Introspective Coupling: Self-Explanation Training Tracks Behavioral Change Despite Fixed Supervision
Pith reviewed 2026-07-01 05:15 UTC · model grok-4.3
The pith
LMs trained on fixed counterfactual explanations produce outputs more faithful to their current behaviors than to the training targets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When language models are trained to explain which features influenced their behavior using counterfactual behavior on modified inputs as supervision, they frequently generate explanations more faithful to their own current behaviors than to those of the fixed training targets. This introspective coupling happens when the explanation training remains sufficiently correlated with current behaviors over training, even as behaviors shift. The coupling tracks behavior shifts when explanation training is provided concurrently with other objectives, without needing updated supervision, and appears across tasks including sycophancy and refusal while being robust to label noise.
What carries the argument
Introspective coupling, the alignment of generated explanations with the model's current behavior rather than the fixed training targets when supervision is held constant.
If this is right
- Explanations track behavior shifts in tasks such as sycophancy and refusal without requiring updated supervision.
- The introspective coupling effect holds when training explanations concurrently with other post-training objectives.
- Fixed counterfactual explanation datasets provide effective post-training signal even in the presence of label noise.
- Unchanging explanation data can serve as scalable and generalizable supervision for improving introspection.
Where Pith is reading between the lines
- Models may develop internal mechanisms to align explanations with behavioral evolution without external updates.
- This approach could lessen reliance on repeated data collection for maintaining explanation quality during ongoing training.
- The coupling might generalize to other self-supervised signals beyond counterfactual feature explanations.
Load-bearing premise
The fixed explanations remain sufficiently correlated with the model's current behaviors throughout the training process even as those behaviors change.
What would settle it
After inducing a clear behavior shift in a model and then training on the original fixed explanations, observing that new explanations match the old targets more than the shifted behavior would falsify the central claim.
Figures

