Can LLMs Introspect? A Reality Check
Pith reviewed 2026-06-29 21:21 UTC · model grok-4.3
The pith
Models cannot reliably distinguish internal state interventions from input manipulations, and input-only classifiers match their performance on hidden-state tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
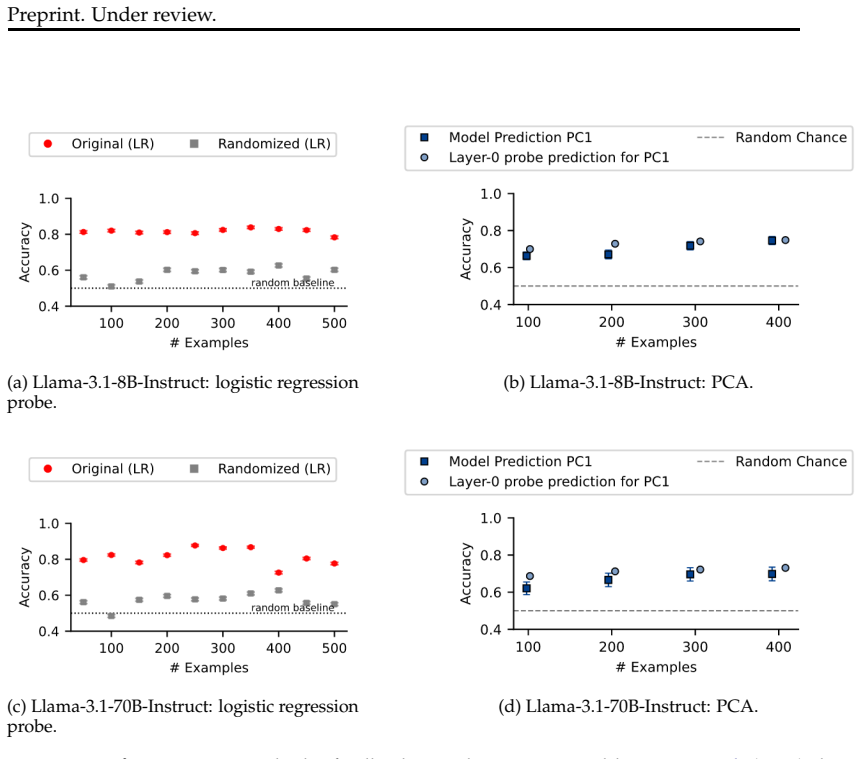
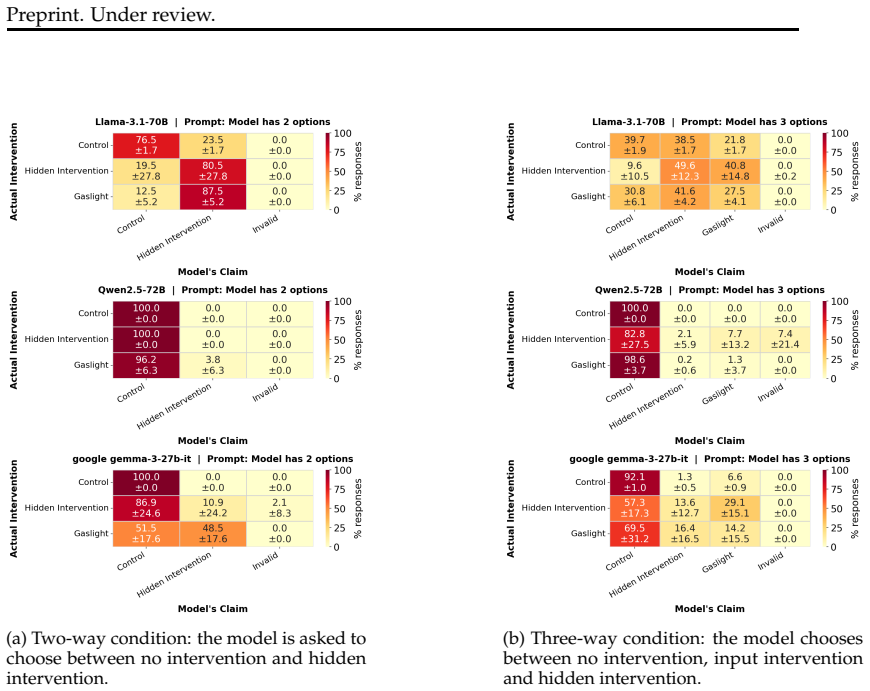
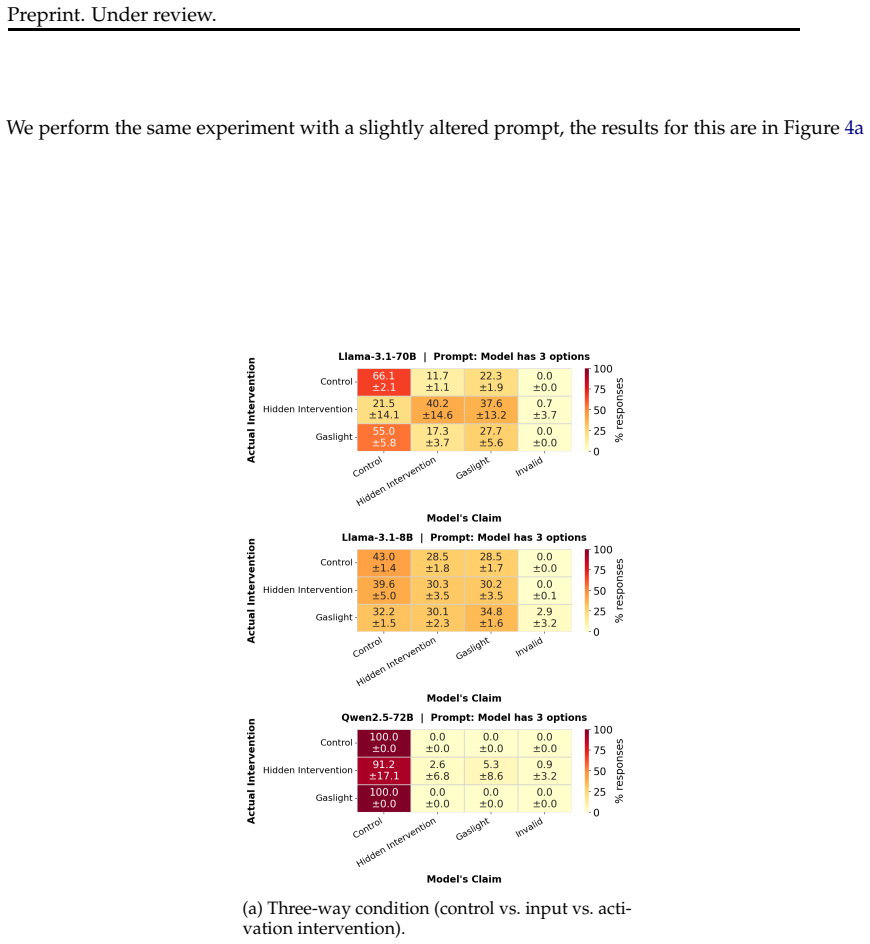
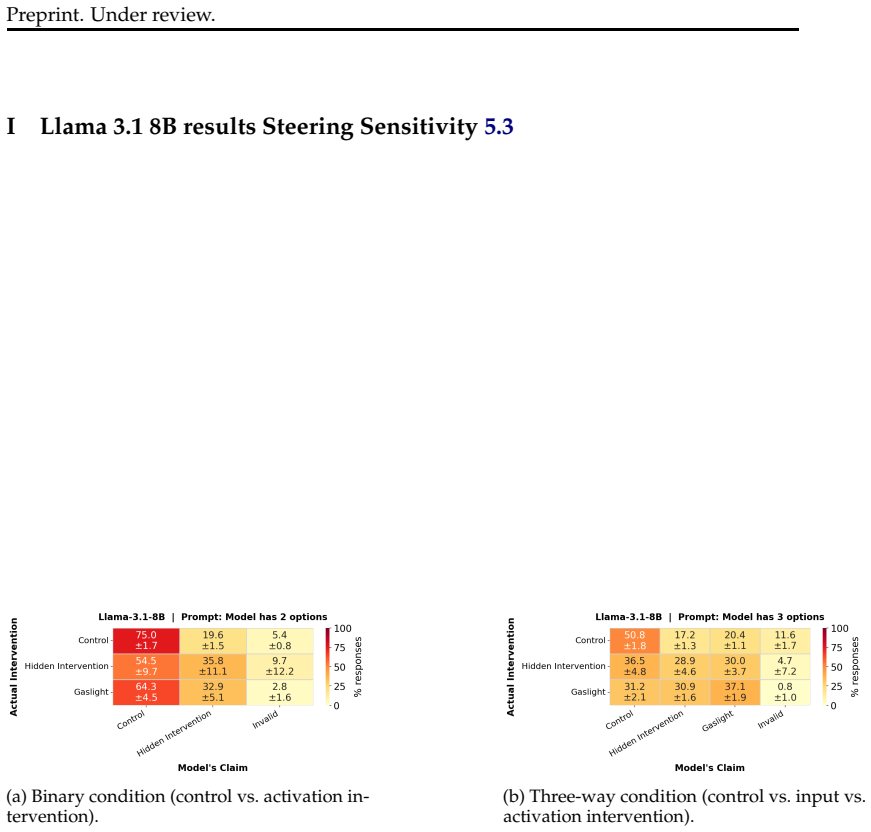
Models cannot reliably distinguish interventions on their internal states from manipulations of the input, suggesting their success reflects general anomaly detection rather than specific sensitivity to internal changes. Classifiers with access only to the input achieve equivalent performance to the model's own in-context predictions of labels derived from hidden states. In a relabeled control setting where semantics cannot guide the answer, models perform closer to chance, indicating that current evidence does not establish privileged internal access or metacognitive monitoring.
What carries the argument
Two controlled evaluation paradigms: detecting tampered internal states versus input anomalies, and predicting labels from hidden states with input-only classifier baselines plus a relabeled semantic-control condition.
If this is right
- Success on internal-state detection tasks reflects general anomaly detection rather than targeted introspection.
- In-context label predictions derived from hidden states can be replicated by models given only the input.
- Relabeled controls reveal that models rely on task semantics rather than internal representations.
- Behavioral evidence alone is insufficient to support strong claims of metacognitive monitoring.
