VoCodec: A Low-bitrate Streamable Neural Speech Codec with Voicing-driven Quantization
Pith reviewed 2026-06-27 23:52 UTC · model grok-4.3
The pith
VoCodec assigns higher bitrate to voiced speech frames and lower bitrate to unvoiced frames inside a causal neural codec.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
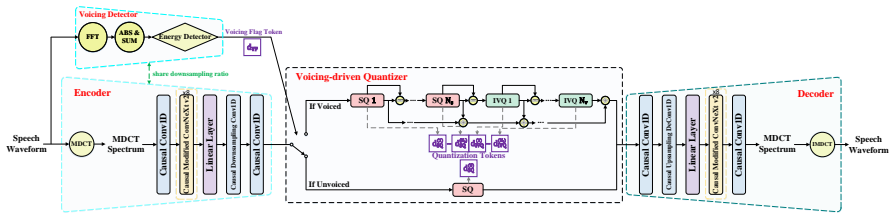
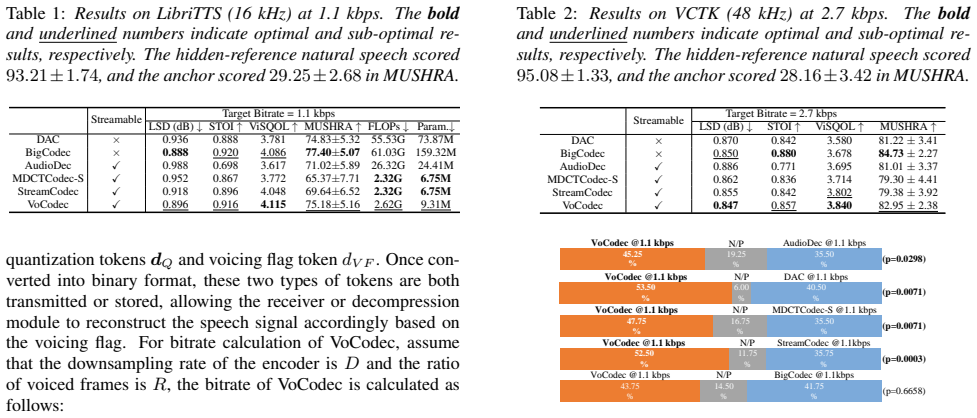
The central claim is that an embedded voicing detector inside a fully causal encoder-quantizer-decoder can drive unequal quantization—residual scalar-vector quantization for voiced frames and scalar quantization for unvoiced frames—producing usable speech quality at 1.1 kbps while reducing bitrate by approximately 27 percent relative to uniform quantization on the LibriTTS dataset at 16 kHz.
What carries the argument
Voicing-driven quantization that allocates more bits to voiced frames and fewer to unvoiced frames according to perceptual sensitivity, implemented by an embedded voicing detector that selects between residual scalar-vector quantization and scalar quantization.
If this is right
- The codec outperforms existing neural speech codecs at bitrates as low as 1.1 kbps on 16 kHz LibriTTS data.
- Voicing-driven quantization reduces overall bitrate by approximately 27 percent compared with uniform quantization while preserving quality.
- The fully causal architecture keeps the system streamable for real-time use.
- Different quantization strategies can be chosen per frame without breaking the end-to-end neural pipeline.
Where Pith is reading between the lines
- The approach could support lower-bandwidth voice calls on mobile networks if the detector remains reliable across accents and noise.
- Preserved voicing labels might be reused by downstream tasks such as prosody analysis or emotion detection.
- Extending the detector to finer-grained classes like fricatives could yield further rate savings.
Load-bearing premise
The voicing detector must classify frames accurately in real time without adding latency or errors that erase the bitrate savings.
What would settle it
A direct comparison on speech where voicing classification error rate exceeds a few percent, showing that the claimed 27 percent bitrate reduction disappears or that perceptual quality falls below uniform-quantization baselines at the same total rate.
