ContextCodec: Content-Focused Context Guidance for Ultra-Low Bitrate Speech Coding
Pith reviewed 2026-06-27 11:49 UTC · model grok-4.3
The pith
ContextCodec transmits phoneme-aligned context features to explicitly guide speech reconstruction at bitrates down to 500 bps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
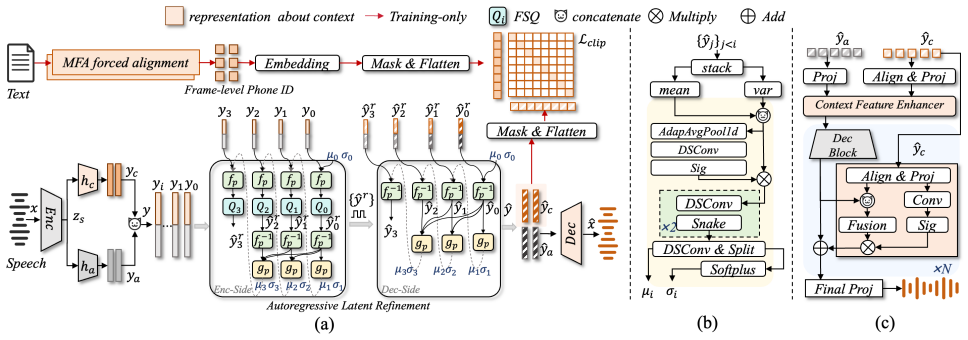
ContextCodec adopts a dual-branch encoder that decouples acoustic details from content-focused context. The context branch is trained with a CLIP-style contrastive loss that aligns context features with phoneme indices, reducing paralinguistic leakage. During decoding, these features are injected at each decoding stage for explicit guidance, together with a lightweight autoregressive latent refinement module.
What carries the argument
dual-branch encoder whose context branch is aligned to phoneme indices via contrastive loss and injected at every decoder stage for explicit guidance
If this is right
- Speech remains intelligible at 500 bps where prior codecs lose the linguistic message.
- Context injection at multiple decoder stages supplies explicit guidance that acoustic-only features cannot provide.
- Contrastive alignment to phoneme indices limits leakage of speaker or prosody information into the transmitted context.
- The added autoregressive refinement module improves latent quality without exceeding the bitrate budget.
- Real-time factor of 0.4886 is achieved on a typical mobile CPU.
Where Pith is reading between the lines
- The same content-context separation might apply to other low-bitrate audio tasks such as music or environmental sound coding if suitable discrete units replace phonemes.
- Explicit context guidance could be added to existing neural codecs to extend their usable bitrate range downward without retraining the entire model.
- If the contrastive alignment generalizes across languages, the approach may support multilingual ultra-low-bitrate communication with minimal additional data.
Load-bearing premise
The dual-branch encoder successfully separates acoustic details from content context and the contrastive loss on phoneme indices reduces paralinguistic leakage enough for the guidance to work.
What would settle it
Reconstruction at 500 bps shows no measurable gain in word error rate or mean opinion score compared with a single-branch baseline that uses the same total bitrate.
Figures

read the original abstract
Neural speech codecs enable low-bitrate speech communication, yet at ultra-low bitrates (< 1000 bps) preserving perceptual quality and intelligibility is challenging. Existing designs often prioritize acoustic details, leaving limited capacity for the core linguistic message under tight bitrate constraints. To address this, we propose ContextCodec, a codec that transmits content-focused context features to explicitly guide reconstruction. ContextCodec adopts a dual-branch encoder that decouples acoustic details from content-focused context. The context branch is trained with a CLIP-style contrastive loss that aligns context features with phoneme indices, reducing paralinguistic leakage. During decoding, these features are injected at each decoding stage for explicit guidance. In addition, we introduce a lightweight autoregressive latent refinement module. Experiments show a strong quality-intelligibility trade-off down to 500 bps, with an RTF of 0.4886 on a typical mobile CPU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ContextCodec, a neural speech codec for ultra-low bitrates (<1000 bps) that uses a dual-branch encoder to decouple acoustic details from content-focused context. The context branch is trained with a CLIP-style contrastive loss aligning features to phoneme indices to reduce paralinguistic leakage; these features are explicitly injected at each decoding stage, augmented by a lightweight autoregressive latent refinement module. The central claim is a strong quality-intelligibility trade-off down to 500 bps with RTF of 0.4886 on a typical mobile CPU.
