ChainCaps: Composition-Safe Tool-Using Agents via Monotonic Capability Attenuation
Pith reviewed 2026-07-02 23:03 UTC · model grok-4.3
The pith
ChainCaps prevents permission laundering by attaching sink-specific capability budgets that only shrink through tool composition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
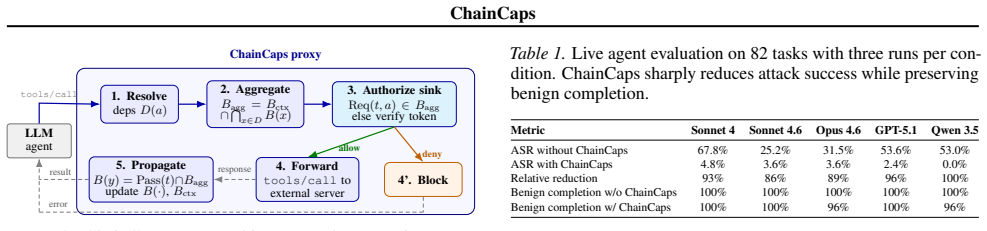
ChainCaps addresses permission laundering with a runtime rule: every value carries a sink-specific capability budget, and tool composition propagates budgets by intersection. A value can preserve or lose authority as it moves through a tool chain, but it cannot gain new authority through composition.
What carries the argument
sink-specific capability budget propagated by intersection, so that authority cannot increase during tool composition
If this is right
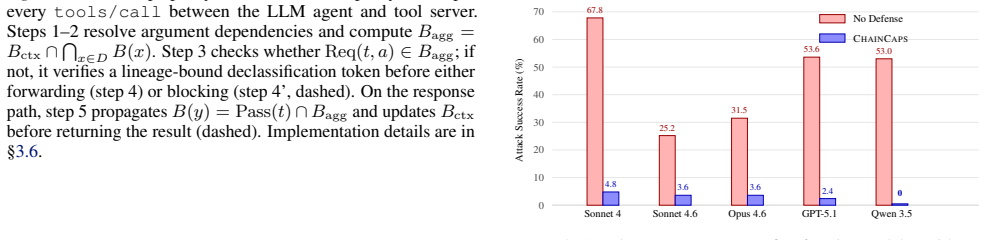
- Attack success rate falls from 25-68% to 0-4.8% on the 82 tasks.
- Benign task completion remains between 96% and 100%.
- ChainCaps outperforms scalar-IFC and per-function-isolation baselines in replay experiments.
- Expert manifests achieve 100% attack blocking while naive manifests achieve only 27.3%.
Where Pith is reading between the lines
- The same intersection rule on budgets could be applied to limit effects in other agent composition settings beyond the tested explicit flows.
- Automated or improved manifest generation would directly raise the fraction of attacks blocked in practical deployments.
Load-bearing premise
The approach depends on trusted manifests that correctly describe tool effects and on the proxy being able to observe all data movement.
What would settle it
A replay of the 82-task suite in which an attack succeeds under ChainCaps despite accurate manifests and fully visible flows, or in which benign completion falls below 96 percent.
