Enhancing Audio Captioning with Auxiliary AudioSet Semantics
Pith reviewed 2026-06-27 23:59 UTC · model grok-4.3
The pith
A compact six-layer decoder generates competitive audio captions by conditioning on ConvNeXt acoustic features augmented with top-K AudioSet keyword predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that explicitly grounding caption generation in auxiliary AudioSet semantics—by augmenting ConvNeXt frame-level acoustic representations with top-K predicted keywords—allows a compact six-layer BART-style decoder to produce natural language descriptions that match the quality of larger models on Clotho V2 and AudioCaps under practical deployment constraints.
What carries the argument
The joint acoustic-semantic representation formed by combining ConvNeXt frame-level features with top-K AudioSet keyword predictions, which directly conditions the compact decoder.
If this is right
- Caption generation proceeds without reliance on large-scale sequence-to-sequence or LLM-based models.
- Structured contextual cues from AudioSet address word-selection indeterminacy in acoustic scene description.
- The compact architecture supports deployment under practical computational constraints while preserving caption quality.
- Competitive results hold on the Clotho V2 and AudioCaps benchmarks.
Where Pith is reading between the lines
- The same augmentation strategy might transfer to other generation tasks that already have access to auxiliary classification outputs.
- Performance could degrade in domains where AudioSet predictions are systematically inaccurate or mismatched to the target audio scenes.
- The approach points toward a broader pattern of using lightweight auxiliary predictions to guide compact decoders across multimodal tasks.
Load-bearing premise
That the top-K AudioSet keyword predictions supply reliable structured contextual cues that improve caption generation rather than adding noise or incorrect semantic information that harms performance.
What would settle it
A controlled ablation in which the model trained and evaluated without the AudioSet keyword augmentation achieves equal or higher caption metrics than the full model on both Clotho V2 and AudioCaps.
Figures

read the original abstract
Automatic Audio Captioning (AAC) seeks to generate natural language descriptions of complex acoustic scenes, bridging auditory perception and language understanding. However, word-selection indeterminacy and increasing reliance on large-scale sequence-to-sequence or LLM-based models limit practical deployment. We propose a resource-efficient AAC framework that explicitly grounds caption generation in auxiliary AudioSet semantics. Frame-level acoustic representations extracted using a ConvNeXt encoder are augmented with top-$K$ predicted AudioSet keywords, providing structured contextual cues for decoding. A compact six-layer BART-style decoder conditions on this joint acoustic-semantic representation, enabling caption generation without LLM-scale decoding. The proposed design balances semantic grounding and computational efficiency within a compact architecture. Evaluations on Clotho V2 and AudioCaps confirm competitive caption quality under practical deployment constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a resource-efficient automatic audio captioning (AAC) framework that extracts frame-level features with a ConvNeXt encoder, augments them with top-K predicted AudioSet keywords, and feeds the joint representation to a compact six-layer BART-style decoder. It claims this supplies structured semantic cues that improve caption generation while avoiding LLM-scale decoding, with evaluations on Clotho V2 and AudioCaps confirming competitive quality under practical constraints.
Significance. If the central claims hold after proper validation, the work would be moderately significant for the AAC field by showing that auxiliary semantics from a standard ontology can be integrated into a small decoder to address word-selection issues without large models, offering a practical efficiency trade-off.
major comments (2)
- [Abstract] Abstract: The assertion that 'Evaluations on Clotho V2 and AudioCaps confirm competitive caption quality' is unsupported by any reported metrics, baselines, error bars, or statistical details in the manuscript, rendering the headline performance claim impossible to evaluate.
- [Framework description (abstract and full text)] Framework description (abstract and full text): The claim that top-K AudioSet keyword predictions supply 'structured contextual cues' that improve caption generation rests on the untested premise that these predictions are accurate and relevant; no ablation against a keyword-free baseline or ground-truth labels is described, leaving open the risk that ontology mismatches or classifier errors add noise and degrade performance instead.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, agreeing where the manuscript requires strengthening and outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'Evaluations on Clotho V2 and AudioCaps confirm competitive caption quality' is unsupported by any reported metrics, baselines, error bars, or statistical details in the manuscript, rendering the headline performance claim impossible to evaluate.