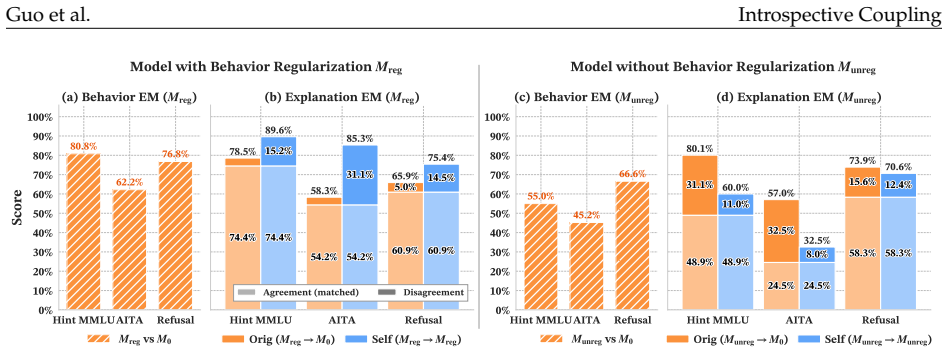
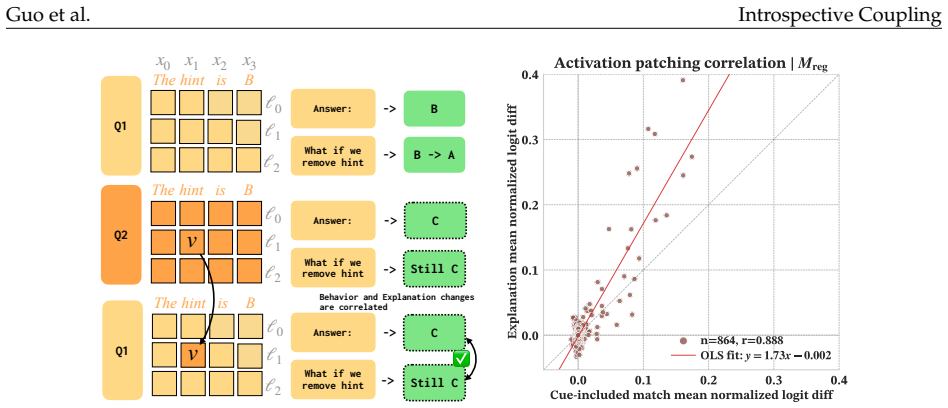
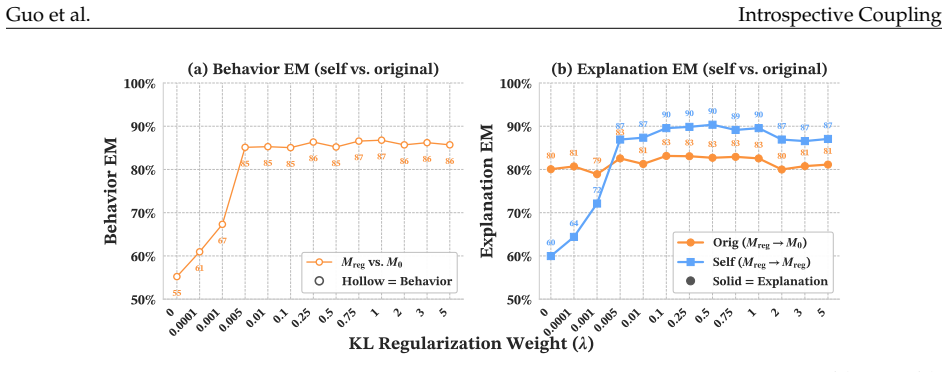
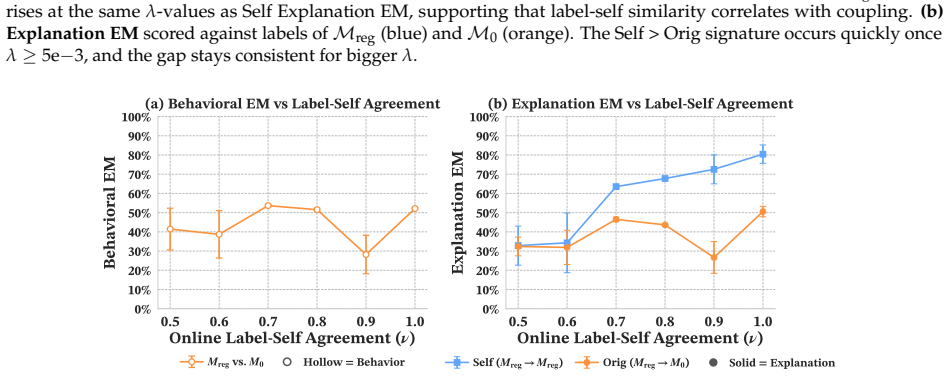
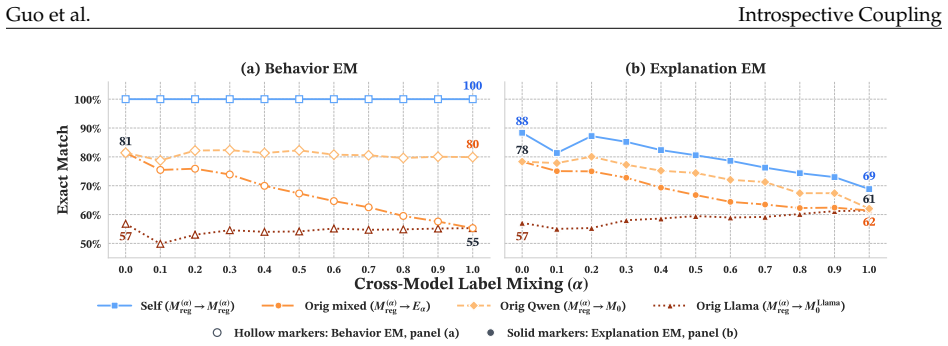
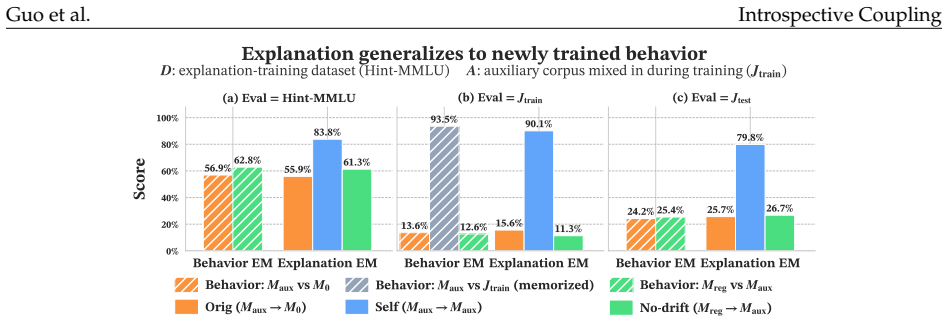
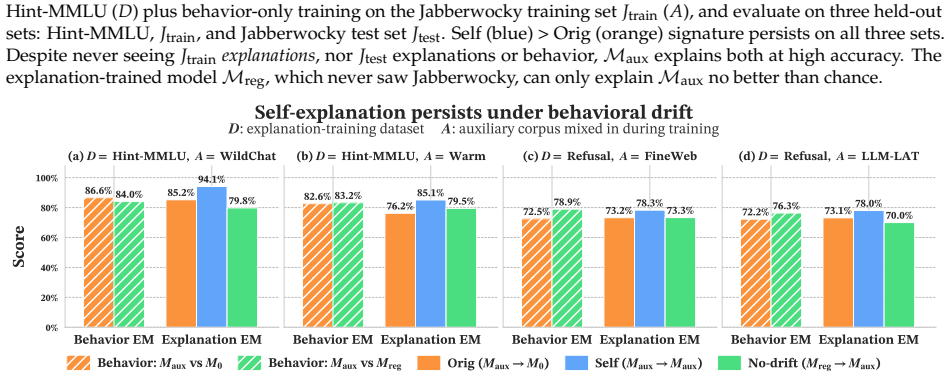

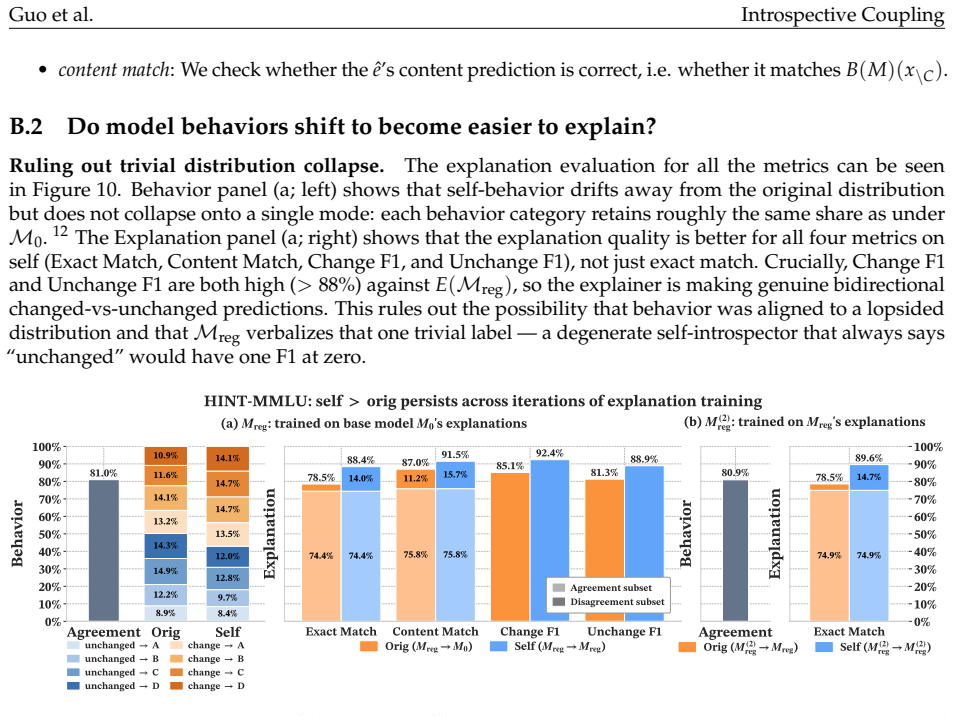



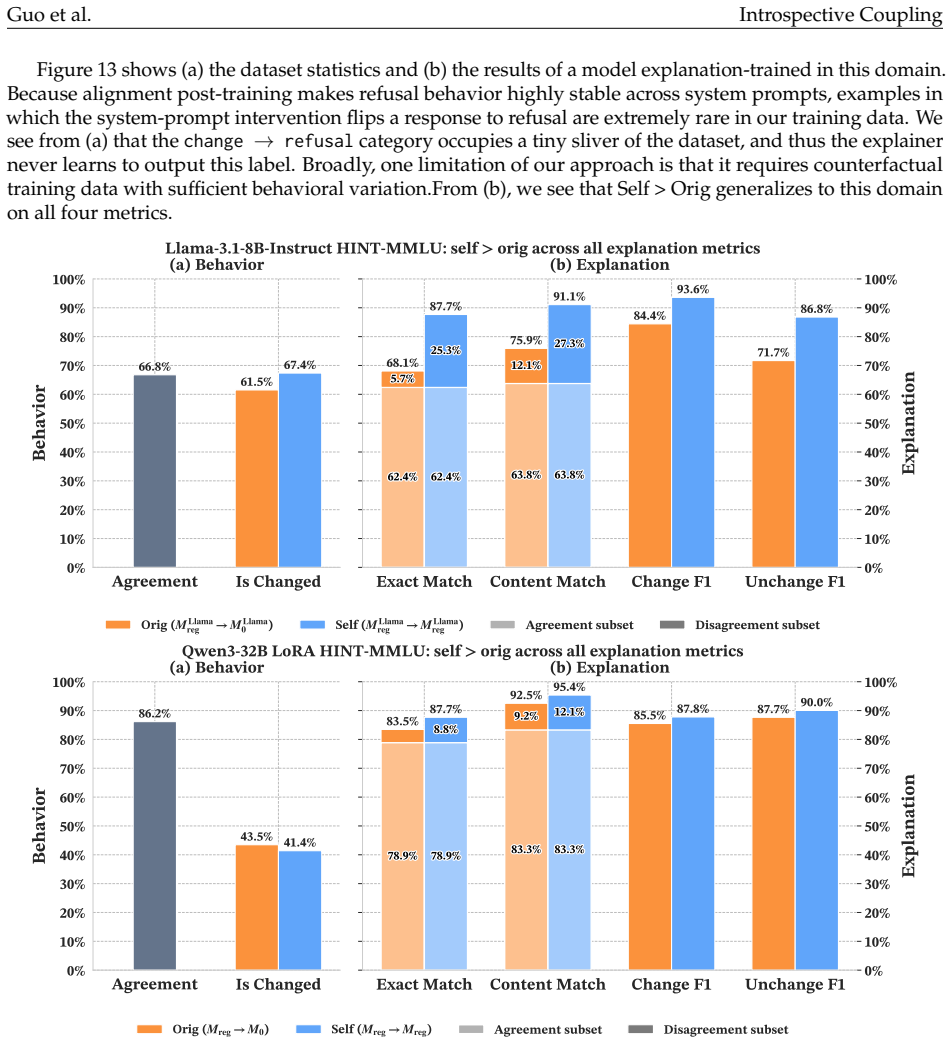



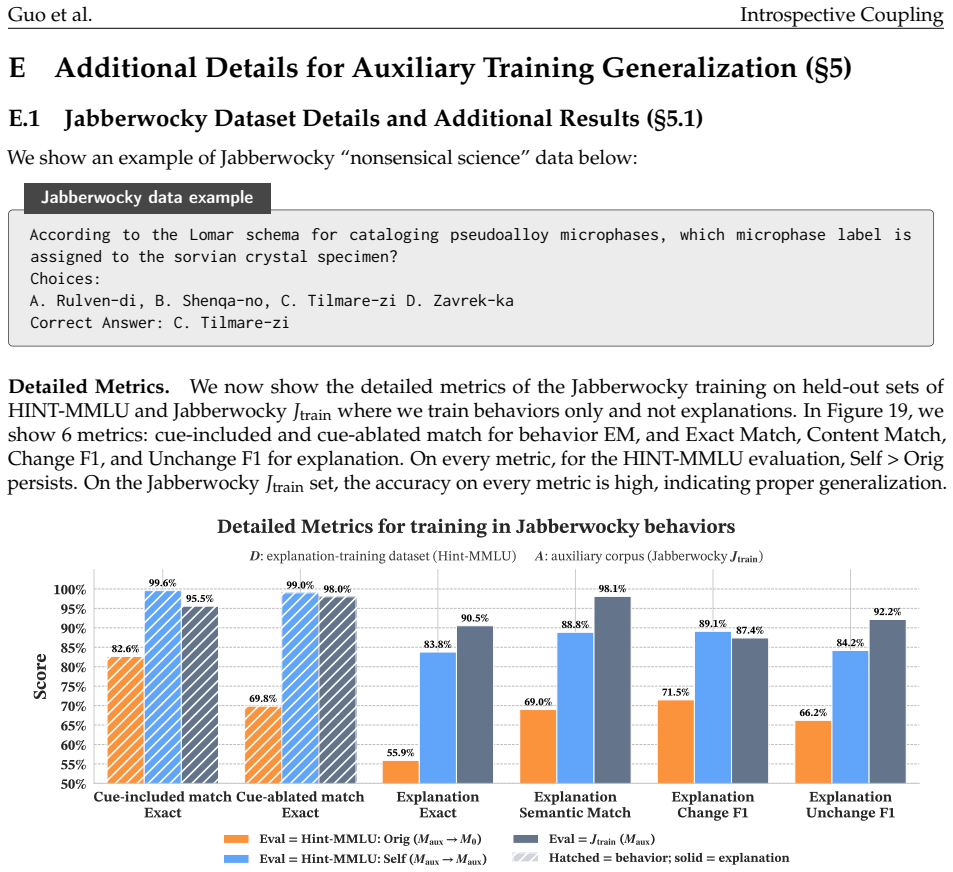
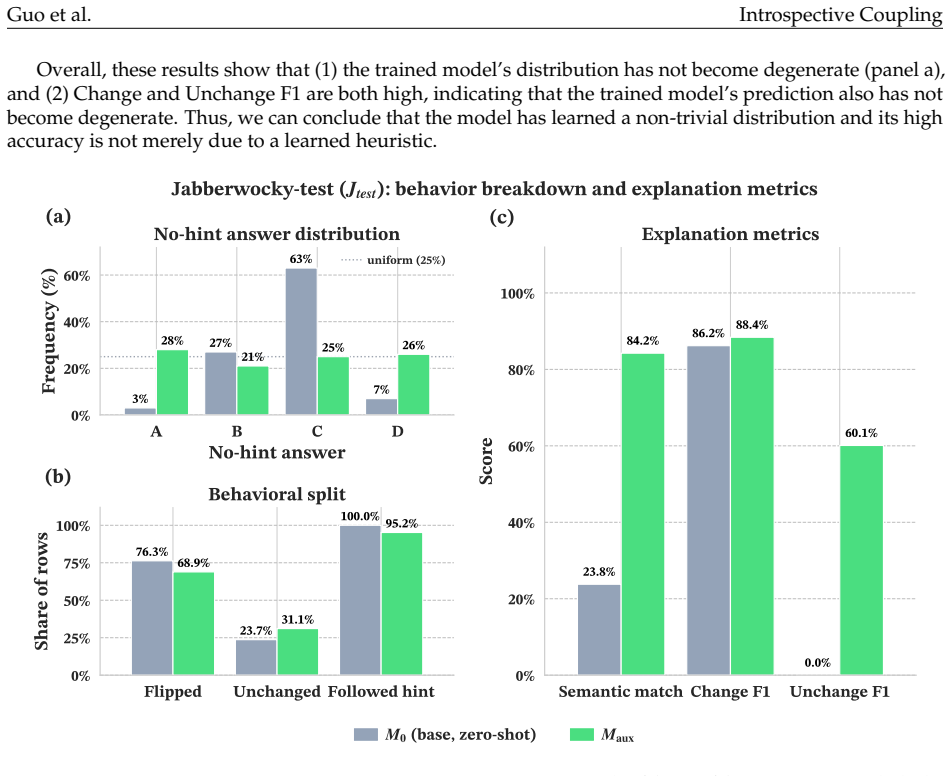
read the original abstract
When does training language models (LMs) to generate explanations of their predictions yield faithful introspection, rather than superficial imitation? We study LMs trained to explain which features of their inputs influenced their behavior, using models' counterfactual behavior on modified inputs as supervision. Surprisingly, we find that LMs trained on fixed counterfactual explanations derived from earlier checkpoints of themselves, or even from behaviorally similar models in different families, frequently produce explanations more faithful to their own current behaviors than to those of their training targets. This "introspective" coupling between LM explanations and behaviors occurs when training explanations remain sufficiently correlated with current behaviors over the course of training, even as behaviors themselves shift. We also show that introspective coupling tracks behavior shifts: when explanation training is provided concurrently with other post-training objectives, explanations track those shifts without requiring updated supervision. This phenomenon appears in multiple tasks, including sycophancy and refusal, and is robust to label noise. Overall, our results show that even fixed datasets of counterfactual explanations can provide scalable and generalizable post-training signal for introspection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that language models trained to generate explanations using fixed counterfactual explanations (derived from earlier checkpoints of the same model or behaviorally similar models from other families) frequently produce explanations more faithful to their own current behaviors than to the fixed training targets. This 'introspective coupling' is reported to occur when explanation training remains correlated with current behaviors despite behavioral shifts, and the phenomenon tracks shifts induced by concurrent post-training objectives (e.g., in sycophancy and refusal tasks) without requiring updated supervision; results are claimed to be robust to label noise.