Significance. If the empirical results hold under rigorous evaluation, the explicit content-guidance mechanism via contrastive alignment could advance ultra-low-bitrate codecs by reallocating limited capacity toward linguistic content rather than acoustic fidelity. This is a targeted application of cross-modal contrastive techniques to speech coding.
major comments (1)
- [Abstract] Abstract: the claim that 'Experiments show a strong quality-intelligibility trade-off down to 500 bps' is presented without any quantitative metrics, baselines, error bars, dataset details, or ablation results. This is load-bearing for the central claim because the validity of the reported trade-off and the dual-branch decoupling cannot be assessed from the given text.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of the work's potential contribution and for the detailed feedback. We address the single major comment on the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Experiments show a strong quality-intelligibility trade-off down to 500 bps' is presented without any quantitative metrics, baselines, error bars, dataset details, or ablation results. This is load-bearing for the central claim because the validity of the reported trade-off and the dual-branch decoupling cannot be assessed from the given text.
Authors: We agree that the abstract, as a standalone summary, would benefit from including a small number of concrete quantitative indicators to substantiate the central claim. In the revised version we will expand the final sentence of the abstract to report key metrics (e.g., PESQ and STOI improvements relative to the strongest baseline at 500 bps) together with the dataset used for the main results. The full experimental protocol, including error bars, ablation studies, and dataset details, is already contained in Sections 4 and 5; the abstract revision will simply surface the most salient numbers without altering the paper's technical content. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript text (abstract plus full description) presents an architectural proposal using a dual-branch encoder and a standard CLIP-style contrastive loss on phoneme indices. No equations, derivations, or first-principles claims appear. No parameter is fitted to a subset and then renamed as a prediction; no self-citation chain is invoked to justify uniqueness; no ansatz is smuggled via prior work; and no known result is merely renamed. The central claims rest on empirical trade-offs at low bitrates rather than any reduction to inputs by construction. This is the normal case of a self-contained empirical architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
They are widely used in audio tokenization [1, 2, 3] and telecommunications applica- tions [4, 5]
Introduction Neural speech codecs (NSC) aim to convert continuous speech signals into compact discrete representations while preserving perceptual quality and intelligibility. They are widely used in audio tokenization [1, 2, 3] and telecommunications applica- tions [4, 5]. As speech communication is increasingly deployed in bandwidth-constrained environm...
-
[2]
We propose ContextCodec, a content-first neural speech codec designed for ultra-low-bitrate communication, which ex- plicitly prioritizes linguistic content through decoupled acous- tic and context modeling and a CLIP (Contrastive Language– Image Pretraining)-style linguistic alignment objective
-
[3]
We design a context-guided attention decoder that preserves contextual guidance under tight bitrate constraints through acoustic pre-conditioning and stage-wise context in- jection, complemented by a lightweight autoregressive latent refinement module that improves reconstruction quality before waveform generation
-
[4]
Extensive objective and subjective evaluations demonstrate that ContextCodec achieves a favorable qual- arXiv:2606.10591v1 [cs.SD] 9 Jun 2026 Figure 2:Overview of ContextCodec. (a) The end-to-end pipeline. (b) The predictorg p. (c) The context-guided attention decoder. ity–intelligibility trade-off down to 500 bps with a real-time factor (RTF) of 0.4886 o...
Pith/arXiv arXiv 2026
-
[5]
The base blocks of the shared encoder, decoder, and multiple dis- criminators follow the same architectural settings as DAC [10]
Design of ContextCodec ContextCodec is built upon a GAN-based quantized autoen- coder framework with finite scalar quantization (FSQ) [28]. The base blocks of the shared encoder, decoder, and multiple dis- criminators follow the same architectural settings as DAC [10]. 2.1. Overall architecture As shown in Figure 2(a), ContextCodec maps an input wave- for...
-
[6]
Experiments 3.1. Experimental setup Datasets and preprocessing.ContextCodec is trained on the training sets of LibriTTS [31] and AISHELL-3 [32]. To ob- tain frame-level supervision for alignment, we run an offline forced-alignment pipeline using MFA 1 to produce phoneme- level TextGrids [33]. We then convert phoneme time intervals 1https://montreal-forced...
arXiv 2000
-
[7]
Conclusion We propose ContextCodec, a context-guided neural speech codec for ultra-low bitrate speech communication. By prioritiz- ing content preservation and using context as an explicit guid- ance signal during decoding, ContextCodec achieves a strong balance between intelligibility and perceptual quality at bitrates down to 500 bps. Extensive objectiv...
