Don't Pause: Streaming Video-Language Synchrony for Online Video Understanding
Pith reviewed 2026-06-27 22:08 UTC · model grok-4.3
The pith
LyraV keeps video perception active by emitting small token chunks per frame instead of pausing for full responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
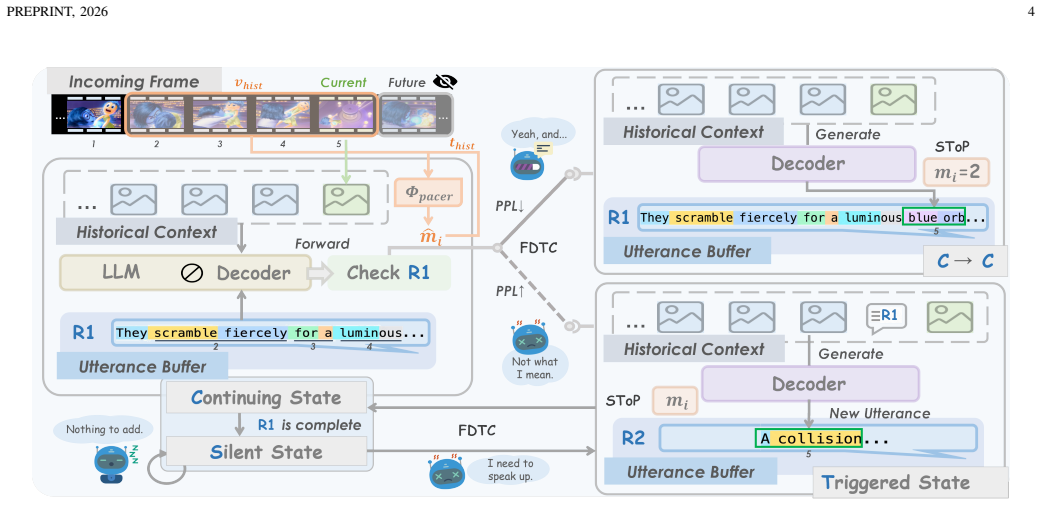
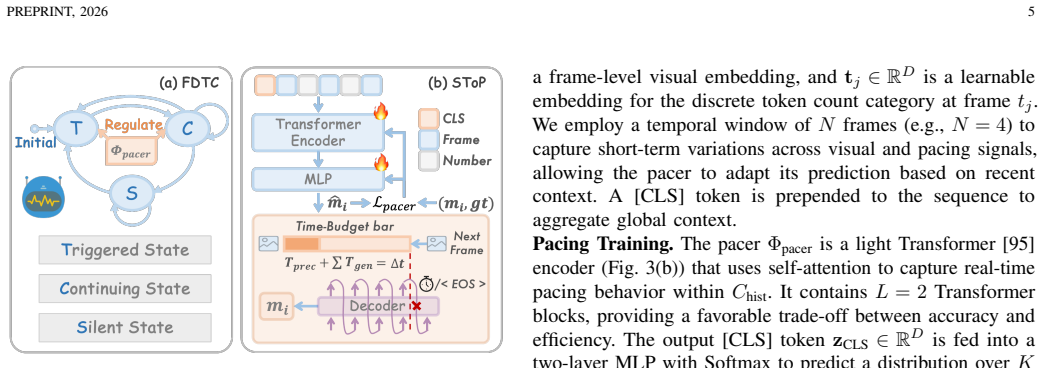
LyraV performs per-frame incremental, sub-budget decoding so perception is never blocked for a full sentence, achieving 98.29% synchrony with video playback and 3.89 FPS while preserving the backbone's general understanding ability. This is realized through the Frame-Driven Transition Controller, a training-free verification-based finite-state machine that makes high-level decisions on continuing speech, starting new responses, or remaining silent, together with the Streaming Token Pacer, a lightweight predictive module that adapts generation rate to visual content pace, enabling seamless interleaving of frames and tokens.
What carries the argument
The Frame-Driven Transition Controller (FDTC), a training-free verification-based finite-state machine for semantic transition decisions, paired with the Streaming Token Pacer (SToP), a plug-and-play predictive module that controls token emission rate to fit real-time frame budgets.
If this is right
- LyraV achieves 98.29% synchrony with video playback and processes at 3.89 FPS on streaming benchmarks.
- It preserves the backbone model's performance on general offline video understanding tasks.
- The system enables dynamic reasoning over streaming tokens for ongoing interpretation alongside incoming frames.
