Speech Meets ELF: Audio Conditional Continuous-Target Diffusion for Speech Recognition and Translation
Pith reviewed 2026-06-27 12:01 UTC · model grok-4.3
The pith
Continuous-target diffusion models unify speech recognition and translation by tracing both errors to close-distance confusion in latent space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
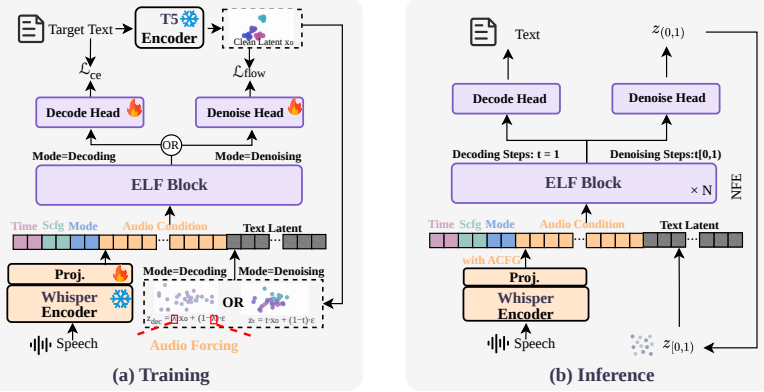
ELF-S2T prepends audio-conditioned vectors to noisy text latents and performs flow-matching denoising inside the pre-trained continuous representation space. Audio forcing during training plus classifier-free guidance at inference keep the model from ignoring the speech input. Experiments on LibriSpeech and CoVoST2 yield competitive word-error and BLEU scores. Error analysis then shows that mistakes in both tasks arise from the same mechanism: close-distance confusion between points in the continuous latent space, indicating a common semantic mapping beneath recognition and translation.
What carries the argument
Audio-conditioned flow-matching denoising of continuous text latents, driven by a linear projector on frozen Whisper features and enforced by audio forcing plus classifier-free guidance.
If this is right
- The same model architecture reaches competitive accuracy on both ASR and S2TT benchmarks.
- Errors in the two tasks share a single root: close-distance confusion inside the continuous latent space.
- The continuous generation paradigm aligns with one semantic mapping process that serves both recognition and translation.
- Audio forcing and classifier-free guidance successfully shift reliance from text pre-training to the audio condition.
Where Pith is reading between the lines
- Methods that explicitly enlarge distances between nearby latent points could reduce errors across both tasks at once.
- The same conditioning pattern might transfer to other speech tasks that map audio to semantic output.
- Testing whether discrete-token models show analogous shared error patterns would clarify whether the finding is specific to continuous spaces.
Load-bearing premise
The pre-trained text backbone plus one linear audio projector, audio forcing, and classifier-free guidance together suffice to make the model depend on the speech input rather than defaulting to its text-only training.
What would settle it
If error analysis after training shows that ASR and S2TT mistakes arise from qualitatively different causes in the latent space, or if removing audio forcing leaves performance unchanged, the shared-cause claim would not hold.
Figures

read the original abstract
Speech-to-text (S2T) systems for recognition (ASR) and translation (S2TT) typically generate discrete text tokens. In contrast, continuous-target language modelling performs generation in a continuous space, yet its potential for S2T remains unexplored. To bridge this gap, we propose ELF-S2T, an audio-conditioned continuous-target generative model for S2T. Built upon the pre-trained Embedded Language Flows (ELF) backbone, ELF-S2T processes speech via a frozen Whisper encoder and a single linear projector, prepending the resulting audio condition to the noisy text latent for in-context, flow-matching denoising. To prevent the model from over-relying on its pre-trained text context, we introduce audio forcing during training, and further amplify the audio condition via classifier-free guidance at inference. Experiments on LibriSpeech and CoVoST2 show that ELF-S2T achieves competitive ASR and S2TT performance. Crucially, our error analysis reveals that, although ASR and S2TT errors look very different on the surface, both stem from the same underlying cause, a close distance confusion in the continuous latent space. This finding naturally aligns with the continuous representation generation paradigm, indicating a common semantic mapping process beneath recognition and translation. Our code and pretrained models are publicly available at https://github.com/Sslnon/ELF-S2T.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ELF-S2T, an audio-conditioned continuous-target generative model for speech recognition (ASR) and speech-to-text translation (S2TT). It builds on the pre-trained Embedded Language Flows (ELF) backbone, conditions on speech via a frozen Whisper encoder plus single linear projector prepended to noisy text latents, and employs flow-matching denoising with audio forcing during training and classifier-free guidance at inference. Experiments on LibriSpeech and CoVoST2 are reported to achieve competitive performance; error analysis concludes that surface-different ASR and S2TT errors share the same root cause of close-distance confusion in the continuous latent space, implying a common semantic mapping process.