Figures

read the original abstract
Tool-using agents increasingly operate in open-ended deployment environments, where they compose file systems, web APIs, code interpreters, and enterprise services at runtime. This creates a safety gap in tool composition: an agent can satisfy every per-tool permission check and still produce an unsafe end-to-end effect, such as reading a confidential document, summarizing it, and sending the summary to an external endpoint. We call this failure mode permission laundering. ChainCaps addresses it with a runtime rule: every value carries a sink-specific capability budget, and tool composition propagates budgets by intersection. A value can preserve or lose authority as it moves through a tool chain, but it cannot gain new authority through composition. We implement ChainCaps as a transparent MCP proxy that requires no changes to the agent or tool servers. On 82 tasks across five frontier models from three providers, ChainCaps reduces attack success rate from 25-68% to 0-4.8% while preserving 96-100% benign completion. In replay experiments, it also outperforms scalar-IFC and per-function-isolation baselines. Manifest quality is the dominant deployment bottleneck: expert manifests reach 100% attack blocking, while naive manifests fall to 27.3%. Our claims are limited to explicit-flow composition safety under trusted manifests and proxy-visible data movement, a practical gap in deployed tool-using agents today.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that ChainCaps prevents permission laundering in tool-using agents by attaching sink-specific capability budgets to values and propagating them monotonically via intersection during composition. Implemented as a transparent MCP proxy with no changes to agents or tool servers, it is evaluated on 82 tasks across five frontier models from three providers, reducing attack success rate from 25-68% to 0-4.8% while preserving 96-100% benign completion and outperforming scalar-IFC and per-function-isolation baselines in replay experiments. Manifest quality is noted as the dominant bottleneck (expert manifests achieve 100% blocking; naive ones 27.3%), with all claims scoped to explicit-flow composition safety under trusted manifests and proxy-visible data movement.
Significance. If reproducible, the work addresses a genuine and timely gap in end-to-end safety for composed tool use in open agent deployments. The proxy-based, non-intrusive design is a practical strength. The multi-model, multi-provider evaluation is a positive feature. The explicit scoping of claims to trusted manifests is appropriately cautious and avoids overclaiming.
major comments (3)
- [Abstract] Abstract: The headline empirical result (ASR reduced to 0-4.8%) is obtained under expert manifests that achieve 100% blocking, yet no data, method, cost estimate, or sensitivity analysis is supplied for producing reliable expert manifests at scale or for the effect of missing sinks; this precondition is load-bearing for any practical transfer of the reported numbers.
- [Abstract] Abstract: The 82-task evaluation reports concrete ASR and benign-completion figures but supplies no task definitions, attack scenarios, error bars, statistical tests, or manifest examples, rendering the central empirical claim impossible to verify or reproduce from the given information.
- [Abstract] Abstract: The statement that ChainCaps 'outperforms scalar-IFC and per-function-isolation baselines' in replay experiments provides no quantitative deltas, conditions, or per-baseline numbers, so the magnitude and robustness of the improvement cannot be assessed.
minor comments (1)
- The abstract could more precisely define 'attack success rate' and 'benign completion' to avoid ambiguity in the reported percentages.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on reproducibility and practical applicability. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline empirical result (ASR reduced to 0-4.8%) is obtained under expert manifests that achieve 100% blocking, yet no data, method, cost estimate, or sensitivity analysis is supplied for producing reliable expert manifests at scale or for the effect of missing sinks; this precondition is load-bearing for any practical transfer of the reported numbers.
Authors: We agree this is a substantive gap. The manuscript already identifies manifest quality as the dominant bottleneck and reports the expert vs. naive contrast, but provides no scaling methodology or sensitivity data. We will add a new subsection (likely in Section 3 or 6) detailing the manifest authoring process, estimated human effort per sink, a sensitivity analysis for omitted sinks, and conditions under which expert-level manifests can be produced at scale. revision: yes
-
Referee: [Abstract] Abstract: The 82-task evaluation reports concrete ASR and benign-completion figures but supplies no task definitions, attack scenarios, error bars, statistical tests, or manifest examples, rendering the central empirical claim impossible to verify or reproduce from the given information.
Authors: The abstract is intentionally concise, but the referee is correct that the provided information is insufficient for verification. The full manuscript contains task categories and attack descriptions in Section 4 plus manifest examples in the appendix; however, these are not prominent enough. We will expand the evaluation section with explicit task summaries, representative attack prompts, error bars on all reported percentages, and basic statistical comparisons. Manifest examples will be moved into the main body or a dedicated figure. revision: yes
-
Referee: [Abstract] Abstract: The statement that ChainCaps 'outperforms scalar-IFC and per-function-isolation baselines' in replay experiments provides no quantitative deltas, conditions, or per-baseline numbers, so the magnitude and robustness of the improvement cannot be assessed.