- Narrative fluency improves because responses interleave naturally with visual input rather than arriving in blocks.
Where Pith is reading between the lines
- The same per-frame pacing and transition control could apply to other live multimodal streams such as audio or sensor feeds.
- Longer-duration live tests would show whether the finite-state decisions remain stable over extended sessions.
- Predictive token pacing may reduce user-perceived latency in interactive video systems beyond the tested benchmarks.
Load-bearing premise
The training-free FDTC finite-state machine and the lightweight predictive SToP module can be combined with an existing backbone without degrading its core capabilities or introducing unacceptable latency in real streaming conditions.
What would settle it
A live video stream test that measures whether synchrony with playback drops substantially below 98.29 percent or whether perception blocks occur for entire sentences during continuous operation.
Figures



read the original abstract
Online Video Large Language Models (Video-LLMs) have advanced toward seamless human-AI interaction through frame-by-frame processing and proactive responding. However, a critical challenge remains in streaming scenarios: existing models typically pause video perception while generating responses, breaking real-time video-language synchrony and causing stutters. To address this, we introduce a novel paradigm for online video understanding: Streaming Video-Language Synchrony (SVLS), and present LyraV, a live streaming assistant built upon a hierarchical control framework with two core innovations. First, the Frame-Driven Transition Controller (FDTC), a training-free verification-based finite-state machine, makes high-level semantic decisions on when to continue speaking, start a new response, or stay silent. Second, the Streaming Token Pacer (SToP), a plug-and-play lightweight predictive module, dynamically adapts the language generation rate to match the pace of the visual content. Concretely, LyraV performs \emph{per-frame incremental, sub-budget decoding}: within each frame interval it emits only a small chunk of tokens that fits the real-time budget, so perception is never blocked for a full sentence. Together, these components enable LyraV to seamlessly interleave incoming video frames with generated word tokens, achieving a fine-grained synchrony. Extensive experiments conducted on five online and three offline benchmarks demonstrate that LyraV preserves the backbone's general understanding ability while substantially improving streaming synchrony and narrative fluency, delivering a 98.29\% synchrony with video playback and a real-time processing speed of 3.89 FPS. Interestingly, we observe an empirical capability in LyraV: dynamic reasoning over streaming tokens, enabling continuous interpretation and "thinking" alongside visual input.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Streaming Video-Language Synchrony (SVLS) paradigm to prevent Video-LLMs from pausing perception during response generation in streaming settings. It presents LyraV, built on a hierarchical control framework with two innovations: the training-free Frame-Driven Transition Controller (FDTC), a verification-based finite-state machine for semantic decisions on continuing, starting new responses, or staying silent; and the plug-and-play Streaming Token Pacer (SToP) module to adapt generation rate to visual pace. The core mechanism is per-frame incremental sub-budget decoding that interleaves frames and tokens, yielding claimed results of 98.29% synchrony at 3.89 FPS across five online and three offline benchmarks while preserving the backbone's general understanding ability; an additional empirical observation is dynamic reasoning over streaming tokens.
Significance. If the integration claims hold, the work offers a practical route to real-time video-language interaction without retraining, leveraging the training-free FDTC and lightweight SToP as strengths that could ease deployment. The emphasis on fine-grained synchrony and narrative fluency addresses a clear gap in existing online Video-LLMs.
major comments (3)
- [§4 Experiments] §4 (Experiments) and Table 2/3: the central claim that LyraV 'preserves the backbone's general understanding ability' is load-bearing for the contribution yet lacks explicit before/after scores, statistical significance, or error bars on the three offline benchmarks; only high-level statements appear without the quantitative comparisons needed to verify no degradation.
- [§3.2 and §3.3] §3.2 (FDTC) and §3.3 (SToP): the 3.89 FPS real-time guarantee and 'never blocked for a full sentence' property depend on the combined latency of the FSM and predictive module, but no per-component breakdown, variable frame-rate stress tests, or buffering analysis under realistic arrival jitter is reported, leaving the latency bounds unverified.
- [Abstract and §4.1] Abstract and §4.1 (Online benchmarks): the headline 98.29% synchrony figure is presented without a detailed measurement protocol, baseline definitions, or error analysis, so it cannot be assessed against the stated claim of fine-grained interleaving.
minor comments (2)
- [§3.2] Notation for state transitions in the FDTC finite-state machine could be formalized with a small diagram or pseudocode for clarity.