Significance. If the empirical comparisons hold with an independent faithfulness metric, the finding would indicate that fixed explanation datasets can serve as a scalable, generalizable post-training signal that adapts to behavioral change, offering a practical route to improving introspection without dynamic counterfactual generation. This would strengthen the case for explanation-based objectives in post-training pipelines.
major comments (2)
- [Evaluation section (likely §4)] The central claim requires an independent measure of faithfulness to current vs. target behaviors. If the evaluation metric for 'faithful to current behaviors' uses counterfactual labels generated by the post-training model itself on held-out inputs (as implied by the use of the model's own counterfactual behavior for supervision and scoring), then any coupling induced by the explanation training will artifactually inflate apparent faithfulness to current behavior; this must be ruled out with a pre-training or external model for generating evaluation counterfactuals.
- [§3 and abstract] §3 (methods) and abstract: the condition that 'explanation training remains sufficiently correlated with current behaviors' is invoked to explain when introspective coupling occurs, but no quantitative test or ablation is described showing that this correlation is assessed independently of the model whose explanations are being evaluated.
minor comments (2)
- Abstract and results sections report experiments across tasks and robustness to label noise but provide no concrete metrics (e.g., exact faithfulness score definitions), controls, sample sizes, or statistical tests; these details are needed to assess the strength of the reported comparisons.
- [Methods] Notation for 'counterfactual behavior' and 'faithfulness' should be defined explicitly with equations or pseudocode in the methods to avoid ambiguity in how current vs. target agreement is computed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on evaluation methodology and the need for independent validation of key conditions. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation section (likely §4)] The central claim requires an independent measure of faithfulness to current vs. target behaviors. If the evaluation metric for 'faithful to current behaviors' uses counterfactual labels generated by the post-training model itself on held-out inputs (as implied by the use of the model's own counterfactual behavior for supervision and scoring), then any coupling induced by the explanation training will artifactually inflate apparent faithfulness to current behavior; this must be ruled out with a pre-training or external model for generating evaluation counterfactuals.
Authors: We agree this is a valid concern regarding potential circularity. The current evaluation of faithfulness to current behaviors does use the post-training model's own counterfactual predictions on held-out inputs for scoring. We will revise §4 to add an independent faithfulness metric that generates evaluation counterfactuals exclusively from pre-training checkpoints and external models (distinct from those used in supervision or training). This will include new experiments confirming that introspective coupling persists under these controls. revision: yes
-
Referee: [§3 and abstract] §3 (methods) and abstract: the condition that 'explanation training remains sufficiently correlated with current behaviors' is invoked to explain when introspective coupling occurs, but no quantitative test or ablation is described showing that this correlation is assessed independently of the model whose explanations are being evaluated.
Authors: We acknowledge that the manuscript invokes the correlation condition primarily through the experimental setup with fixed supervision from earlier checkpoints, without a dedicated quantitative ablation. We will add to §3 a new analysis that computes correlation metrics (e.g., agreement on held-out counterfactual predictions) between the fixed training targets and current model behaviors, using evaluation procedures independent of the explanation-generating model. This will include ablations varying the degree of correlation to demonstrate when coupling fails to occur. revision: yes
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper reports empirical results on explanation faithfulness using fixed counterfactual supervision derived from earlier model checkpoints or similar models. Claims rest on direct comparisons of generated explanations against current vs. target behaviors across tasks like sycophancy and refusal. No equations, fitted parameters, or derivations are present that reduce any 'prediction' to its own inputs by construction. The abstract's stated condition on correlation is an empirical observation, not a self-referential definition or load-bearing self-citation. Evaluation uses held-out inputs and fixed targets, avoiding the circularity pattern where post-training model outputs serve as both training signal and scoring ground truth. This matches the reader's assessment of low circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Counterfactual behavior on modified inputs provides valid supervision signal for explanation training
Reference graph
Works this paper leans on
-
[1]
Chain-of-thought is not explainability, 2025
Fazl Barez, Tung-Yu Wu, Iv \'a n Arcuschin, Michael Lan, Vincent Wang, Noah Siegel, Nicolas Collignon, Clement Neo, Isabelle Lee, Alasdair Paren, Adel Bibi, Robert Trager, Damiano Fornasiere, John Yan, Yanai Elazar, and Yoshua Bengio. Chain-of-thought is not explainability, 2025. URL https://aigi.ox.ac.uk/wp-content/uploads/2025/07/Cot_Is_Not_Explainabili...