Authors: We agree that the abstract's performance claim would be stronger and more evaluable if accompanied by specific metrics. In the revised manuscript we will update the abstract to report the primary captioning scores (e.g., SPIDEr, CIDEr, BLEU-4) achieved on both Clotho V2 and AudioCaps, together with the corresponding baseline numbers from the experiments section. revision: yes
-
Referee: [Framework description (abstract and full text)] Framework description (abstract and full text): The claim that top-K AudioSet keyword predictions supply 'structured contextual cues' that improve caption generation rests on the untested premise that these predictions are accurate and relevant; no ablation against a keyword-free baseline or ground-truth labels is described, leaving open the risk that ontology mismatches or classifier errors add noise and degrade performance instead.
Authors: We acknowledge the absence of an explicit ablation isolating the contribution of the predicted keywords. The revised manuscript will include a new ablation table that compares the full model against an otherwise identical keyword-free variant on both datasets. We will also report the keyword predictor's top-K accuracy on the evaluation splits to quantify the risk of noisy labels. revision: yes
Circularity Check
No significant circularity; architecture uses standard pretrained components
full rationale
The paper presents an engineering framework that augments ConvNeXt frame features with top-K AudioSet keyword predictions before BART decoding. No equations, fitted parameters renamed as predictions, or self-citations appear in the abstract or described approach. The central claim rests on empirical evaluation of a composite system built from independently pretrained models rather than any derivation that reduces to its own inputs by construction. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
muffled speech
Introduction Automated Audio Captioning (AAC) transforms raw audio sig- nals into structured textual descriptions, enabling applications in multimedia retrieval, security surveillance, and assistive tech- nologies. Unlike traditional audio tagging, AAC must model not only discrete acoustic events but also broader scene-level context, including environment...
-
[2]
We introduce a simple, effective fusion of frame-level acous- tic features with top-KAudioSet keyword embeddings that explicitly grounds caption generation and reduces word- selection indeterminacy
-
[3]
We propose a compact six-layer BART-style decoder and provide ablations demonstrating that, when guided by seman- tic keywords, reduced decoder capacity attains a favorable efficiency-quality Pareto frontier
-
[4]
We systematically analyze the role of semantic tags through tag-only, audio-only, and fusion ablations, highlighting com- plementary gains from joint modeling
-
[5]
We evaluate comprehensively on Clotho V2 and AudioCaps, including SPIDEr and FENSE metrics, cross-dataset analy- sis, and sensitivity studies on the number of keywords (K)
-
[6]