Significance. If the performance claims and error analysis hold after verification that the model relies on audio conditioning, the work would indicate that continuous-target diffusion can unify ASR and S2TT under a shared latent-space mechanism, extending the continuous representation paradigm beyond discrete-token approaches. Public release of code and pretrained models is a clear strength supporting reproducibility.
major comments (2)
- [Abstract and §3] Abstract and §3 (architecture/training): The central claim that ASR/S2TT errors arise from close-distance confusion inside an audio-conditioned continuous latent space (rather than the text prior) is load-bearing on the model actually using the Whisper+linear audio condition. The description of prepending the projector output, audio forcing, and CFG does not include ablations (e.g., WER/BLEU drop or error-pattern change when audio input is removed or replaced by noise) or diagnostics (attention maps, conditioning strength metrics) showing that these mechanisms override the ELF text backbone. Without such evidence the error analysis cannot substantiate the claimed audio-driven shared semantic mapping.
- [§4] §4 (experiments): The abstract states 'competitive' performance on LibriSpeech and CoVoST2 yet supplies no WER, BLEU, baseline tables, statistical significance, or description of the error-analysis procedure. If these details exist later in the manuscript they must be explicitly cross-referenced to the abstract claim; otherwise the quantitative support for both the performance and the error-cause conclusion remains unverifiable.
minor comments (1)
- [§3] Notation for the linear projector and the exact form of the audio-forcing loss should be defined with an equation in §3 to avoid ambiguity when readers attempt to reproduce the conditioning mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important points for strengthening the claims regarding audio conditioning and quantitative support. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications and additions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (architecture/training): The central claim that ASR/S2TT errors arise from close-distance confusion inside an audio-conditioned continuous latent space (rather than the text prior) is load-bearing on the model actually using the Whisper+linear audio condition. The description of prepending the projector output, audio forcing, and CFG does not include ablations (e.g., WER/BLEU drop or error-pattern change when audio input is removed or replaced by noise) or diagnostics (attention maps, conditioning strength metrics) showing that these mechanisms override the ELF text backbone. Without such evidence the error analysis cannot substantiate the claimed audio-driven shared semantic mapping.
Authors: We agree that the error analysis claim requires explicit evidence that the audio conditioning is actively used rather than being overridden by the pre-trained ELF text backbone. The manuscript describes the Whisper encoder, linear projector, prepending mechanism, audio forcing during training, and classifier-free guidance at inference as the means to incorporate audio. However, we acknowledge that no ablations or conditioning diagnostics are currently included. In the revised manuscript, we will add ablations (e.g., performance and error-pattern changes when audio is removed or replaced by noise) and any feasible diagnostics to demonstrate that the audio condition drives the shared semantic mapping. revision: yes
-
Referee: [§4] §4 (experiments): The abstract states 'competitive' performance on LibriSpeech and CoVoST2 yet supplies no WER, BLEU, baseline tables, statistical significance, or description of the error-analysis procedure. If these details exist later in the manuscript they must be explicitly cross-referenced to the abstract claim; otherwise the quantitative support for both the performance and the error-cause conclusion remains unverifiable.
Authors: The quantitative results (WER/BLEU scores, baselines, statistical details) and the error-analysis procedure are presented in §4. We agree that the abstract claim would benefit from explicit cross-references to these sections. In the revision, we will add direct references from the abstract to the relevant parts of §4 to ensure the support for competitive performance and the error analysis is immediately verifiable. revision: yes
Circularity Check
Empirical error analysis on public benchmarks exhibits no circular reduction
full rationale
The paper constructs ELF-S2T by prepending a linear projection of frozen Whisper features to noisy ELF text latents and applies audio forcing plus CFG to encourage audio conditioning. The central claim—that ASR and S2TT errors share a close-distance confusion cause in continuous latent space—is obtained from post-training error inspection on LibriSpeech and CoVoST2 outputs rather than any equation that equates a reported quantity to a fitted parameter or prior self-citation. No self-definitional loop, fitted-input prediction, or load-bearing uniqueness theorem appears in the architecture or analysis; the derivation chain therefore remains independent of its own outputs and is validated against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow-matching denoising can be applied to continuous text latents when conditioned on audio embeddings from a separate encoder.
