R³: Composed Video Retrieval via Reasoning-Guided Recalling and Re-ranking
Pith reviewed 2026-06-28 17:40 UTC · model grok-4.3
The pith
Generating a reasoning trace from an edit instruction turns a source video into a retrieval program that captures state changes and temporal consistency in zero-shot composed video retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
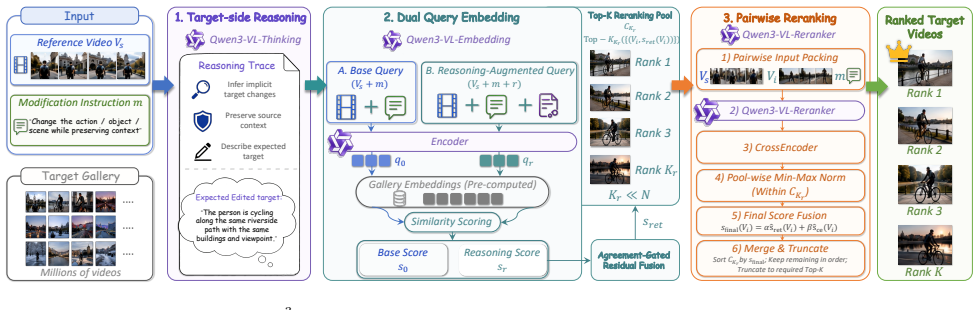
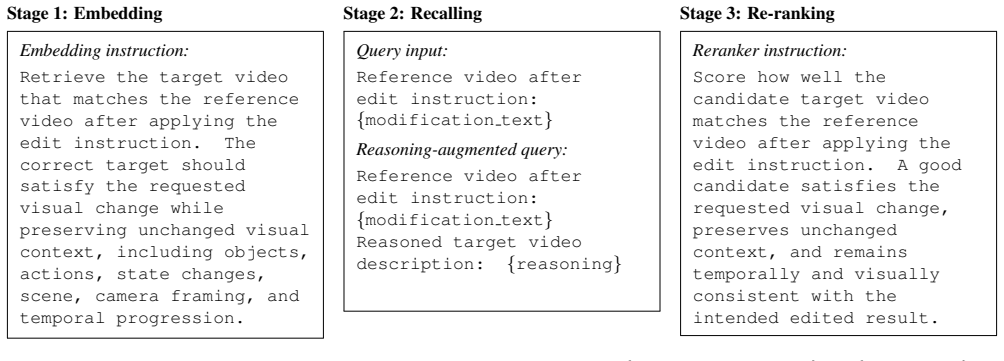
R^3 turns the source-edit query into a reasoning-grounded retrieval program: an off-the-shelf model first emits a reasoning trace describing the edited video; the trace is encoded with the source video to produce a reasoning-augmented query whose retrieval score is fused with the base composed-query score through an agreement-gated residual rule; a pairwise multimodal re-ranker then verifies the recalled candidates by direct source-candidate comparison, yielding improved zero-shot performance on the CoVR-R challenge.
What carries the argument
Reasoning trace generation followed by agreement-gated residual score fusion and candidate re-ranking.
If this is right
- The fused score improves recall of videos that exhibit the precise state or action changes implied by the edit.
- Re-ranking becomes computationally feasible because it is applied only to the shortlist produced by the reasoning-augmented query.
- Object preservation and temporal consistency are enforced at verification time rather than relying solely on the initial embedding space.
- The entire pipeline remains zero-shot, requiring no additional training data or parameter updates for new edit instructions.
Where Pith is reading between the lines
- Replacing the reasoning model with a stronger chain-of-thought reasoner would be expected to widen the performance margin without any change to the fusion or re-ranking stages.
- The same trace-plus-residual pattern could be tested on composed image or audio retrieval tasks that also require modeling post-edit consequences.
- If the agreement gate frequently suppresses the reasoning trace on easy edits, the method effectively falls back to the base embedder, suggesting a natural curriculum for future hybrid systems.
Load-bearing premise
An off-the-shelf model can generate a reasoning trace that accurately captures target-side consequences such as state changes, action replacement, object preservation, and temporal consistency without any fine-tuning or domain-specific adaptation.