Related Works and Baselines Prior studies have explored auxiliary semantic cues, encoder fu- sion strategies, and advanced language modeling to address data scarcity and improve semantic grounding in AAC. Koizumi et al. [1] guided caption generation by leveraging the most fre- quent words from Clotho captions, which improved semantic relevance but lacked ...
Pith/arXiv arXiv 2026
-
[7]
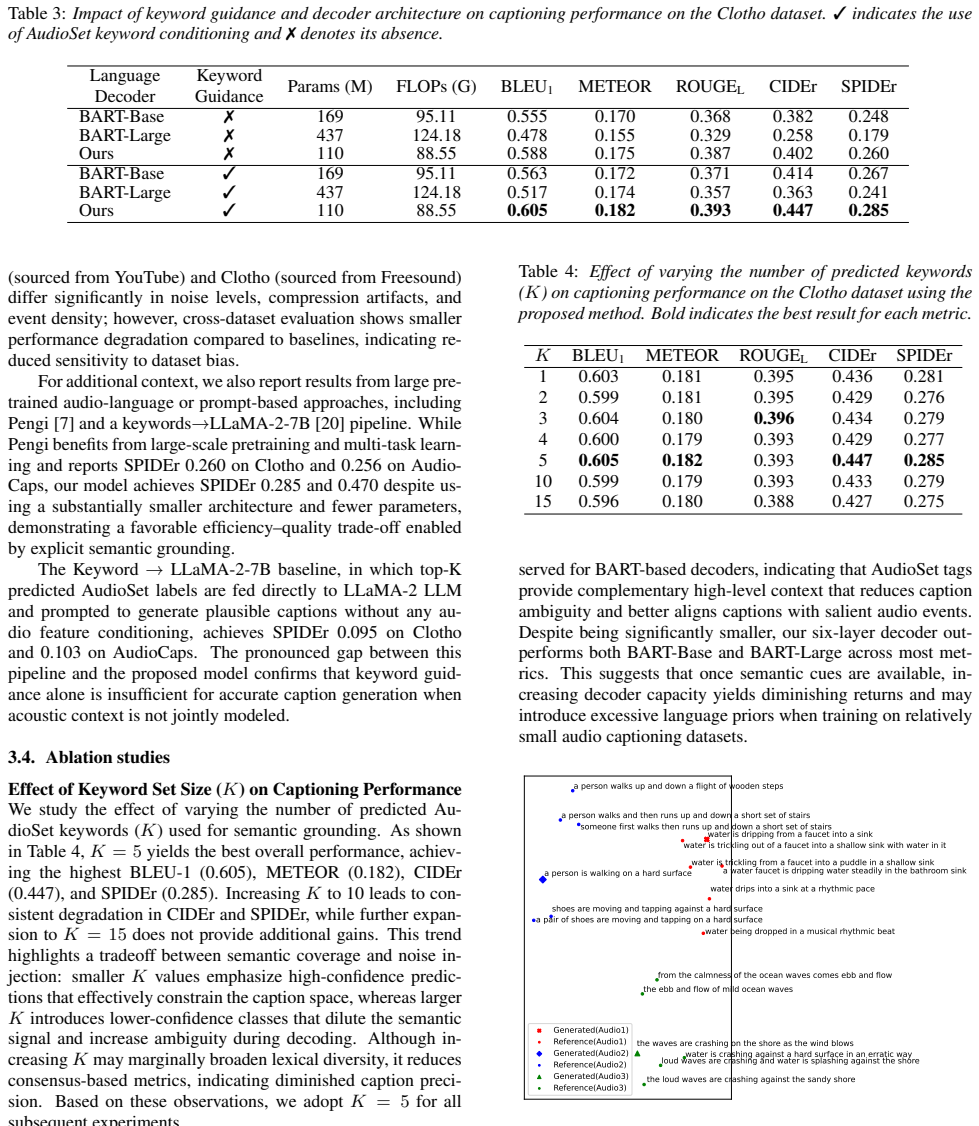
Experiments and Results 3.1. Datasets We conducted experiments on two audio captioning bench- marks: AudioCaps [11] and Clotho-V2 [12]. AudioCaps con- Table 1:Evaluation on Clotho. Methods are grouped based on training source. (i) Clotho, (ii) AudioCaps and (iii) Large pretrained or prompt-based methods.†Results are directly quoted from the original paper...
arXiv 2023
-
[8]
Conclusion This work presents a balanced framework for automated au- dio captioning that integrates AudioSet semantic cues with a ConvNeXt-based encoder and a lightweight six-layer BART- style decoder. By incorporating predicted AudioSet keywords, the proposed approach helps mitigate word-selection indeter- minacy and improves semantic alignment between a...
-
[9]
A Transformer-based Audio Captioning Model with Keyword Estimation,
Y . Koizumi, R. Masumura, K. Nishida, M. Yasuda, and S. Saito, “A Transformer-based Audio Captioning Model with Keyword Estimation,” inProceedings of the INTERSPEECH, 2020
2020
-
[10]
Audio Captioning Based on Combined Audio and Semantic Embeddings,
A. O. Eren and M. Sert, “Audio Captioning Based on Combined Audio and Semantic Embeddings,” inIEEE International Sympo- sium on Multimedia, 2020
2020
-
[11]
Automated Audio Cap- tioning by Fine-Tuning BART with AudioSet Tags,
F. Gontier, R. Serizel, and C. Cerisara, “Automated Audio Cap- tioning by Fine-Tuning BART with AudioSet Tags,” inProceed- ings of the Detection and Classification of Acoustic Scenes and Events Workshop (DCASE), 2021
2021
-
[12]
Panns: Large-scale pretrained audio neural networks for audio pattern recognition,
Q. Kong, Y . Cao, T. Iqbal, Y . Wang, W. Wang, and M. D. Plumb- ley, “Panns: Large-scale pretrained audio neural networks for audio pattern recognition,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2880–2894, 2020
2020
-
[13]
Y AMNet: A Deep Net for Audio Event Detection,
S. P. Hershey, J. L. Roux, and D. Wang, “Y AMNet: A Deep Net for Audio Event Detection,” 2017, accessed: 2025-09-13. [Online]. Available: https://github.com/tensorflow/models/tree/ master/research/audioset/yamnet
2017
-
[14]
Prefix Tuning for Auto- mated Audio Captioning,
M. Kim, K. Sung-Bin, and T.-H. Oh, “Prefix Tuning for Auto- mated Audio Captioning,” inIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1– 5
2023
-
[15]
Pengi: An audio language model for audio tasks,
S. Deshmukh, B. Elizalde, R. Singh, and H. Wang, “Pengi: An audio language model for audio tasks,” inAdvances in Neural Information Processing Systems, A. Oh, T. Neumann, A. Glober- son, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp. 18 090–18 108. [Online]. Avail- able: https://proceedings.neurips.cc/paper files/pap...