- [§4] The abstract mentions 'five online and three offline benchmarks' but the main text should explicitly list their names and splits in §4 for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. We address each of the major comments below, proposing specific revisions to strengthen the paper.
read point-by-point responses
-
Referee: [§4 Experiments] §4 (Experiments) and Table 2/3: the central claim that LyraV 'preserves the backbone's general understanding ability' is load-bearing for the contribution yet lacks explicit before/after scores, statistical significance, or error bars on the three offline benchmarks; only high-level statements appear without the quantitative comparisons needed to verify no degradation.
Authors: We agree that explicit quantitative comparisons are important to substantiate the claim of preserved general understanding ability. In the revised manuscript, we will add a dedicated table in Section 4 comparing the performance of the backbone model and LyraV on the three offline benchmarks, including any available statistical measures such as standard deviations across multiple runs. revision: yes
-
Referee: [§3.2 and §3.3] §3.2 (FDTC) and §3.3 (SToP): the 3.89 FPS real-time guarantee and 'never blocked for a full sentence' property depend on the combined latency of the FSM and predictive module, but no per-component breakdown, variable frame-rate stress tests, or buffering analysis under realistic arrival jitter is reported, leaving the latency bounds unverified.
Authors: The reported 3.89 FPS is the end-to-end measured processing speed. Our design ensures incremental decoding within frame intervals. We will enhance the revision with a per-component latency breakdown for FDTC and SToP, variable frame-rate experiments, and buffering analysis under jitter to verify the real-time properties. revision: yes
-
Referee: [Abstract and §4.1] Abstract and §4.1 (Online benchmarks): the headline 98.29% synchrony figure is presented without a detailed measurement protocol, baseline definitions, or error analysis, so it cannot be assessed against the stated claim of fine-grained interleaving.
Authors: We will update the abstract and Section 4.1 to provide a comprehensive description of the synchrony metric's measurement protocol, including how it is computed, the baseline methods used for comparison, and details on any error analysis performed. revision: yes
Circularity Check
No circularity; results are empirical evaluations on external benchmarks
full rationale
The paper introduces LyraV via two components (training-free FDTC FSM and plug-and-play SToP module) that enable per-frame sub-budget decoding. All headline metrics (98.29% synchrony, 3.89 FPS, preserved backbone accuracy) are stated as outcomes of experiments on five online and three offline benchmarks rather than quantities derived from internal definitions, fitted parameters renamed as predictions, or self-citation chains. No equations appear in the provided text, and the central claims rest on external benchmark comparisons instead of reducing to the method's own inputs by construction. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
LiveStarPro: Proactive Streaming Video Understanding with Hierarchical Memory for Long-Horizon Streams
LiveStarPro uses SVeD for response timing via perplexity, SCAM for incremental alignment, and TSHM for event-chain memory to achieve 28.9% better semantic correctness and 1.58x speedup on long video streams.
Reference graph
Works this paper leans on
-
[1]
K. Ataallah, X. Shen, E. Abdelrahman, E. Sleiman, D. Zhu, J. Ding, and M. Elhoseiny, “Minigpt4-video: Advancing multimodal llms for video understanding with interleaved visual-textual tokens,”arXiv preprint arXiv:2404.03413, 2024
arXiv 2024
-
[2]
Video-chatgpt: Towards detailed video understanding via large vision and language models,
M. Maaz, H. Rasheed, S. Khan, and F. S. Khan, “Video-chatgpt: Towards detailed video understanding via large vision and language models,” arXiv preprint arXiv:2306.05424, 2023
Pith/arXiv arXiv 2023
-
[3]
Videochat: Chat-centric video understanding,
K. Li, Y . He, Y . Wang, Y . Li, W. Wang, P. Luo, Y . Wang, L. Wang, and Y . Qiao, “Videochat: Chat-centric video understanding,”arXiv preprint arXiv:2305.06355, 2023