What would settle it
If the generated reasoning traces are replaced by random or mismatched descriptions on the same gallery, the reported retrieval gains over the base composed-query embedding should disappear.
Figures
read the original abstract
The CoVR-R challenge evaluates composed video retrieval, where a system must retrieve a target video from a large gallery given a reference video and a textual edit instruction. This setting is not a standard video-text retrieval problem: the query is defined by both the visual evidence in the source video and the transformation implied by the edit. A strong embedding model can provide scalable candidate recall, but it may under-express target-side consequences such as state changes, action replacement, object preservation, or temporal consistency. A pairwise multimodal reranker can verify such details more directly, but exhaustive reranking over the full gallery is computationally infeasible. We present $\mathbb{R}^3$, a zero-shot composed video retrieval pipeline built around Reasoning-guided Recalling and Reranking. The core idea is to turn the source-edit query into a reasoning-grounded retrieval program rather than treating the edit text as a short caption. First, the model generates a reasoning trace that describes the expected target video after applying the edit. Then the trace is encoded together with the source video as a reasoning-augmented query, and its retrieval score is fused with the base composed query through an agreement-gated residual rule. At last, a re-ranker verifies the recalled candidates with direct source-candidate comparison. Experiments have demonstrated the effectiveness of our method in addressing this challenge. Codes are available on https://github.com/Lee-zixu/R-3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces R³, a zero-shot composed video retrieval pipeline for the CoVR-R task. Given a reference video and textual edit instruction, it generates a reasoning trace describing expected target-video consequences, encodes the trace together with the source as an augmented query, fuses its retrieval score with the base composed-query score via an agreement-gated residual rule, and finally applies a pairwise re-ranker to the recalled candidates.
Significance. If the off-the-shelf reasoning traces prove reliable, the pipeline offers a practical, training-free route to compensate for embedding-model shortcomings on state changes, action replacement, object preservation and temporal consistency, while avoiding exhaustive gallery re-ranking. Code release supports reproducibility.
major comments (3)
- [Abstract] Abstract: the statement that 'experiments have demonstrated the effectiveness' supplies no metrics, baselines, ablation results or dataset details, so the data-to-claim link for the zero-shot CoVR-R claim cannot be evaluated.
- [Reasoning-guided Recalling] Reasoning-guided Recalling section: the central claim requires that an off-the-shelf model produces reasoning traces that accurately capture the four target-side consequence types (state changes, action replacement, object preservation, temporal consistency); no trace examples, fidelity metrics or ablation isolating trace quality are supplied, leaving the agreement-gated fusion step vulnerable to noise.
- [Method] Method description: the agreement-gated residual fusion rule is presented without an explicit equation, definition of the gating threshold, or analysis of its behavior under low trace-base agreement, making it impossible to determine whether the rule is parameter-free or merely reduces to the base score by construction.
minor comments (2)
- Notation: the title uses R^3 while the abstract uses \mathbb{R}^3; a single consistent symbol would improve readability.
- The GitHub link is given but no commit hash or environment file is referenced, which would aid exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to improve clarity, completeness, and evidential support.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'experiments have demonstrated the effectiveness' supplies no metrics, baselines, ablation results or dataset details, so the data-to-claim link for the zero-shot CoVR-R claim cannot be evaluated.
Authors: We agree that the current abstract is too high-level and does not provide sufficient quantitative grounding. In the revised version we will expand the abstract to report key retrieval metrics (e.g., Recall@K on CoVR-R), comparisons against the base embedding model and other zero-shot baselines, and brief mention of the dataset and evaluation protocol. revision: yes
-
Referee: [Reasoning-guided Recalling] Reasoning-guided Recalling section: the central claim requires that an off-the-shelf model produces reasoning traces that accurately capture the four target-side consequence types (state changes, action replacement, object preservation, temporal consistency); no trace examples, fidelity metrics or ablation isolating trace quality are supplied, leaving the agreement-gated fusion step vulnerable to noise.