2023
-
[16]
SLAM-AAC: Enhancing Audio Captioning with Para- phrasing Augmentation and CLAP-Refine through LLMs,
W. Chen, Z. Ma, X. Li, X. Xu, Y . Liang, Z. Zheng, K. Yu, and X. Chen, “SLAM-AAC: Enhancing Audio Captioning with Para- phrasing Augmentation and CLAP-Refine through LLMs,” pp. 1– 5, 2025
2025
-
[17]
Adapting a ConvNeXt Model to Audio Classification on Au- dioSet,
T. Pellegrini, I. Khalfaoui-Hassani, E. Labb ´e, and T. Masquelier, “Adapting a ConvNeXt Model to Audio Classification on Au- dioSet,” inProceedings of the Interspeech, 2023, pp. 4169–4173
2023
-
[18]
AudioSet: An Ontology and Human-Labeled Dataset for Audio Events,
J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “AudioSet: An Ontology and Human-Labeled Dataset for Audio Events,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 776–780
2017
-
[19]
Au- dioCaps: Generating Captions for Audios in the Wild,
C. Kim, J. S. Chung, J. Ha, B. Ko, M. Kim, and J. Kim, “Au- dioCaps: Generating Captions for Audios in the Wild,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 10 723–10 732
2020
-
[20]
Clotho: A Sound Event Dataset for Semantic Audio Generation,
K. Drossos, E. Benetos, and X. Serra, “Clotho: A Sound Event Dataset for Semantic Audio Generation,” inProceedings of the 21st International Society for Music Information Retrieval Con- ference (ISMIR), 2020
2020
-
[21]
Bleu: a Method for Automatic Evaluation of Machine Translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a Method for Automatic Evaluation of Machine Translation,” inProceed- ings of the 40th Annual Meeting of the Association for Computa- tional Linguistics, P. Isabelle, E. Charniak, and D. Lin, Eds., 2002, pp. 311–318
2002
-
[22]
METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judg- ments,
S. Banerjee and A. Lavie, “METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judg- ments,” inProceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, Michigan, 2005, pp. 65–72
2005
-
[23]
ROUGE: A Package for Automatic Evaluation of Summaries,
C.-Y . Lin, “ROUGE: A Package for Automatic Evaluation of Summaries,” inText Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74–81. [Online]. Available: https://aclanthology.org/W04-1013/
2004
-
[24]
CIDEr: Consensus- based image description evaluation,
R. Vedantam, C. L. Zitnick, and D. Parikh, “CIDEr: Consensus- based image description evaluation,” inIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 4566–4575
2015
-
[25]
SPICE: Semantic Propositional Image Caption Evaluation,
P. Anderson, B. Fernando, M. Johnson, and S. Gould, “SPICE: Semantic Propositional Image Caption Evaluation,” inECCV, 2016
2016
-
[26]
Improved Image Captioning via Policy Gradient optimization of SPIDEr,
S. Liu, Z. Zhu, N. Ye, S. Guadarrama, and K. Murphy, “Improved Image Captioning via Policy Gradient optimization of SPIDEr,” inIEEE International Conference on Computer Vision (ICCV). IEEE, 2017, p. 873–881
2017
-
[27]
Can audio captions be evaluated with image caption metrics?
Z. Zhou, Z. Zhang, X. Xu, Z. Xie, M. Wu, and K. Q. Zhu, “Can audio captions be evaluated with image caption metrics?” in ICASSP 2022 - 2022 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2022, pp. 981–985
2022
-
[28]
Llama 2: Open Foundation and Fine-Tuned Chat Models,
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V . Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V . Kerkez, M. Khabsa, I. Kloumann, A. Koren...
Pith/arXiv arXiv 2023
-
[29]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter,
V . Sanh, L. Debut, J. Chaumond, and T. Wolf, “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter,”
-
[30]
Available: https://arxiv.org/abs/1910.01108
[Online]. Available: https://arxiv.org/abs/1910.01108
Pith/arXiv arXiv 1910
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.