Forward citations
Cited by 1 Pith paper
-
Continuous Language Diffusion as a Decoder-Interface Problem
Continuous language diffusion works by entering high-margin decoder basins where frozen T5 embeddings recover 93-96% of native decisions and linear readouts reach 97.9% agreement, implying models should be evaluated a...
Reference graph
Works this paper leans on
-
[1]
D.; Ho, J.; Tarlow, D.; and van den Berg, R
Austin, J.; Johnson, D. D.; Ho, J.; Tarlow, D.; and van den Berg, R. 2021. Structured denoising diffusion models in discrete state-spaces. In Proceedings of the 35th International Conference on Neural Information Processing Systems, NIPS '21. Red Hook, NY, USA: Curran Associates Inc. ISBN 9781713845393
2021
-
[2]
Baas, M.; Eloff, K.; and Kamper, H. 2022. TransFusion: Transcribing Speech with Multinomial Diffusion. arXiv:2210.07677
arXiv 2022
-
[3]
Fathullah, Y.; Wu, C.; Lakomkin, E.; Jia, J.; Shangguan, Y.; Li, K.; Guo, J.; Xiong, W.; Mahadeokar, J.; Kalinli, O.; Fuegen, C.; and Seltzer, M. 2023. Prompting Large Language Models with Speech Recognition Abilities. arXiv:2307.11795
arXiv 2023
-
[4]
Guo, H.; Zhao, Q.; Zhao, Y.; Nie, S.; Zhu, R.; Guo, Q.; Wang, F.; Yang, T.; Zhao, H.; Wei, G.; and Zeng, Y. 2026. Continuous Latent Diffusion Language Model. arXiv:2605.06548
Pith/arXiv arXiv 2026
-
[5]
Ho, J.; and Salimans, T. 2022. Classifier-Free Diffusion Guidance. arXiv:2207.12598
Pith/arXiv arXiv 2022
-
[6]
Hu, K.; Qiu, L.; Lu, Y.; Zhao, H.; Li, T.; Kim, Y.; Andreas, J.; and He, K. 2026. ELF: Embedded Language Flows. arXiv:2605.10938
Pith/arXiv arXiv 2026
-
[7]
Kwon, T.; Ahn, J.; Yun, T.; Jwa, H.; Choi, Y.; Park, S.; Kim, N.-J.; Kim, J.; Ryu, H. G.; and Lee, H.-J. 2025. Whisfusion: Parallel ASR Decoding via a Diffusion Transformer. arXiv:2508.07048
Pith/arXiv arXiv 2025
-
[8]
Leng, S.; Xing, Y.; Cheng, Z.; Zhou, Y.; Zhang, H.; Li, X.; Zhao, D.; Lu, S.; Miao, C.; and Bing, L. 2024. The Curse of Multi-Modalities: Evaluating Hallucinations of Large Multimodal Models across Language, Visual, and Audio. arXiv:2410.12787
arXiv 2024
-
[9]
Lipman, Y.; Chen, R. T. Q.; Ben-Hamu, H.; Nickel, M.; and Le, M. 2023. Flow Matching for Generative Modeling. arXiv:2210.02747
Pith/arXiv arXiv 2023
-
[10]
Lou, A.; Meng, C.; and Ermon, S. 2024. Discrete diffusion modeling by estimating the ratios of the data distribution. In Proceedings of the 41st International Conference on Machine Learning, ICML'24. JMLR.org
2024
-
[11]
Ma, Z.; Yang, G.; Yang, Y.; Gao, Z.; Wang, J.; Du, Z.; Yu, F.; Chen, Q.; Zheng, S.; Zhang, S.; and Chen, X. 2024. An Embarrassingly Simple Approach for LLM with Strong ASR Capacity. arXiv:2402.08846
arXiv 2024
-
[12]
Ma, Z.; Yang, G.; Yang, Y.; Gao, Z.; Wang, J.; Du, Z.; Yu, F.; Chen, Q.; Zheng, S.; Zhang, S.; and Chen, X. 2025. Speech recognition meets large language model: benchmarking, models, and exploration. In Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intellig...