Authors: We acknowledge the absence of concrete trace examples and direct fidelity analysis. We will add representative reasoning traces in a new figure or table, report an indirect fidelity proxy via retrieval gain when traces are included versus excluded, and include an ablation that isolates trace quality by comparing retrieval performance with and without the reasoning-augmented query. Because the pipeline is strictly zero-shot, we cannot claim oracle-level trace fidelity, but the added material will allow readers to assess the practical reliability of the off-the-shelf traces. revision: yes
-
Referee: [Method] Method description: the agreement-gated residual fusion rule is presented without an explicit equation, definition of the gating threshold, or analysis of its behavior under low trace-base agreement, making it impossible to determine whether the rule is parameter-free or merely reduces to the base score by construction.
Authors: We agree that the fusion rule requires a formal definition. In the revised manuscript we will insert an explicit equation for the agreement-gated residual, specify how the gating threshold is determined (or confirm it is fixed and parameter-free), and add a short analysis subsection examining score behavior when trace-base agreement is low, including the limiting case where the residual term is suppressed. revision: yes
Circularity Check
No circularity: engineering pipeline with no derivations or self-referential reductions
full rationale
The paper describes a zero-shot retrieval pipeline (reasoning trace generation from an off-the-shelf model, agreement-gated residual fusion of scores, and re-ranking) without any equations, fitted parameters, predictions of derived quantities, or load-bearing self-citations. No step reduces by construction to its own inputs; the central claim is an empirical engineering composition whose validity rests on external model behavior and experimental results rather than definitional equivalence or imported uniqueness theorems. This matches the default case of a self-contained applied method.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
COMBINER: Composed Image Retrieval Guided by Attribute-based Neighbor Relations
COMBINER proposes a new architecture for composed image retrieval using adaptive semantic disentanglement, unified prototype-based composition, and dual attribute-based relation modeling to address visually similar bu...
-
RankVR: Low-Rank Structure Perception and Value Recalibration for Robust Composed Image Retrieval
RankVR introduces GSCP and ASVC modules to improve CIR robustness by decoupling clean samples via low-rank structure and dynamically scoring triplet value in noisy datasets.
-
IMAGINE: Adaptive Schema-Imagery Enhanced Composition for Composed Video Retrieval
IMAGINE uses adaptive schema-imagery via dynamic multimodal prototypes to incorporate implicit semantics into composed video retrieval, claiming SOTA results on CVR and CIR benchmarks.
Reference graph
Works this paper leans on
-
[1]
Hud: Hierarchical uncertainty-aware disambiguation network for composed video retrieval
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Haokun Wen, and Weili Guan. Hud: Hierarchical uncertainty-aware disambiguation network for composed video retrieval. In ACM MM, page 6143–6152, 2025. 1
2025
-
[2]
Covr: Learning composed video retrieval from web video captions
Lucas Ventura, Antoine Yang, Cordelia Schmid, and G ¨ul Varol. Covr: Learning composed video retrieval from web video captions. InAAAI, pages 5270–5279, 2024
2024
-
[3]
Refine: Composed video retrieval via shared and differential semantics enhancement
Yupeng Hu, Zixu Li, Zhiwei Chen, Qinlei Huang, Zhiheng Fu, Mingzhu Xu, and Liqiang Nie. Refine: Composed video retrieval via shared and differential semantics enhancement. ACM ToMM, 2026
2026
-
[4]
Covr-2: Automatic data construction for composed video retrieval.IEEE TPAMI, 2024