Pith/arXiv arXiv 2023
-
[4]
Vid2seq: Large-scale pretraining of a visual language model for dense video captioning,
A. Yang, A. Nagrani, P. H. Seo, A. Miech, J. Pont-Tuset, I. Laptev, J. Sivic, and C. Schmid, “Vid2seq: Large-scale pretraining of a visual language model for dense video captioning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 10 714–10 726
2023
-
[5]
Internvideo: General video foundation models via generative and discriminative learning,
Y . Wang, K. Li, Y . Li, Y . He, B. Huang, Z. Zhao, H. Zhang, J. Xu, Y . Liu, Z. Wanget al., “Internvideo: General video foundation models via generative and discriminative learning,”arXiv preprint arXiv:2212.03191, 2022
Pith/arXiv arXiv 2022
-
[6]
Cat+: Investigating and enhancing audio-visual understanding in large language models,
Q. Ye, Z. Yu, R. Shao, Y . Cui, X. Kang, X. Liu, P. Torr, and X. Cao, “Cat+: Investigating and enhancing audio-visual understanding in large language models,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 10, pp. 8674–8690, 2025
2025
-
[7]
Motionllm: Understanding human behaviors from human motions and videos,
L.-H. Chen, S. Lu, A. Zeng, H. Zhang, B. Wang, R. Zhang, and L. Zhang, “Motionllm: Understanding human behaviors from human motions and videos,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–15, 2025
2025
-
[8]
Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms,
Z. Cheng, S. Leng, H. Zhang, Y . Xin, X. Li, G. Chen, Y . Zhu, W. Zhang, Z. Luo, D. Zhaoet al., “Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms,”arXiv preprint arXiv:2406.07476, 2024
Pith/arXiv arXiv 2024
-
[9]
Oryx mllm: On- demand spatial-temporal understanding at arbitrary resolution,
Z. Liu, Y . Dong, Z. Liu, W. Hu, J. Lu, and Y . Rao, “Oryx mllm: On- demand spatial-temporal understanding at arbitrary resolution,”arXiv preprint arXiv:2409.12961, 2024
arXiv 2024
-
[10]
Timechat: A time-sensitive multimodal large language model for long video understanding,
S. Ren, L. Yao, S. Li, X. Sun, and L. Hou, “Timechat: A time-sensitive multimodal large language model for long video understanding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 313–14 323. PREPRINT, 2026 15
2024
-
[11]
Hier-egopack: Hierarchical egocentric video understanding with diverse task perspectives,
S. A. Peirone, F. Pistilli, A. Alliegro, T. Tommasi, and G. Averta, “Hier-egopack: Hierarchical egocentric video understanding with diverse task perspectives,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 2, pp. 1917–1931, 2026
1917
-
[12]
Flash- vstream: Memory-based real-time understanding for long video streams,
H. Zhang, Y . Wang, Y . Tang, Y . Liu, J. Feng, J. Dai, and X. Jin, “Flash- vstream: Memory-based real-time understanding for long video streams,” arXiv preprint arXiv:2406.08085, 2024
arXiv 2024
-
[13]
Moviechat+: Question-aware sparse memory for long video question answering,
E. Song, W. Chai, T. Ye, J.-N. Hwang, X. Li, and G. Wang, “Moviechat+: Question-aware sparse memory for long video question answering,” arXiv preprint arXiv:2404.17176, 2024
arXiv 2024
-
[14]
Ma-lmm: Memory-augmented large multimodal model for long-term video understanding,
B. He, H. Li, Y . K. Jang, M. Jia, X. Cao, A. Shah, A. Shrivastava, and S.-N. Lim, “Ma-lmm: Memory-augmented large multimodal model for long-term video understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13 504–13 514
2024
-
[15]
Longllava: Scaling multi-modal llms to 1000 images efficiently via hybrid architecture,
X. Wang, D. Song, S. Chen, C. Zhang, and B. Wang, “Longllava: Scaling multi-modal llms to 1000 images efficiently via hybrid architecture,” 2024. [Online]. Available: https://arxiv.org/abs/2409.02889
arXiv 2024
-
[16]
Longvila: Scaling long-context visual language models for long videos,
F. Xue, Y . Chen, D. Li, Q. Hu, L. Zhu, X. Li, Y . Fang, H. Tang, S. Yang, Z. Liu, Y . He, H. Yin, P. Molchanov, J. Kautz, L. Fan, Y . Zhu, Y . Lu, and S. Han, “Longvila: Scaling long-context visual language models for long videos,”null, 2024
2024
-
[17]
Long context transfer from language to vision,
P. Zhang, K. Zhang, B. Li, G. Zeng, J. Yang, Y . Zhang, Z. Wang, H. Tan, C. Li, and Z. Liu, “Long context transfer from language to vision,”arXiv preprint arXiv:2406.16852, 2024