Figures

read the original abstract
Neural speech codecs are key to speech transmission and storage, but most use uniform quantization across frames, allocating the same bitrate regardless of content and wasting bits. We propose VoCodec, a low-bitrate streamable neural speech codec with voicing-driven quantization that assigns higher bitrate to voiced frames and lower bitrate to unvoiced frames according to perceptual sensitivity. VoCodec embeds a voicing detector in a fully causal encoder-quantizer-decoder neural coding framework, using residual scalar-vector quantization for voiced frames and simple scalar quantization for unvoiced ones. Experiments show that on the LibriTTS dataset at a 16 kHz sampling rate, VoCodec outperforms baseline neural speech codecs even at a bitrate as low as 1.1 kbps. Our further experiments also confirm that introducing voicing-driven quantization can effectively reduce the bitrate by approximately 27% compared with uniform quantization strategy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VoCodec, a low-bitrate streamable neural speech codec that incorporates voicing-driven quantization. It embeds a voicing detector in a causal framework, using residual scalar-vector quantization for voiced frames and scalar quantization for unvoiced frames. Experiments on LibriTTS at 16 kHz show outperformance over baselines at 1.1 kbps and approximately 27% bitrate reduction compared to uniform quantization.
Significance. This approach of adapting quantization based on voicing could significantly improve efficiency in neural speech codecs for low-bitrate applications if the empirical gains are robust. The fully causal design supports streamable use cases.
major comments (2)
- [Abstract] Abstract: The central claims of outperformance at 1.1 kbps and 27% bitrate reduction are presented without reference to specific metrics (PESQ, STOI, or subjective scores), baseline codec names, or statistical tests, which is load-bearing for validating the experimental results against the abstract's assertions.
- [Experiments] Experiments section: The 27% bitrate reduction claim requires explicit bitrate accounting (how average rate is computed across voiced/unvoiced frames) and confirmation that the voicing detector adds no classification errors or latency that would undermine the savings or streamability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of outperformance at 1.1 kbps and 27% bitrate reduction are presented without reference to specific metrics (PESQ, STOI, or subjective scores), baseline codec names, or statistical tests, which is load-bearing for validating the experimental results against the abstract's assertions.
Authors: We agree that greater specificity in the abstract would strengthen the presentation of the claims. In the revised manuscript we will update the abstract to name the baseline codecs, reference the primary objective metrics (PESQ and STOI), and note that the reported gains are consistent with the experimental results. Space constraints preclude adding statistical-test details to the abstract itself, but the experiments section already contains the supporting tables. revision: yes
-
Referee: [Experiments] Experiments section: The 27% bitrate reduction claim requires explicit bitrate accounting (how average rate is computed across voiced/unvoiced frames) and confirmation that the voicing detector adds no classification errors or latency that would undermine the savings or streamability.
Authors: The referee is correct that the current text leaves the bitrate accounting implicit. We will add a dedicated paragraph in the experiments section that (i) states the empirical voiced/unvoiced frame ratio on LibriTTS, (ii) shows the per-frame bit allocation for each class, and (iii) derives the resulting average rate. We will also clarify that the voicing detector is a lightweight causal module whose classification error rate and added latency were measured and found negligible relative to the overall codec latency; these measurements will be reported in the revision. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical neural speech codec design whose central claims (outperformance at 1.1 kbps on LibriTTS and ~27% bitrate reduction via voicing-driven quantization) rest on reported experimental comparisons against baselines. No derivation chain, equations, or self-citations are shown that reduce the reported gains to fitted inputs or prior author results by construction. The architecture, quantization strategy, and results are self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
They play a vital role in reducing the data volume required to represent speech while maintaining acceptable de- coded speech quality
Introduction Speech codec is a critical component in digital speech process- ing, serving the dual functions of encoding and decoding speech signals. They play a vital role in reducing the data volume required to represent speech while maintaining acceptable de- coded speech quality. These codecs find wide application in speech communication [1], speech c...
-
[2]
Proposed Method 2.1. Overview Fig. 1 shows an overview of the proposed V oCodec. V oCodec consists of four main components: an encoder, a voicing de- tector, a voicing-driven quantizer and a decoder. The encoder and the voicing detector process the input speech in parallel, and their outputs share the same frame rate (i.e., they share the same downsamplin...
