabdallah. Trusted execution environment: What it is, and what it is not. In2015 IEEE Trust- com/BigDataSE/Ispa, volume 1, pages 57–64. IEEE, 2015
2015
-
[42]
Large language models encode clinical knowledge.Na- ture, 620(7972):172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mah- davi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge.Na- ture, 620(7972):172–180, 2023
2023
-
[43]
On the limitations of unsupervised bilingual dictionary in- duction
Anders Søgaard, Sebastian Ruder, and Ivan Vuli´c. On the limitations of unsupervised bilingual dictionary in- duction. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 778–788, 2018
2018
-
[44]
Hidden no more: Attacking and defending private third-party llm inference
Rahul Krishna Thomas, Louai Zahran, Erica Choi, Ak- ilesh Potti, Micah Goldblum, and Arka Pal. Hidden no more: Attacking and defending private third-party llm inference. InForty-second International Conference on Machine Learning, 2025
2025
-
[45]
Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539– 554, 2022
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539– 554, 2022
2022
-
[46]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[47]
Milvus: A purpose- built vector data management system
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xiangyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. Milvus: A purpose- built vector data management system. InProceedings of the 2021 international conference on management of data, pages 2614–2627, 2021. 15
2021
-
[48]
A survey of model architectures in information retrieval
Zhichao Xu, Fengran Mo, Zhiqi Huang, Crystina Zhang, Puxuan Yu, Bei Wang, Jimmy Lin, and Vivek Srikumar. A survey of model architectures in information retrieval. arXiv preprint arXiv:2502.14822, 2025
-
[49]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chen- gen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Parallelizing linear transformers with the delta rule over sequence length.Advances in neu- ral information processing systems, 37:115491–115522, 2024
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length.Advances in neu- ral information processing systems, 37:115491–115522, 2024
2024
-
[51]
Hotpotqa: A dataset for diverse, ex- plainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Ben- gio, William Cohen, Ruslan Salakhutdinov, and Christo- pher D Manning. Hotpotqa: A dataset for diverse, ex- plainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
2018
-
[52]
Pre- trained transformers for text ranking: Bert and beyond
Andrew Yates, Rodrigo Nogueira, and Jimmy Lin. Pre- trained transformers for text ranking: Bert and beyond. InProceedings of the 14th ACM International Confer- ence on web search and data mining, pages 1154–1156, 2021
2021
-
[53]
Scx: Stateless kv-cache encoding for cloud-scale confidential trans- former serving
Mu Yuan, Lan Zhang, Liekang Zeng, Siyang Jiang, Bu- fang Yang, Di Duan, and Guoliang Xing. Scx: Stateless kv-cache encoding for cloud-scale confidential trans- former serving. InProceedings of the ACM SIGCOMM 2025 Conference, pages 39–54, 2025
2025
-
[54]
Pri- vacyrestore: Privacy-preserving inference in large lan- guage models via privacy removal and restoration
Ziqian Zeng, Jianwei Wang, Junyao Yang, Zhengdong Lu, Haoran Li, Huiping Zhuang, and Cen Chen. Pri- vacyrestore: Privacy-preserving inference in large lan- guage models via privacy removal and restoration. In Proceedings of the 63rd Annual Meeting of the Associ- ation for Computational Linguistics (Volume 1: Long Papers), pages 10821–10855, 2025
2025
-
[55]
mgte: Generalized long- context text representation and reranking models for multilingual text retrieval
Xin Zhang, Yanzhao Zhang, Dingkun Long, Wen Xie, Ziqi Dai, Jialong Tang, Huan Lin, Baosong Yang, Pengjun Xie, Fei Huang, et al. mgte: Generalized long- context text representation and reranking models for multilingual text retrieval. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 1393–1412, 2024
2024
-
[56]
Siren’s song in the ai ocean: A survey on hallucination in large language models.Computa- tional Linguistics, 51(4):1373–1418, 2025
Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yu- long Chen, et al. Siren’s song in the ai ocean: A survey on hallucination in large language models.Computa- tional Linguistics, 51(4):1373–1418, 2025
2025
-
[57]
Retrieval-augmented generation for ai-generated content: A survey.Data Science and Engineering, pages 1–29, 2026
Penghao Zhao, Hailin Zhang, Qinhan Yu, Zhengren Wang, Yunteng Geng, Fangcheng Fu, Ling Yang, Wen- tao Zhang, Jie Jiang, and Bin Cui. Retrieval-augmented generation for ai-generated content: A survey.Data Science and Engineering, pages 1–29, 2026
2026
-
[58]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xi- aolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large lan- guage models.arXiv preprint arXiv:2303.18223, 1(2):1– 124, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Fei Zheng, Chaochao Chen, Zhongxuan Han, and Xi- aolin Zheng. Permllm: Private inference of large lan- guage models within 3 seconds under wan.arXiv preprint arXiv:2405.18744, 2024
-
[60]
A review on edge large language models: Design, execution, and applications
Yue Zheng, Yuhao Chen, Bin Qian, Xiufang Shi, Yuan- chao Shu, and Jiming Chen. A review on edge large language models: Design, execution, and applications. ACM Computing Surveys, 57(8):1–35, 2025
2025
-
[61]
Qmsum: A new bench- mark for query-based multi-domain meeting summa- rization
Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan, Asli Celikyilmaz, Yang Liu, Xipeng Qiu, et al. Qmsum: A new bench- mark for query-based multi-domain meeting summa- rization. InProceedings of the 2021 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies, ...
2021
-
[62]
Training lan- guage models with memory augmentation
Zexuan Zhong, Tao Lei, and Danqi Chen. Training lan- guage models with memory augmentation. InProceed- ings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5657–5673, 2022. 16 A Numerical Stability Evaluation We evaluate the numerical stability of using a random dense matrix for feature scrambling. Table 4 presents the re...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.