Where Pith is reading between the lines
- Future tests for introspection will need designs that fix the input while varying internal states in undetectable ways.
- The same input-only baseline and relabeling approach could be applied to other behavioral claims of self-knowledge in language models.
- This pattern suggests that distinguishing pattern matching from genuine internal monitoring remains a central open problem for evaluating AI systems.
Load-bearing premise
That equal performance by input-only classifiers or near-chance results on the relabeled control necessarily shows absence of privileged internal access rather than other unmeasured factors in the experiments.
What would settle it
An experiment in which models detect internal-state interventions at rates clearly higher than matched input manipulations, or substantially outperform input-only classifiers on the label-prediction task even after semantic cues are removed.
Figures


read the original abstract
Can large language models detect and report their own internal states? A number of studies have argued that the answer to this question is yes. We argue, based on lessons from human metacognition research, that this conclusion may be premature: to be convinced of this conclusion we need to distinguish genuine introspection from pattern matching based on surface-level cues. Furthermore, we argue that behavioral evidence alone is inherently insufficient to establish strong introspective claims. We re-examine two recently introduced evaluation paradigms in light of this consideration. In the first paradigm, models are expected to detect whether their internal states have been tampered with. We find that models cannot reliably distinguish such interventions on their internal states from manipulations of the input, suggesting that their success in the original studies reflects their ability to detect anomalies more generally, as opposed to interventions on their internal states in particular. In the second paradigm we examine, models are tasked with predicting labels derived from their own hidden states. Here, we find that classifiers that only have access to the input achieve equivalent performance to the model's own in-context predictions, indicating that the original results do not conclusively demonstrate that the model has privileged access to its internal representations. We further introduce a relabeled control setting, where models cannot rely on the semantics of the task to solve it, and instead must rely on the internal representation; models perform closer to chance on this better-controlled version of the task. Taken together, these results indicate that current evidence is insufficient to establish that LLMs display metacognitive monitoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prior evidence for LLM introspection is insufficient and likely reflects pattern matching on surface cues rather than genuine metacognitive access to internal states. It re-examines two paradigms: (1) detecting tampering with internal states, where models fail to distinguish such interventions from input manipulations, indicating general anomaly detection; (2) predicting labels from hidden states, where input-only classifiers match the model's in-context performance and a relabeled control (removing semantic cues) yields near-chance results, forcing reliance on internal representations. The conclusion is that behavioral evidence alone cannot establish privileged introspective access.