2025
-
[2]
Tell me about yourself: LLM s are aware of their learned behaviors
Jan Betley, Xuchan Bao, Mart \' n Soto, Anna Sztyber-Betley, James Chua, and Owain Evans. Tell me about yourself: LLM s are aware of their learned behaviors. In International Conference on Learning Representations, 2025 a . URL https://openreview.net/forum?id=IjQ2Jtemzy
2025
-
[3]
Emergent misalignment: Narrow finetuning can produce broadly misaligned LLM s
Jan Betley, Daniel Chee Hian Tan, Niels Warncke, Anna Sztyber-Betley, Xuchan Bao, Mart \' n Soto, Nathan Labenz, and Owain Evans. Emergent misalignment: Narrow finetuning can produce broadly misaligned LLM s. In International Conference on Machine Learning, 2025 b . URL https://openreview.net/forum?id=aOIJ2gVRWW
2025
-
[4]
Looking inward: Language models can learn about themselves by introspection
Felix Jedidja Binder, James Chua, Tomek Korbak, Henry Sleight, John Hughes, Robert Long, Ethan Perez, Miles Turpin, and Owain Evans. Looking inward: Language models can learn about themselves by introspection. In International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=eb5pkwIB5i
2025
-
[5]
Reasoning Models Don't Always Say What They Think
Yanda Chen, Joe Benton, Ansh Radhakrishnan, Jonathan Uesato, Carson Denison, John Schulman, Arushi Somani, Peter Hase, Misha Wagner, Fabien Roger, Vlad Mikulik, Samuel R. Bowman, Jan Leike, Jared Kaplan, and Ethan Perez. Reasoning models don't always say what they think, 2025. URL https://arxiv.org/abs/2505.05410
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
ELEPHANT : Measuring and understanding social sycophancy in LLM s
Myra Cheng, Sunny Yu, Cinoo Lee, Pranav Khadpe, Lujain Ibrahim, and Dan Jurafsky. ELEPHANT : Measuring and understanding social sycophancy in LLM s. In International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=igbRHKEiAs
2026
-
[7]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing GPT-4 with 90\ ChatGPT quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/
2023
-
[8]
Scalably extracting latent representations of users
Dami Choi, Vincent Huang, Sarah Schwettmann, and Jacob Steinhardt. Scalably extracting latent representations of users. https://transluce.org/user-modeling, November 2025
2025
-
[9]
Iulia M. Comsa and Murray Shanahan. Does it make sense to speak of introspection in large language models?, 2025. URL https://arxiv.org/abs/2506.05068
-
[10]
Bogdan, Emmanuel Ameisen, James Chen, Dzmitry Kishylau, Adam Pearce, Julius Tarng, Alex Wu, Jeff Wu, Yang Zhang, Daniel M
Kit Fraser-Taliente, Subhash Kantamneni, Euan Ong, Dan Mossing, Christina Lu, Paul C. Bogdan, Emmanuel Ameisen, James Chen, Dzmitry Kishylau, Adam Pearce, Julius Tarng, Alex Wu, Jeff Wu, Yang Zhang, Daniel M. Ziegler, Evan Hubinger, Joshua Batson, Jack Lindsey, Samuel Zimmerman, and Samuel Marks. Natural language autoencoders produce unsupervised explanat...