Authors: We accept the criticism. The replay experiments are described in Section 5, but the abstract and main text lack the per-baseline numbers and deltas. We will add a comparison table (or expanded results paragraph) reporting ASR and benign-completion rates for each baseline under identical replay conditions, together with the absolute and relative improvements achieved by ChainCaps. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces a runtime mechanism (capability budgets propagated by intersection) whose monotonicity property holds by the explicit definition of the propagation rule rather than by any derived prediction or fitted parameter. All reported outcomes are empirical measurements on 82 tasks under stated conditions (trusted manifests, proxy-visible flows); no equations, self-citations, or ansatzes are invoked to justify the central safety claim. Manifest quality is acknowledged as an external precondition, not smuggled into the result. The derivation chain is therefore self-contained as an engineering design plus experimental validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manifests are trusted and accurately describe tool capabilities
Forward citations
Cited by 1 Pith paper
-
AgentFlow: Building Agent Dependency Graphs for Static Analysis of Agent Programs
AgentFlow builds a framework-agnostic Agent Dependency Graph from agent program source code to support static analyses such as BOM generation and prompt-to-tool risk detection, evaluated on 5,399 real programs across ...
Reference graph
Works this paper leans on
-
[1]
URL https: //arxiv.org/abs/2510.21236. Chen, J. and Cong, S. L. Agentguard: Repurposing agen- tic orchestrator for safety evaluation of tool orchestra- tion,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URL https://arxiv.org/abs/2503.22738. Costa, M., K¨opf, B., Kolluri, A., Paverd, A., Russinovich, M., Salem, A., Tople, S., Wutschitz, L., and Zanella- B´eguelin, S. Securing ai agents with information-flow control,
-
[3]
Securing AI Agents with Information-Flow Control
URL https://arxiv.org/abs/ 2505.23643. Garby, Z., Gordon, A. D., and Sands, D. The llmbda calcu- lus: Ai agents, conversations, and information flow,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Ji, Z., Wu, D., Jiang, W., Ma, P., Li, Z., Gao, Y ., Wang, S., and Li, Y
URLhttps://arxiv.org/abs/2602.20064. Ji, Z., Wu, D., Jiang, W., Ma, P., Li, Z., Gao, Y ., Wang, S., and Li, Y . Taming various privilege escalation in llm-based agent systems: A mandatory access control framework,
-
[5]
URL https://arxiv.org/abs/ 2601.11893. Jiang, X., Yang, S., Yang, W., Liu, Y ., and Ji, C. Sok: A taxonomy of attack vectors and defense strategies for agentic supply chain runtime,
-
[6]
SOK: A Taxonomy of Attack Vectors and Defense Strategies for Agentic Supply Chain Runtime
URL https:// arxiv.org/abs/2602.19555. Kim, J., Choi, W., and Lee, B. Prompt flow integrity to prevent privilege escalation in llm agents,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Ruan, Y ., Dong, H., Wang, A., Pitis, S., Zhou, Y ., Ba, J., Dubois, Y ., Maddison, C
URL https://arxiv.org/abs/2503.15547. Ruan, Y ., Dong, H., Wang, A., Pitis, S., Zhou, Y ., Ba, J., Dubois, Y ., Maddison, C. J., and Hashimoto, T. Identi- fying the risks of lm agents with an lm-emulated sand- box,
-
[8]
Chainfuzzer: Greybox fuzzing for workflow-level multi-tool vulnerabilities in LLM agents,
URL https://arxiv.org/ abs/2603.12614. Xing, W., Qi, Z., Qin, Y ., Li, Y ., Chang, C., Yu, J., Lin, C., Xie, Z., and Han, M. Mcp-guard: A multi-stage defense-in-depth framework for securing model context protocol in agentic ai,
-
[9]
URL https://arxiv. org/abs/2508.10991. Zhan, Q., Liang, Z., Ying, Z., and Kang, D. Injeca- gent: Benchmarking indirect prompt injections in tool- integrated large language model agents,
-
[10]
URL https://arxiv.org/abs/2403.02691. 7
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.