Pith/arXiv arXiv 2024
-
[18]
Momentor++: Advancing video large language models with fine-grained long video reasoning,
J. Li, M. Gao, X. He, S. Tang, W.-S. Zheng, J. Xiao, M. Wang, T.-S. Chua, and Y . Zhuang, “Momentor++: Advancing video large language models with fine-grained long video reasoning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 6, pp. 6208– 6224, 2026
2026
-
[19]
Selongvlm: Empowering long video language models with self-corrective clip selection,
K. Zhang, Z. Yang, M. Han, Y . Zhuge, H. Hao, C. Li, Z. Li, and X. Chang, “Selongvlm: Empowering long video language models with self-corrective clip selection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–16, 2026
2026
-
[20]
Ego-r1: Agentic chain-of-tool-thought for ultra- long egocentric video reasoning,
S. Tian, R. Wang, H. Guo, P. Wu, Y . Dong, X. Wang, J. Yang, H. Zhang, H. Zhu, and Z. Liu, “Ego-r1: Agentic chain-of-tool-thought for ultra- long egocentric video reasoning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–16, 2026
2026
-
[21]
Interaction methods for smart glasses: A survey,
L.-H. Lee and P. Hui, “Interaction methods for smart glasses: A survey,” IEEE access, vol. 6, pp. 28 712–28 732, 2018
2018
-
[22]
A head-mounted three dimensional display,
I. E. Sutherland, “A head-mounted three dimensional display,” in Proceedings of the December 9-11, 1968, fall joint computer conference, part I, 1968, pp. 757–764
1968
-
[23]
Horn,Robot vision
B. Horn,Robot vision. MIT press, 1986
1986
-
[24]
Videollm-online: Online video large language model for streaming video,
J. Chen, Z. Lv, S. Wu, K. Q. Lin, C. Song, D. Gao, J.-W. Liu, Z. Gao, D. Mao, and M. Z. Shou, “Videollm-online: Online video large language model for streaming video,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 407–18 418
2024
-
[25]
Videollm-mod: Efficient video-language streaming with mixture-of-depths vision computation,
S. Wu, J. Chen, K. Q. Lin, Q. Wang, Y . Gao, Q. Xu, T. Xu, Y . Hu, E. Chen, and M. Z. Shou, “Videollm-mod: Efficient video-language streaming with mixture-of-depths vision computation,”Advances in Neural Information Processing Systems, vol. 37, pp. 109 922–109 947, 2024
2024
-
[26]
Lion-fs: Fast & slow video-language thinker as online video assistant,
W. Li, B. Hu, R. Shao, L. Shen, and L. Nie, “Lion-fs: Fast & slow video-language thinker as online video assistant,”arXiv preprint arXiv:2503.03663, 2025
arXiv 2025
-
[27]
Streammind: Unlocking full frame rate streaming video dialogue through event-gated cognition,
X. Ding, H. Wu, Y . Yang, S. Jiang, D. Bai, Z. Chen, and T. Cao, “Streammind: Unlocking full frame rate streaming video dialogue through event-gated cognition,”arXiv preprint arXiv:2503.06220, 2025
arXiv 2025
-
[28]
Y . Wang, X. Meng, Y . Wang, J. Liang, J. Wei, H. Zhang, and D. Zhao, “Videollm knows when to speak: Enhancing time-sensitive video comprehension with video-text duet interaction format,”arXiv preprint arXiv:2411.17991, 2024
arXiv 2024
-
[29]
Streambridge: Turning your offline video large language model into a proactive streaming assistant,
H. Wang, B. Feng, Z. Lai, M. Xu, S. Li, W. Ge, A. Dehghan, M. Cao, and P. Huang, “Streambridge: Turning your offline video large language model into a proactive streaming assistant,”arXiv preprint arXiv:2505.05467, 2025
arXiv 2025
-
[30]
Streaming long video understanding with large language models,
R. Qian, X. Dong, P. Zhang, Y . Zang, S. Ding, D. Lin, and J. Wang, “Streaming long video understanding with large language models,” Advances in Neural Information Processing Systems, vol. 37, pp. 119 336–119 360, 2024
2024
-
[31]
Livestar: Live streaming assistant for real-world online video understanding,
Z. Yang, K. Zhang, Y . Hu, B. Wang, S. Qian, B. Wen, F. Yang, T. Gao, W. Dong, and C. Xu, “Livestar: Live streaming assistant for real-world online video understanding,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. [Online]. Available: https://openreview.net/forum?id=4n7IifN7yr
2025
-
[32]
Speakstream: Streaming text-to-speech with interleaved data,
R. H. Bai, Z. Gu, T. Likhomanenko, and N. Jaitly, “Speakstream: Streaming text-to-speech with interleaved data,”arXiv preprint arXiv:2505.19206, 2025
arXiv 2025
-
[33]