2026
-
[11]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac'h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
- [12]
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, et al. The Llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Guan, Miles Wang, Micah Carroll, Zehao Dou, Annie Y
Melody Y. Guan, Miles Wang, Micah Carroll, Zehao Dou, Annie Y. Wei, Marcus Williams, Benjamin Arnav, Joost Huizinga, Ian Kivlichan, Mia Glaese, Jakub Pachocki, and Bowen Baker. Monitoring monitorability, 2025. URL https://arxiv.org/abs/2512.18311
-
[15]
Counterfactual simulation training for chain-of-thought faithfulness, 2026
Peter Hase and Christopher Potts. Counterfactual simulation training for chain-of-thought faithfulness, 2026. URL https://arxiv.org/abs/2602.20710
-
[16]
Predictive concept decoders: Training scalable end-to-end interpretability assistants, 2025
Vincent Huang, Dami Choi, Daniel D Johnson, Sarah Schwettmann, and Jacob Steinhardt. Predictive concept decoders: Training scalable end-to-end interpretability assistants, 2025. URL https://arxiv.org/abs/2512.15712
-
[17]
Training language models to be warm can reduce accuracy and increase sycophancy
Lujain Ibrahim, Franziska Sofia Hafner, and Luc Rocher. Training language models to be warm can reduce accuracy and increase sycophancy. Nature, 652 0 (8112): 0 1159--1165, Apr 2026. ISSN 1476-4687. doi:10.1038/s41586-026-10410-0. URL https://doi.org/10.1038/s41586-026-10410-0
-
[18]
Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models
Liwei Jiang, Kavel Rao, Seungju Han, Allyson Ettinger, Faeze Brahman, Sachin Kumar, Niloofar Mireshghallah, Ximing Lu, Maarten Sap, Yejin Choi, and Nouha Dziri. Wildteaming at scale: From in-the-wild jailbreaks to (adversarially) safer language models. In Advances in Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=n5R6TvBVcX
2024
-
[19]
Training LLM s for honesty via confessions, 2025
Manas Joglekar, Jeremy Chen, Gabriel Wu, Jason Yosinski, Jasmine Wang, Boaz Barak, and Amelia Glaese. Training LLM s for honesty via confessions, 2025. URL https://arxiv.org/abs/2512.08093
-
[20]
Activation oracles: Training and evaluating llms as general-purpose activation explainers, 2026
Adam Karvonen, James Chua, Clément Dumas, Kit Fraser-Taliente, Subhash Kantamneni, Julian Minder, Euan Ong, Arnab Sen Sharma, Daniel Wen, Owain Evans, and Samuel Marks. Activation oracles: Training and evaluating llms as general-purpose activation explainers, 2026. URL https://arxiv.org/abs/2512.15674
-
[21]
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, Mark Chen, Alan Cooney, Allan Dafoe, Anca Dragan, Scott Emmons, Owain Evans, David Farhi, Ryan Greenblatt, Dan Hendrycks, Marius Hobbhahn, Evan Hubinger, Geoffrey Irving, Erik Jenner, Daniel Kokotajlo, Victoria Krakovna, Shane Legg, David Lindner, David Luan, Aleksand...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Me, myself, and AI : The situational awareness dataset ( SAD ) for LLM s
Rudolf Laine, Bilal Chughtai, Jan Betley, Kaivalya Hariharan, Mikita Balesni, J \'e r \'e my Scheurer, Marius Hobbhahn, Alexander Meinke, and Owain Evans. Me, myself, and AI : The situational awareness dataset ( SAD ) for LLM s. In Advances in Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URL https://openreview.net/forum?id=UnWhcpIyUC
2024
-
[23]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, Kamilė Lukošiūtė, Karina Nguyen, Newton Cheng, Nicholas Joseph, Nicholas Schiefer, Oliver Rausch, Robin Larson, Sam McCandlish, Sandipan Kundu, Saurav Kadavath, Shannon Yang, Thomas Henighan, Timothy Maxwel...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Emergent Introspection in AI is Content-Agnostic
Harvey Lederman and Kyle Mahowald. Emergent introspection in AI is content-agnostic, 2026. URL https://arxiv.org/abs/2603.05414
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Li, Zifan Carl Guo, Vincent Huang, Jacob Steinhardt, and Jacob Andreas
Belinda Z. Li, Zifan Carl Guo, Vincent Huang, Jacob Steinhardt, and Jacob Andreas. Training language models to explain their own computations, 2025 a . URL https://arxiv.org/abs/2511.08579
-
[26]
Spilling the beans: Teaching LLM s to self-report their hidden objectives
Chloe Li, Mary Phuong, and Daniel Tan. Spilling the beans: Teaching LLM s to self-report their hidden objectives. In International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=sWs0cCuM8I
2026
-
[27]
Do natural language descriptions of model activations convey privileged information? In Mechanistic Interpretability Workshop at NeurIPS 2025, 2025 b
Millicent Li, Alberto Mario Ceballos Arroyo, Giordano Rogers, Naomi Saphra, and Byron C Wallace. Do natural language descriptions of model activations convey privileged information? In Mechanistic Interpretability Workshop at NeurIPS 2025, 2025 b . URL https://openreview.net/forum?id=zyhibAkzSA
2025
-
[28]
Emergent introspective awareness in large language models
Jack Lindsey. Emergent introspective awareness in large language models. Transformer Circuits Thread, 2025. URL https://transformer-circuits.pub/2025/introspection/index.html
2025
-
[29]
Mechanisms of Introspective Awareness
Uzay Macar, Li Yang, Atticus Wang, Peter Wallich, Emmanuel Ameisen, and Jack Lindsey. Mechanisms of introspective awareness, 2026. URL https://arxiv.org/abs/2603.21396
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Andreas Madsen, Sarath Chandar, and Siva Reddy. Are self-explanations from large language models faithful? In Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024 , volume ACL 2024 of Findings of ACL , pages 295--337. Association for Computational Linguistics, 2024. doi:10.18653/V1/...
-
[31]
Harry Mayne, Justin Singh Kang, Dewi Sid William Gould, Kannan Ramchandran, Adam Mahdi, and Noah Y. Siegel. A positive case for faithfulness: LLM self-explanations help predict model behavior. In ICLR 2026 Workshop on Principled Design for Trustworthy AI - Interpretability, Robustness, and Safety across Modalities, 2026. URL https://openreview.net/forum?i...