-
[8]
2023YFB2904300, the National Natural Science Foundation of China under Grant No
Acknowledgements This work is supported by the National Key Research and Development Program of China under Grant No. 2023YFB2904300, the National Natural Science Foundation of China under Grant No. 62293484, and Beijing Natural Science Foundation (F251001)
-
[9]
All technical con- tent, experimental results, and final wording were verified and approved by the authors
Generative AI Use Disclosure We used generative AI tools (GPT-5.2) to assist with English polishing and LATEX formatting suggestions. All technical con- tent, experimental results, and final wording were verified and approved by the authors
-
[10]
Audiolm: a language modeling approach to audio gener- ation,
Z. Borsos, R. Marinier, D. Vincent, E. Kharitonov, O. Pietquin, M. Sharifi, D. Roblek, O. Teboul, D. Grangier, M. Tagliasacchi et al., “Audiolm: a language modeling approach to audio gener- ation,”IEEE/ACM transactions on audio, speech, and language processing, vol. 31, pp. 2523–2533, 2023
2023
-
[11]
Freecodec: A disentangled neural speech codec with fewer tokens,
Y . Zheng, W. Tu, Y . Kang, J. Chen, Y . Zhang, L. Xiao, Y . Yang, and L. Ma, “Freecodec: A disentangled neural speech codec with fewer tokens,” inProc. Interspeech 2025, 2025, pp. 4878–4882
2025
-
[12]
H. Hu, X. Zhu, T. He, D. Guo, B. Zhang, X. Wang, Z. Guo, Z. Jiang, H. Hao, Z. Guo, X. Zhang, P. Zhang, B. Yang, J. Xu, J. Zhou, and J. Lin, “Qwen3-tts technical report,”arXiv preprint arXiv:2601.15621, 2026
Pith/arXiv arXiv 2026
-
[13]
Generative speech coding with predictive variance regularization,
W. B. Kleijn, A. Storus, M. Chinen, T. Denton, F. S. Lim, A. Luebs, J. Skoglund, and H. Yeh, “Generative speech coding with predictive variance regularization,” inICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6478–6482
2021
-
[14]
Lpcnet: Improving neural speech synthesis through linear prediction,
J.-M. Valin and J. Skoglund, “Lpcnet: Improving neural speech synthesis through linear prediction,” inICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2019, pp. 5891–5895
2019
-
[15]
Lsp- net: an ultra-low bitrate hybrid neural codec,
B. Zhang, I. McLoughlin, X. Miao, and A. Madhukumar, “Lsp- net: an ultra-low bitrate hybrid neural codec,” inProc. Interspeech 2025, 2025, pp. 614–618
2025
-
[16]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 30, pp. 495–507, 2021
2021
-
[17]
Generative adver- sarial nets,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde- Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adver- sarial nets,”Advances in neural information processing systems, vol. 27, 2014
2014
-
[18]
Srcodec: Split-residual vector quantization for neural speech codec,
Y . Zheng, W. Tu, L. Xiao, and X. Xu, “Srcodec: Split-residual vector quantization for neural speech codec,” inICASSP 2024- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 451–455
2024
-
[19]
High-fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved rvqgan,”Ad- vances in Neural Information Processing Systems, vol. 36, pp. 27 980–27 993, 2023
2023
-
[20]
Snac: Multi- scale neural audio codec,
H. Siuzdak, F. Gr ¨otschla, and L. A. Lanzend ¨orfer, “Snac: Multi- scale neural audio codec,” inAudio Imagination: NeurIPS 2024 Workshop AI-Driven Speech, Music, and Sound Generation
2024
-
[21]
Hifi- codec: Group-residual vector quantization for high fidelity audio codec,
D. Yang, S. Liu, R. Huang, J. Tian, C. Weng, and Y . Zou, “Hifi- codec: Group-residual vector quantization for high fidelity audio codec,”arXiv preprint arXiv:2305.02765, 2023
arXiv 2023
-
[22]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”arXiv preprint arXiv:2210.13438, 2022
Pith/arXiv arXiv 2022
-
[23]
Lightcodec: A high fidelity neural audio codec with low computation complexity,
L. Xu, J. Wang, J. Zhang, and X. Xie, “Lightcodec: A high fidelity neural audio codec with low computation complexity,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 586–590
2024
-
[24]
Wavlm: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “Wavlm: Large-scale self- supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[25]
Hubert: Self-supervised speech represen- tation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdi- nov, and A. Mohamed, “Hubert: Self-supervised speech represen- tation learning by masked prediction of hidden units,”IEEE/ACM transactions on audio, speech, and language processing, vol. 29, pp. 3451–3460, 2021
2021
-
[26]
wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations,”Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020
2020
-
[27]
Codec does matter: Exploring the semantic shortcoming of codec for audio language model,
Z. Ye, P. Sun, J. Lei, H. Lin, X. Tan, Z. Dai, Q. Kong, J. Chen, J. Pan, Q. Liuet al., “Codec does matter: Exploring the semantic shortcoming of codec for audio language model,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 24, 2025, pp. 25 697–25 705