Soccernet: A scalable dataset for action spotting in soccer videos,
S. Giancola, M. Amine, T. Dghaily, and B. Ghanem, “Soccernet: A scalable dataset for action spotting in soccer videos,” inProceedings of the IEEE conference on computer vision and pattern recognition workshops, 2018, pp. 1711–1721
2018
-
[34]
Generating live soccer-match commentary from play data,
Y . Taniguchi, Y . Feng, H. Takamura, and M. Okumura, “Generating live soccer-match commentary from play data,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 01, 2019, pp. 7096–7103
2019
-
[35]
Sharegpt4video: Improving video understanding and generation with better captions,
L. Chen, X. Wei, J. Li, X. Dong, P. Zhang, Y . Zang, Z. Chen, H. Duan, Z. Tang, L. Yuanet al., “Sharegpt4video: Improving video understanding and generation with better captions,”Advances in Neural Information Processing Systems, vol. 37, pp. 19 472–19 495, 2024
2024
-
[36]
Pllava: Parameter-free llava extension from images to videos for video dense captioning,
L. Xu, Y . Zhao, D. Zhou, Z. Lin, S. K. Ng, and J. Feng, “Pllava: Parameter-free llava extension from images to videos for video dense captioning,”arXiv preprint arXiv:2404.16994, 2024
Pith/arXiv arXiv 2024
-
[37]
Video recap: Recursive captioning of hour-long videos,
M. M. Islam, N. Ho, X. Yang, T. Nagarajan, L. Torresani, and G. Bertasius, “Video recap: Recursive captioning of hour-long videos,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 198–18 208
2024
-
[38]
Llama 2: Open foundation and fine-tuned chat models,
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[39]
Gemini: a family of highly capable multimodal models,
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gemini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
Pith/arXiv arXiv 2023
-
[40]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[41]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
2022
-
[42]
Improving language understanding by generative pre-training,
A. Radford, K. Narasimhan, T. Salimans, I. Sutskeveret al., “Improving language understanding by generative pre-training,”Unknown, 2018
2018
-
[43]
Ldre: Llm-based divergent reasoning and ensemble for zero-shot composed image retrieval,
Z. Yang, D. Xue, S. Qian, W. Dong, and C. Xu, “Ldre: Llm-based divergent reasoning and ensemble for zero-shot composed image retrieval,” inProceedings of the 47th International ACM SIGIR conference on research and development in information retrieval, 2024, pp. 80–90
2024
-
[44]
Vila: On pre-training for visual language models,
J. Lin, H. Yin, W. Ping, P. Molchanov, M. Shoeybi, and S. Han, “Vila: On pre-training for visual language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 689–26 699
2024
-
[45]
Seman- tic editing increment benefits zero-shot composed image retrieval,
Z. Yang, S. Qian, D. Xue, J. Wu, F. Yang, W. Dong, and C. Xu, “Seman- tic editing increment benefits zero-shot composed image retrieval,” in Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 1245–1254
2024
-
[46]
Large language models are temporal and causal reasoners for video question answering,
D. Ko, J. S. Lee, W. Kang, B. Roh, and H. J. Kim, “Large language models are temporal and causal reasoners for video question answering,” arXiv preprint arXiv:2310.15747, 2023
arXiv 2023
-
[47]
Mvbench: A comprehensive multi-modal video understanding benchmark,
K. Li, Y . Wang, Y . He, Y . Li, Y . Wang, Y . Liu, Z. Wang, J. Xu, G. Chen, P. Luoet al., “Mvbench: A comprehensive multi-modal video understanding benchmark,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 22 195–22 206
2024
-
[48]
Videogpt+: Integrating image and video encoders for enhanced video understanding,
M. Maaz, H. Rasheed, S. Khan, and F. Khan, “Videogpt+: Integrating image and video encoders for enhanced video understanding,”arXiv preprint arXiv:2406.09418, 2024
arXiv 2024
-
[49]
Llava-next: A strong zero-shot video understanding model,
Y . Zhang, B. Li, h. Liu, Y . j. Lee, L. Gui, D. Fu, J. Feng, Z. Liu, and C. Li, “Llava-next: A strong zero-shot video understanding model,” April 2024. [Online]. Available: https: //llava-vl.github.io/blog/2024-04-30-llava-next-video/
2024
-
[50]
Learning to answer visual questions from web videos,