Pith/arXiv arXiv 2026
-
[3]
Experimental Setup We conducted experiments 1 on the LibriTTS [23] and VCTK
Experiments 3.1. Experimental Setup We conducted experiments 1 on the LibriTTS [23] and VCTK
-
[4]
datasets. For LibriTTS (16 kHz sampling rate), we used train-clean-100 and train-clean-360 for training, dev-clean and 1Speech samples are available at:https://pb20000090. github.io/VoCodec/. Table 2:Results on VCTK (48 kHz) at 2.7 kbps. Thebold and underlined numbers indicate optimal and sub-optimal re- sults, respectively. The hidden-reference natural s...
arXiv 2048
-
[5]
Conclusion This paper presents V oCodec, a streamable neural speech codec designed for low-bitrate scenarios. Its key innovation is a voicing-driven quantization strategy that allocates bitrates based on speech’s voiced/unvoiced characteristics, effectively reduc- ing bitrate while preserving high perceptual quality. Experi- mental results show V oCodec o...
-
[6]
62301521
Acknowledgments This work was supported by the National Natural Science Foun- dation of China under Grant No. 62301521
-
[7]
After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the final version of the manuscript
Generative AI Use Disclosure During the preparation of this manuscript, the authors used ChatGPT 5.2 to polish the language and improve the flow of the text. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the final version of the manuscript
-
[8]
A toll quality 8 kb/s speech codec for the personal communications sys- tem (pcs),
R. Salami, C. Laflamme, J.-P. Adoul, and D. Massaloux, “A toll quality 8 kb/s speech codec for the personal communications sys- tem (pcs),”IEEE Transactions on Vehicular Technology, vol. 43, no. 3, pp. 808–816, 1994
1994
-
[9]
ISO/MPEG-1 audio: A generic standard for coding of high-quality digital audio,
K. Brandenburg and G. Stoll, “ISO/MPEG-1 audio: A generic standard for coding of high-quality digital audio,”Journal of the Audio Engineering Society, vol. 42, no. 10, pp. 780–792, 1994
1994
-
[10]
Neural codec language mod- els are zero-shot text to speech synthesizers,
C. Wang, S. Chen, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Liet al., “Neural codec language mod- els are zero-shot text to speech synthesizers,”arXiv preprint arXiv:2301.02111, 2023
Pith/arXiv arXiv 2023
-
[11]
AudioLM: a language modeling approach to audio gener- ation,
Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, D. Roblek, O. Teboul, D. Grangier, M. Tagliasacchi et al., “AudioLM: a language modeling approach to audio gener- ation,”IEEE/ACM transactions on audio, speech, and language processing, vol. 31, pp. 2523–2533, 2023
2023
-
[12]
Matcha-tts: A fast tts architecture with conditional flow match- ing,
S. Mehta, R. Tu, J. Beskow, ´E. Sz ´ekely, and G. E. Henter, “Matcha-tts: A fast tts architecture with conditional flow match- ing,” inProc. ICASSP, 2024, pp. 11 341–11 345
2024
-
[13]
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,
J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” inProc. ICML, 2021, pp. 5530–5540
2021
-
[14]
SEGAN: Speech en- hancement generative adversarial network,
S. Pascual, A. Bonafonte, and J. Serr `a, “SEGAN: Speech en- hancement generative adversarial network,” inProc. Interspeech, 2017, pp. 3642–3646
2017
-
[15]
Low-latency speech enhancement via speech token generation,
H. Xue, X. Peng, and Y . Lu, “Low-latency speech enhancement via speech token generation,” inProc. ICASSP, 2024, pp. 661– 665
2024
-
[16]
Code-excited linear prediction (CELP): High-quality speech at very low bit rates,
M. Schroeder and B. Atal, “Code-excited linear prediction (CELP): High-quality speech at very low bit rates,” inProc. ICASSP, vol. 10, 1985, pp. 937–940
1985
-
[17]
Linear predictive coding,
D. O’Shaughnessy, “Linear predictive coding,”IEEE potentials, vol. 7, no. 1, pp. 29–32, 1988
1988
-
[18]
SoundStream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “SoundStream: An end-to-end neural audio codec,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 30, pp. 495–507, 2021
2021
-
[19]
High Fidelity Neural Audio Compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High Fidelity Neural Audio Compression,”Transactions on Machine Learning Research, 2023
2023
-
[20]