2025
-
[13]
Panayotov, V.; Chen, G.; Povey, D.; and Khudanpur, S. 2015. Librispeech: An ASR corpus based on public domain audio books. 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5206--5210
2015
-
[14]
W.; Xu, T.; Brockman, G.; McLeavey, C.; and Sutskever, I
Radford, A.; Kim, J. W.; Xu, T.; Brockman, G.; McLeavey, C.; and Sutskever, I. 2022. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv:2212.04356
Pith/arXiv arXiv 2022
-
[15]
Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; and Liu, P. J. 2023. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv:1910.10683
Pith/arXiv arXiv 2023
-
[16]
S.; Arriola, M.; Schiff, Y.; Gokaslan, A.; Marroquin, E.; Chiu, J
Sahoo, S. S.; Arriola, M.; Schiff, Y.; Gokaslan, A.; Marroquin, E.; Chiu, J. T.; Rush, A.; and Kuleshov, V. 2024. Simple and effective masked diffusion language models. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS '24. Red Hook, NY, USA: Curran Associates Inc. ISBN 9798331314385
2024
-
[17]
Seamless Communication ; Barrault, L.; et al. 2023. SeamlessM4T: Massively Multilingual & Multimodal Machine Translation. arXiv:2308.11596
arXiv 2023
-
[18]
Tang, C.; Yu, W.; Sun, G.; Chen, X.; Tan, T.; Li, W.; Lu, L.; Ma, Z.; and Zhang, C. 2024. SALMONN: Towards Generic Hearing Abilities for Large Language Models. In The Twelfth International Conference on Learning Representations
2024
-
[19]
Wang, C.; Wu, A.; and Pino, J. 2020. CoVoST 2 and Massively Multilingual Speech-to-Text Translation. arXiv:2007.10310
arXiv 2020
-
[20]
Wang, D.; Li, J.; Cui, M.; Yang, D.; Chen, X.; and Meng, H. 2025. Speech Discrete Tokens or Continuous Features? A Comparative Analysis for Spoken Language Understanding in SpeechLLMs. arXiv:2508.17863
arXiv 2025
-
[21]
Wu, H.; Tang, M.; Zheng, X.; and Jiang, H. 2025. When Language Overrules: Revealing Text Dominance in Multimodal Large Language Models. arXiv:2508.10552
arXiv 2025
-
[22]
Xu, J.; Guo, Z.; He, J.; Hu, H.; He, T.; Bai, S.; Chen, K.; Wang, J.; Fan, Y.; Dang, K.; Zhang, B.; Wang, X.; Chu, Y.; and Lin, J. 2025 a . Qwen2.5-Omni Technical Report. arXiv:2503.20215
Pith/arXiv arXiv 2025
-
[23]
Xu, J.; Guo, Z.; Hu, H.; Chu, Y.; Wang, X.; He, J.; Wang, Y.; Shi, X.; He, T.; Zhu, X.; Lv, Y.; Wang, Y.; Guo, D.; Wang, H.; Ma, L.; Zhang, P.; Zhang, X.; Hao, H.; Guo, Z.; Yang, B.; Zhang, B.; Ma, Z.; Wei, X.; Bai, S.; Chen, K.; Liu, X.; Wang, P.; Yang, M.; Liu, D.; Ren, X.; Zheng, B.; Men, R.; Zhou, F.; Yu, B.; Yang, J.; Yu, L.; Zhou, J.; and Lin, J. 20...
Pith/arXiv arXiv 2025
-
[24]
Xu, Y.; Zhang, S.-X.; Yu, J.; Wu, Z.; and Yu, D. 2024. Comparing Discrete and Continuous Space LLMs for Speech Recognition. arXiv:2409.00800
arXiv 2024
-
[25]
Yu, W.; Tang, C.; Sun, G.; Chen, X.; Tan, T.; Li, W.; Lu, L.; Ma, Z.; and Zhang, C. 2023. Connecting Speech Encoder and Large Language Model for ASR. arXiv:2309.13963
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.