A. Yang, A. Miech, J. Sivic, I. Laptev, and C. Schmid, “Learning to answer visual questions from web videos,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 5, pp. 3202–3218, 2025
2025
-
[51]
Transformer-empowered invariant grounding for video question answering,
Y . Li, X. Wang, J. Xiao, W. Ji, and T.-S. Chua, “Transformer-empowered invariant grounding for video question answering,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 11, pp. 9510–9522, 2025
2025
-
[52]
Intentqa: Intent question answering in videos by cognitive context reasoning,
J. Li, P. Wei, W. Han, S.-C. Zhu, and L. Fan, “Intentqa: Intent question answering in videos by cognitive context reasoning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–18, 2026. PREPRINT, 2026 16
2026
-
[53]
Parse, align and aggregate: Graph-driven compositional reasoning for video question answering,
J. Li, Z. Liao, F. Xiao, T. Li, Q. Zhang, H. Zhao, L. Niu, G. Chen, L. Zhang, and C. Jiang, “Parse, align and aggregate: Graph-driven compositional reasoning for video question answering,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, vol. 48, no. 5, pp. 5586–5603, 2026
2026
-
[54]
Mecd+: Unlocking event-level causal graph discovery for video reasoning,
T. Chen, H. Liu, Y . Wang, Y . Chen, T. He, C. Gan, H. He, and W. Lin, “Mecd+: Unlocking event-level causal graph discovery for video reasoning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 3, pp. 2628–2645, 2026
2026
-
[55]
Adversa: Abductive driving accident video understanding,
L.-L. Li, J. Fang, J. Xiao, H. Yu, C. Lv, J. Xue, Z. Li, and T.-S. Chua, “Adversa: Abductive driving accident video understanding,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 6, pp. 6980–6998, 2026
2026
-
[56]
Moviechat+: Question-aware sparse memory for long video question answering,
E. Song, W. Chai, T. Ye, J.-N. Hwang, X. Li, and G. Wang, “Moviechat+: Question-aware sparse memory for long video question answering,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 1, pp. 374–389, 2026
2026
-
[57]
Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding,
Y . Guo, J. Liu, M. Li, D. Cheng, X. Tang, D. Sui, Q. Liu, X. Chen, and K. Zhao, “Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 3, 2025, pp. 3302–3310
2025
-
[58]
Vtg-gpt: Tuning-free zero- shot video temporal grounding with gpt,
Y . Xu, Y . Sun, Z. Xie, B. Zhai, and S. Du, “Vtg-gpt: Tuning-free zero- shot video temporal grounding with gpt,”Applied Sciences, vol. 14, no. 5, p. 1894, 2024
2024
-
[59]
Hawkeye: Training video-text llms for grounding text in videos,
Y . Wang, X. Meng, J. Liang, Y . Wang, Q. Liu, and D. Zhao, “Hawkeye: Training video-text llms for grounding text in videos,”arXiv preprint arXiv:2403.10228, 2024
arXiv 2024
-
[60]
A survey on video temporal grounding with multimodal large language model,
J. Wu, W. Liu, Y . Liu, M. Liu, L. Nie, Z. Lin, and C. W. Chen, “A survey on video temporal grounding with multimodal large language model,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 2, pp. 1521–1541, 2026
2026
-
[61]
The dawn of lmms: Preliminary explorations with gpt-4v (ision),
Z. Yang, L. Li, K. Lin, J. Wang, C.-C. Lin, Z. Liu, and L. Wang, “The dawn of lmms: Preliminary explorations with gpt-4v (ision),”arXiv preprint arXiv:2309.17421, vol. 9, no. 1, p. 1, 2023
Pith/arXiv arXiv 2023
-
[62]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosenet al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[64]
Valor: Vision-audio-language omni-perception pretraining model and dataset,
J. Liu, S. Chen, X. He, L. Guo, X. Zhu, W. Wang, and J. Tang, “Valor: Vision-audio-language omni-perception pretraining model and dataset,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 2, pp. 708–724, 2025
2025
-
[65]
Cap4video++: Enhancing video understanding with auxiliary captions,
W. Wu, X. Wang, H. Luo, J. Wang, Y . Yang, and W. Ouyang, “Cap4video++: Enhancing video understanding with auxiliary captions,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 7, pp. 5223–5237, 2025
2025
-
[66]
Hierarchical banzhaf interaction for general video-language representation learning,
P. Jin, H. Li, L. Yuan, S. Yan, and J. Chen, “Hierarchical banzhaf interaction for general video-language representation learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 3, pp. 2125–2139, 2025