Lucas Ventura, Antoine Yang, Cordelia Schmid, and G ¨ul Varol. Covr-2: Automatic data construction for composed video retrieval.IEEE TPAMI, 2024
2024
-
[5]
Retrack: Evidence-driven dual-stream directional anchor calibration network for com- posed video retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Qinlei Huang, Guozhi Qiu, Zhiheng Fu, and Meng Liu. Retrack: Evidence-driven dual-stream directional anchor calibration network for com- posed video retrieval. InAAAI, pages 23373–23381, 2026. 1
2026
-
[6]
ConeSep: Cone-based Robust Noise-Unlearning Compositional Network for Composed Image Retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Mingyu Zhang, Zhiheng Fu, and Liqiang Nie. Conesep: Cone-based robust noise- unlearning compositional network for composed image re- trieval.arXiv preprint arXiv:2604.20358, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Air-Know: Arbiter-Calibrated Knowledge-Internalizing Robust Network for Composed Image Retrieval
Zhiheng Fu, Yupeng Hu, Qianyun Yang, Shiqi Zhang, Zhi- wei Chen, and Zixu Li. Air-know: Arbiter-calibrated knowledge-internalizing robust network for composed image retrieval.arXiv preprint arXiv:2604.19386, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Sentence-level prompts benefit composed image retrieval
Xinxing Xu, Yong Liu, Salman Khan, Fahad Khan, Wang- meng Zuo, Rick Siow Mong Goh, Chun-Mei Feng, et al. Sentence-level prompts benefit composed image retrieval. In ICLR, 2024
2024
-
[9]
Encoder: Entity mining and modifica- tion relation binding for composed image retrieval
Zixu Li, Zhiwei Chen, Haokun Wen, Zhiheng Fu, Yupeng Hu, and Weili Guan. Encoder: Entity mining and modifica- tion relation binding for composed image retrieval. InAAAI, pages 5101–5109, 2025
2025
-
[10]
Offset: Segmentation-based focus shift revision for composed image retrieval
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Xuemeng Song, and Liqiang Nie. Offset: Segmentation-based focus shift revision for composed image retrieval. InACM MM, page 6113–6122, 2025
2025
-
[11]
Pair: Complementarity-guided disentanglement for composed im- age retrieval
Zhiheng Fu, Zixu Li, Zhiwei Chen, Chunxiao Wang, Xuemeng Song, Yupeng Hu, and Liqiang Nie. Pair: Complementarity-guided disentanglement for composed im- age retrieval. InICASSP, pages 1–5. IEEE, 2025
2025
-
[12]
Median: Adaptive intermediate-grained aggregation network for composed im- age retrieval
Qinlei Huang, Zhiwei Chen, Zixu Li, Chunxiao Wang, Xue- meng Song, Yupeng Hu, and Liqiang Nie. Median: Adaptive intermediate-grained aggregation network for composed im- age retrieval. InICASSP, pages 1–5. IEEE, 2025. 1
2025
-
[13]
Tempme: Video tempo- ral token merging for efficient text-video retrieval
Leqi Shen, Tianxiang Hao, et al. Tempme: Video tempo- ral token merging for efficient text-video retrieval. InICLR, pages 60839–60860, 2025. 1
2025
-
[14]
Zixu Li, Yupeng Hu, Zhiwei Chen, Zhiheng Fu, Xiaowei Zhu, Weili Guan, and Liqiang Nie. Tempret: Tempo- ral enhancement and two-stage reranking for cvpr 2026 epic-kitchens-100 multi-instance retrieval challenge.arXiv preprint arXiv:2605.24470, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, et al. Qwen-vl: A versatile vision- language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Erase: Bypassing collaborative detection of ai counterfeit via com- prehensive artifacts elimination.IEEE TDSC, pages 1–18, 2026
Qianyun Yang, Peizhuo Lv, Yingjiu Li, Shengzhi Zhang, Yuxuan Chen, Zhiwei Chen, Zixu Li, and Yupeng Hu. Erase: Bypassing collaborative detection of ai counterfeit via com- prehensive artifacts elimination.IEEE TDSC, pages 1–18, 2026
2026
-
[17]
EgoAdapt: A Multi-Scene Egocentric Adaptation Method for CVPR 2026 HD-EPIC VQA Challenge