2025
-
[28]
Socodec: A semantic-ordered multi-stream speech codec for ef- ficient language model based text-to-speech synthesis,
H. Guo, F. Xie, K. Xie, D. Yang, D. Guo, X. Wu, and H. Meng, “Socodec: A semantic-ordered multi-stream speech codec for ef- ficient language model based text-to-speech synthesis,” in2024 IEEE Spoken Language Technology Workshop (SLT), 2024, pp. 645–651
2024
-
[29]
Universal speech to- ken learning via low-bitrate neural codec and pretrained represen- tations,
X. Jiang, X. Peng, Y . Zhang, and Y . Lu, “Universal speech to- ken learning via low-bitrate neural codec and pretrained represen- tations,”IEEE Journal of Selected Topics in Signal Processing, vol. 18, no. 8, pp. 1477–1489, 2024
2024
-
[30]
Secous- ticodec: Cross-modal aligned streaming single-codecbook speech codec,
C. Qiang, H. Wang, C. Gong, T. Wang, R. Fu, T. Wang, R. Chen, J. Yi, Z. Wen, C. Zhang, L. Wang, J. Dang, and J. Tao, “Secous- ticodec: Cross-modal aligned streaming single-codecbook speech codec,”arXiv preprint arXiv:2508.02849, 2025
arXiv 2025
-
[31]
Moshi: a speech-text foundation model for real-time dialogue,
A. D ´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
Pith/arXiv arXiv 2024
-
[32]
Speechtok- enizer: Unified speech tokenizer for speech language models,
X. Zhang, D. Zhang, S. Li, Y . Zhou, and X. Qiu, “Speechtok- enizer: Unified speech tokenizer for speech language models,” inThe Twelfth International Conference on Learning Representa- tions
-
[33]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agar- wal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PmLR, 2021, pp. 8748–8763
2021
-
[34]
Joint autoregressive and hierarchical priors for learned image compression,
D. Minnen, J. Ball ´e, and G. D. Toderici, “Joint autoregressive and hierarchical priors for learned image compression,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018
2018
-
[35]
Learned image compression with discretized gaussian mixture likelihoods and at- tention modules,
Z. Cheng, H. Sun, M. Takeuchi, and J. Katto, “Learned image compression with discretized gaussian mixture likelihoods and at- tention modules,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 7939–7948
2020
-
[36]
Channel-wise autoregressive entropy models for learned image compression,
D. He, Y . Zheng, B. Sun, Y . Wang, H. Qin, Y . Ren, X. Wang, H. Liu, M. Jin, and Y . Ma, “Channel-wise autoregressive entropy models for learned image compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), 2022, pp. 13 016–13 025
2022
-
[37]
Fi- nite scalar quantization: VQ-V AE made simple,
F. Mentzer, D. Minnen, E. Agustsson, and M. Tschannen, “Fi- nite scalar quantization: VQ-V AE made simple,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[38]
Semanticodec: An ultra low bitrate semantic audio codec for general sound,
H. Liu, X. Xu, Y . Yuan, M. Wu, W. Wang, and M. D. Plumb- ley, “Semanticodec: An ultra low bitrate semantic audio codec for general sound,”IEEE Journal of Selected Topics in Signal Pro- cessing, 2024
2024
-
[39]
Naturalspeech 3: zero-shot speech syn- thesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y . Liu, Y . Leng, K. Song, S. Tanget al., “Naturalspeech 3: zero-shot speech syn- thesis with factorized codec and diffusion models,” inProceed- ings of the 41st International Conference on Machine Learning, 2024, pp. 22 605–22 623
2024
-
[40]
Libritts: A corpus derived from librispeech for text- to-speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “Libritts: A corpus derived from librispeech for text- to-speech,”arXiv preprint arXiv:1904.02882, 2019
Pith/arXiv arXiv 1904
-
[41]
Aishell-3: A multi- speaker mandarin tts corpus and the baselines,
Y . Shi, H. Bu, X. Xu, S. Zhang, and M. Li, “Aishell-3: A multi- speaker mandarin tts corpus and the baselines,”arXiv preprint arXiv:2010.11567, 2020
arXiv 2010
-
[42]
Praatio,
T. Mahrt, “Praatio,” https://github.com/timmahrt/praatIO, 2016, gitHub repository
2016
-
[43]
English multi-speaker corpus for cstr voice cloning toolkit,
J. Yamagishi, “English multi-speaker corpus for cstr voice cloning toolkit,”URL http://homepages. inf. ed. ac. uk/jyamagis/page3/page58/page58. html, 2012
2012
-
[44]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” in Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), 2020, pp. 4211–4215
2020
-
[45]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[46]
webmushra—a comprehensive framework for web-based listening tests,
M. Schoeffler, S. Bartoschek, F.-R. St ¨oter, M. Roess, S. Westphal, B. Edler, and J. Herre, “webmushra—a comprehensive framework for web-based listening tests,”Journal of open research software, vol. 6, no. 1, 2018
2018
-
[47]
Definition of the opus audio codec,
J.-M. Valin, K. V os, and T. Terriberry, “Definition of the opus audio codec,” Tech. Rep., 2012
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.