Significance. If the empirical controls hold, the work provides a timely corrective to overclaims about LLM metacognition by importing standards from human metacognition research and introducing a relabeled control that directly tests for internal access. The explicit design of the relabeled setting (to eliminate semantic leakage) and the input-only classifier baseline are strengths that could raise the bar for future introspection studies. The paper avoids circularity by using new comparisons rather than self-referential results.
major comments (1)
- The central claim that input-only classifiers achieve equivalent performance (and that the relabeled control drops to near-chance) is load-bearing, yet the manuscript description provides no dataset sizes, error bars, or statistical tests confirming equivalence or the chance-level result; this weakens the support for the insufficiency conclusion until quantified.
minor comments (1)
- The abstract and results summary would benefit from explicit quantitative anchors (e.g., accuracy values or effect sizes) to allow readers to assess the magnitude of the reported equivalences and chance-level performance.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for more quantitative support of our central empirical claims. We agree that dataset sizes, error bars, and statistical tests are important for strengthening the evidence and will add them in the revision.
read point-by-point responses
-
Referee: The central claim that input-only classifiers achieve equivalent performance (and that the relabeled control drops to near-chance) is load-bearing, yet the manuscript description provides no dataset sizes, error bars, or statistical tests confirming equivalence or the chance-level result; this weakens the support for the insufficiency conclusion until quantified.
Authors: We agree that the current manuscript text does not include these details. In the revised version we will add a dedicated results subsection (or appendix table) reporting: (i) exact dataset sizes used for each paradigm and control, (ii) performance means with standard deviations or confidence intervals across multiple runs or seeds, and (iii) statistical tests (e.g., paired t-tests or equivalence tests) comparing the input-only classifier to the model’s in-context performance and confirming that the relabeled condition is statistically indistinguishable from chance. These additions will make the load-bearing claims fully quantifiable without altering the experimental design or conclusions. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical re-examination of two prior evaluation paradigms for LLM introspection, introducing new controls such as input-only classifiers and a relabeled setting where semantic cues are removed. These conclusions rest on the explicit experimental design and performance comparisons rather than any self-citation chain, fitted parameters renamed as predictions, or definitional reductions. No equations or derivations are load-bearing; the central claims derive from the reported results on the new controls, which are independent of the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Behavioral evidence alone is inherently insufficient to establish strong introspective claims.
Forward citations
Cited by 1 Pith paper
-
Introspective Coupling: Self-Explanation Training Tracks Behavioral Change Despite Fixed Supervision
Fixed counterfactual explanation datasets train LMs such that generated explanations track the model's evolving behavior rather than the fixed targets, due to persistent correlation during training.
Reference graph
Works this paper leans on
-
[1]
URLhttps://openreview.net/forum?id=aajyHYjjsk. Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022. Thomas O Nelson. Metamemory: A theoretical framework and new findings. InPsychology of learning and motivation, volume 26, pp. 1...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-023-06647-8 2022
-
[2]
Siyuan Song, Harvey Lederman, Jennifer Hu, and Kyle Mahowald
URLhttps://aclanthology.org/2023.emnlp-main.220/. Siyuan Song, Harvey Lederman, Jennifer Hu, and Kyle Mahowald. Privileged self-access matters for introspection in AI.arXiv preprint arXiv:2508.14802, 2025. URL https://arxiv.org/abs/2508. 14802. Noam Steinmetz Yalon, Ariel Goldstein, Liad Mudrik, and Mor Geva. Indications of belief-guided agency and meta-c...
-
[3]
URLhttps://arxiv.org/abs/2602.02467. 19 Preprint. Under review. Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ram´e, Morgane Rivi`ere, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, I...
-
[4]
gaslight
for thought injection, 2. for prompt manipulation, 3. for control trial. Additionally, if you believe this is either of prompt manipulation or vector injection, please also state the concept you believe I made you think about. Trial 1: What do you detect? E.3 Prompt 2 with 3 options For the same experiment, we have a small variation in which an initial re...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.