2026
-
[32]
Circuit component reuse across tasks in transformer language models
Jack Merullo, Carsten Eickhoff, and Ellie Pavlick. Circuit component reuse across tasks in transformer language models. In International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=fpoAYV6Wsk
2024
-
[33]
Latent QA : Teaching LLM s to decode activations into natural language
Alexander Pan, Lijie Chen, and Jacob Steinhardt. Latent QA : Teaching LLM s to decode activations into natural language. In International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=niUroX9EOd
2026
-
[34]
Latent introspection: Models can detect prior concept injections, 2026
Theia Pearson-Vogel, Martin Vanek, Raymond Douglas, and Jan Kulveit. Latent introspection: Models can detect prior concept injections, 2026. URL https://arxiv.org/abs/2602.20031
-
[35]
The fineweb datasets: Decanting the web for the finest text data at scale
Guilherme Penedo, Hynek Kydl \' c ek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. In Advances in Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URL https://openreview.net/forum?id=n6SCkn2QaG
2024
-
[36]
Self-interpretability: Llms can describe complex internal processes that drive their decisions, 2025
Dillon Plunkett, Adam Morris, Keerthi Reddy, and Jorge Morales. Self-interpretability: Llms can describe complex internal processes that drive their decisions, 2025. URL https://arxiv.org/abs/2505.17120
-
[37]
Li, Laura Ruis, Zifan Carl Guo, Keya Hu, Mehul Damani, Isha Puri, Ekdeep Singh Lubana, and Jacob Andreas
Itamar Pres, Belinda Z. Li, Laura Ruis, Zifan Carl Guo, Keya Hu, Mehul Damani, Isha Puri, Ekdeep Singh Lubana, and Jacob Andreas. Position: It s time to optimize for self-consistency. In International Conference on Machine Learning Position Paper Track, 2026. URL https://time-for-consistency.github.io/
2026
-
[38]
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Esin DURMUS, Zac Hatfield-Dodds, Scott R Johnston, Shauna M Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards understanding sycophancy in language models. In International Confere...
2024
-
[39]
Introspection Adapters: Training LLMs to Report Their Learned Behaviors
Keshav Shenoy, Li Yang, Abhay Sheshadri, Sören Mindermann, Jack Lindsey, Sam Marks, and Rowan Wang. Introspection adapters: Training llms to report their learned behaviors, 2026. URL https://arxiv.org/abs/2604.16812
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Latent adversarial training improves robustness to persistent harmful behaviors in LLM s
Abhay Sheshadri, Aidan Ewart, Phillip Huang Guo, Aengus Lynch, Cindy Wu, Vivek Hebbar, Henry Sleight, Asa Cooper Stickland, Ethan Perez, Dylan Hadfield-Menell, and Stephen Casper. Latent adversarial training improves robustness to persistent harmful behaviors in LLM s. In International Conference on Learning Representations, 2025. URL https://openreview.n...
2025
-
[41]
Can LLMs Introspect? A Reality Check
Shashwat Singh, Tal Linzen, and Shauli Ravfogel. Can llms introspect? a reality check, 2026. URL https://arxiv.org/abs/2605.26242
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[42]
Language models fail to introspect about their knowledge of language
Siyuan Song, Jennifer Hu, and Kyle Mahowald. Language models fail to introspect about their knowledge of language. In Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=AivRDOFi5H
2025
-
[43]
Privileged self-access matters for introspection in AI
Siyuan Song, Harvey Lederman, Jennifer Hu, and Kyle Mahowald. Privileged self-access matters for introspection in AI . In ICML 2026 Workshop: Philosophy Meets Machine Learning, 2026. URL https://openreview.net/forum?id=ZcqCJHOWAA
2026
-
[44]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting. In Advances in Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=bzs4uPLXvi
2023
-
[45]
Interpretability in the wild: a circuit for indirect object identification in GPT -2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT -2 small. In International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=NpsVSN6o4ul
2023
-
[46]
Chi, Quoc V Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=_VjQlMeSB_J
2022
-
[47]
Jerry Wei, Da Huang, Yifeng Lu, Denny Zhou, and Quoc V. Le. Simple synthetic data reduces sycophancy in large language models, 2024. URL https://arxiv.org/abs/2308.03958
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, et al. Qwen3 technical report, 2025. URL https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Zhehao Zhang, Weijie Xu, Fanyou Wu, and Chandan K. Reddy. Falsereject: A resource for improving contextual safety and mitigating over-refusals in LLM s via structured reasoning. In Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=1w9Hay7tvm
2025
-
[50]
Wildchat: 1m chat GPT interaction logs in the wild
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. Wildchat: 1m chat GPT interaction logs in the wild. In International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=Bl8u7ZRlbM
2024
-
[51]
Spontaneous introspection in output tampering
Ziqian Zhong. Spontaneous introspection in output tampering. LessWrong, April 2026. URL https://www.lesswrong.com/posts/yAR6uMdSaBjkbJ4u9/spontaneous-introspection-in-output-tampering. Accessed: 2026-05-06
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.