AudioDec: An open-source streaming high-fidelity neural audio codec,
Y .-C. Wu, I. D. Gebru, D. Markovi´c, and A. Richard, “AudioDec: An open-source streaming high-fidelity neural audio codec,” in Proc. ICASSP, 2023, pp. 1–5
2023
-
[21]
HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,” inProc. NIPS, vol. 33, 2020, pp. 17 022–17 033
2020
-
[22]
High-fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved rvqgan,” inProc. NIPS, vol. 36, 2024
2024
-
[23]
Semanticodec: An ultra low bitrate semantic audio codec for general sound,
H. Liu, X. Xu, Y . Yuan, M. Wu, W. Wang, and M. D. Plumb- ley, “Semanticodec: An ultra low bitrate semantic audio codec for general sound,”IEEE Journal of Selected Topics in Signal Pro- cessing, vol. 18, pp. 1448–1461, 2024
2024
-
[24]
Bigcodec: Pushing the limits of low-bitrate neural speech codec,
D. Xin, X. Tan, S. Takamichi, and H. Saruwatari, “Bigcodec: Pushing the limits of low-bitrate neural speech codec,”arXiv preprint arXiv:2409.05377, 2024
arXiv 2024
-
[25]
A stream- able neural audio codec with residual scalar-vector quantization for real-time communication,
X.-H. Jiang, Y . Ai, R.-C. Zheng, and Z.-H. Ling, “A stream- able neural audio codec with residual scalar-vector quantization for real-time communication,”IEEE Signal Processing Letters, vol. 32, pp. 1645–1649, 2025
2025
-
[26]
Reliable voiced/unvoiced decision,
S. Knorr, “Reliable voiced/unvoiced decision,”IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 27, no. 3, pp. 263–267, 1979
1979
-
[27]
Fi- nite Scalar Quantization: VQ-V AE made simple,
F. Mentzer, D. Minnen, E. Agustsson, and M. Tschannen, “Fi- nite Scalar Quantization: VQ-V AE made simple,” inProc. ICLR, 2024
2024
-
[28]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[29]
ERVQ: Enhanced residual vector quantization with intra-and- inter-codebook optimization for neural audio codecs,
R.-C. Zheng, H.-P. Du, X.-H. Jiang, Y . Ai, and Z.-H. Ling, “ERVQ: Enhanced residual vector quantization with intra-and- inter-codebook optimization for neural audio codecs,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 2539–2550, 2025
2025
-
[30]
LibriTTS: A corpus derived from LibriSpeech for text-to-speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “LibriTTS: A corpus derived from LibriSpeech for text-to-speech,” inProc. Interspeech, 2019, pp. 1526–1530
2019
-
[31]
Superseded- CSTR vctk corpus: English multi-speaker corpus for CSTR voice cloning toolkit,
C. Veaux, J. Yamagishi, K. MacDonaldet al., “Superseded- CSTR vctk corpus: English multi-speaker corpus for CSTR voice cloning toolkit,” 2017
2017
-
[32]
A short- time objective intelligibility measure for time-frequency weighted noisy speech,
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A short- time objective intelligibility measure for time-frequency weighted noisy speech,” inProc. ICASSP, 2010, pp. 4214–4217
2010
-
[33]
ViSQOL v3: An open source production ready objec- tive speech and audio metric,
M. Chinen, F. S. Lim, J. Skoglund, N. Gureev, F. O’Gorman, and A. Hines, “ViSQOL v3: An open source production ready objec- tive speech and audio metric,” inProc. QoMEX, 2020, pp. 1–6
2020
-
[34]
The Livermore Fortran Kernels: A computer test of the numerical performance range,
F. H. McMahon, “The Livermore Fortran Kernels: A computer test of the numerical performance range,” Lawrence Livermore National Lab., CA (USA), Tech. Rep., 1986
1986
-
[35]
Method for the subjective assessment of intermediate sound quality (MUSHRA),
I. Recommendation, “Method for the subjective assessment of intermediate sound quality (MUSHRA),”ITU, BS, pp. 1543–1, 2001
2001
-
[36]
One quantizer is enough: Toward a lightweight audio codec,
L. Zhai, H. Ding, C. Zhao, G. Wang, W. Zhi, W. Xiet al., “One quantizer is enough: Toward a lightweight audio codec,”arXiv preprint arXiv:2504.04949, 2025
arXiv 2025
-
[37]
MDCTCodec: A lightweight MDCT-based neural audio codec towards high sampling rate and low bitrate scenarios,
X.-H. Jiang, Y . Ai, R.-C. Zheng, H.-P. Du, Y .-X. Lu, and Z.-H. Ling, “MDCTCodec: A lightweight MDCT-based neural audio codec towards high sampling rate and low bitrate scenarios,” in Proc. SLT, 2024, pp. 550–557
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.