2025
-
[67]
Video dataflywheel: Resolving the impossible data trinity in video-language understanding,
X. Wang, J. Wu, Z. Lin, F. Zhang, D. Zhang, and L. Nie, “Video dataflywheel: Resolving the impossible data trinity in video-language understanding,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 4, pp. 2912–2923, 2025
2025
-
[68]
Video-llava: Learning united visual representation by alignment before projection,
B. Lin, B. Zhu, Y . Ye, M. Ning, P. Jin, and L. Yuan, “Video-llava: Learning united visual representation by alignment before projection,” arXiv preprint arXiv:2311.10122, 2023
Pith/arXiv arXiv 2023
-
[69]
Streaming dense video captioning,
X. Zhou, A. Arnab, S. Buch, S. Yan, A. Myers, X. Xiong, A. Nagrani, and C. Schmid, “Streaming dense video captioning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 243–18 252
2024
-
[70]
Streaming video understanding and multi-round interaction with memory-enhanced knowledge,
H. Xiong, Z. Yang, J. Yu, Y . Zhuge, L. Zhang, J. Zhu, and H. Lu, “Streaming video understanding and multi-round interaction with memory-enhanced knowledge,”arXiv preprint arXiv:2501.13468, 2025
arXiv 2025
-
[71]
Merlot reserve: Neural script knowledge through vision and language and sound,
R. Zellers, J. Lu, X. Lu, Y . Yu, Y . Zhao, M. Salehi, A. Kusupati, J. Hessel, A. Farhadi, and Y . Choi, “Merlot reserve: Neural script knowledge through vision and language and sound,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 375–16 387
2022
-
[72]
J. Gao, Y . Lian, Z. Zhou, Y . Fu, and B. Wang, “Livechat: A large- scale personalized dialogue dataset automatically constructed from live streaming,”arXiv preprint arXiv:2306.08401, 2023
arXiv 2023
-
[73]
Ego4d: Around the world in 3,000 hours of egocentric video,
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liuet al., “Ego4d: Around the world in 3,000 hours of egocentric video,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18 995–19 012
2022
-
[74]
Vispeak: Visual instruction feedback in streaming videos,
S. Fu, Q. Yang, Y .-M. Li, Y .-X. Peng, K.-Y . Lin, X. Wei, J.-F. Hu, X. Xie, and W.-S. Zheng, “Vispeak: Visual instruction feedback in streaming videos,”arXiv preprint arXiv:2503.12769, 2025
arXiv 2025
-
[75]
Open-ended hierarchical streaming video understanding with vision language models,
H. Kang, Y . Park, Y . Yoo, Y . Choi, and S. J. Kim, “Open-ended hierarchical streaming video understanding with vision language models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 20 715–20 725
2025
-
[76]
Streamagent: Towards anticipatory agents for streaming video understanding,
H. Yang, F. Tang, L. Zhao, X. An, M. Hu, H. Li, X. Zhuang, Y . Lu, X. Zhang, A. Swikiret al., “Streamagent: Towards anticipatory agents for streaming video understanding,”arXiv preprint arXiv:2508.01875, 2025
Pith/arXiv arXiv 2025
-
[77]
Learning to respond: A large-scale benchmark and progressive learning framework for trigger-centric online video understanding
J. Qian, H. Du, G. Nan, S. Huang, J. Yu, H. Wang, J. Chen, M. Cai, M. Yang, J. Liet al., “Learning to respond: A large-scale benchmark and progressive learning framework for trigger-centric online video understanding.”
-
[78]
Egospeak: learning when to speak for egocentric conversational agents in the wild,
J. Kim, M.-S. Kim, J. Chung, J. Cho, J. Kim, S. Kim, G. Sim, and Y . Yu, “Egospeak: learning when to speak for egocentric conversational agents in the wild,” inFindings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 2990–3005
2025
-
[79]
Streamlined dense video captioning,
J. Mun, L. Yang, Z. Ren, N. Xu, and B. Han, “Streamlined dense video captioning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 6588–6597
2019
-
[80]
Proact-vl: A proactive videollm for real-time ai companions,
W. Yan, Y . Dai, Q. Ran, H. Li, W. Lin, H. Liao, X. Xie, T. Jin, and J. Lian, “Proact-vl: A proactive videollm for real-time ai companions,” arXiv preprint arXiv:2603.03447, 2026
Pith/arXiv arXiv 2026
-
[81]
Streamready: Learning what to answer and when in long streaming videos,
S. Azad, V . Vineet, and Y . S. Rawat, “Streamready: Learning what to answer and when in long streaming videos,”arXiv preprint arXiv:2603.08620, 2026
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.