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Guozhi Qiu, Weili Guan, and Liqiang Nie. Egoadapt: A multi-scene ego- centric adaptation method for cvpr 2026 hd-epic vqa chal- lenge.arXiv preprint arXiv:2605.24500, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Zhiheng Fu, Zixu Li, Zhiwei Chen, Fangxu Liu, Yupeng Hu, Weili Guan, and Liqiang Nie. Egoaction: Egocentric action composition with reliability-aware temporal fusion for the epic-kitchens action detection challenge at cvpr 2026.arXiv preprint arXiv:2605.24496, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Shuai Bai, Keqin Chen, Xuejing Liu, et al. Qwen2.5-vl tech- nical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
OmniEgo-R$^2$: A Routed Reasoning Framework for the 1st Cross-Domain EgoCross Challenge at CVPR 2026
Zixu Li, Zhiwei Chen, Zhiheng Fu, Wenbo Wang, Yupeng Hu, Weili Guan, and Liqiang Nie. Omniego-r 2: A routed reasoning framework for the 1st cross-domain egocross chal- lenge at cvpr 2026.arXiv preprint arXiv:2605.24481, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Uatvr: Uncertainty-adaptive text-video retrieval
Bo Fang, Wenhao Wu, et al. Uatvr: Uncertainty-adaptive text-video retrieval. InCVPR, pages 13723–13733, 2023. 1
2023
-
[22]
Stable: Efficient hybrid nearest neighbor search via magnitude-uniformity and cardinality- robustness.IEEE TKDE, 2026
Qianyun Yang, Zhiwei Chen, Yupeng Hu, Zixu Li, Zhi- heng Fu, and Liqiang Nie. Stable: Efficient hybrid nearest neighbor search via magnitude-uniformity and cardinality- robustness.IEEE TKDE, 2026
2026
-
[23]
Egovlpv2: Egocentric video-language pre-training with fusion in the backbone
Shraman Pramanick, Yale Song, Sayan Nag, Kevin Qinghong Lin, Hardik Shah, Mike Zheng Shou, Rama Chellappa, and Pengchuan Zhang. Egovlpv2: Egocentric video-language pre-training with fusion in the backbone. InICCV, pages 5285–5297, 2023. 1
2023
-
[24]
Zixu Li, Zhiheng Fu, Yupeng Hu, Zhiwei Chen, Haokun Wen, and Liqiang Nie. Finecir: Explicit parsing of fine- grained modification semantics for composed image re- trieval.https://arxiv.org/abs/2503.21309, 2025. 1
-
[25]
Intent: Invariance and discrimination-aware noise mitigation for robust composed image retrieval
Zhiwei Chen, Yupeng Hu, Zhiheng Fu, Zixu Li, Jiale Huang, Qinlei Huang, and Yinwei Wei. Intent: Invariance and discrimination-aware noise mitigation for robust composed image retrieval. InAAAI, pages 20463–20471, 2026
2026
-
[26]
Habit: Chrono- synergia robust progressive learning framework for com- posed image retrieval
Zixu Li, Yupeng Hu, Zhiwei Chen, Shiqi Zhang, Qinlei Huang, Zhiheng Fu, and Yinwei Wei. Habit: Chrono- synergia robust progressive learning framework for com- posed image retrieval. InAAAI, pages 6762–6770, 2026
2026
-
[27]
TEMA: Anchor the Image, Follow the Text for Multi-Modification Composed Image Retrieval
Zixu Li, Yupeng Hu, Zhiheng Fu, Zhiwei Chen, Yongqi Li, and Liqiang Nie. Tema: Anchor the image, follow the text for multi-modification composed image retrieval.arXiv preprint arXiv:2604.21806, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Melt: Improve com- posed image retrieval via the modification frequentation- rarity balance network
Guozhi Qiu, Zhiwei Chen, Zixu Li, Qinlei Huang, Zhiheng Fu, Xuemeng Song, and Yupeng Hu. Melt: Improve com- posed image retrieval via the modification frequentation- rarity balance network. InICASSP, pages 13007–13011. IEEE, 2026. 1
2026
-
[29]
Hint: Com- posed image retrieval with dual-path compositional contex- tualized network
Mingyu Zhang, Zixu Li, Zhiwei Chen, Zhiheng Fu, Xiaowei Zhu, Jiajia Nie, Yinwei Wei, and Yupeng Hu. Hint: Com- posed image retrieval with dual-path compositional contex- tualized network. InICASSP, pages 13002–13006. IEEE,
-
[30]
CoVR-R:Reason-Aware Composed Video Retrieval
Omkar Thawakar, Dmitry Demidov, Vaishnav Potlapalli, Sai Prasanna Teja Reddy Bogireddy, Viswanatha Reddy Gajjala, Alaa Mostafa Lasheen, Rao Muhammad Anwer, and Fa- had Khan. Covr-r: Reason-aware composed video retrieval. arXiv preprint arXiv:2603.20190, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.